Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
marsee101
5,819 views
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
「ゼロから作るDeep learning」の畳み込みニューラルネットワークを使用してFPGAで実装しました。
Technology
◦
Read more
11
Save
Share
Embed
Embed presentation
1
/ 63
2
/ 63
3
/ 63
4
/ 63
5
/ 63
6
/ 63
7
/ 63
8
/ 63
9
/ 63
10
/ 63
11
/ 63
12
/ 63
13
/ 63
14
/ 63
15
/ 63
16
/ 63
17
/ 63
18
/ 63
19
/ 63
20
/ 63
21
/ 63
22
/ 63
23
/ 63
24
/ 63
25
/ 63
26
/ 63
27
/ 63
28
/ 63
29
/ 63
30
/ 63
31
/ 63
32
/ 63
33
/ 63
34
/ 63
35
/ 63
36
/ 63
37
/ 63
38
/ 63
39
/ 63
40
/ 63
41
/ 63
42
/ 63
43
/ 63
44
/ 63
45
/ 63
46
/ 63
47
/ 63
48
/ 63
49
/ 63
50
/ 63
51
/ 63
52
/ 63
53
/ 63
54
/ 63
55
/ 63
56
/ 63
57
/ 63
58
/ 63
59
/ 63
60
/ 63
61
/ 63
62
/ 63
63
/ 63
More Related Content
PDF
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
PPTX
機械学習 / Deep Learning 大全 (1) 機械学習基礎編
by
Daiyu Hatakeyama
PDF
グラフニューラルネットワークとグラフ組合せ問題
by
joisino
PPTX
【DL輪読会】Factory: Fast Contact for Robotic Assembly
by
Deep Learning JP
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PPTX
Graph Neural Networks
by
tm1966
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
機械学習 / Deep Learning 大全 (1) 機械学習基礎編
by
Daiyu Hatakeyama
グラフニューラルネットワークとグラフ組合せ問題
by
joisino
【DL輪読会】Factory: Fast Contact for Robotic Assembly
by
Deep Learning JP
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
Graph Neural Networks
by
tm1966
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
What's hot
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
PDF
SSII2022 [OS3-04] Human-in-the-Loop 機械学習
by
SSII
PDF
これから始める人の為のディープラーニング基礎講座
by
NVIDIA Japan
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
グラフデータ分析 入門編
by
順也 山口
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PDF
Sift特徴量について
by
la_flance
PPTX
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
PDF
FeUdal Networks for Hierarchical Reinforcement Learning
by
佑 甲野
PPTX
[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
by
Deep Learning JP
PDF
【メタサーベイ】Transformerから基盤モデルまでの流れ / From Transformer to Foundation Models
by
cvpaper. challenge
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
深層学習の判断根拠を理解するための 研究とその意義 @PRMU 2017熊本
by
Takahiro Kubo
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
PDF
[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...
by
Deep Learning JP
PDF
Transformer 動向調査 in 画像認識(修正版)
by
Kazuki Maeno
GAN(と強化学習との関係)
by
Masahiro Suzuki
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
SSII2022 [OS3-04] Human-in-the-Loop 機械学習
by
SSII
これから始める人の為のディープラーニング基礎講座
by
NVIDIA Japan
Attentionの基礎からTransformerの入門まで
by
AGIRobots
グラフデータ分析 入門編
by
順也 山口
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
Sift特徴量について
by
la_flance
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
FeUdal Networks for Hierarchical Reinforcement Learning
by
佑 甲野
[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
by
Deep Learning JP
【メタサーベイ】Transformerから基盤モデルまでの流れ / From Transformer to Foundation Models
by
cvpaper. challenge
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
深層学習の判断根拠を理解するための 研究とその意義 @PRMU 2017熊本
by
Takahiro Kubo
報酬設計と逆強化学習
by
Yusuke Nakata
[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...
by
Deep Learning JP
Transformer 動向調査 in 画像認識(修正版)
by
Kazuki Maeno
Similar to 「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PPTX
LUT-Network Revision2
by
ryuz88
PDF
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
ハンズオン セッション 3: リカレント ニューラル ネットワーク入門
by
NVIDIA Japan
PPTX
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
PPTX
LUT-Network ~本物のリアルタイムコンピューティングを目指して~
by
ryuz88
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PDF
MANABIYA Machine Learning Hands-On
by
陽平 山口
PDF
[第2版]Python機械学習プログラミング 第15章
by
Haruki Eguchi
PPT
Deep Learningの技術と未来
by
Seiya Tokui
PDF
(公開版)Reconf研2017GUINNESS
by
Hiroki Nakahara
PDF
Tensor flow usergroup 2016 (公開版)
by
Hiroki Nakahara
PDF
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
PPTX
Deep Learningについて(改訂版)
by
Brains Consulting, Inc.
PPTX
ディープラーニングハンズオン・レクチャー資料
by
Yoshihiro Ochi
PPTX
機械学習 / Deep Learning 大全 (6) Library編
by
Daiyu Hatakeyama
PPTX
深層学習とTensorFlow入門
by
tak9029
PDF
[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...
by
Deep Learning JP
PDF
Enjoy handwritten digits recognition AI !!
by
KAIKenzo
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
LUT-Network Revision2
by
ryuz88
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
Deep Learningの基礎と応用
by
Seiya Tokui
ハンズオン セッション 3: リカレント ニューラル ネットワーク入門
by
NVIDIA Japan
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
LUT-Network ~本物のリアルタイムコンピューティングを目指して~
by
ryuz88
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
MANABIYA Machine Learning Hands-On
by
陽平 山口
[第2版]Python機械学習プログラミング 第15章
by
Haruki Eguchi
Deep Learningの技術と未来
by
Seiya Tokui
(公開版)Reconf研2017GUINNESS
by
Hiroki Nakahara
Tensor flow usergroup 2016 (公開版)
by
Hiroki Nakahara
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
Deep Learningについて(改訂版)
by
Brains Consulting, Inc.
