Download as PDF, PPTX














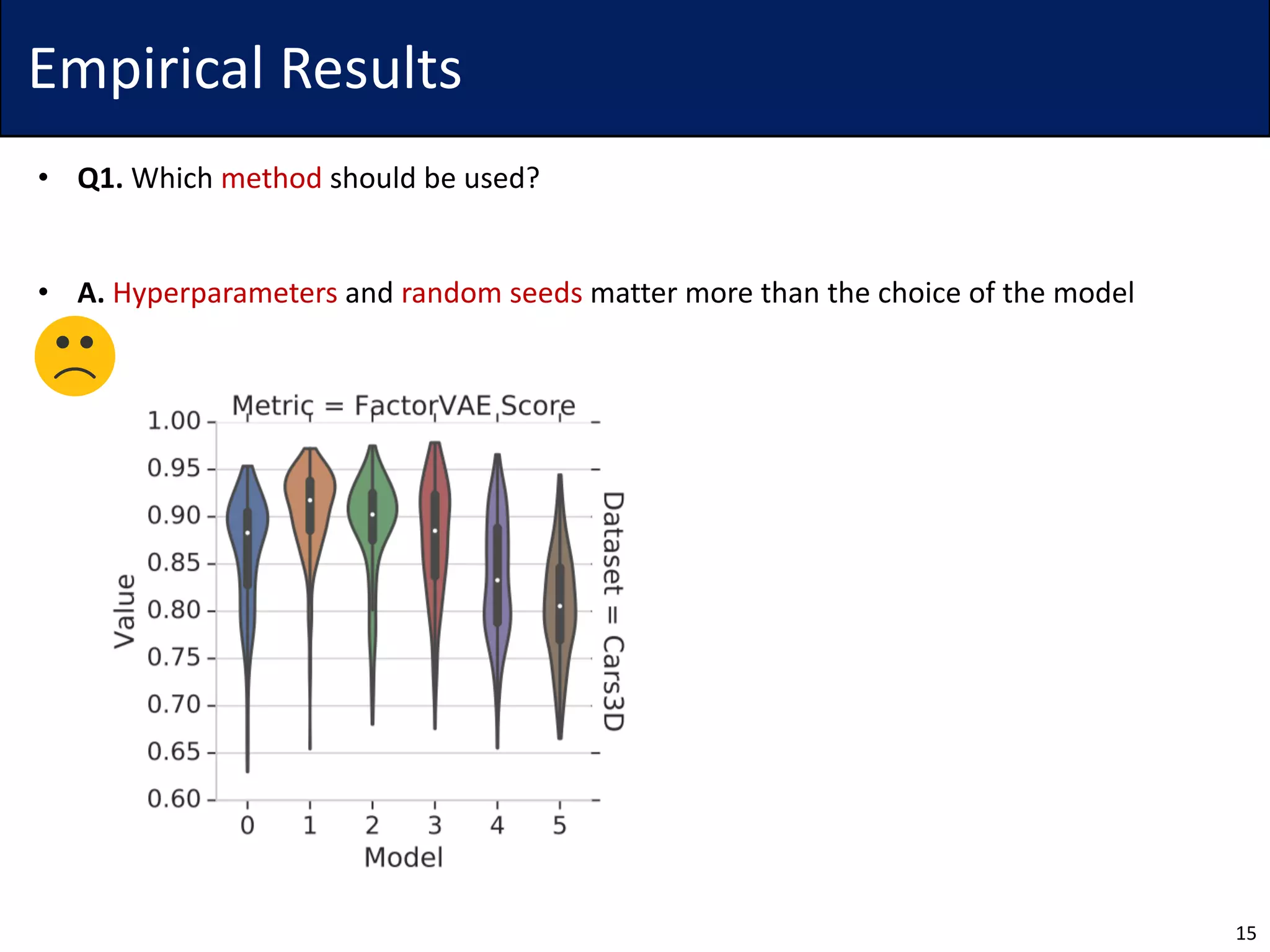
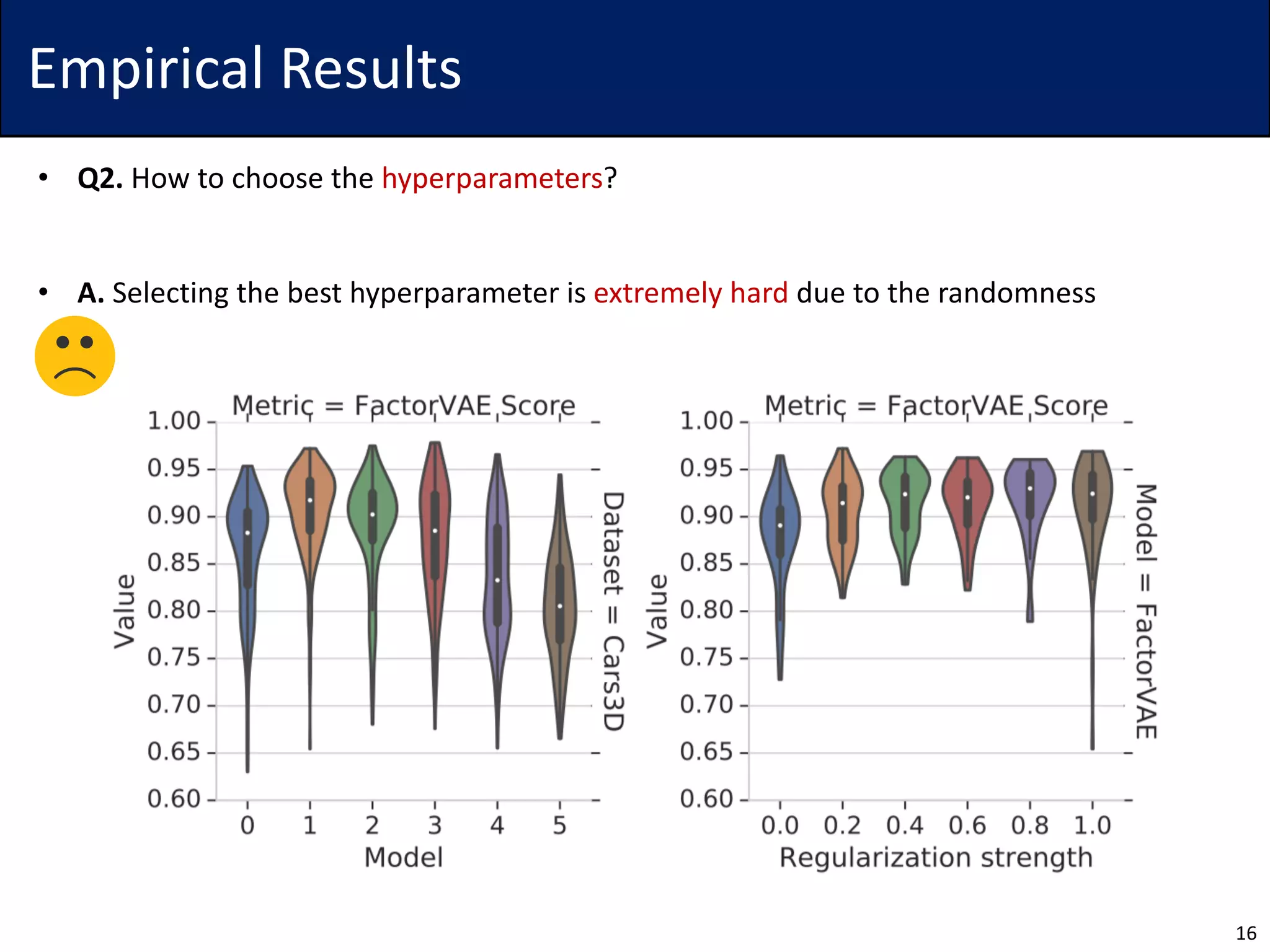
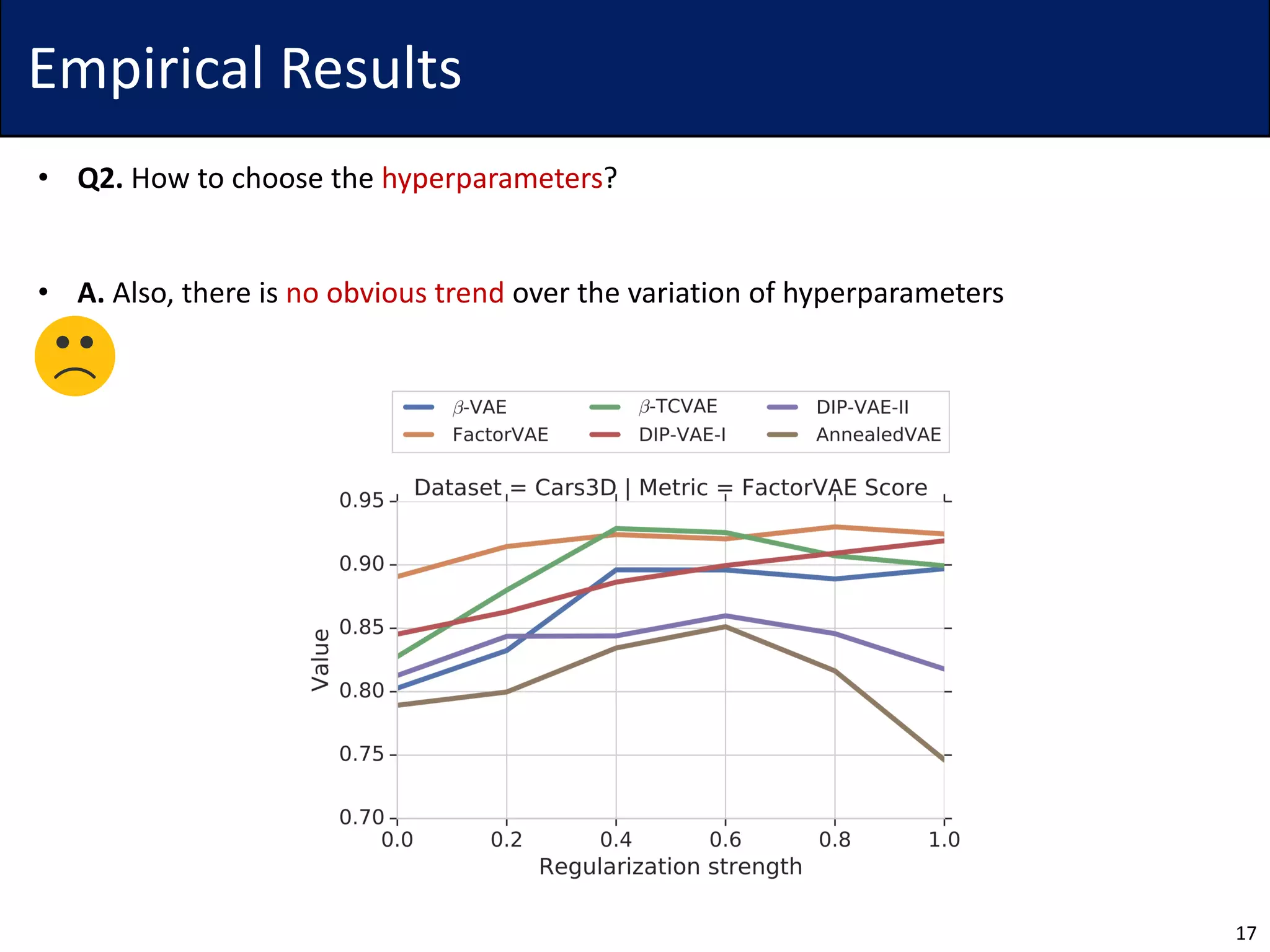
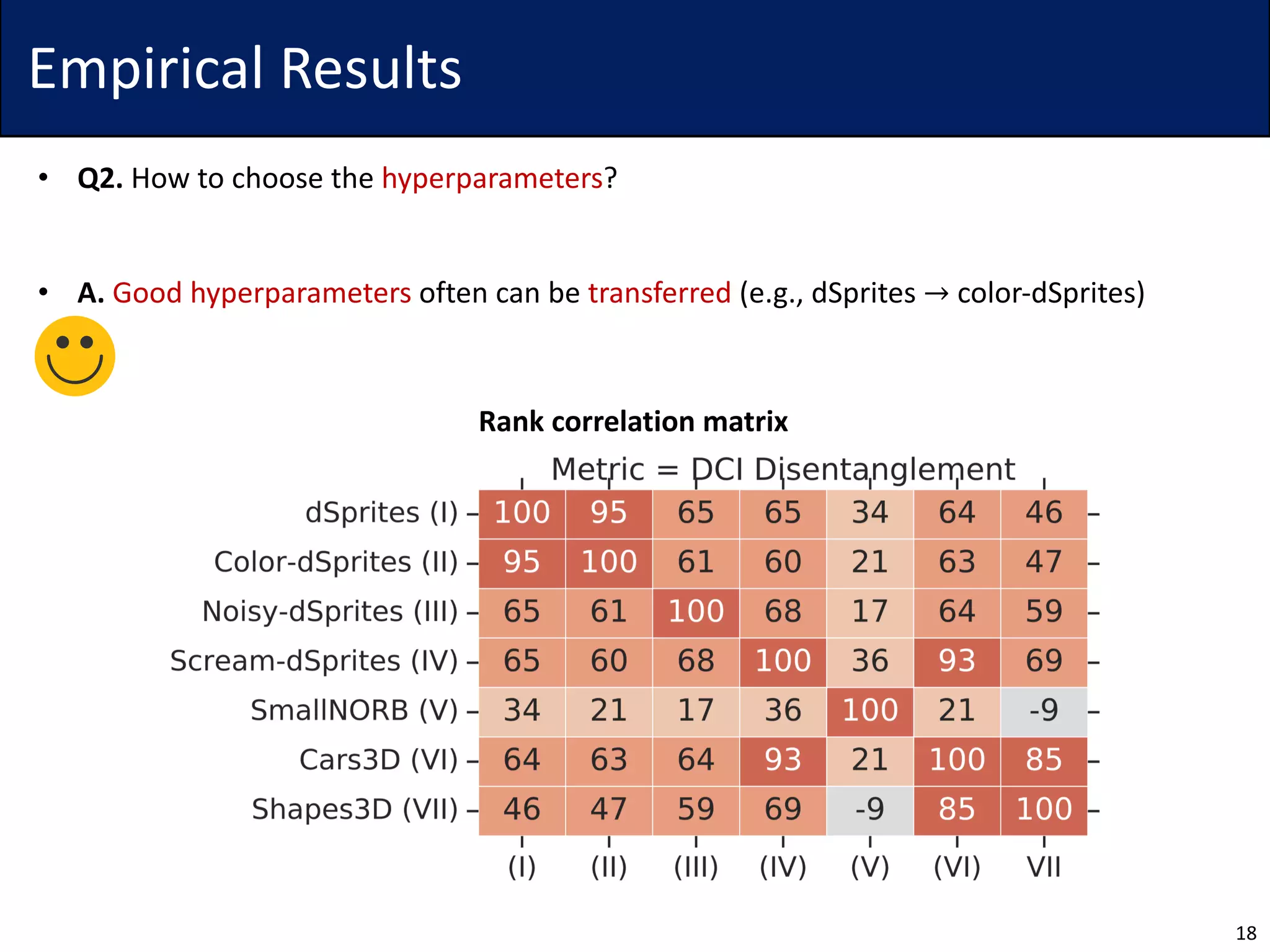









The document discusses challenges in the unsupervised learning of disentangled representations, emphasizing that such learning is fundamentally impossible without inductive biases. It reviews existing methods, metrics for evaluation, and presents theoretical results that highlight limitations of current approaches. Empirical findings suggest the significance of hyperparameters and the necessity for rigorous validation of methods, with recommendations for future research to improve disentanglement using few labels.


















![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)

























































