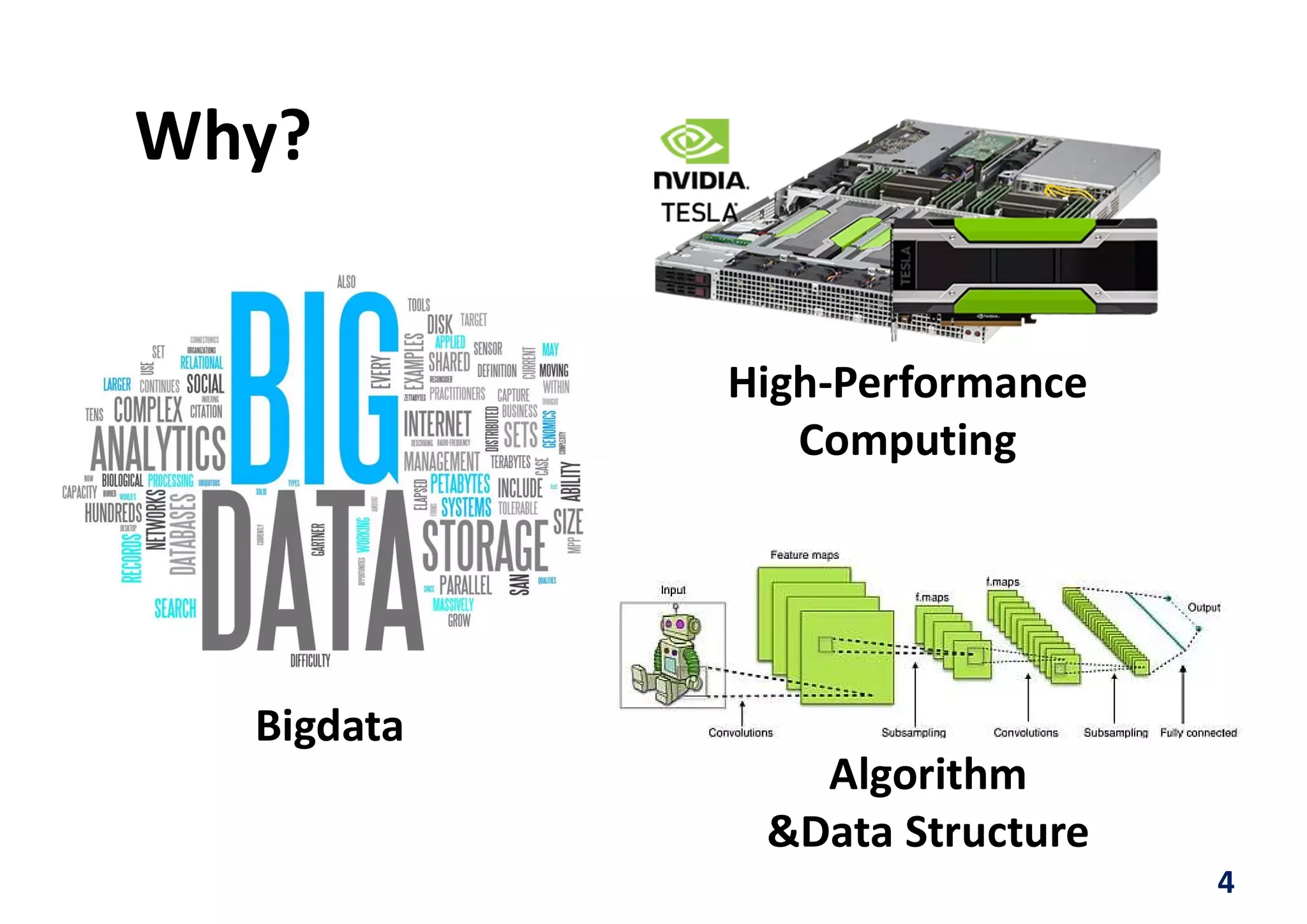
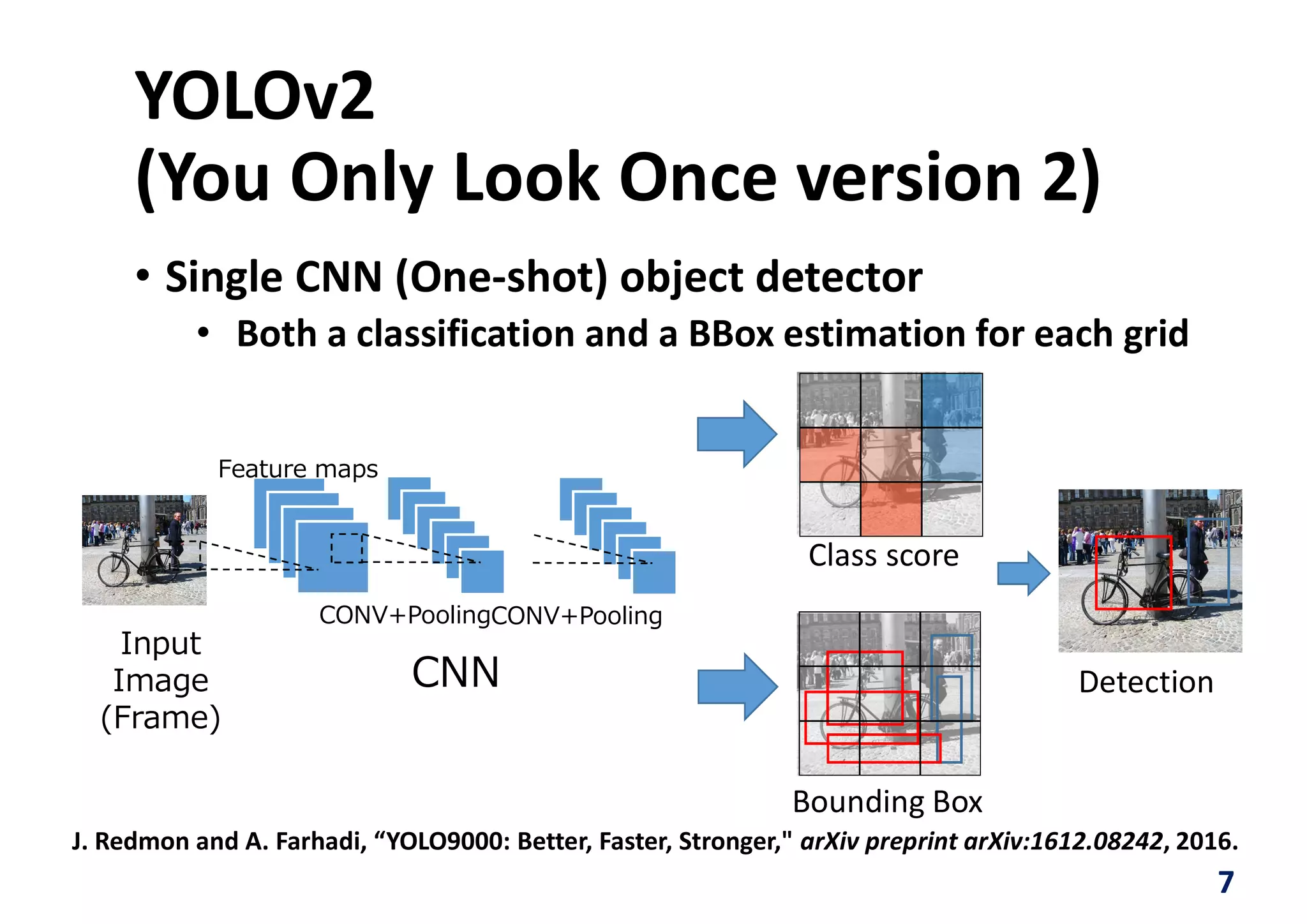
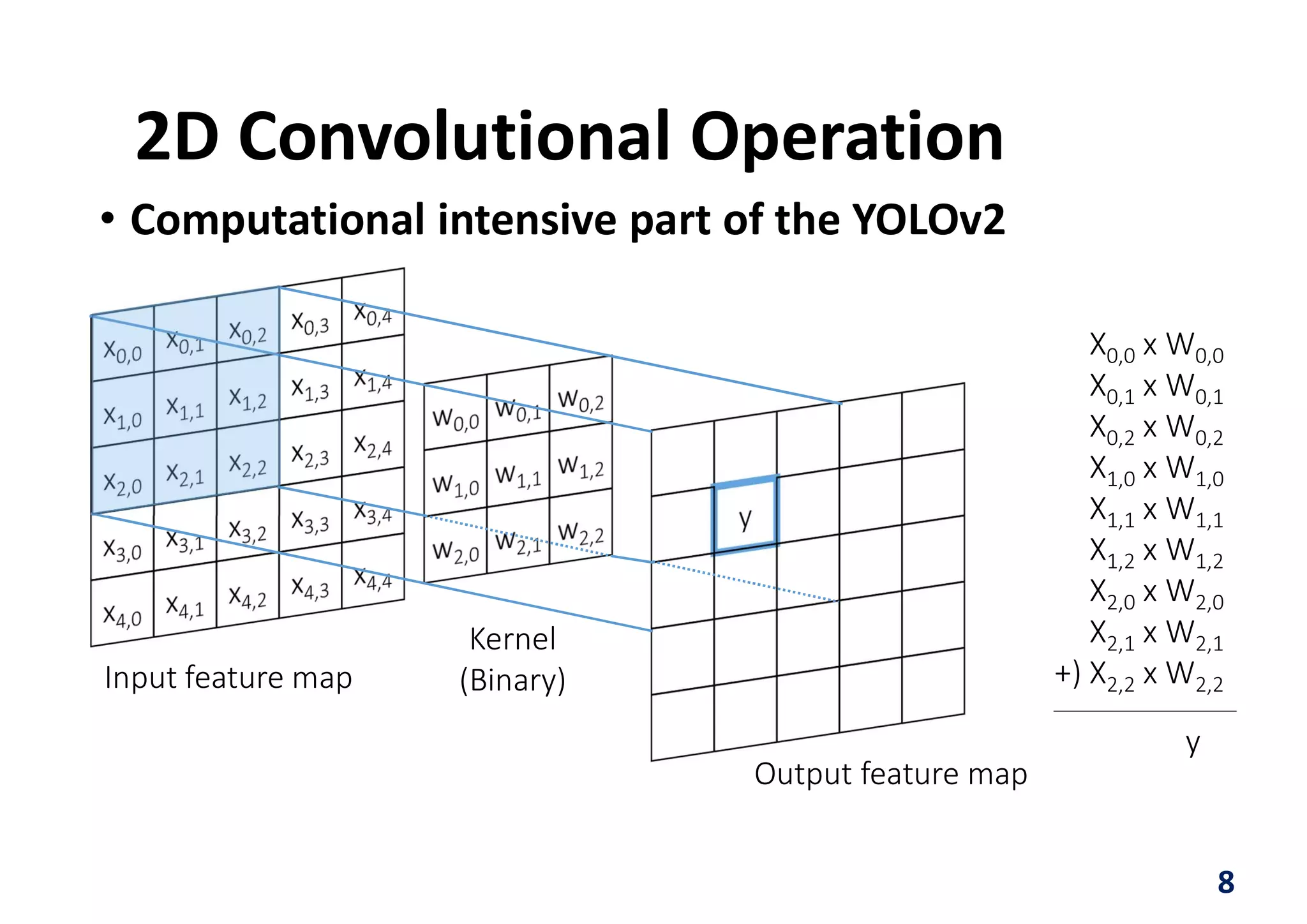