ディープラーニングハンズオン・レクチャー資料
by
Yoshihiro Ochi
機械学習 / Deep Learning 大全 (6) Library編
by
Daiyu Hatakeyama
深層学習とTensorFlow入門
by
tak9029
[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...
by
Deep Learning JP
Enjoy handwritten digits recognition AI !!
by
KAIKenzo
More from marsee101
PDF
Robot car gabor_filter
by
marsee101
PDF
Ultra96 pmod expansion board
by
marsee101
PDF
Camera input from_ultra_96's_slow_expansion_connector
by
marsee101
PDF
Fpga robot car
by
marsee101
PDF
FPGAスタートアップ資料
by
marsee101
PDF
Fpgaでの非同期信号の扱い方とvivadoによるサポート(公開用)
by
marsee101
PDF
Pynqでカメラ画像をリアルタイムfastx コーナー検出
by
marsee101
PDF
高位合成ツールVivado hlsのopen cv対応
by
marsee101
PDF
SDSoC勉強会_170128_スライド「SDx 2016.3のプラグマによるハードウェアと性能」
by
marsee101
PDF
FPGAの部屋、slide share、xilinxツールのご紹介
by
marsee101
PDF
Vivado hlsのシミュレーションとhlsストリーム
by
marsee101
ODP
MPSoCのPLの性能について
by
marsee101
PDF
Vivado hls勉強会5(axi4 stream)
by
marsee101
PDF
Vivado hls勉強会4(axi4 master)
by
marsee101
PDF
Vivado hls勉強会3(axi4 lite slave)
by
marsee101
PDF
Vivado hls勉強会2(レジスタの挿入とpipelineディレクティブ)
by
marsee101
PDF
Vivado hls勉強会1(基礎編)
by
marsee101
PPTX
Ubuntuをインストールしたzyboボードにカメラを付けてopen cvで顔認識
by
marsee101
PPTX
ラプラシアンフィルタをZedBoardで実装(ソフトウェアからハードウェアにオフロード)
by
marsee101
Robot car gabor_filter
by
marsee101
Ultra96 pmod expansion board
by
marsee101
Camera input from_ultra_96's_slow_expansion_connector
by
marsee101
Fpga robot car
by
marsee101
FPGAスタートアップ資料
by
marsee101
Fpgaでの非同期信号の扱い方とvivadoによるサポート(公開用)
by
marsee101
Pynqでカメラ画像をリアルタイムfastx コーナー検出
by
marsee101
高位合成ツールVivado hlsのopen cv対応
by
marsee101
SDSoC勉強会_170128_スライド「SDx 2016.3のプラグマによるハードウェアと性能」
by
marsee101
FPGAの部屋、slide share、xilinxツールのご紹介
by
marsee101
Vivado hlsのシミュレーションとhlsストリーム
by
marsee101
MPSoCのPLの性能について
by
marsee101
Vivado hls勉強会5(axi4 stream)
by
marsee101
Vivado hls勉強会4(axi4 master)
by
marsee101
Vivado hls勉強会3(axi4 lite slave)
by
marsee101
Vivado hls勉強会2(レジスタの挿入とpipelineディレクティブ)
by
marsee101
Vivado hls勉強会1(基礎編)
by
marsee101
Ubuntuをインストールしたzyboボードにカメラを付けてopen cvで顔認識
by
marsee101
ラプラシアンフィルタをZedBoardで実装(ソフトウェアからハードウェアにオフロード)
by
marsee101
Recently uploaded
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
1.
1 「ゼロから作る Deep Learning
」 の畳み込みニューラルネットワー クのハードウェア化 marsee こと小野雅晃 数学が苦手で自分で 1 から DNN を実装できない人のための フレームワークの例
2.
2 自己紹介 ● 大学の技術職員 ● 定年間近 ●
朝起きてブログ書いています( 3 時から 4 時ころ) ● 最近 FPGA の話題が少なくて寂しい。。。 ● ニューラルネットワークの話題が多い
3.
3 ニューラルネットワークとは? ● 脳の神経回路を模した回路 – 樹状突起とシナプス 樹状突起 シナプス 七田チャイルドアカデミー 「脳のしくみ」
できる人って ? にインスパイアされました
4.
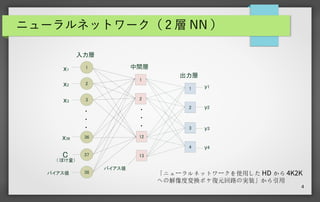
4 ニューラルネットワーク( 2 層
NN ) 1 2 3 36 37 38 1 2 12 13 x1 x2 x3 x36 C ( ぼけ量) バイアス値 バイアス値 1 2 3 4 y1 y2 y3 y4 入力層 中間層 出力層 「ニューラルネットワークを使用した HD から 4K2K への解像度変換ボケ復元回路の実装」から引用
5.
5 ニューラルネットワークの推論をハードウェア化 ● 2 層ニューラルネットワーク
(NN) はハードウェア化したこと あり – ニューラルネットワークを使用した HD から 4K2K への解 像度変換ボケ復元回路の実装( 2015 年 3 月発表) – http://www.tech.tsukuba.ac.jp/2014/report2014/report03 .pdf – HD から 4K2K へボケを復元しながら超解像度変換 – 6x6 入力 NN は 1 クロック (148.5MHz) で 4 ピクセル出力 – NN 推論の乗算をシフト+加算で実行。 DSP を使用しない – 重みを入れると VHDL を出力する自作 Ruby スクリプトで NN の VHDL を生成
6.
