クルマで想定されるスペック
4
クラウド エッジ
Many classes (1000s) Few classes(<10)
Large workloads Frame rates (15‐30 FPS)
High efficiency
(Performance/W)
Low cost & low power
(1W‐5W)
Server form factor Custom form factor
J. Freeman (Intel), “FPGA Acceleration in the era of high level design”, 2017
Artificial Neuron (AN)
+
x0=1
x1
x2
xN
...w0 (Bias)
w1
w2
wN
f(u)
u y
xi: Input signal
wi: Weight
u: Internal state
f(u): Activation function
(Sigmoid, ReLU, etc.)
y: Output signal
y f (u)
u wi xi
i0
N
9
• Normalizing theresult
of MAC operations
• Batch normalization is
necessary for the
Binarized CNN to
improve its accracy
20
Normalization for Binarized DNN
Batch
Norm
0
20
40
60
80
100
1 80 160 200
Error rate[%]
epoch
Without BN
With BN
H. Nakahara, H. Yonekawa, T. Sasao, H. Iwamoto,
and M. Motomura, "A Memory‐Based Realization
of a Binarized Deep Convolutional Neural
Network," The International Conference on Field‐
Programmable Technology (FPT 2016), pp.273‐76,
2016.
mean
variance
Scaling Shift
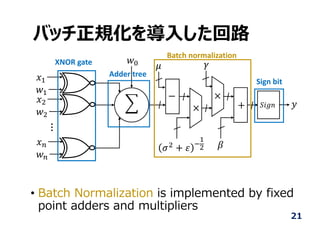
21.
• Batch Normalizationis implemented by fixed
point adders and multipliers
21
バッチ正規化を導⼊した回路
Adder tree
Batch normalization
Sign bit
XNOR gate
22.
• The outputfrom batch
normalization( ) is the
input to sign function
Constant factor can
be ignored
• The input from batch
normalization( ) is the
integer value
To integer
22
バッチ正規化をバイアスで実現




















![• Normalizing the result
of MAC operations
• Batch normalization is
necessary for the
Binarized CNN to
improve its accracy
20
Normalization for Binarized DNN
Batch
Norm
0
20
40
60
80
100
1 80 160 200
Error rate[%]
epoch
Without BN
With BN
H. Nakahara, H. Yonekawa, T. Sasao, H. Iwamoto,
and M. Motomura, "A Memory‐Based Realization
of a Binarized Deep Convolutional Neural
Network," The International Conference on Field‐
Programmable Technology (FPT 2016), pp.273‐76,
2016.
mean
variance
Scaling Shift](https://image.slidesharecdn.com/reconf2017guinness-170926023938/85/Reconf-2017GUINNESS-20-320.jpg)






![モデルサイズの⽐較
29
Layer
Baseline Proposed
Dim.
In F
maps
Out F
maps
Weight
[bits]
Dim.
In F
maps
Out F
maps
Weight[bi
ts]
Iconv 32x32 3 64 1.7K 32x32 3 64 1.7K
Bconv 32x32 64 64 36.8K 32x32 64 64 36.8K
Max Pool 16x16 64 64 16x16 64 64
Bconv 16x16 64 128 73.7K 16x16 64 128 73.7K
Bconv 16x16 128 128 147.4K 16x16 128 128 147.4K
Max Pool 8x8 128 128 8x8 128 128
Bconv 8x8 128 256 294.9K 8x8 128 256 294.9K
Bconv 8x8 256 256 589.8K 8x8 256 256 589.8K
Max Pool 4x4 256 256 4x4 256 256
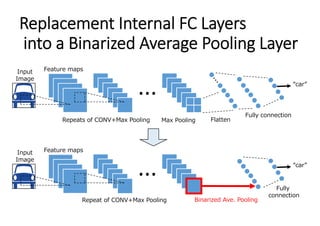
BFC 1x1 4096 4096 16.7M
(Binarized Average Pooling)
BFC 1x1 4096 4096 16.7M
BFC 1x1 4096 10 40.9K 1x1 256 10 2.5K
(fc total) (33.6M) (2.5K)
Total 34.7M 1.5M
Error Rate 18.6% 18.2%](https://image.slidesharecdn.com/reconf2017guinness-170926023938/85/Reconf-2017GUINNESS-29-320.jpg)






![既存FPGA実現法との⽐較 36
Implementation
(Year)
Zhao et al. [1]
(2017)
FINN [2]
(2017)
Ours
FPGA Board
(FPGA)
Zedboard
(XC7Z020)
PYNQ board
(XC7Z020)
Zedboard
(XC7Z020)
Clock (MHz) 143 166 143
#LUTs
#18Kb BRAMs
#DSP Blocks
46900
94
3
42833
270
32
14509
32
1
Test Error 12.27% 19.90% 18.20%
Time [msec]
(FPS)
5.94
(168)
2.24
(445)
2.37
(420)
Power [W] 4.7 2.5 2.3
FPS/Watt
FPS/LUT
FPS/BRAM
35.7
35.8x10‐4
1.8
178.0
103.9x10‐4
1.6
182.6
289.4x10‐4
13.1
Y. Umuroglu, et al., “FINN: A Framework for Fast, Scalable Binarized Neural Network Inference,” ISFPGA, 2017.
R. Zhao et al., “Accelerating Binarized Convolutional Neural Networks with Software‐Programmable FPGAs,” ISFPGA, 2017.](https://image.slidesharecdn.com/reconf2017guinness-170926023938/85/Reconf-2017GUINNESS-36-320.jpg)
![Comparison with Embedded
Platforms (VGG11 Forwarding)
Platform CPU GPU FPGA
Device
ARM Cortex‐A57 Maxwell GPU Zynq7020
Clock Freq. 1.9 GHz 998 MHz 143.78 MHz
Memory 16 GB eMMC Flash 4 GB LPDDR4 4.9 Mb BRAM
Time [msec]
(FPS)
4210.0
(0.23)
27.23
(36.7)
2.37
(421.9)
Power [W] 7 17 2.3
Efficiency 0.032 2.2 182.6
Design Time [Hours] 72 72 75](https://image.slidesharecdn.com/reconf2017guinness-170926023938/85/Reconf-2017GUINNESS-37-320.jpg)















![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)
