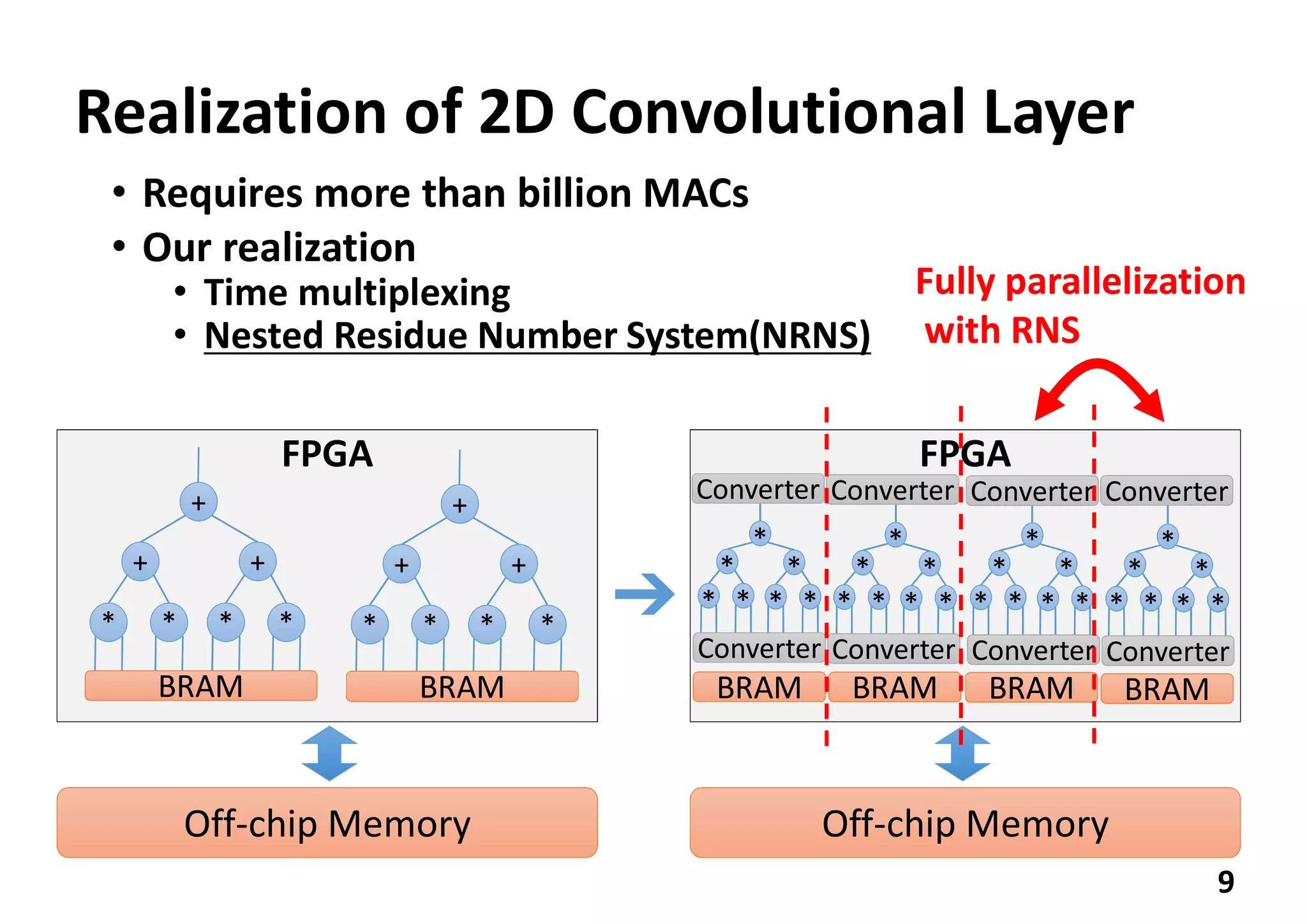
Downloaded 32 times








![13
00 01 10 11
00
01
10
11
0
1
1
1
1
1
0
0
0
1
1
1
1
1
0
0
X1=(x1, x2)
X2=(x3, x4)