6 解像度変換ボケ復元システム全体 「ニューラルネットワ ークを使用した HD か ら
4K2K への解像度変 換ボケ復元回路の実 装」から引用
7.
7 FPGA ボード 「ニューラルネットワ ークを使用した HD
か ら 4K2K への解像度変 換ボケ復元回路の実 装」から引用
8.
8 解度変換ボケ復元用 FPGA 回路 「ニューラルネットワークを使用 した
HD から 4K2K への解像度変 換ボケ復元回路の実装」から引用 AXI Interconnect HDMI Input Module (Neural Network x4 output) AXI4 Master Write 160MHz HDMI INPUT HDMI Output Module HDMI OUTPUT0 DDR3 SDRAM Controller (MIG) AXI4 Master Read/Write 200MHz 512bits MicroBlaze (CPU) AXI Interconnect Serial InterfaceGPIO ボケ量の 設定 HDMI Output Module HDMI OUTPUT1 HDMI Output Module HDMI OUTPUT2 HDMI Output Module AXI4 Master Read 64bits 160MHz HDMI OUTPUT3 64bits or 128bits 64bits or 128bits DDR3 SDRAM (DDR3-1600) 64bits 800MHz AXI4 Master Read 64bits 160MHz AXI4 Master Read 64bits 160MHz AXI4 Master Read 64bits 160MHz HD 148.5MHz HD 148.5MHz HD 148.5MHz HD 148.5MHz HD 148.5MHz FPGA (XC7K325T-2FFG900)MicroBlaze回路 TB-FMCH-HDMI2 RX Board TB-FMCH-HDMI2 TX Board TB-FMCH-HDMI2 TX Board TB-7K-325T-IMG FMC Connector FMC Connector FMC Connector
9.
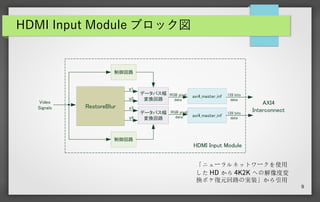
9 HDMI Input Module
ブロック図 RestoreBlur データバス幅 変換回路 データバス幅 変換回路 y1 y2 y3 y4 axi4_master_inf axi4_master_inf RGB pixel data RGB pixel data 128 bits data 128 bits data AXI4 Interconnect Video Signals 制御回路 制御回路 HDMI Input Module 「ニューラルネットワークを使用 した HD から 4K2K への解像度変 換ボケ復元回路の実装」から引用
10.
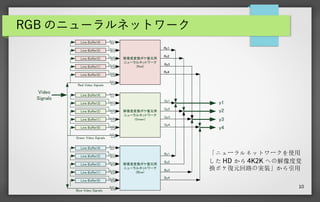
10 RGB のニューラルネットワーク Line Buffer(3) Line
Buffer(2) Line Buffer(1) Line Buffer(0) Line Buffer(4) 解像度変換ボケ復元用 ニューラルネットワーク (Red) Ry1 Ry2 Ry3 Ry4 Line Buffer(3) Line Buffer(2) Line Buffer(1) Line Buffer(0) Line Buffer(4) 解像度変換ボケ復元用 ニューラルネットワーク (Green) Gy1 Gy2 Gy3 Gy4 Line Buffer(3) Line Buffer(2) Line Buffer(1) Line Buffer(0) Line Buffer(4) 解像度変換ボケ復元用 ニューラルネットワーク (Blue) By1 By2 By3 By4 Red Video Signals Green Video Signals Blue Video Signals Video Signals y1 y2 y3 y4 Rx1~ Rx6 Rx7~ Rx12 Rx13~ Rx18 Rx19~ Rx24 Rx25~ Rx30 Rx31~ Rx36 Gx1~ Gx6 Gx7~ Gx12 Gx13~ Gx18 Gx19~ Gx24 Gx25~ Gx30 Gx31~ Gx36 Bx1~ Bx6 Bx7~ Bx12 Bx13~ Bx18 Bx19~ Bx24 Bx25~ Bx30 Bx31~ Bx36 「ニューラルネットワークを使用 した HD から 4K2K への解像度変 換ボケ復元回路の実装」から引用
11.
11 ニューラルネットワークの学習は? ● 推論はハードウェア化もした ● 学習は本読んでも良くわからない ●
自分で実装できるレベルに。。。 ● なんといっても数式ばかりで良くわからない ● 困った。。。 ● そんなとき見つけた本 ● 「ゼロから作る Deep Learning 」 ● オライリーから出ている本 オライリー・ジャパン 「ゼロから作 る Deep Learning 」の表紙を引 用
12.
12 ●「ゼロから作る Deep Learning
」 ● とっても良い本 ● Python ベース、 C に比べてコードが少なくて済む ● Python 入門から書かれている ● Python コードが公開されていて、 MIT ライセンスで商用 OK ● Python がとってもわかりやすい ● PDF 版を買えば普通にコピペができる ● CONV 、 Afne 、 RELU 、 SoftMax などの各層に forward() と backwar() の関数がある ● 各層を接続していけば、 forward() (推論)と backward() (損失関 数の勾配)が連結される
13.
13 ●「ゼロから作る Deep Learning
」の目次 ● 第 1 章 Python 入門 ● 第 2 章 パーセプトロン ● 第 3 章 ニューラルネットワーク ● 第 4 章 ニューラルネットワークの学習 ● 第 5 章 誤差逆伝搬法 ● 第 6 章 学習に関するテクニック ● 第 7 章 畳み込みニューラルネットワーク ● 第 8 章 ディープラーニング
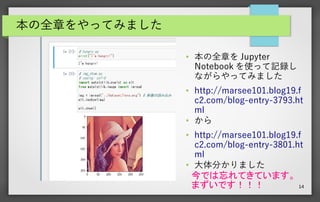
14.
