Download as PDF, PPTX







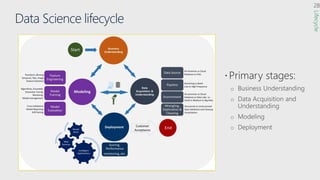


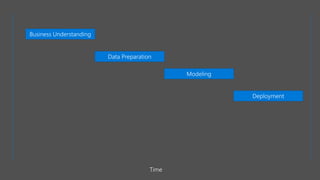
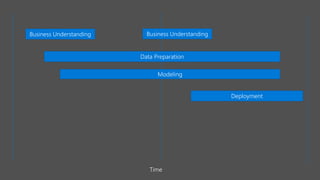




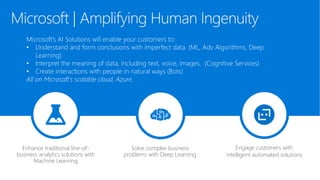


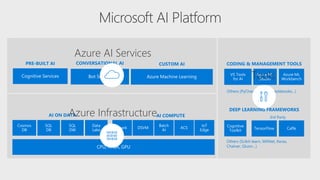


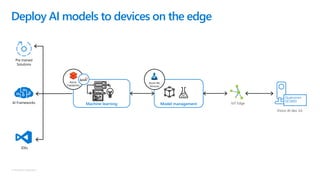
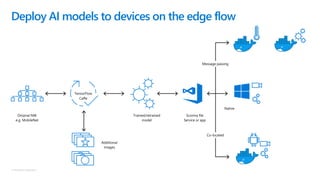
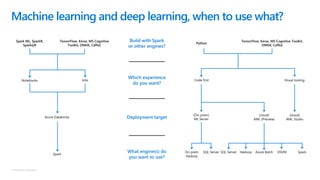





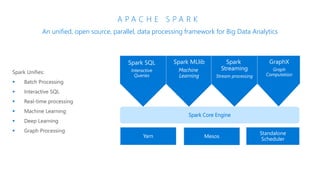




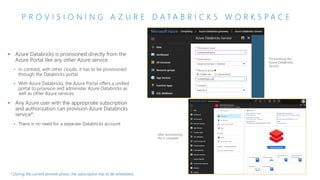
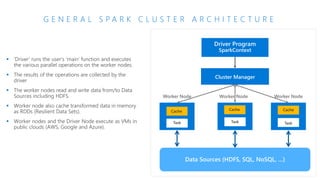
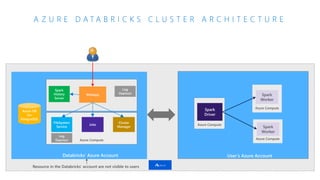
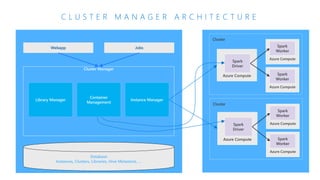









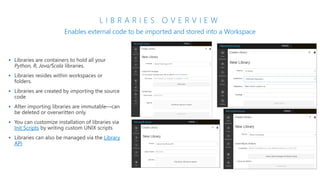

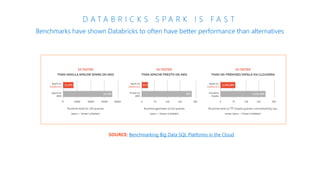

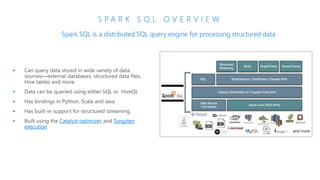
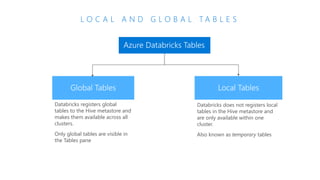
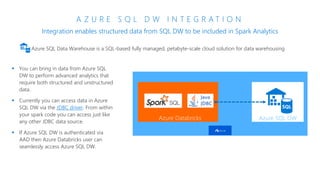
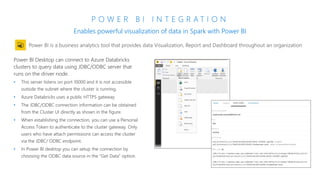






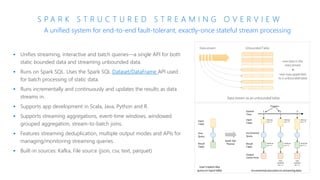


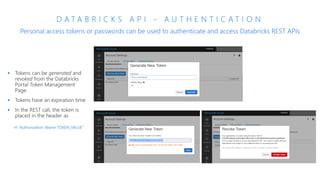






The document discusses the current state and challenges of data science in enterprises, noting that while many organizations plan to implement advanced analytics programs, a significant number of big data projects are unsuccessful. It highlights various tools and platforms, particularly focusing on Azure's offerings such as Azure Databricks and Azure ML, for seamless machine learning and big data analytics. Additionally, the document emphasizes the importance of collaboration and diverse skills in optimizing data science practices within organizations.















































![[第35回 Machine Learning 15minutes!] Microsoft AI Updates](https://cdn.slidesharecdn.com/ss_thumbnails/20190427ml15minmicrosoftai-190427060706-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)

