GPU Computing With Apache Spark And Python
- Python is a popular language for data science and analytics due to its large ecosystem of libraries and ease of use, but it is slow for number crunching tasks. GPU computing is a way to accelerate Python workloads.
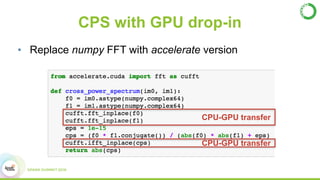
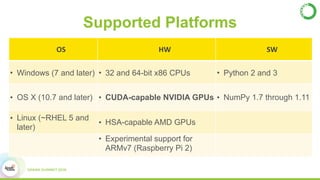
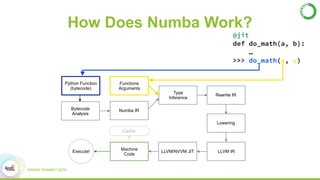
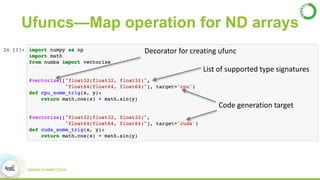
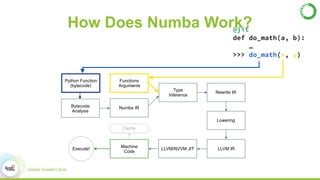
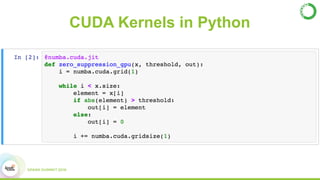
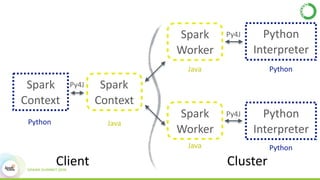
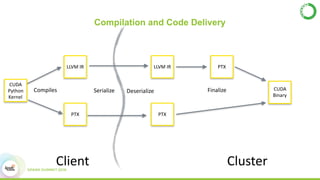
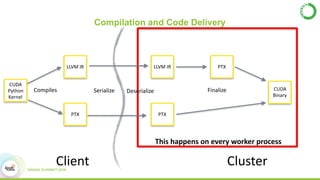
- This presentation demonstrates using GPUs with Apache Spark and Python through libraries like Accelerate, which provides drop-in GPU-accelerated functions, and Numba, which can compile Python functions to run on GPUs.
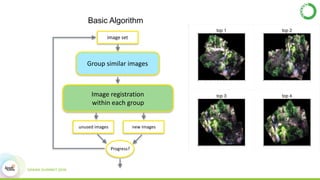
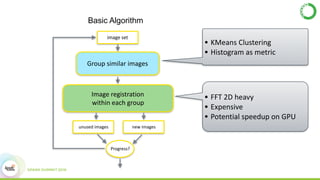
- As an example, the task of image registration, which involves computationally expensive 2D FFTs, is accelerated using these GPU libraries within a PySpark job, achieving a 2-4x speedup over CPU-only versions

































































































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)