14 本の全章をやってみました ● 本の全章を Jupyter Notebook
を使って記録し ながらやってみました ● http://marsee101.blog19.f c2.com/blog-entry-3793.ht ml ● から ● http://marsee101.blog19.f c2.com/blog-entry-3801.ht ml ● 大体分かりました 今では忘れてきています。 まずいです!!!
15.
15 3 層ニューラルネットワーク(推論) X0 X1 X2 X3 X4 y0 y1 第1層目 第2層目
第3層目 内積→活性化関数 forward()
16.
16 ニューラルネットワークの学習 ● 誤差逆伝搬法での学習 ● 重みとバイアスを調整して訓練データで正解が出るようするー学習 ● 学習方法(「ゼロから作る Deep Learning
」の 157 ページより引用) – ステップ 1 (ミニバッチ) ● 訓練データの中からランダムに一部のデータを選び出す – ステップ 2 (勾配の算出) ● 各重みパラメータに関する損失関数の勾配を求める – ステップ 3 (パラメータの更新) ● 重みパラメータを勾配方向に微小量だけ更新する – ステップ 4 (繰り返す) ● ステップ 1 、ステップ 2 、ステップ 3 を繰り返す
17.
17 2 層ニューラルネットワーク ● 第
5 章誤差逆伝搬法の 2 層ニューラルネットワークの Python コード を改造してハードウェア化することにした ● MNIST の手書き数字認識用のニューラルネットワーク( 784 入力 ( 28x28 )、 0 ~ 9 までの数字の 10 出力) ● 第 5 章誤差逆伝搬法の 2 層ニューラルネットワークの構成 – 全結合層(隠れ層 50 出力) – ReLU – 全結合層( 10 出力) – Softmax
18.
18 ハードウェア化への第 1 歩(量子化) ●
第 5 章誤差逆伝搬法の 2 層ニューラルネットワークの Python コードを改造し てハードウェア化 ● 学習はそのまま浮動小数点演算で学習 ● 推論のみ 重みとバイアス、層の出力を量子化 ● 量子化方法( forward_int() ) – 量子化ビット分を掛け算( float 型) – 四捨五入して int 型に変換し、小数点以下切り捨て – 量子化ビット長で飽和演算 – float 型に変換 – 掛け算した分を割り算して戻す( float )
19.
19 重みとバイアスの量子化コード MAGNIFICATION = 2
** (9-1) RANGE = 2 ** 4 class Affne: def __fnft__(self, W, b): self.W =W self.b = b self.x = None self.orfgfnal_x_shape = None # 重み バイアスパラメータの微分・ self.dW = None self.db = None self.bw=MAGNIFICATION def forward_fnt(self, x): # テンソル対応 self.orfgfnal_x_shape = x.shape x = x.reshape(x.shape[0], -1) self.x = x self.W = np.array(self.W*self.bw+0.5, dtype=fnt) self.b = np.array(self.b*self.bw+0.5, dtype=fnt) for f fn range(self.W.shape[0]): for j fn range(self.W.shape[1]): ff (self.W[f][j] > self.bw-1): self.W[f][j] = self.bw-1 elff (self.W[f][j] < -self.bw): self.W[f][j] = -self.bw; for f fn range(self.b.shape[0]): ff (self.b[f] > self.bw-1): self.b[f] = self.bw-1 elff (self.b[f] < -self.bw): self.b[f] = -self.bw self.W = np.array(self.W, dtype=float) self.b = np.array(self.b, dtype=float) self.W = self.W/self.bw self.b = self.b/self.bw out = np.dot(self.x, self.W) + self.b 「ゼロから作る Deep Learning 」の Python コードを変更 掛け算 INT に変換 飽和演算 掛け算した分を 割り算で戻す FLOAT に変換
20.
20 出力の量子化 out = np.array(out*self.bw+0.5,
dtype=fnt) for f fn range(out.shape[0]): for j fn range(out.shape[1]): ff (out[f][j] > self.bw*RANGE-1): out[f][j] = self.bw*RANGE-1 elff (out[f][j] < -self.bw*RANGE): out[f][j] = -self.bw*RANGE out = np.array(out, dtype=float) out = out/self.bw return out 掛け算 INT に変換 飽和演算 FLOAT に変換 掛け算した分を割 り算で戻す ● 重みは正規化されているので、 -1 ~ 1 、 9 ビットに量子化 ● 出力は符号 1 ビット、整数部 4 ビット、小数部 9 ビットの計 13 ビットに 量子化
21.
21 精度の比較 ● 浮動小数点数の推論の精度と量子化したときの精度を比較( Python コードを使用) ●
テスト・データを推論したときの精度 – 浮動小数点数で推論 ー 96.9 % – 量子化したときの精度 ー 96.4 % ● 量子化したときの方が少し精度が下がっているが十分に許容範囲内 ● この量子化で行くことにした
22.
22 Vivado HLS で実装するための準備 ● トレーニングによって生成された重みを
C のヘッダファイルに変換 ● Python コードで実装した ● 第一層目の全結合層の重みとバイアス – af1_weight.h – af1_bias.h ● 第 2 層目の全結合層の重みとバイアス – af2_weight.h – af2_bias.h ● ヘッダファイル内には浮動小数点数の配列と固定小数点数の配列 – const float af1_fweight[784][50]; – const ap_fxed<9, 1, AP_TRN_ZERO, AP_SAT> af1_weight[784][50];
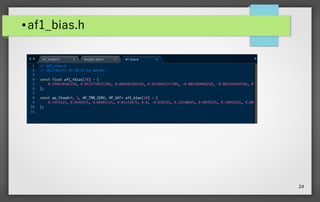
23.
