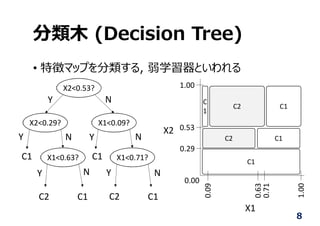
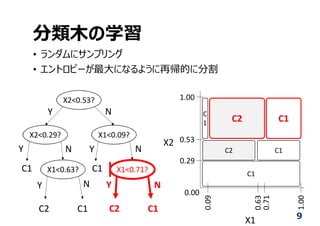
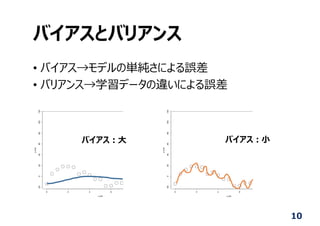
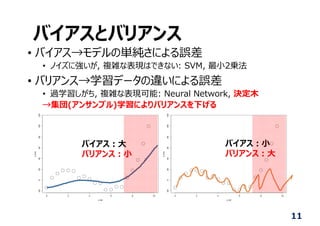
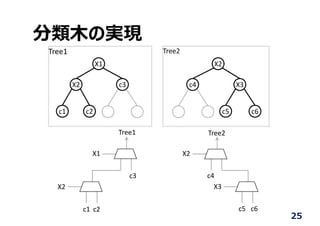
分類⽊ (Decision Tree)
•特徴マップを分類する, 弱学習器といわれる
1.00
0.53
0.29
0.00
0.09
0.63
0.71
1.00
C1
C2 C1
C
1
C2 C1
X1
X2
X2<0.53?
X2<0.29? X1<0.09?
X1<0.63? X1<0.71?
Y N
N
NN
NY
Y
Y
Y
C1
C1C2 C1C2
C1
8
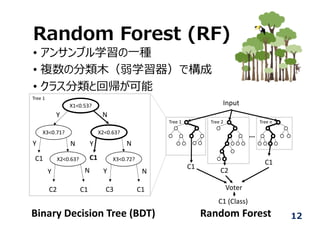
Random Forest (RF)
•アンサンブル学習の⼀種
• 複数の分類⽊(弱学習器)で構成
• クラス分類と回帰が可能
12
Tree 1 Tree 2 Tree n
C1
C2
C1
Voter
C1 (Class)
InputX1<0.53?
X3<0.71? X2<0.63?
X2<0.63? X3<0.72?
Y N
N
NN
NY
Y
Y
Y
C1
C1C2 C1C3
C1
Tree 1
Binary Decision Tree (BDT) Random Forest
...
13.
RFのアプリケーション
• Key pointmatching [Lepetit et al., 2006]
• Object detector [Shotton et al., 2008][Gall et al., 2011]
• Hand written character recognition [Amit&Geman, 1997]
• Visual word clustering
[Moosmann et al.,2006]
• Pose recognition
[Yamashita et al., 2010]
• Human detector
[Mitsui et al., 2011]
[Dahang et al., 2012]
• Human pose estimation
[Shotton 2011]
13
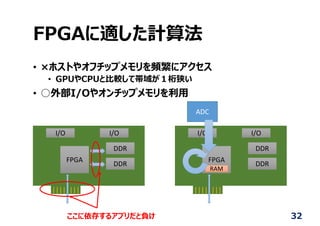
FPGA (Field Programmable
GateArray)
• Reconfigurable architecture
• Look-up Table (LUT)
• Configurable channel
• Advantages
• Faster than CPU
• Dissipate lower power
than GPU
• Short time design
than ASIC
15
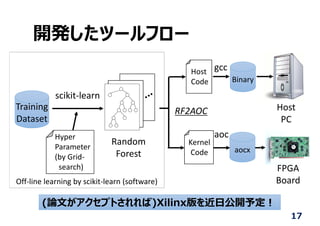
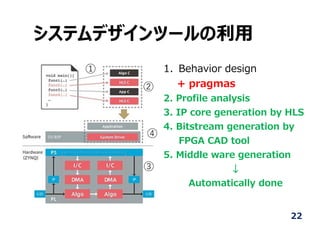
システムデザインツールの利⽤
22
①
②
④
③
1. Behavior design
+pragmas
2. Profile analysis
3. IP core generation by HLS
4. Bitstream generation by
FPGA CAD tool
5. Middle ware generation
↓
Automatically done
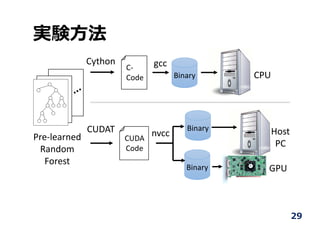
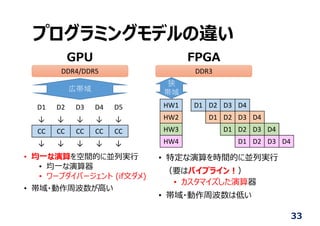
他のプラットフォームとの⽐較
• Implemented RFfollowing devices
• CPU: Intel Core i7 650
• GPU: NVIDIA GeForce GTX Titan
• FPGA: Terasic DE5-NET
• Measure dynamic power including
the host PC
• Test bench: 10,000 random vectors
• Execution time including
communication time between
the host PC and devices
30
GPU
FPGA
Deep Forestへ拡張
• SlidingWindow + Cascaded Forestの組合せ
36
Z.H.Zhou, J.Feng, “Deep Forest: Towards An Alternative to Deep Neural
Networks,”arXiv:1702.08835, [v2] Wed, 31 May 2017.






