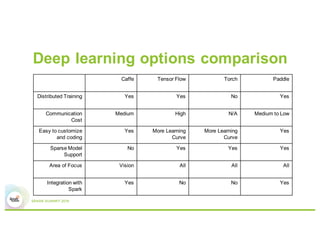
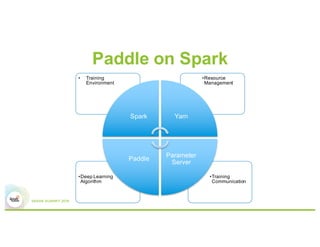
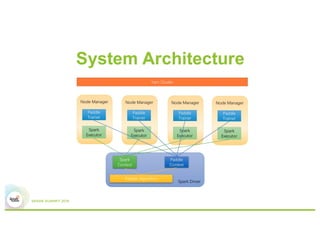
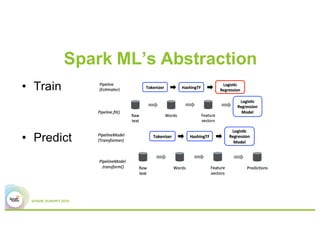
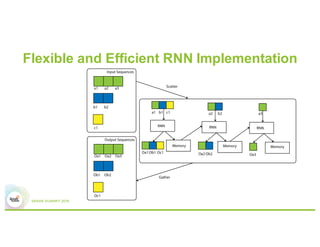
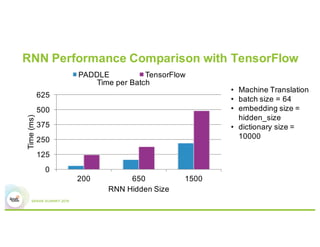
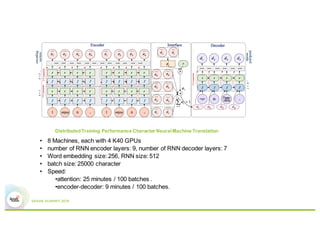
This document summarizes Baidu's work on scaling deep learning using Spark. It discusses:
1) Baidu's goals of implementing Spark ML abstractions to train deep learning models with minimal code changes and leveraging Paddle's distributed training capabilities.
2) The system architecture which uses Spark and YARN for resource management and Paddle for distributed training.
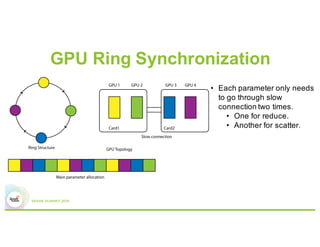
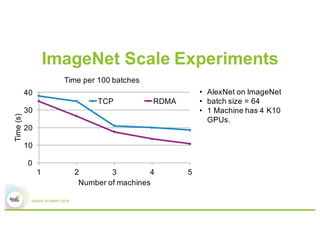
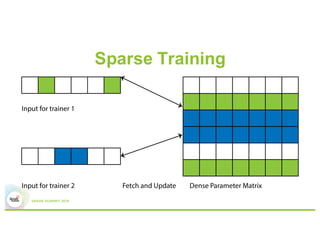
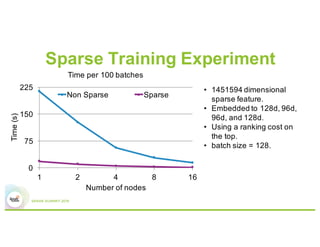
3) Experiments showing Paddle can efficiently train large models like image recognition on ImageNet using many machines and GPUs, as well as sparse models.