23 ● af1_weight.h
24.
24 ● af1_bias.h
25.
25 ● af2_weight.h
26.
26 af2_bias.h
27.
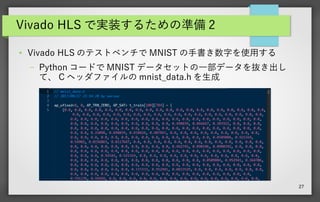
27 Vivado HLS で実装するための準備
2 ● Vivado HLS のテストベンチで MNIST の手書き数字を使用する – Python コードで MNIST データセットの一部データを抜き出し て、 C ヘッダファイルの mnist_data.h を生成
28.
28 ニューラルネットワークの C ソースコード ● af1_dot1:
for(int col=0; col<50; col++){ ● dot1[col] = 0; ● af1_dot2: for(int row=0; row<784; row++){ ● dot1[col] += buf[row]*af1_weight[row][col]; ● } ● dot1[col] += af1_bias[col]; ● ● if(dot1[col] < 0) // ReLU ● dot1[col] = 0; ● } ● ● af2_dot1: for(int col=0; col<10; col++){ ● dot2[col] = 0; ● af2_dot2: for(int row=0; row<50; row++){ ● dot2[col] += dot1[row]*af2_weight[row][col]; ● } ● dot2[col] += af2_bias[col]; ● out[col] = dot2[col]; ● } ● 最後の softmax 関数は無し ● 実装が難しいし、 10 出力 の max 値を検出するれば手 書き数字の判定はできる ● ap_fxed は Vivado HLS の 任意精度固定小数点データ 型 ap_ffxed<13, 5, AP_TRN_ZERO, AP_SAT> dot1[50]; ap_ffxed<13, 5, AP_TRN_ZERO, AP_SAT> dot2[10];
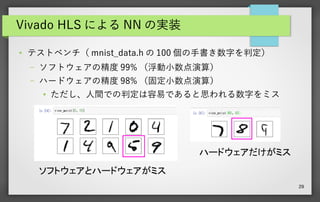
29.
29 Vivado HLS による
NN の実装 ● テストベンチ( mnist_data.h の 100 個の手書き数字を判定) – ソフトウェアの精度 99% (浮動小数点演算) – ハードウェアの精度 98% (固定小数点演算) ● ただし、人間での判定は容易であると思われる数字をミス ソフトウェアとハードウェアがミス ハードウェアだけがミス
30.
30 Vivado HLS による
C コードの合成結果 (2017.1) ● 使用する Zynq は PYNQ ボードの xc7x020clg400-1 ● Latency は 2.79ms ( 100MHz クロック) ● リソース使用量は BRAM が 38 個、 DSP48E が 1 個
31.
31 畳み込みニューラルネットワーク ● 畳み込み層とプーリング層が増えている ● 畳み込み層は形状の特徴を捉えることができる可能性 ●
プーリング層は画像を縮小して位置による変化に鈍感にする – 平均 – 最大値
32.
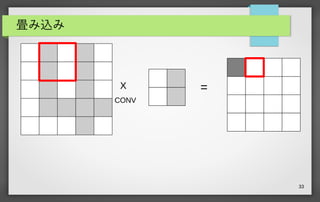
32 畳み込み X CONV = ● 5x5 の画像に 2x2
のカーネルを畳み込む例 ● 5x5 の画像の左上からカーネルをスライドさせながら要素同士 を掛けて合計する 5x5 の画像 2x2 のカーネル 出力0 1 2
33.
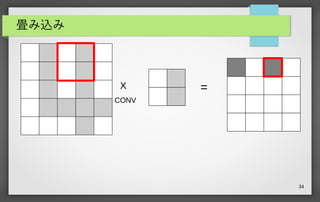
33 畳み込み X CONV =
34.
34 畳み込み X CONV =
35.
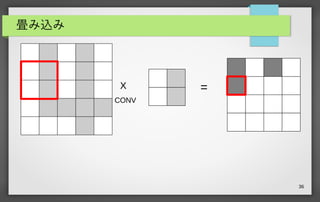
35 畳み込み X CONV =
36.
36 畳み込み X CONV =
37.
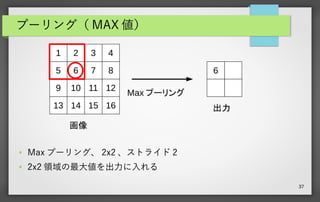
37 プーリング( MAX 値) ●
Max プーリング、 2x2 、ストライド 2 ● 2x2 領域の最大値を出力に入れる 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Max プーリング 画像 出力 6
38.
38 プーリング( MAX 値) 1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Max プーリング 画像 出力 6 8
39.
39 プーリング( MAX 値) 1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Max プーリング 画像 出力 6 8 14
40.
40 プーリング( MAX 値) 1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Max プーリング 画像 出力 6 8 14 16
41.
41 実装した畳み込みニューラルネットワーク ● MNIST の手書き数字認識用のニューラルネットワーク( 784
入力( 28x28 )、 0 ~ 9 までの数字の 10 出力) ● 畳み込み層(フィルタ数 10 、当初は 30 だったが PYNQ に入らなかったため変更) – カーネル 5x5 、パディングなし、ストライド 1 ● ReLU ● プーリング層 – 2x2 の Max プーリング、ストライド 2 ● 全結合層 ● ReLU ● 全結合層 ● SoftMax
42.
