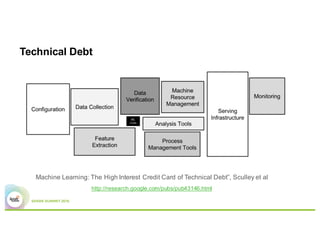
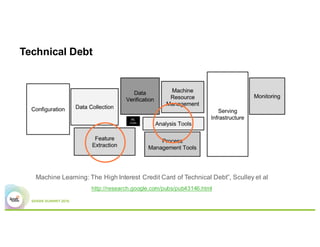
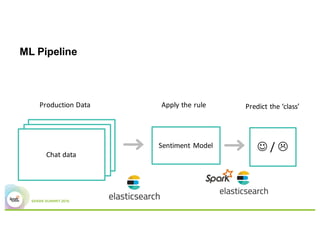
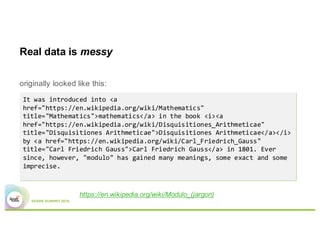
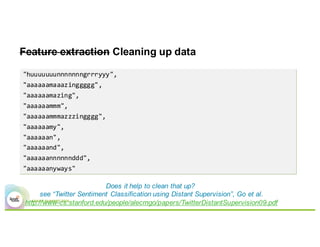
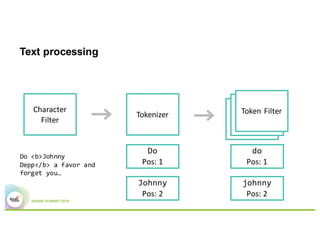
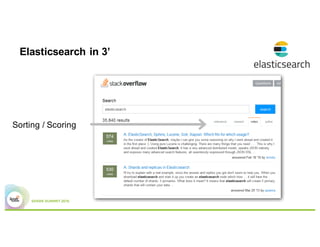
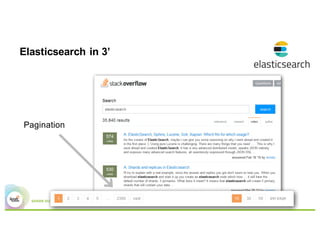
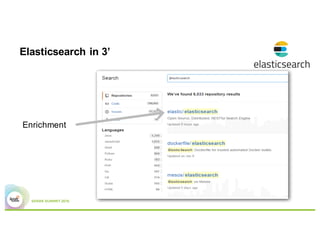
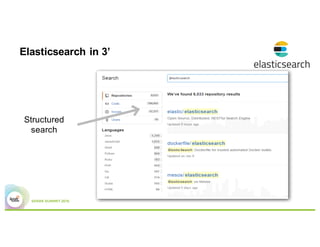
This document summarizes a presentation about using Elasticsearch and Lucene for text processing and machine learning pipelines in Apache Spark. Some key points:
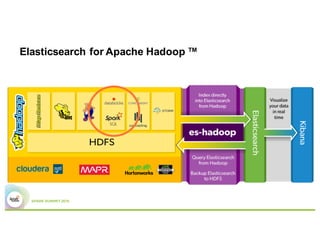
- Elasticsearch provides text analysis capabilities through Lucene and can be used to clean, tokenize, and vectorize text for machine learning tasks.
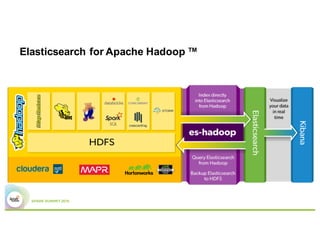
- Elasticsearch integrates natively with Spark through Java/Scala APIs and allows indexing and querying data from Spark.
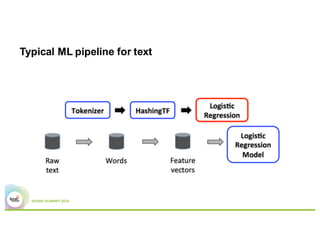
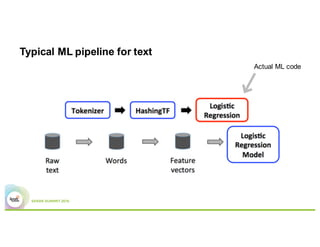
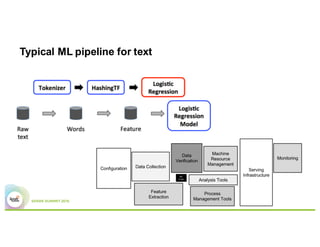
- A typical machine learning pipeline for text classification in Spark involves tokenization, feature extraction (e.g. hashing), and a classifier like logistic regression.
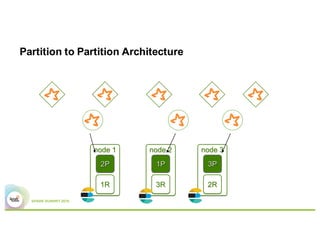
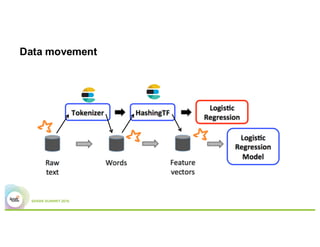
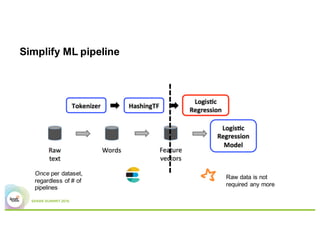
- The presentation proposes preparing text analysis specifications in Elasticsearch once and reusing them across multiple Spark pipelines to simplify the workflows and avoid data movement between systems

























![Elasticsearch as a DataFrame
val df = sql.read.format(“es").load("buckethead/albums")
df.filter(df("category").equalTo("pikes").and(df("year").geq(2015)))
{ "query" :
{ "bool" : { "must" : [
"match" : { "category" : "pikes" }
],
"filter" : [
{ "range" : { "year" : {"gte" : "2015" }}}
]
}}}](https://image.slidesharecdn.com/3icostinleau-160614190230/85/Elasticsearch-And-Apache-Lucene-For-Apache-Spark-And-MLlib-38-320.jpg)







![Work once – reuse multiple times
// prepare the spec for vectorize – fast and lightweight
val spec = s"""{ "features" : [{
| "field": "text",
| "type" : "string",
| "tokens" : "all_terms",
| "number" : "occurrence",
| "min_doc_freq" : 2000
| }],
| "sparse" : "true"}""".stripMargin
ML.prepareSpec(spec, “my-spec”)](https://image.slidesharecdn.com/3icostinleau-160614190230/85/Elasticsearch-And-Apache-Lucene-For-Apache-Spark-And-MLlib-51-320.jpg)


![Need to adjust the model? Change the spec
val spec = s"""{ "features" : [{
| "field": "text",
| "type" : "string",
| "tokens" : "given",
| "number" : "tf",
| "terms": ["term1", "term2", ...]
| }],
| "sparse" : "true"}""".stripMargin
ML.prepareSpec(spec)](https://image.slidesharecdn.com/3icostinleau-160614190230/85/Elasticsearch-And-Apache-Lucene-For-Apache-Spark-And-MLlib-55-320.jpg)






















































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)



