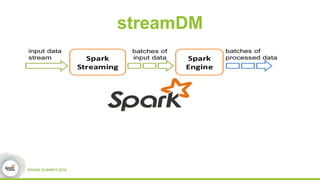
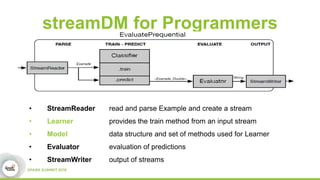
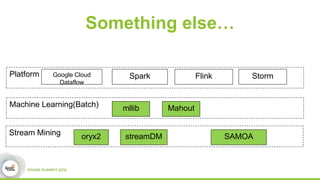
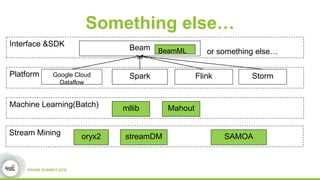
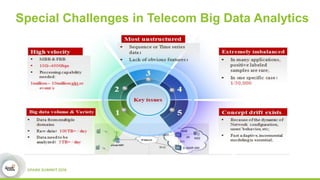
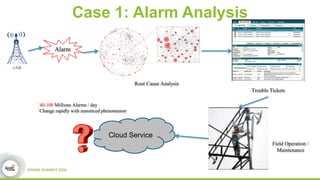
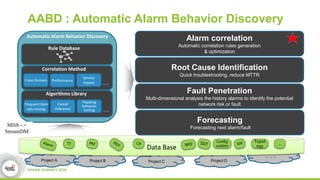
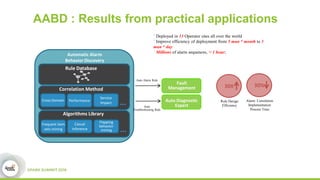
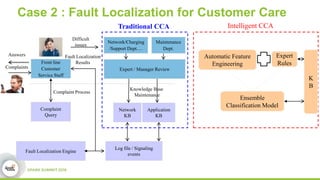
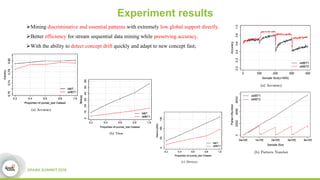
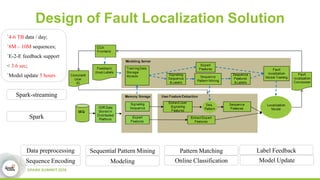
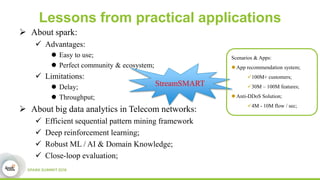
This document discusses streamDM, an open source machine learning library for stream mining in Spark Streaming. It summarizes streamDM's capabilities for incremental learning on data streams using algorithms like SGD, Naive Bayes, clustering and decision trees. Examples of using streamDM in Huawei's network alarm analysis and fault localization systems are provided, demonstrating improvements in efficiency, accuracy and ability to handle large volumes of streaming data. The document encourages researchers to apply for Huawei's Innovation Research Program grants to further collaborative work on stream mining algorithms and applications.











































































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)