![RFのアプリケーション
• Key point matching [Lepetit et al., 2006]
• Object detector [Shotton et al., 2008][Gall et al., 2011]
• Hand written character recognition [Amit&Geman, 1997]
• Visual word clustering
[Moosmann et al.,2006]
• Pose recognition
[Yamashita et al., 2010]
• Human detector
[Mitsui et al., 2011]
[Dahang et al., 2012]
• Human pose estimation
[Shotton 2011]
13](https://image.slidesharecdn.com/fpgax2017rfonfpga-170926023739/85/FPGA-2017-13-320.jpg)


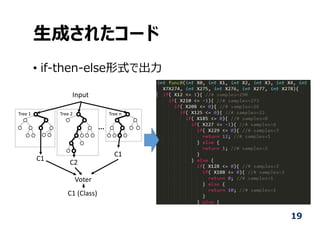
![scikit-learn を使ったコード⽣成
• 内部のデータ構造にアクセス→再帰的にコード⽣成
18
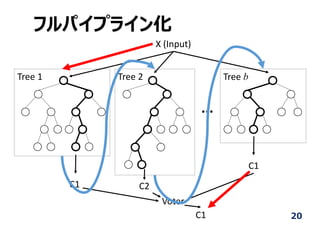
Tree 1 Tree 2 Tree n
C1
C2
C1
Voter
C1 (Class)
Input
...
len(model.estimators_) … ⽊の個数
model.estimators_[i] … i番⽬の⽊にアクセス
以降, tree = model.estimators_[i] として
tree.tree_.children_left
tree.tree_.children_right
→⽊の⼦ノードにアクセス, 再帰的に
アクセス可能
tree.tree_.threshold … 現時点のしきい値
tree.tree_.feature … ⽊の⼊⼒変数リスト
tree.tree_.value … 認識したクラスインデックス](https://image.slidesharecdn.com/fpgax2017rfonfpga-170926023739/85/FPGA-2017-18-320.jpg)

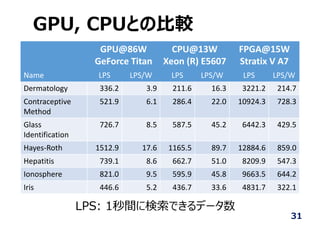
![短精度ビット⻑と分類精度
0.0
5.0
10.0
15.0
20.0
25.0
30.0
35.0
40.0
45.0
6 7 8 9 10 11 12 13 14
Misclassification Rate [%]
n‐bit Fixd Point Precision
Dermatology
Arrhythmia
Contraceptive Method Choice
Glass Identification
Hayes‐Roth
Hepatitis
Ionosphere
Iris
24](https://image.slidesharecdn.com/fpgax2017rfonfpga-170926023739/85/FPGA-2017-24-320.jpg)
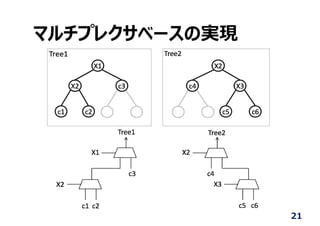
![時分割によるリソース共有
__kernel int RF(
__global float X1, X2, X3){
(fetch inputs)
for( int i = 0; i < 2; i++){
if( i == 0) class = tree1(X1,X2,X3);
else class = tree2(X1,X2,X3);
voting[class]++; // voter
}
}
..
X1
X2
X2
*
c1 c4
Voter
*
X3
c2 c4
c3 c5 c3 c6
26](https://image.slidesharecdn.com/fpgax2017rfonfpga-170926023739/85/FPGA-2017-26-320.jpg)
![ループ展開による
スループット向上
__kernel int RF(
__global float X1,X2,X3){
(fetch inputs)
#pragma unroll 2
for( int i = 0; i < 2; i++){
if( i == 0) class = tree1(X1,X2,X3);
else class = tree2(X1,X2,X3);
voting[class]++; // voter
}
}
..
X1 X2 X3
c3
c1 c2
c4
c5 c6
Voter
Voter
Register
27](https://image.slidesharecdn.com/fpgax2017rfonfpga-170926023739/85/FPGA-2017-27-320.jpg)



![Deep Forestへ拡張
• Sliding Window + Cascaded Forestの組合せ
36
Z.H.Zhou, J.Feng, “Deep Forest: Towards An Alternative to Deep Neural
Networks,”arXiv:1702.08835, [v2] Wed, 31 May 2017.](https://image.slidesharecdn.com/fpgax2017rfonfpga-170926023739/85/FPGA-2017-36-320.jpg)









![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Attentive neural processes](https://cdn.slidesharecdn.com/ss_thumbnails/attentiveneuralprocesses-181225051145-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)

























