42 ハードウェア化への第 1 歩(量子化) ●
第 7 章畳み込みニューラルネットワークの畳み込みニューラルネットワークの Python コードを改造してハードウェア化 ● 学習はそのまま浮動小数点演算で学習 ● 推論のみ 重みとバイアス、層の出力を量子化 ● 量子化方法( forward_int() ) – 量子化ビット分を掛け算( float 型) – 四捨五入して int 型に変換し、小数点以下切り捨て – 量子化ビット長で飽和演算 – float 型に変換 – 掛け算した分を割り算で戻す( float )
43.
43 畳み込みニューラルネットワークを量子化 ● 2 層ニューラルネットワークと同様に量子化 ●
畳み込み層と全結合層の両方の演算のビット幅を設定
44.
44 畳み込みニューラルネットワークの精度を確認 ● 学習を行って精度を確認する – 精度は 98.69% ● 量子化したときの精度 –
量子化してないときと同じ 98.69% ● この量子化で OK ● 畳み込み層 – 演算ビット数 10 ビット、整数部 3 ビット ● 全結合層 – 演算ビット数 12 ビット、整数部 7 ビット ● 重み、バイアス – 演算ビット数 9 ビット、整数部 1 ビット
45.
45 Vivado HLS で実装するための準備 ● トレーニングによって生成された重みを
C のヘッダファイルに変換 ● Python コードで実装した ● 畳み込み層の重みとバイアス – conv1_weight.h – conv1_bias.h ● 最初の全結合層の重みとバイアス – af1_weight.h – af1_bias.h ● 二番目の全結合層の重みとバイアス – af2_weight.h – af2_bias.h ● 浮動小数点数の配列と固定小数点数の配列 – const float conv1_fweight[10][1][5][5]; – const ap_fxed<9, 1, AP_TRN_ZERO, AP_SAT> conv1_weight[10][1][5][5];
46.
46 畳み込みニューラルネットワークの C ソースコード ● CONV1:
for(int i=0; i<10; i++){ // カーネルの個 数 ● CONV2: for(int j=0; j<24; j++){ ● CONV3: for(int k=0; k<24; k++){ ● conv_out[i][j][k] = 0; ● CONV4: for(int m=0; m<5; m++){ ● CONV5: for(int n=0; n<5; n++){ ● conv_out[i][j][k] += buf[j+m][k+n] * conv1_weight[i][0][m][n]; ● } ● } ● conv_out[i][j][k] += conv1_bias[i]; ● ● if(conv_out[i][j][k]<0) // ReLU ● conv_out[i][j][k] = 0; ● } ● } ● } ● POOL1: for(int i=0; i<10; i++){ ● POOL2: for(int j=0; j<24; j += 2){ ● POOL3: for(int k=0; k<24; k += 2){ ● POOL4: for(int m=0; m<2; m++){ ● POOL5: for(int n=0; n<2; n++){ ● if(m==0 && n==0){ ● pool_out[i][j/2][k/2] = conv_out[i][j] [k]; ● } else if(pool_out[i][j/2][k/2] < conv_out[i][j+m][k+n]){ ● pool_out[i][j/2][k/2] = conv_out[i] [j+m][k+n]; ● } ● } ● } ● } ● } ● }
47.
47 CNN の Vivado
HLS による C シミュレーション ● 100 個の手書き数字のデータ (mnist_data.h) を使用して、何個間違う かをカウント ● ソフトウェア ー 1 個、ハードウェア ー 3 個 ● ソフトウェアに比べてハードウェアが間違いすぎか? ● 小数部分の桁が少ない全結合層のビット幅を 12 から 13 にしてみた ● ソフトウェア ー 1 個、ハードウェア ー 1 個
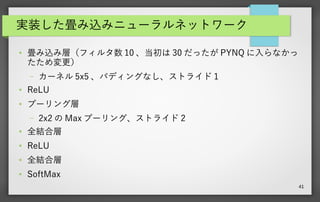
48.
48 CNN を合成( Vivado
HLS ) ● 使用する Zynq は PYNQ ボードの xc7x020clg400-1 ● Latency は 100 MHz クロックで、 17.2 ms ● リソース使用量を見ると BRAM_18K の使用が多い(重み、バイアス) ● チューニングをすると 6.91ms まで行った。 BRAM_18K が 59%
49.
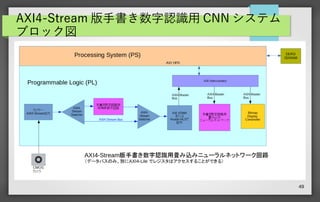
49 AXI4-Stream 版手書き数字認識用 CNN
システム ブロック図
50.
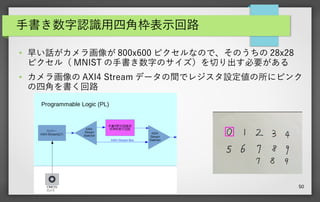
50 手書き数字認識用四角枠表示回路 ● 早い話がカメラ画像が 800x600
ピクセルなので、そのうちの 28x28 ピクセル( MNIST の手書き数字のサイズ)を切り出す必要がある ● カメラ画像の AXI4 Stream データの間でレジスタ設定値の所にピンク の四角を書く回路
51.
51 手書き数字認識用畳み込みニューラルネットワーク ● 手書き数字のある 28 行の画像を手書き数字認識用
CNN に渡す ● アドレス・オフセットも同時に指定する ● 手書き数字認識用 CNN は、 28x28 ピクセルの領域の手書き数字を認識する ● 合成したときのレイテンシは 12.8ms
52.
