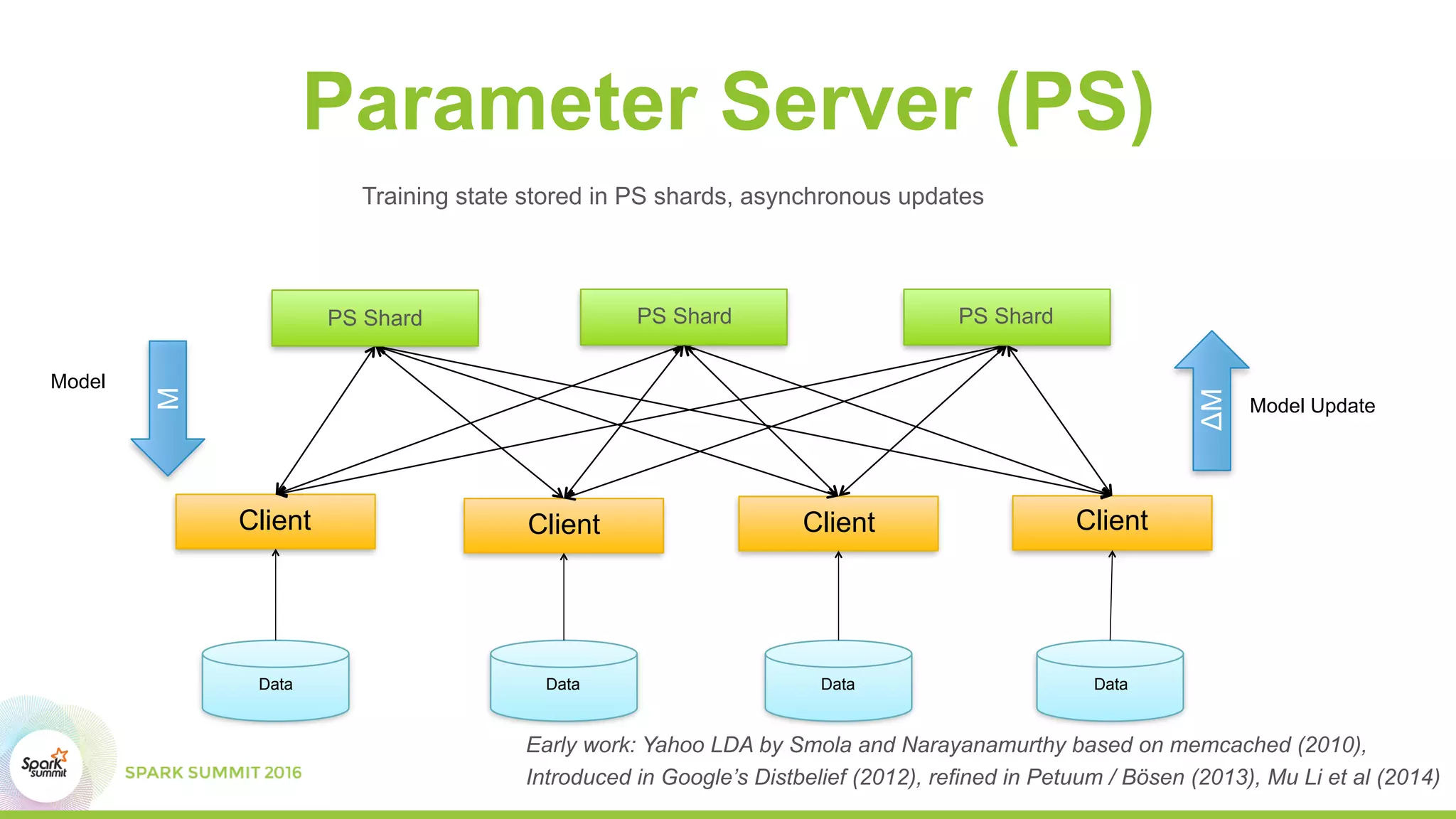
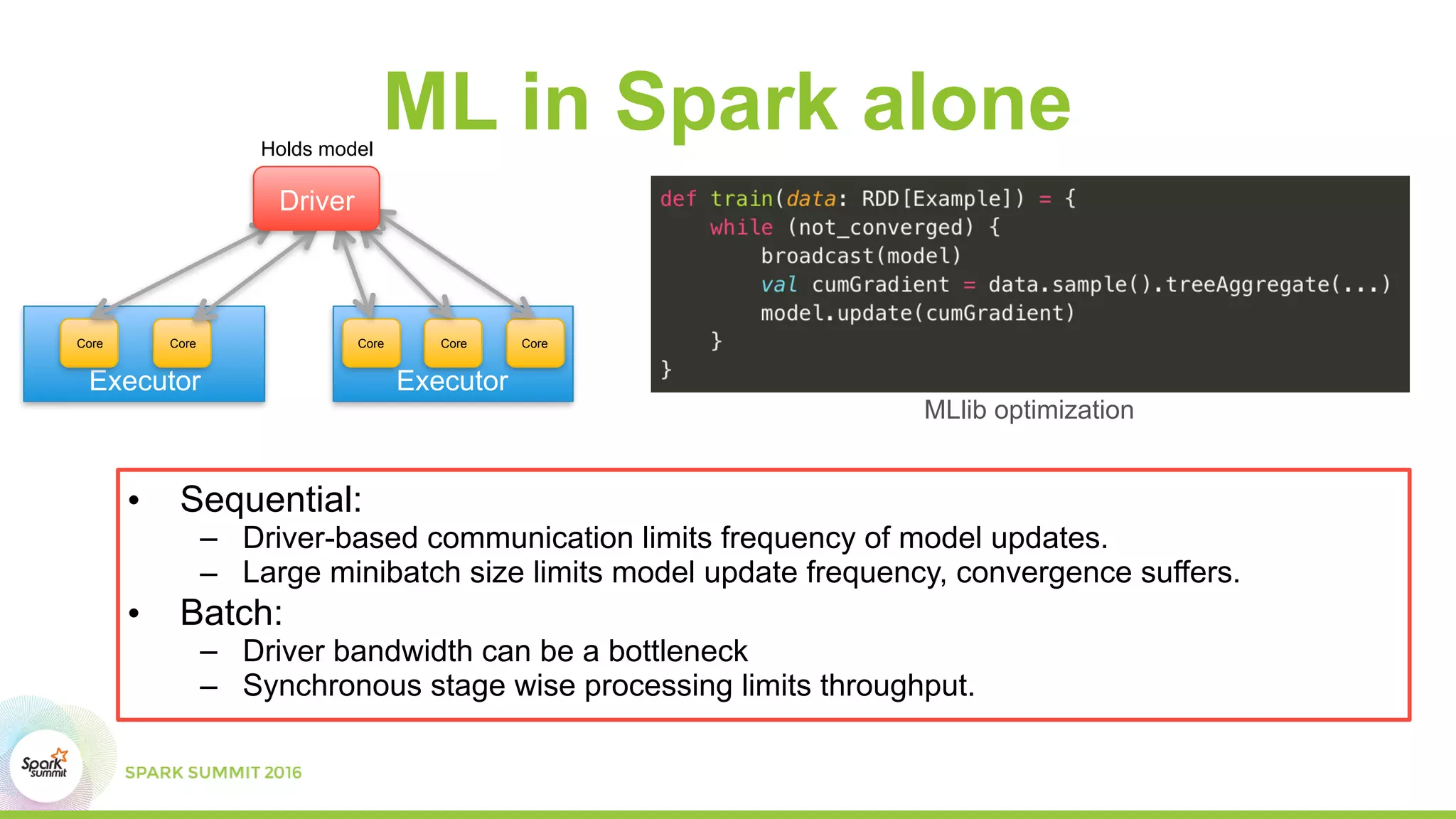
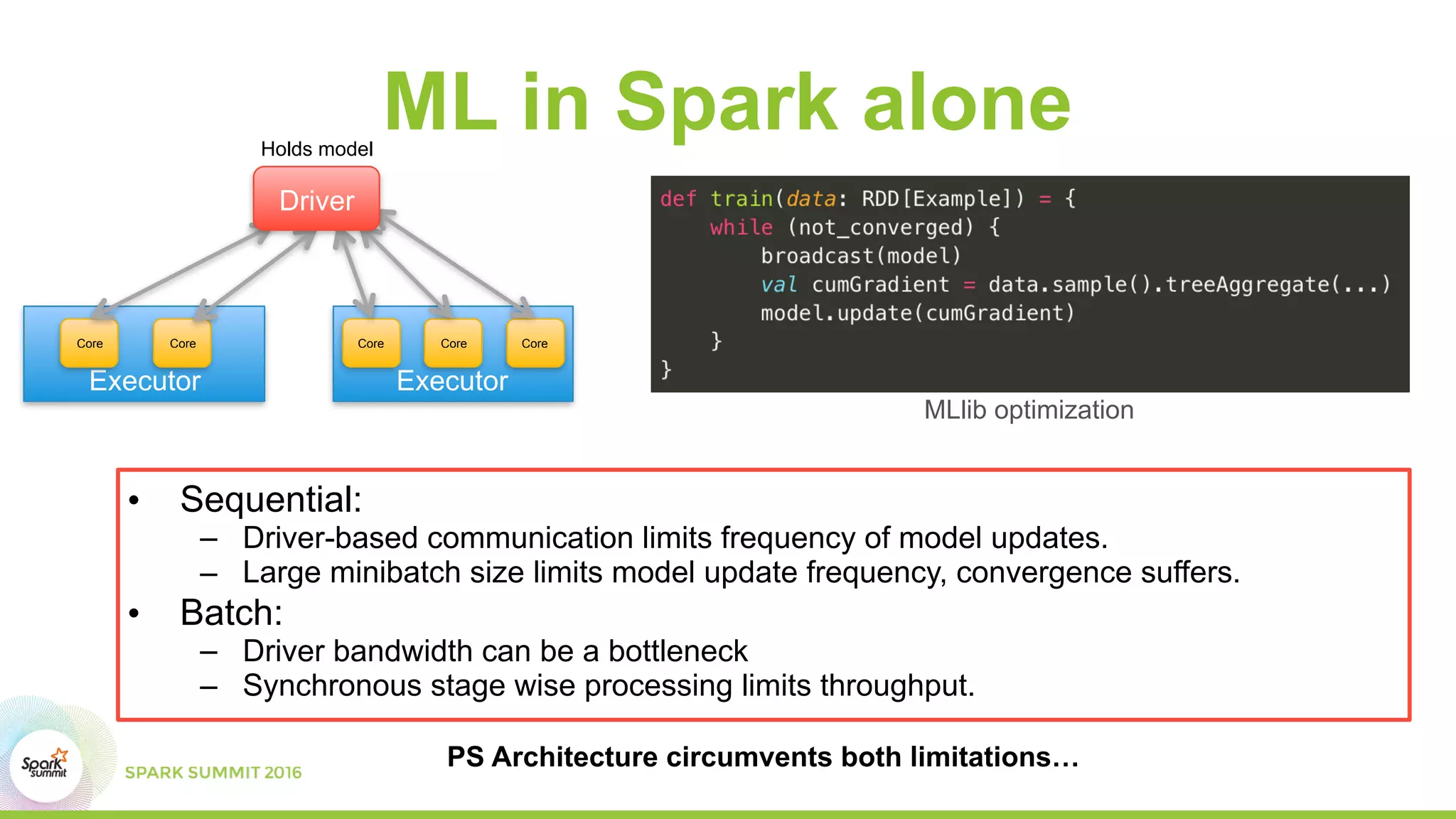
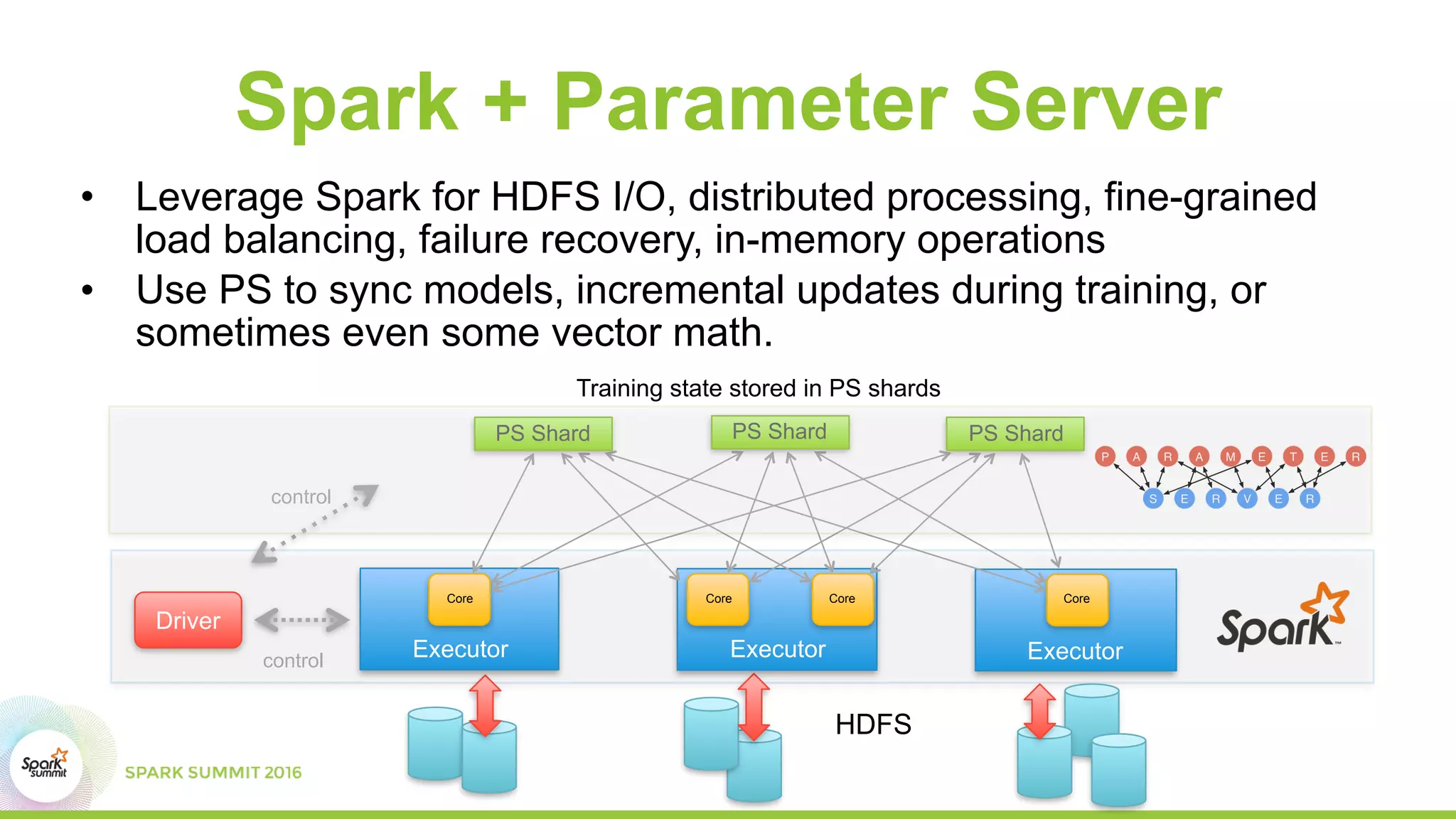
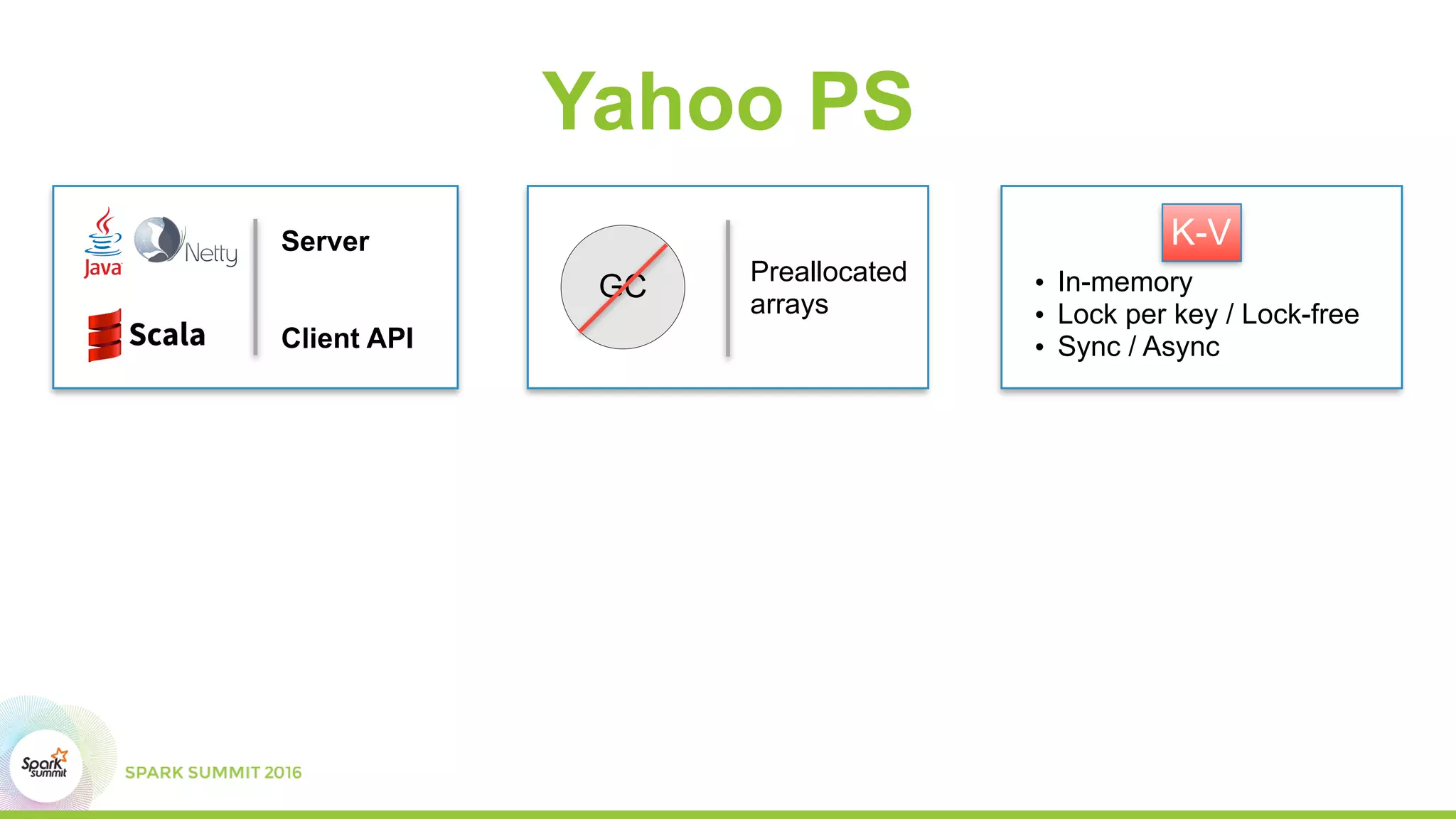
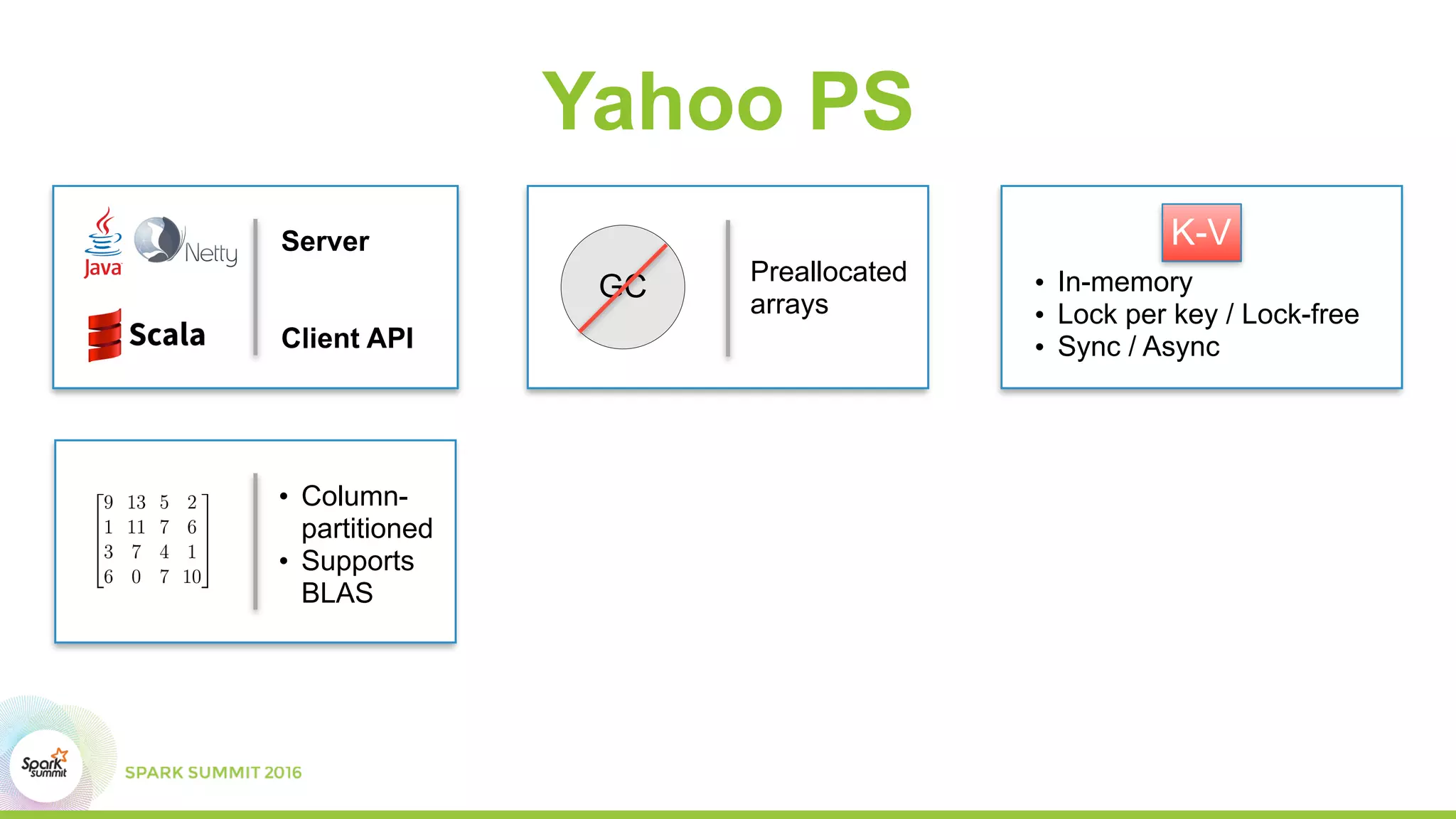
