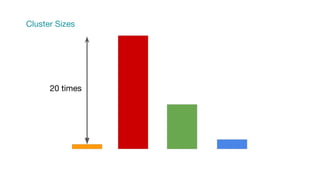
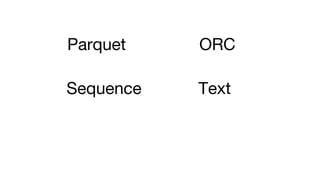
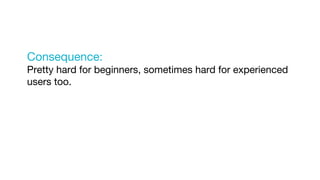
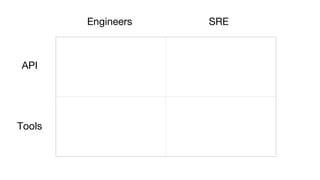
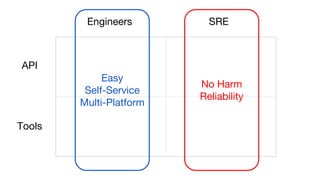
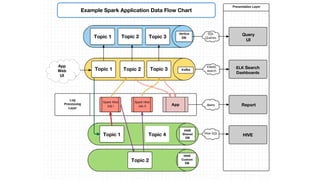
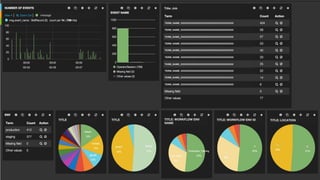
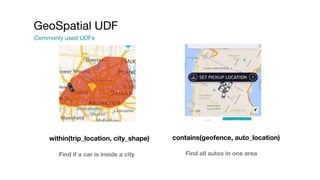
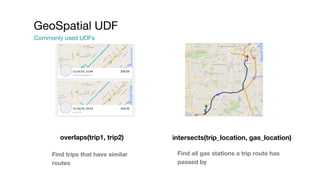
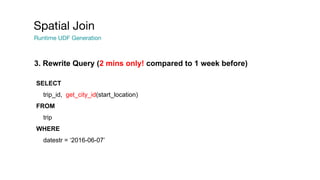
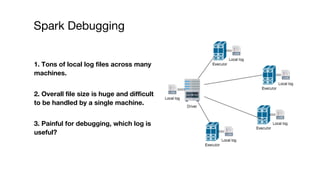
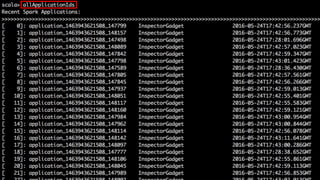
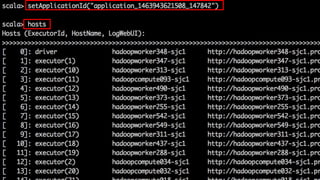
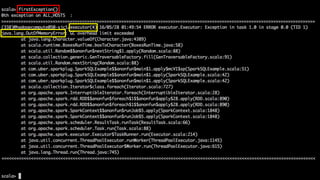
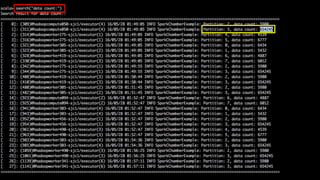
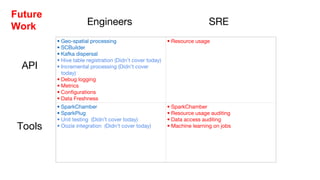
This document summarizes a presentation given at Spark Summit 2016 about tools and techniques used at Uber for Spark development and jobs. It introduces SCBuilder for encapsulating cluster environments, Kafka dispersal for publishing RDD results to Kafka, and SparkPlug for kickstarting job development with templates. It also discusses SparkChamber for distributed log debugging and future work including analytics, machine learning, and resource usage auditing.