This document discusses using Distributed Tensorflow with Kubernetes for training neural networks. It covers:
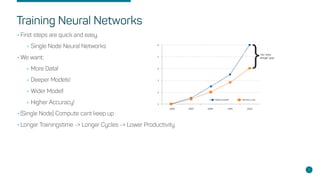
- The need for distributed training to handle large datasets, deep models, and high accuracy requirements.
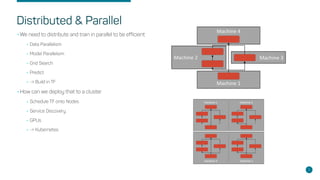
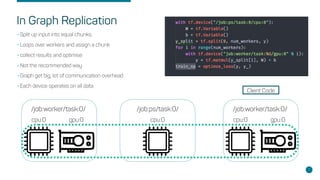
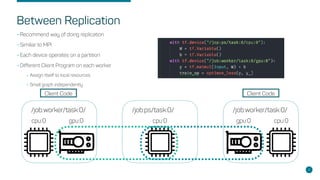
- Kubernetes as an orchestration tool for scheduling Tensorflow across nodes with GPUs.
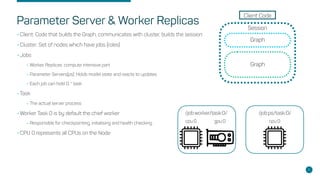
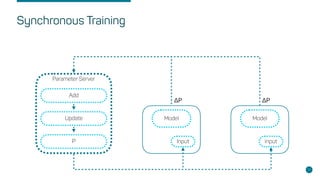
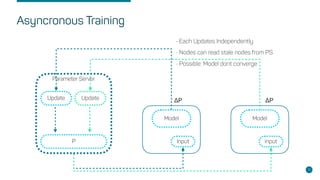
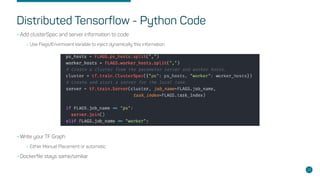
- Key concepts like parameter servers, worker replicas, and synchronous/asynchronous training modes.
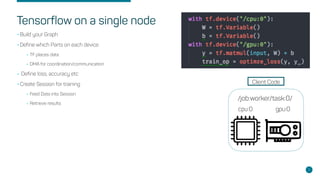
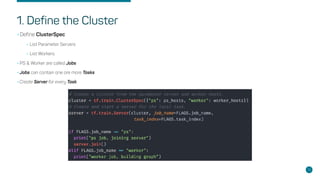
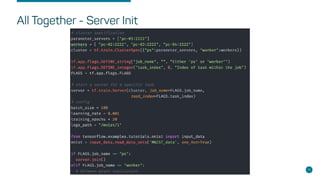
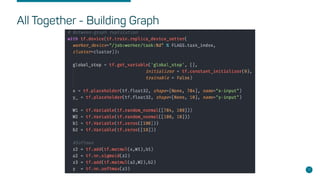
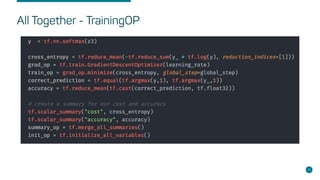
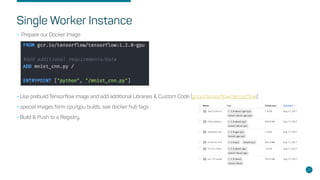
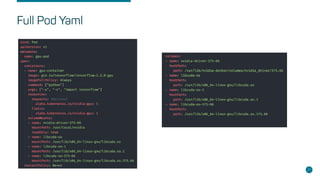
- Steps for setting up distributed Tensorflow jobs on Kubernetes including defining the cluster, assigning operations, creating training sessions, and packaging into containers.
- Considerations for enabling GPUs, building Docker images, writing deployments, and automating with tools like the Tensorflow Operator.






















![[Lakmal] Automate Microservice to API](https://cdn.slidesharecdn.com/ss_thumbnails/lakmalautomatemicroservicetoapi-210512215049-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)


























