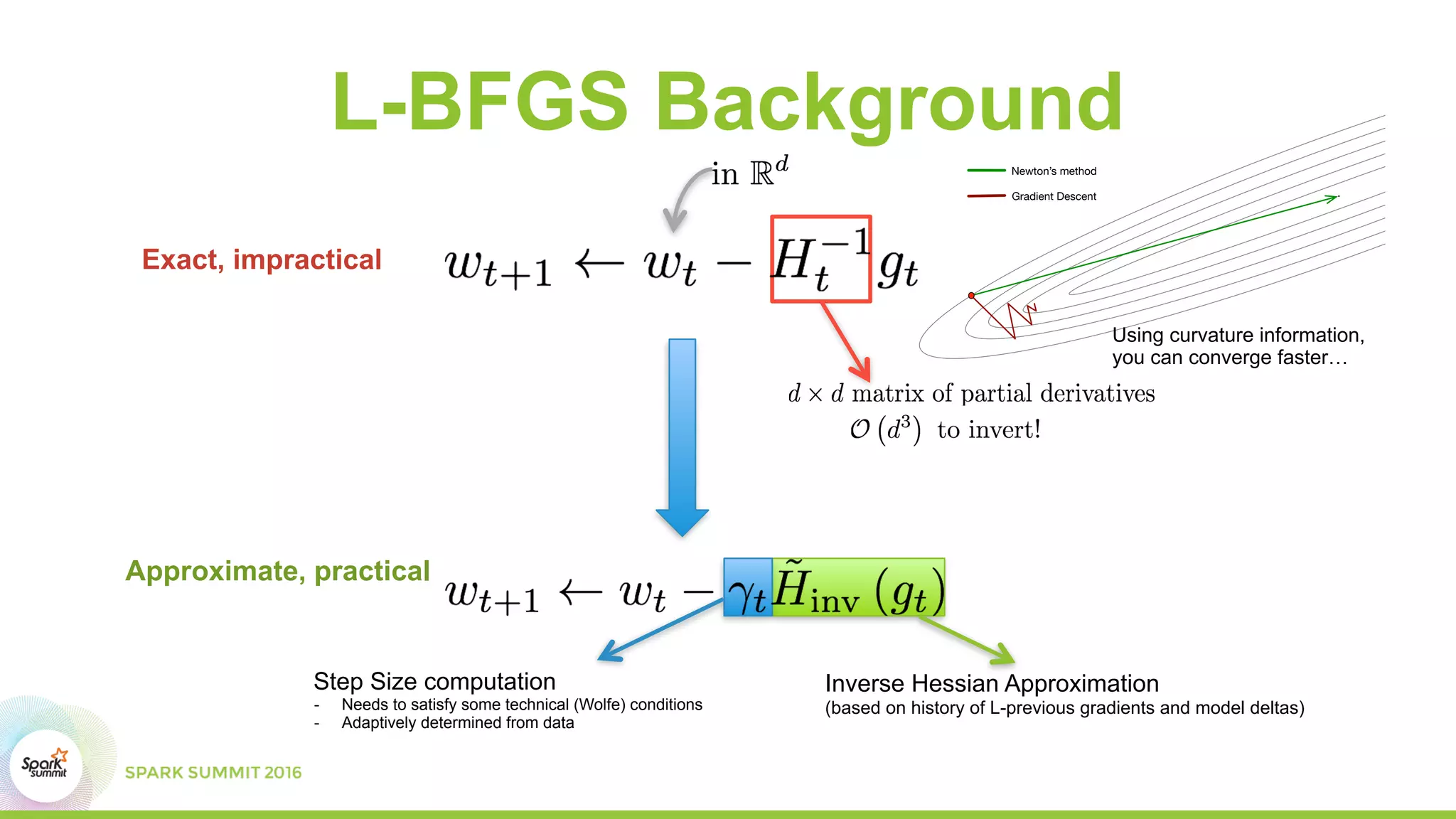
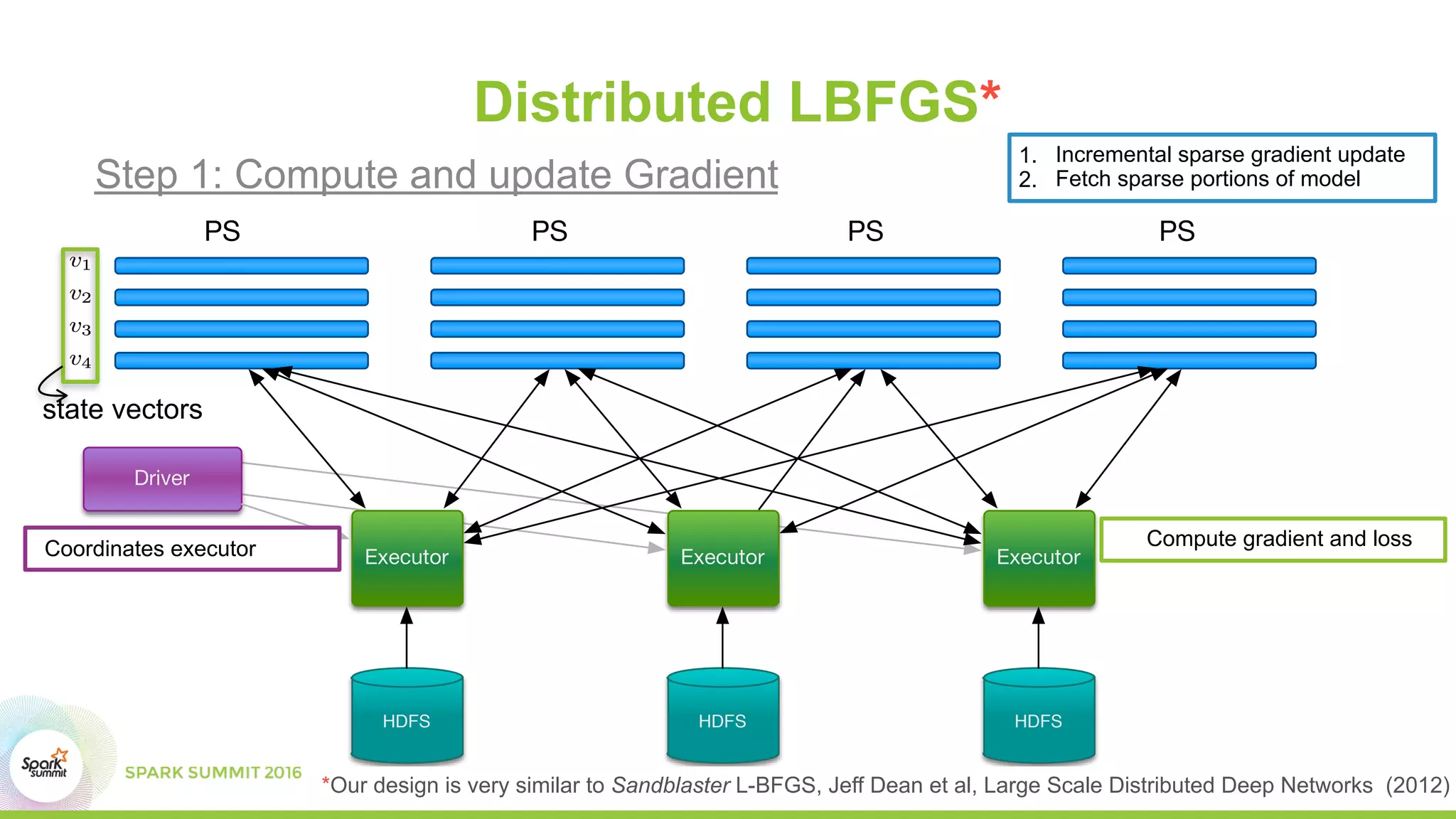
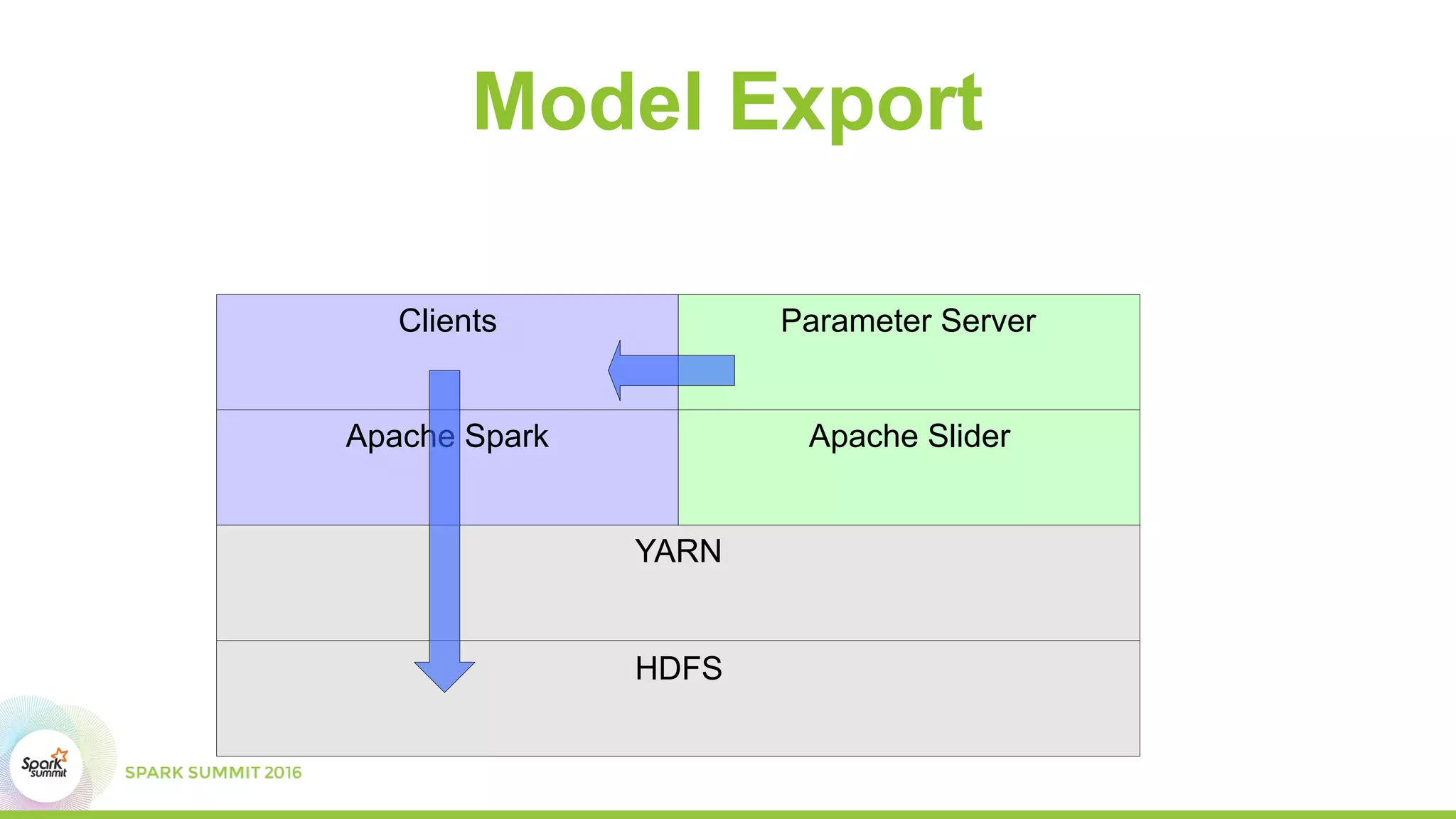
This document summarizes scaling machine learning to billions of parameters using Spark and a parameter server architecture. It