Downloaded 272 times



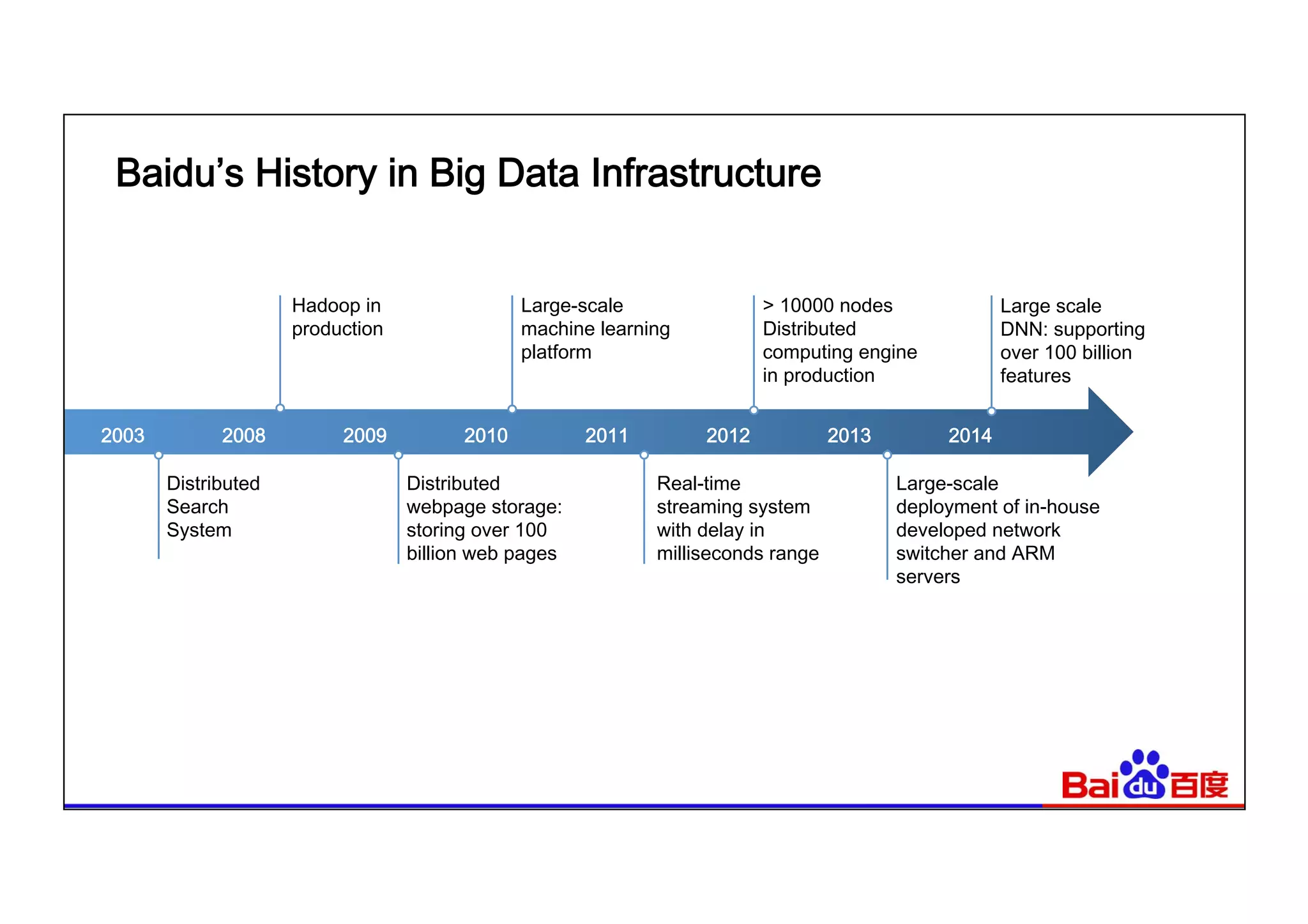
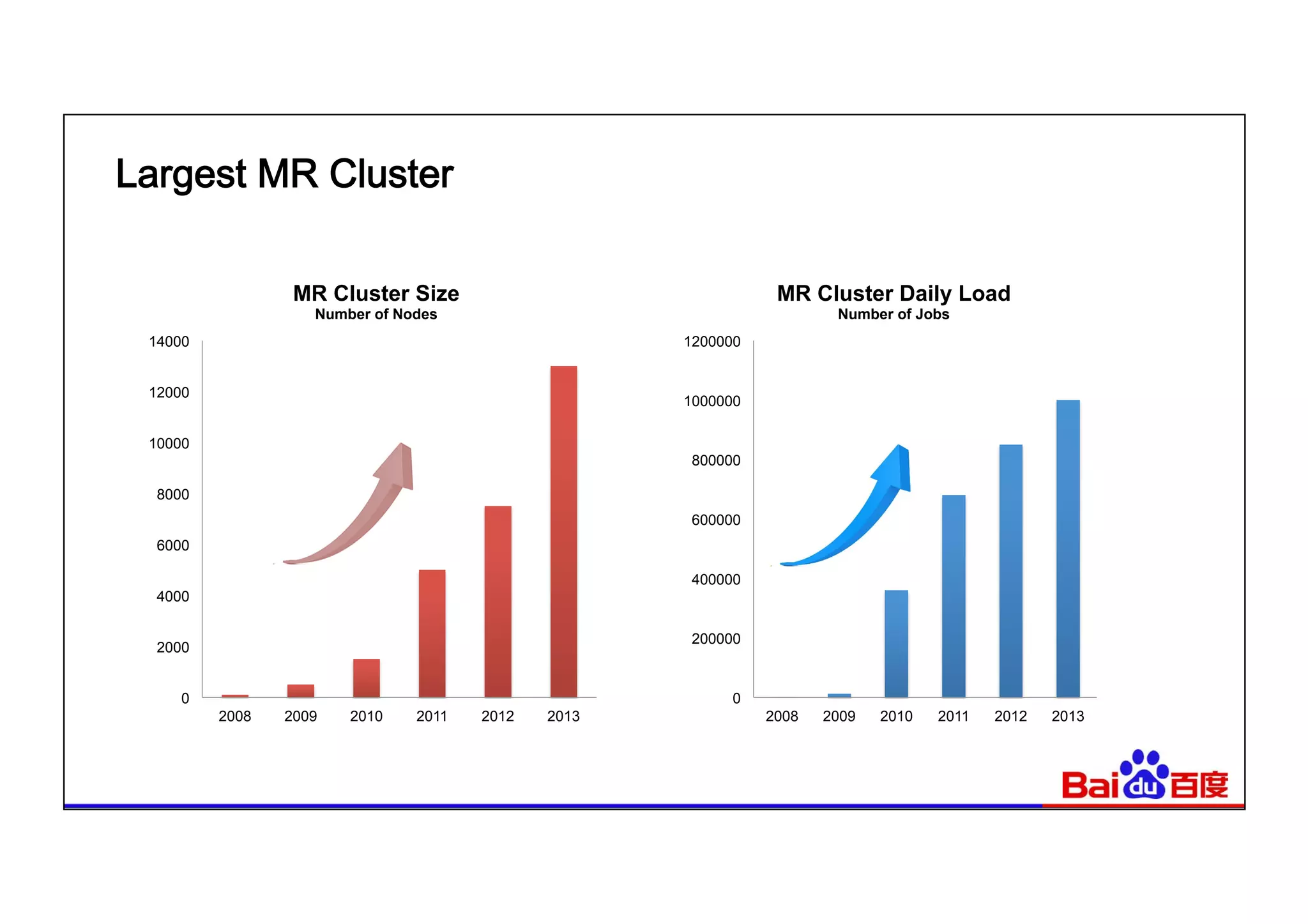

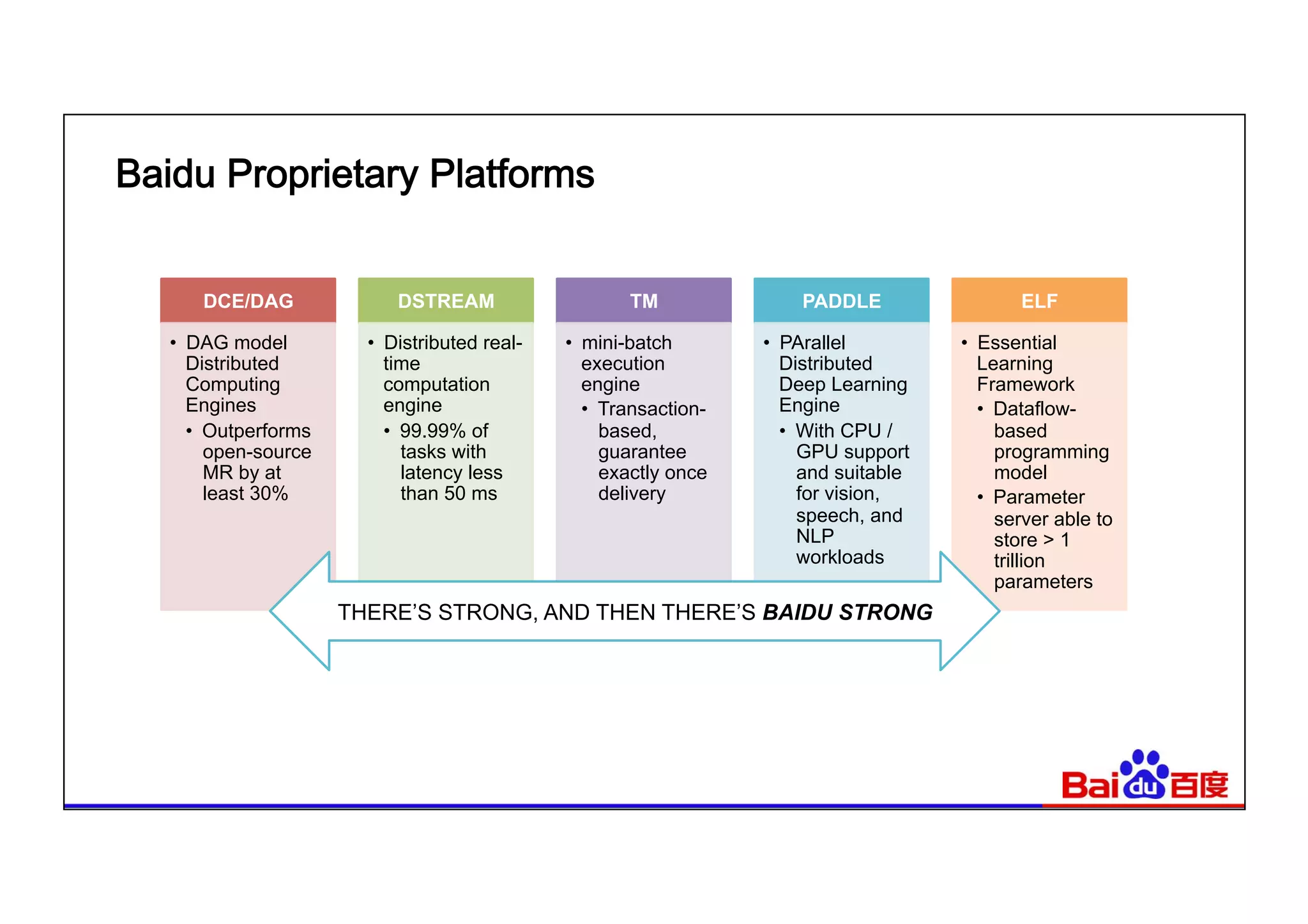