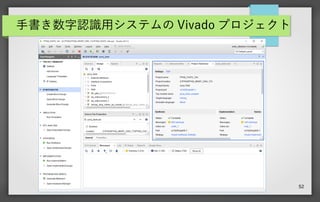
52 手書き数字認識用システムの Vivado プロジェクト
53.
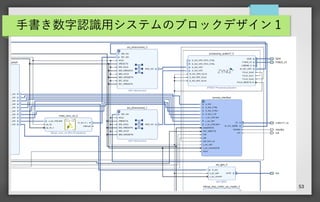
53 手書き数字認識用システムのブロックデザイン 1
54.
54 手書き数字認識用システムのブロックデザイン 2
55.
55 手書き数字認識用システムの合成結果
56.
56 SDK で制御用アプリケーションソフトを開発 ● SDK
でハードウェ アをたたいてハード ウェアを起動 ● FPGA に実装した畳 み込みニューラルネ ットワークで手書き 数字を判定 ● ターミナルソフト上 に判定した手書き数 字を表示
57.
57 PYNQ ボードで動作確認
58.
58 手書き数字の 1 を判定 ●
1 をピンクの四角枠に入れて r キーを押すと CNN の推論を行う ● result[1] が 72 で最大なので、結果 (max_id) は 1
59.
59 手書き数字の 5 を判定 ●
5 をピンクの四角枠に入れて r キーを押すと CNN の推論を行う ● result[5] が b2 で最大なので、結果 (max_id) は 5
60.
60 Linux 上で手書き数字認識 CNN
制御用ア プリケーションソフトを作成 1 ● PYNQ ボードの Debian 上で手書き数字 CNN 制御用アプリケーションソフトを作成した ● FPGA に実装した固定小数点のハードウェア と ARM Cortex-A9 650MHz の性能を比較し た ● gcc のオプティマイズオプション無しのとき – ハードウェア処理時間ー 12.9ms – ソフトウェア処理時間ー 60.8ms – SW 処理時間 /HW 処理時間≒ 4.71 倍
61.
61 Linux 上で手書き数字認識 CNN
制御用ア プリケーションソフトを作成 2 ● Ubuntu 16.04 上で手書き数字 CNN 制御用ア プリケーションソフトを作成した ● FPGA に実装した固定小数点のハードウェア と ARM Cortex-A9 650MHz のの性能を比較 した ● gcc のオプティマイズオプション -O2 のとき – ハードウェア処理時間ー 12.9ms – ソフトウェア処理時間ー 6.13ms – SW 処理時間 /HW 処理時間≒ 0.475 倍
62.
62 まとめ 1 ● 「ゼロから作る Deep
Learning 」を読んで勉強した ● MNIST の 2 層ニューラルネットワークの量子化 ● 量子化の結果を元に重みとバイアスを C のヘッダに変換 ● MNIST のデータの一部を C のヘッダに変換(テストベンチ用) ● Vivado HLS の C コードで 2 層ニューラルネットワークを記述 ● Vivado HLS で合成 ● MNIST の畳み込みニューラルネットワークを量子化 ● 量子化の結果を元に重みとバイアスを C のヘッダに変換 ● Vivado HLS の C コードで畳み込みニューラルネットワークを記述 ● Vivado HLS で合成
63.
63 まとめ 2 ● 四角枠生成回路などの必要な
IP を生成 ● Vivado で回路を作って合成 ● SDK でアプリケーションソフトを作ってテストー成功 ● Linux 上でアプリケーションソフトを作ってテストー成功 ● DNN に関する FPGA の部屋のすべての記事は下記の URL を参照 – Deep Neural Network – http://marsee101.web.fc2.com/dnn.html –













![19
重みとバイアスの量子化コード
MAGNIFICATION = 2 ** (9-1)
RANGE = 2 ** 4
class Affne:
def __fnft__(self, W, b):
self.W =W
self.b = b
self.x = None
self.orfgfnal_x_shape = None
# 重み バイアスパラメータの微分・
self.dW = None
self.db = None
self.bw=MAGNIFICATION
def forward_fnt(self, x):
# テンソル対応
self.orfgfnal_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
self.W = np.array(self.W*self.bw+0.5, dtype=fnt)
self.b = np.array(self.b*self.bw+0.5, dtype=fnt)
for f fn range(self.W.shape[0]):
for j fn range(self.W.shape[1]):
ff (self.W[f][j] > self.bw-1):
self.W[f][j] = self.bw-1
elff (self.W[f][j] < -self.bw):
self.W[f][j] = -self.bw;
for f fn range(self.b.shape[0]):
ff (self.b[f] > self.bw-1):
self.b[f] = self.bw-1
elff (self.b[f] < -self.bw):
self.b[f] = -self.bw
self.W = np.array(self.W, dtype=float)
self.b = np.array(self.b, dtype=float)
self.W = self.W/self.bw
self.b = self.b/self.bw
out = np.dot(self.x, self.W) + self.b
「ゼロから作る Deep
Learning 」の
Python コードを変更
掛け算
INT に変換
飽和演算
掛け算した分を
割り算で戻す
FLOAT に変換](https://image.slidesharecdn.com/deeplearning-170924122345/85/Deep-learning-19-320.jpg)
![20
出力の量子化
out = np.array(out*self.bw+0.5, dtype=fnt)
for f fn range(out.shape[0]):
for j fn range(out.shape[1]):
ff (out[f][j] > self.bw*RANGE-1):
out[f][j] = self.bw*RANGE-1
elff (out[f][j] < -self.bw*RANGE):
out[f][j] = -self.bw*RANGE
out = np.array(out, dtype=float)
out = out/self.bw
return out
掛け算
INT に変換
飽和演算
FLOAT に変換
掛け算した分を割
り算で戻す
●
重みは正規化されているので、 -1 ~ 1 、 9 ビットに量子化
●
出力は符号 1 ビット、整数部 4 ビット、小数部 9 ビットの計 13 ビットに
量子化](https://image.slidesharecdn.com/deeplearning-170924122345/85/Deep-learning-20-320.jpg)

![22
Vivado HLS で実装するための準備
●