describes the requirements for supporting both batch and sequential optimization at web scale. It then outlines the Spark + Parameter server approach, leveraging Spark for distributed processing and the parameter server for synchronizing model updates. Examples of distributed L-BFGS and Word2Vec training are presented to illustrate batch and sequential optimization respectively.



















































![Word Embeddings
v(paris) = [0.13, -0.4, 0.22, …., -0.45]
v(lion) = [-0.23, -0.1, 0.98, …., 0.65]
v(quark) = [1.4, 0.32, -0.01, …, 0.023]
...](https://image.slidesharecdn.com/5bbhaskarordentlich-160614184838/75/Scaling-Machine-Learning-To-Billions-Of-Parameters-60-2048.jpg)









![Word2vec Application at Yahoo
• Example training data:
gas_cap_replacement_for_car
slc_679f037df54f5d9c41cab05bfae0926
gas_door_replacement_for_car
slc_466145af16a40717c84683db3f899d0a fuel_door_covers
adid_c_28540527225_285898621262
slc_348709d73214fdeb9782f8b71aff7b6e autozone_auto_parts
adid_b_3318310706_280452370893 auoto_zone
slc_8dcdab5d20a2caa02b8b1d1c8ccbd36b
slc_58f979b6deb6f40c640f7ca8a177af2d
[ Grbovic, et. al. SIGIR 2015 and SIGIR 2016 (to appear) ]](https://image.slidesharecdn.com/5bbhaskarordentlich-160614184838/75/Scaling-Machine-Learning-To-Billions-Of-Parameters-70-2048.jpg)
























































































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)