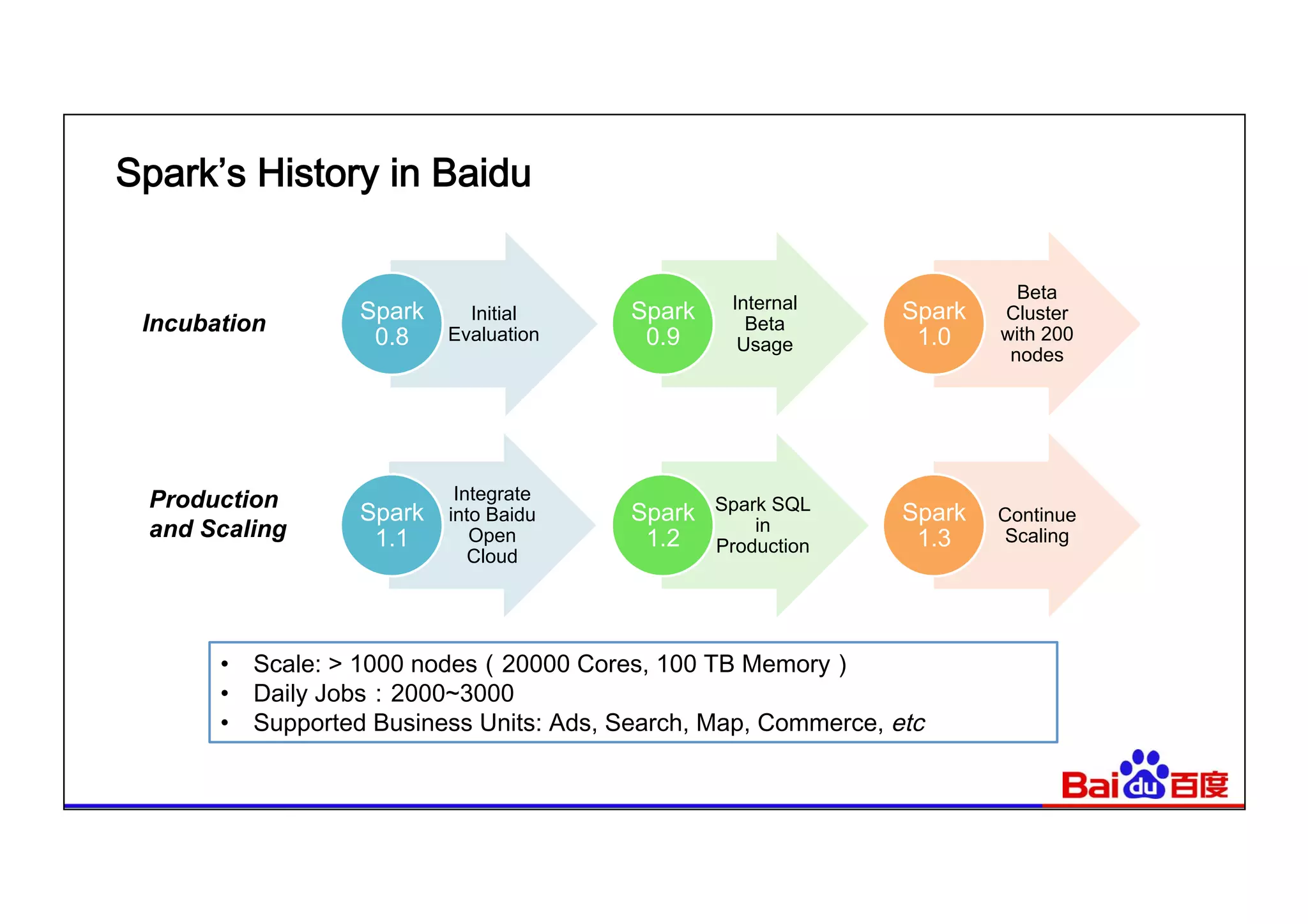
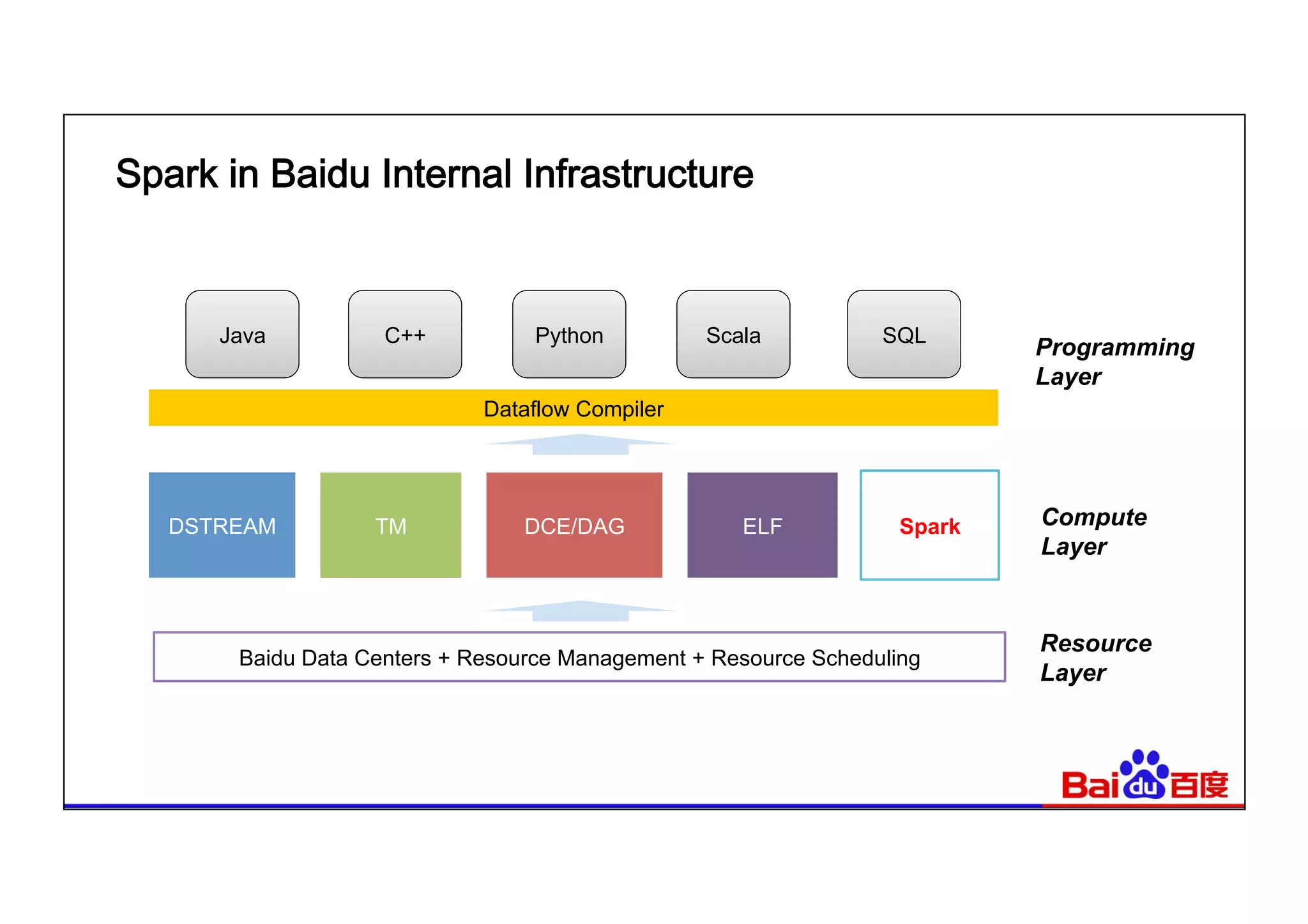
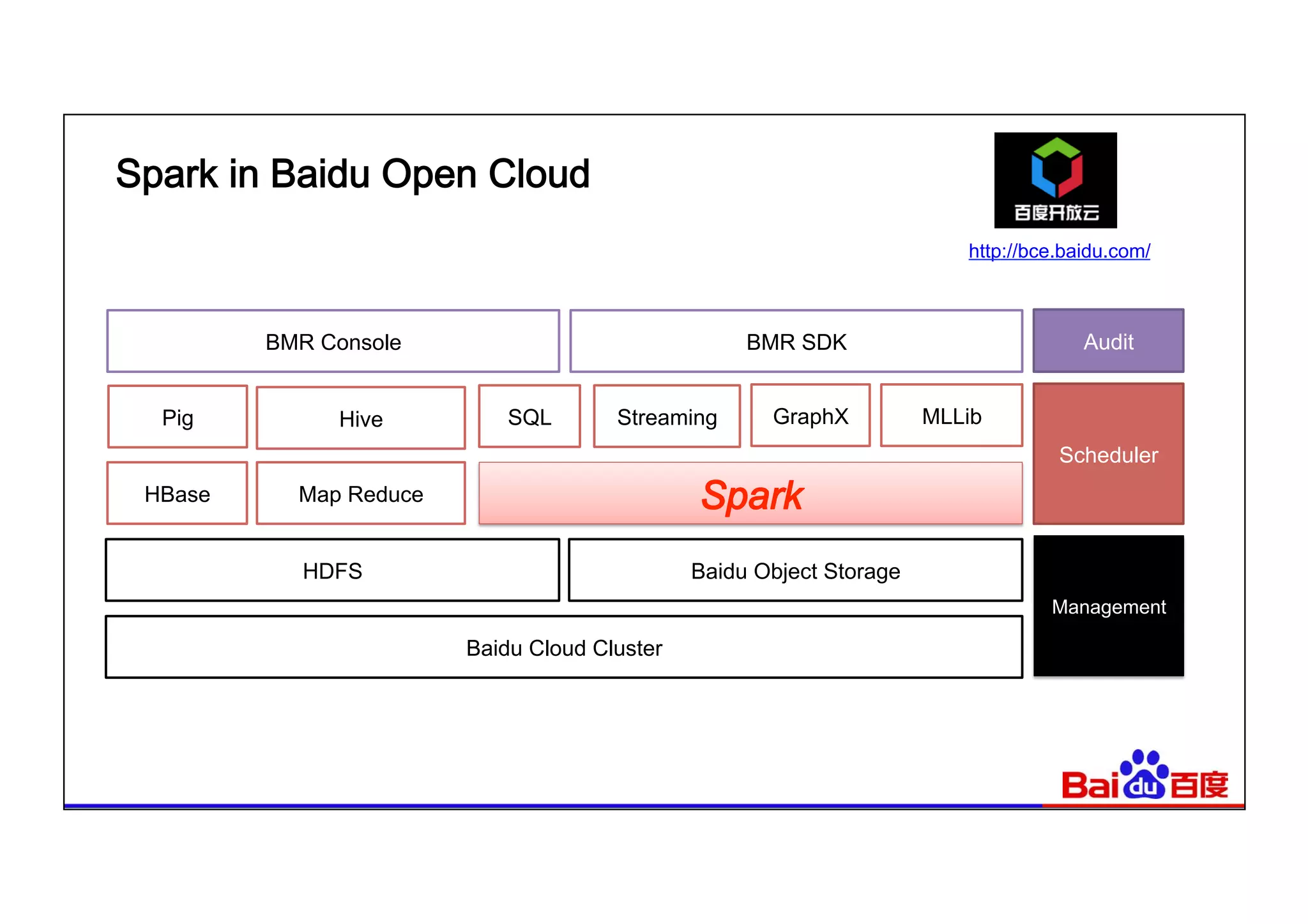

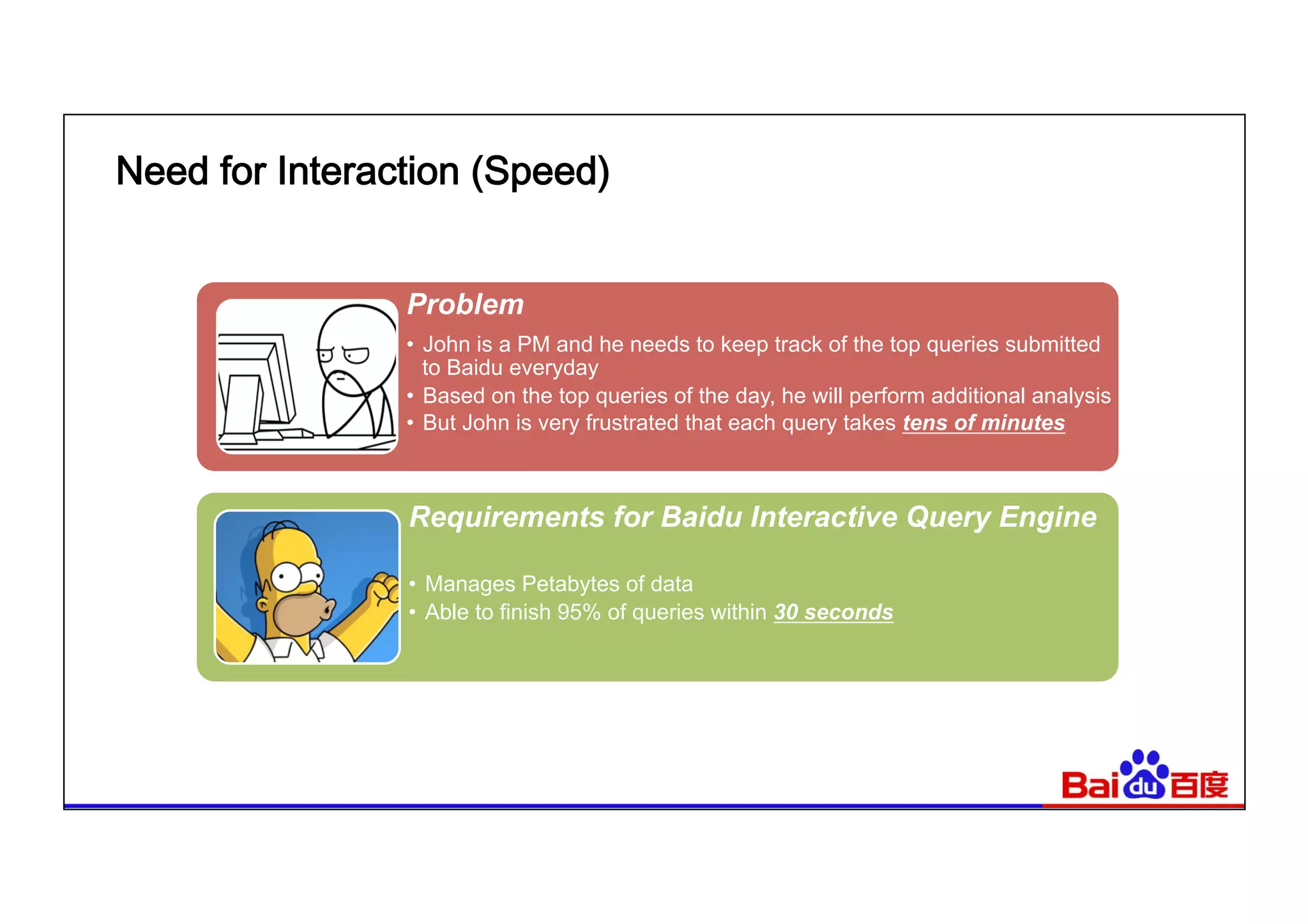
