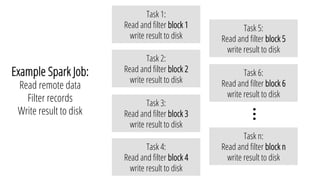
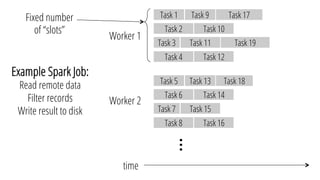
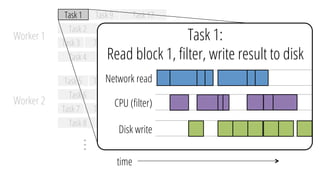
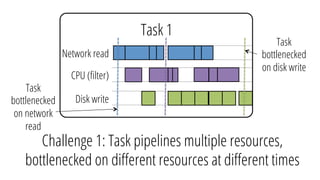
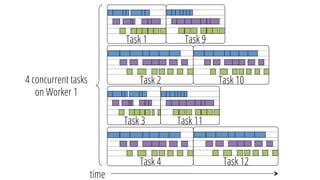
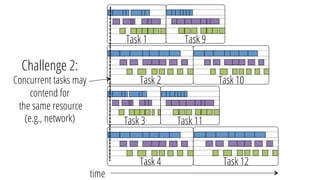
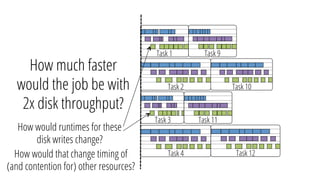
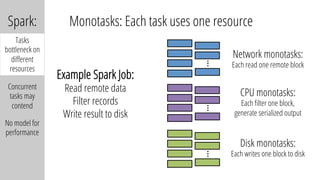
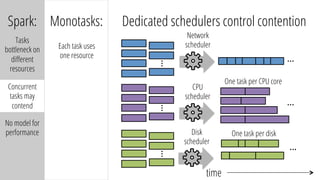
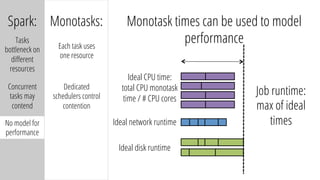
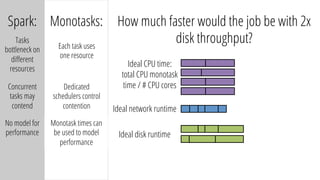
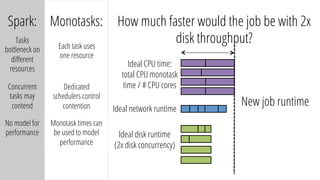
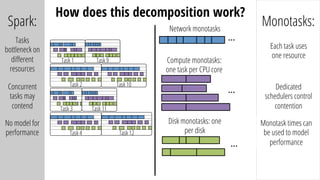
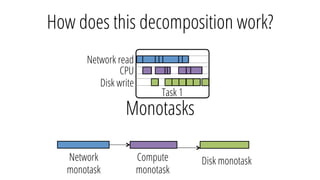
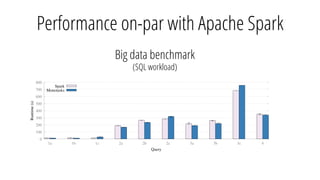
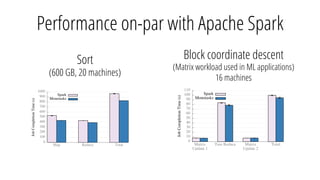
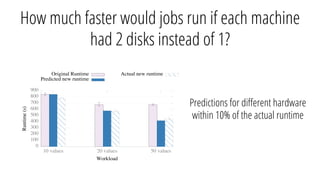
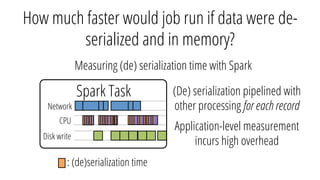
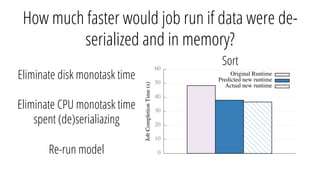
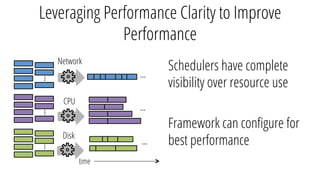
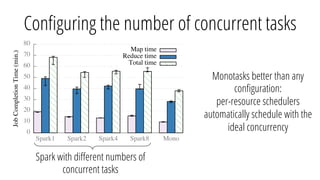
The document describes a new architecture called "monotasks" for Apache Spark that aims to make reasoning about Spark job performance easier. The monotasks architecture decomposes Spark tasks so that each task uses only one resource (e.g. CPU, disk, network). This avoids issues where Spark tasks bottleneck on different resources over time or experience resource contention. With monotasks, dedicated schedulers control resource contention and monotask timing data can be used to model ideal performance. Results show monotasks match Spark's performance and provide clearer insight into bottlenecks.







![Reasoning about Spark Performance
Spark Summit 2015:
CPU (not I/O) often
the bottleneck
Project Tungsten:
initiative to optimize
Spark’s CPU use
Spark 2.0:
Some evidence that I/O
is again the bottleneck
[HotCloud ’16]](https://image.slidesharecdn.com/2pkayousterhout-160614191417/85/Re-Architecting-Spark-For-Performance-Understandability-12-320.jpg)