トレーニングによって生成された重みを C のヘッダファイルに変換
●
Python コードで実装した
●
第一層目の全結合層の重みとバイアス
– af1_weight.h
– af1_bias.h
●
第 2 層目の全結合層の重みとバイアス
– af2_weight.h
– af2_bias.h
●
ヘッダファイル内には浮動小数点数の配列と固定小数点数の配列
– const float af1_fweight[784][50];
– const ap_fxed<9, 1, AP_TRN_ZERO, AP_SAT> af1_weight[784][50];](https://image.slidesharecdn.com/deeplearning-170924122345/85/Deep-learning-22-320.jpg)



![28
ニューラルネットワークの C ソースコード
●
af1_dot1: for(int col=0; col<50; col++){
●
dot1[col] = 0;
●
af1_dot2: for(int row=0; row<784; row++){
●
dot1[col] += buf[row]*af1_weight[row][col];
●
}
●
dot1[col] += af1_bias[col];
●
●
if(dot1[col] < 0) // ReLU
●
dot1[col] = 0;
●
}
●
●
af2_dot1: for(int col=0; col<10; col++){
●
dot2[col] = 0;
●
af2_dot2: for(int row=0; row<50; row++){
●
dot2[col] += dot1[row]*af2_weight[row][col];
●
}
●
dot2[col] += af2_bias[col];
●
out[col] = dot2[col];
●
}
●
最後の softmax 関数は無し
● 実装が難しいし、 10 出力
の max 値を検出するれば手
書き数字の判定はできる
● ap_fxed は Vivado HLS の
任意精度固定小数点データ
型
ap_ffxed<13, 5, AP_TRN_ZERO, AP_SAT> dot1[50];
ap_ffxed<13, 5, AP_TRN_ZERO, AP_SAT> dot2[10];](https://image.slidesharecdn.com/deeplearning-170924122345/85/Deep-learning-28-320.jpg)










![45
Vivado HLS で実装するための準備
●
トレーニングによって生成された重みを C のヘッダファイルに変換
●
Python コードで実装した
●
畳み込み層の重みとバイアス
– conv1_weight.h
– conv1_bias.h
●
最初の全結合層の重みとバイアス
– af1_weight.h
– af1_bias.h
●
二番目の全結合層の重みとバイアス
– af2_weight.h
– af2_bias.h
●
浮動小数点数の配列と固定小数点数の配列
– const float conv1_fweight[10][1][5][5];
– const ap_fxed<9, 1, AP_TRN_ZERO, AP_SAT> conv1_weight[10][1][5][5];](https://image.slidesharecdn.com/deeplearning-170924122345/85/Deep-learning-45-320.jpg)
![46
畳み込みニューラルネットワークの C ソースコード
●
CONV1: for(int i=0; i<10; i++){ // カーネルの個
数
●
CONV2: for(int j=0; j<24; j++){
●
CONV3: for(int k=0; k<24; k++){
●
conv_out[i][j][k] = 0;
●
CONV4: for(int m=0; m<5; m++){
●
CONV5: for(int n=0; n<5; n++){
●
conv_out[i][j][k] += buf[j+m][k+n] *
conv1_weight[i][0][m][n];
●
}
●
}
●
conv_out[i][j][k] += conv1_bias[i];
●
●
if(conv_out[i][j][k]<0) // ReLU
●
conv_out[i][j][k] = 0;
●
}
●
}
●
}
●
POOL1: for(int i=0; i<10; i++){
●
POOL2: for(int j=0; j<24; j += 2){
●
POOL3: for(int k=0; k<24; k += 2){
●
POOL4: for(int m=0; m<2; m++){
●
POOL5: for(int n=0; n<2; n++){
●
if(m==0 && n==0){
●
pool_out[i][j/2][k/2] = conv_out[i][j]
[k];
●
} else if(pool_out[i][j/2][k/2] <
conv_out[i][j+m][k+n]){
●
pool_out[i][j/2][k/2] = conv_out[i]
[j+m][k+n];
●
}
●
}
●
}
●
}
●
}
●
}](https://image.slidesharecdn.com/deeplearning-170924122345/85/Deep-learning-46-320.jpg)





![58
手書き数字の 1 を判定
● 1 をピンクの四角枠に入れて r キーを押すと CNN の推論を行う
● result[1] が 72 で最大なので、結果 (max_id) は 1](https://image.slidesharecdn.com/deeplearning-170924122345/85/Deep-learning-58-320.jpg)
![59
手書き数字の 5 を判定
● 5 をピンクの四角枠に入れて r キーを押すと CNN の推論を行う
● result[5] が b2 で最大なので、結果 (max_id) は 5](https://image.slidesharecdn.com/deeplearning-170924122345/85/Deep-learning-59-320.jpg)










![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)










![[第2版]Python機械学習プログラミング 第15章](https://cdn.slidesharecdn.com/ss_thumbnails/15-190318023254-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...](https://cdn.slidesharecdn.com/ss_thumbnails/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649-thumbnail.jpg?width=640&height=640&fit=bounds)
