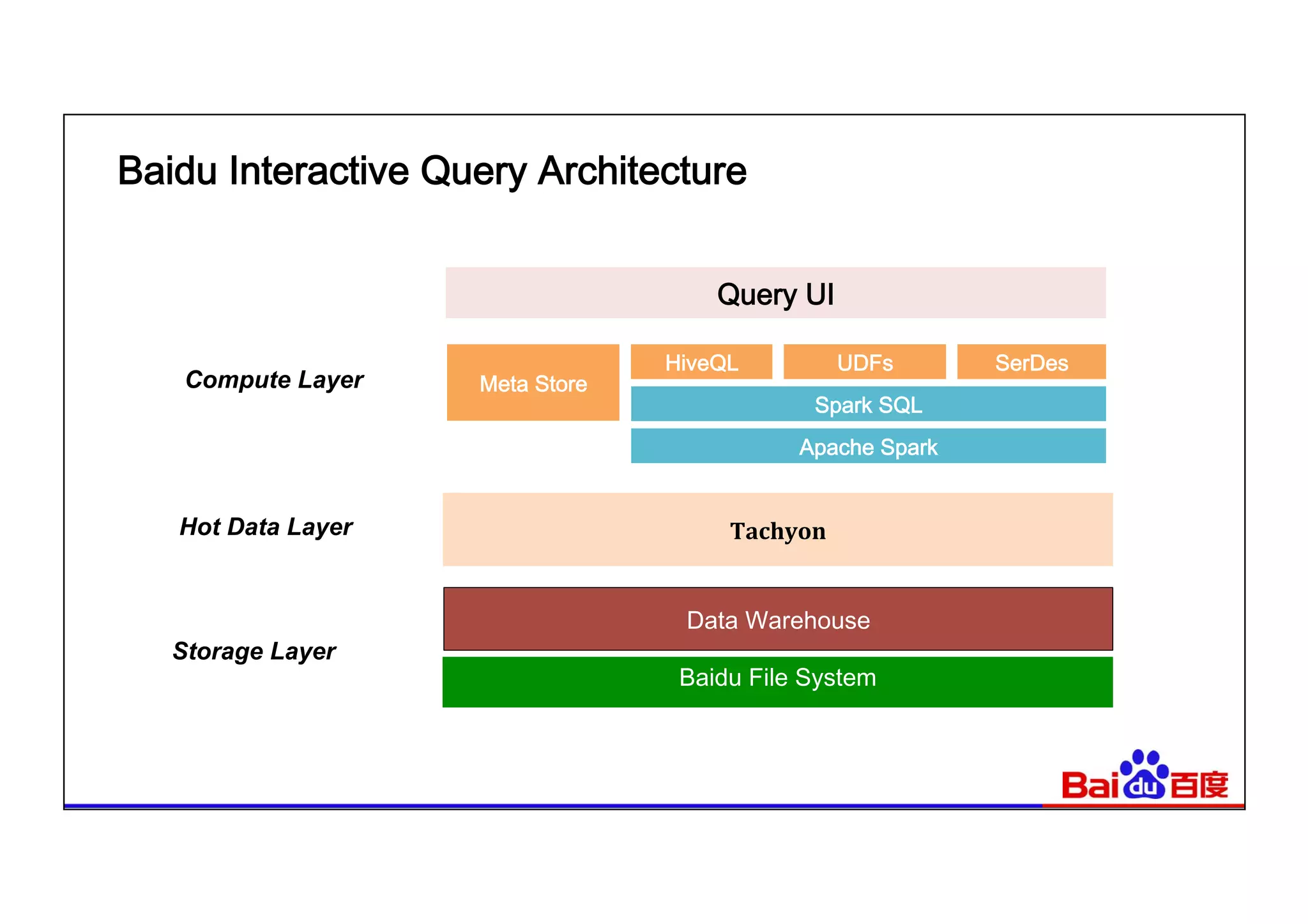
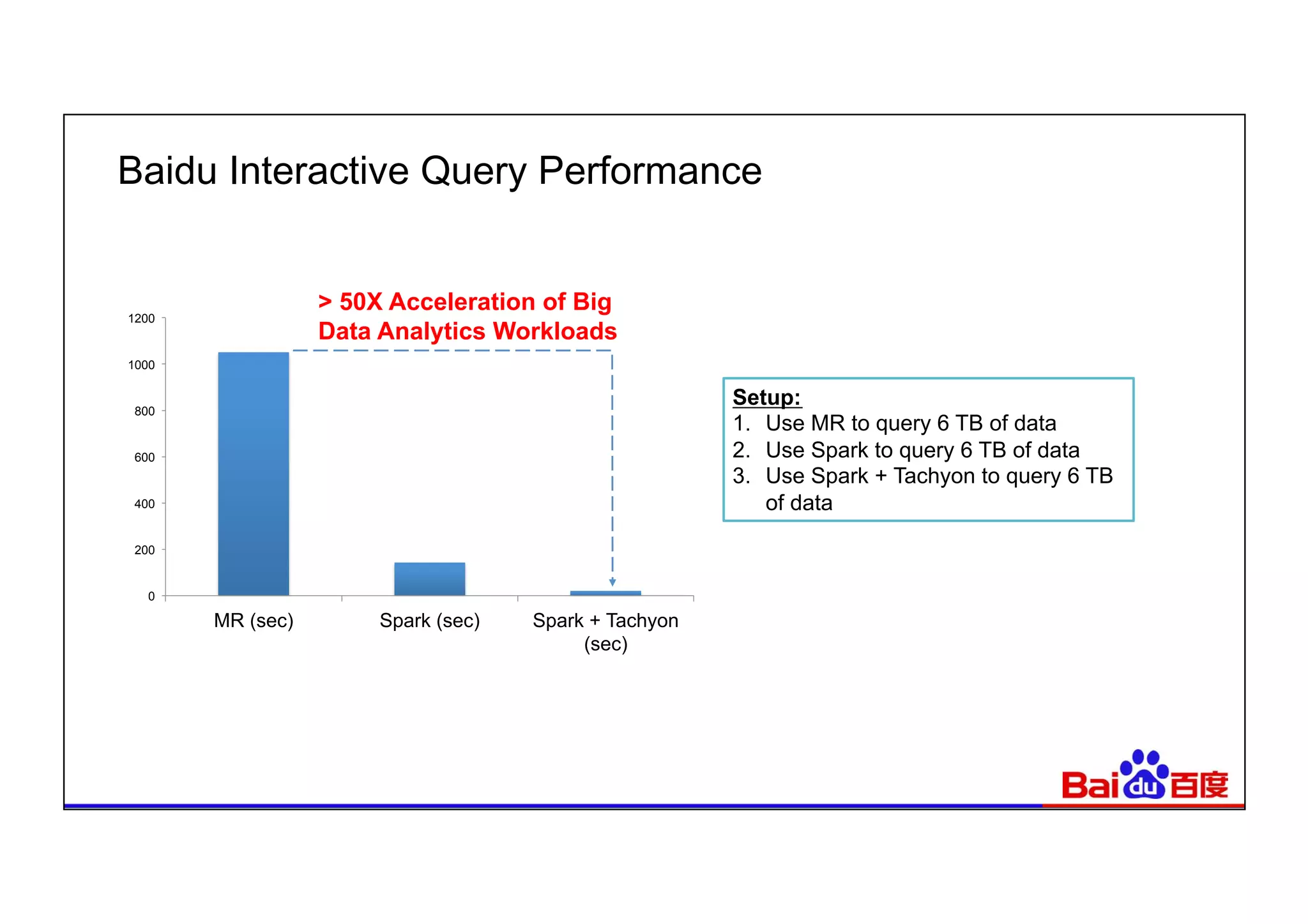
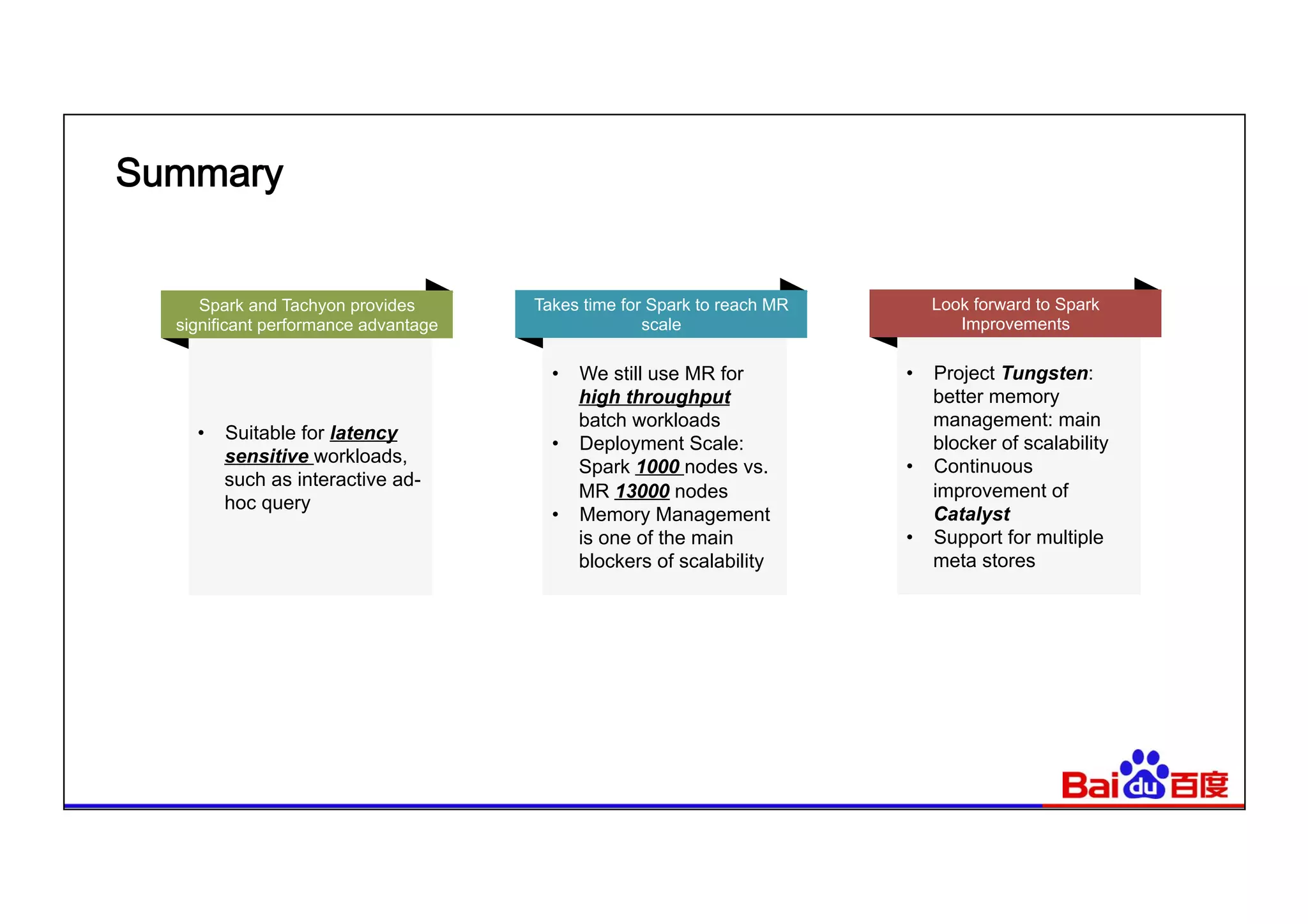
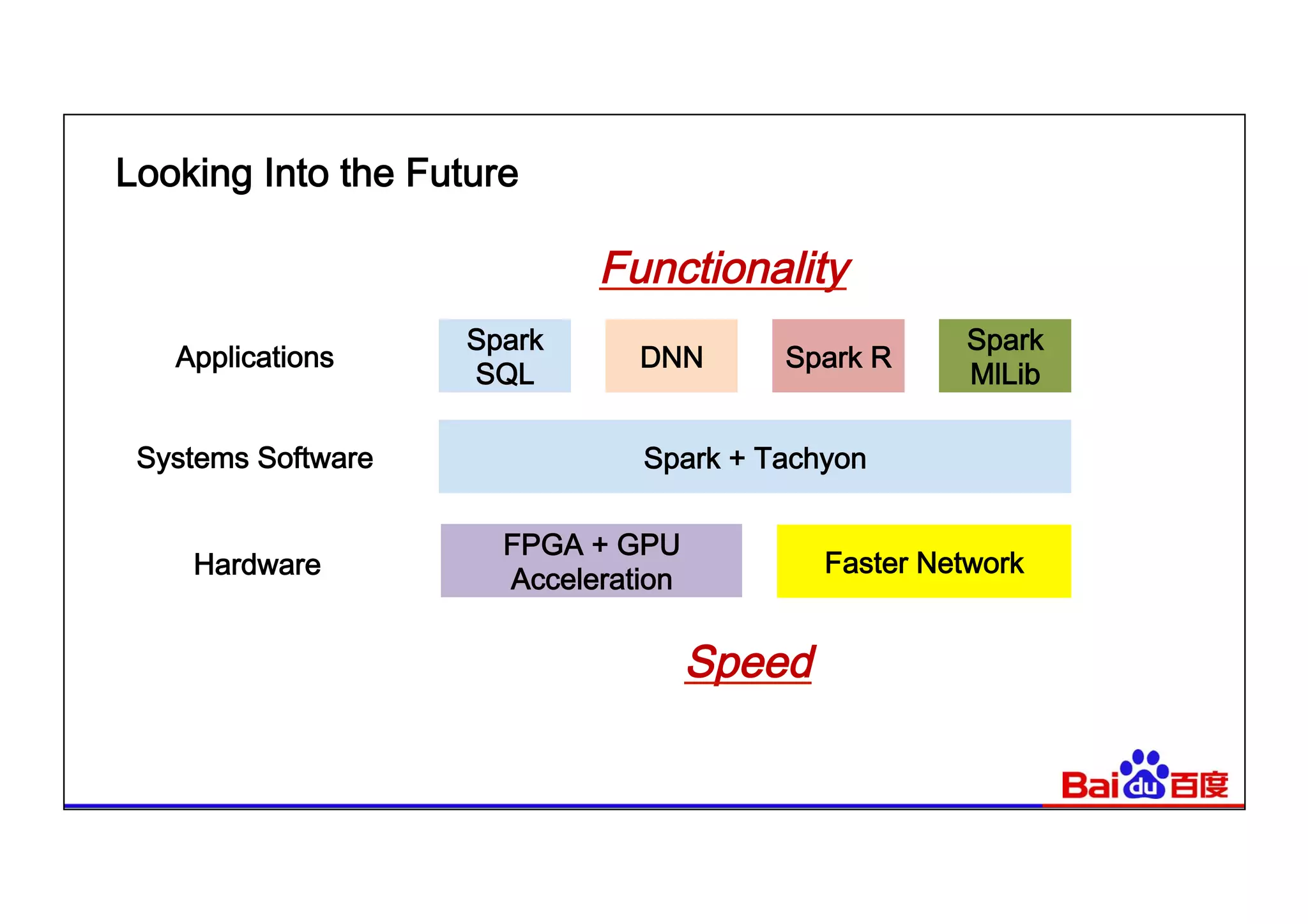

This document summarizes Baidu's use of Apache Spark and Tachyon for interactive data analytics. It describes Baidu's need for faster interactive queries to analyze petabytes of data within 30 seconds. Baidu implemented a query architecture using Spark, SQL and UDFs over Tachyon for hot data and HDFS storage. This provided over 50x acceleration compared to MapReduce, enabling 95% of queries to finish within 30 seconds. While Spark has improved performance, MapReduce still handles high throughput batch workloads at larger scale. Future opportunities include hardware acceleration and continued Spark optimizations for memory management and query planning.
























































































![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)