h(X1) 0 01 1
x1 0 0 1 1
x2 0 1 0 1
h(X1) 0 1 0 1
0 1
00 0 1
01 1 1
10 1 0
11 1 0
x3,x4
h(X1)
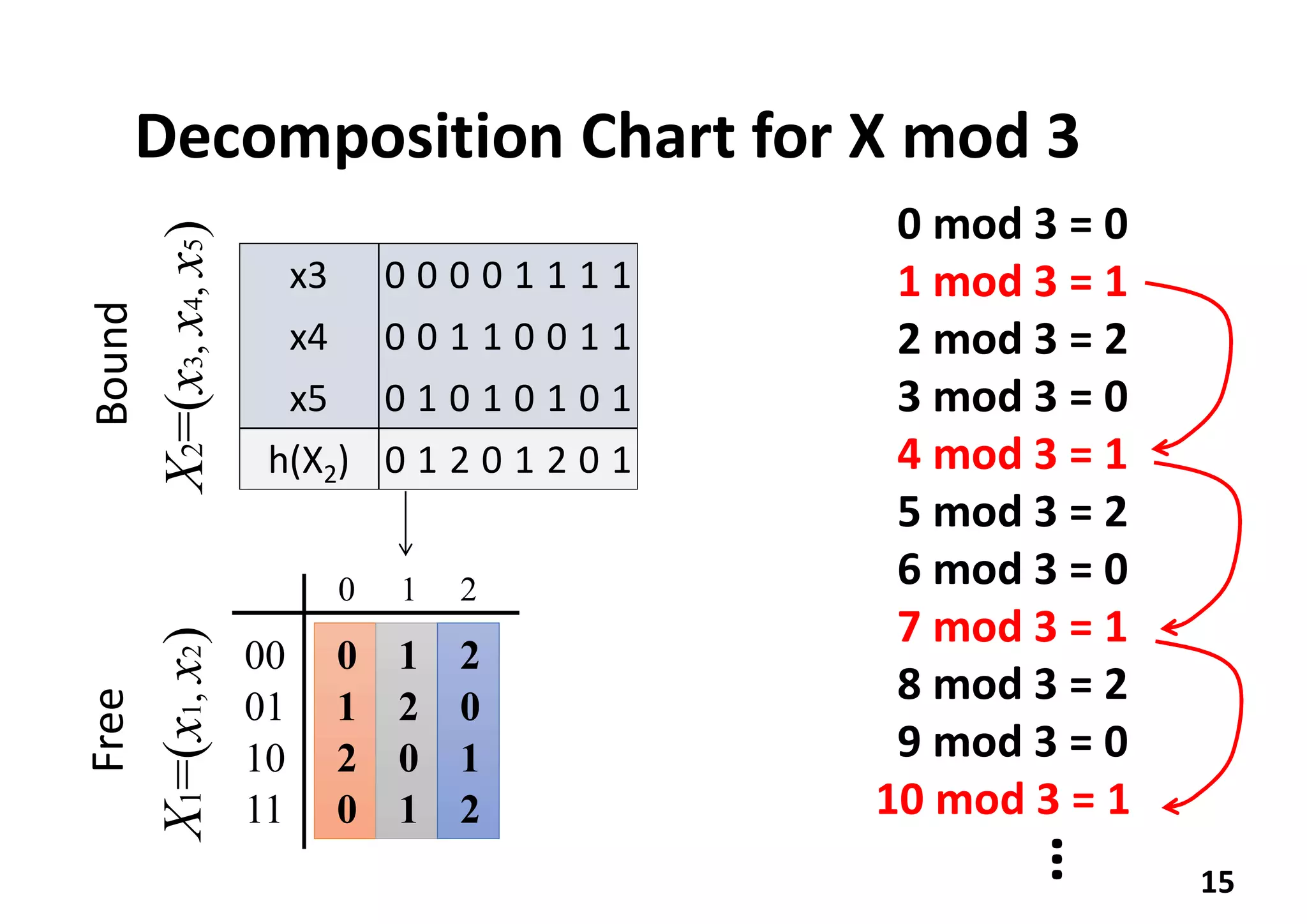
Functional Decomposition
24x1=16 [bit] 22x1+23x1=12 [bit]
Column multiplicity=2
Bound variables
Free
variables](https://image.slidesharecdn.com/iscas2018nrnsyolov2v2pdfversion-180530153809/75/ISCAS-18-A-Deep-Neural-Network-on-the-Nested-RNS-NRNS-on-an-FPGA-Applied-to-YOLOv2-13-2048.jpg)



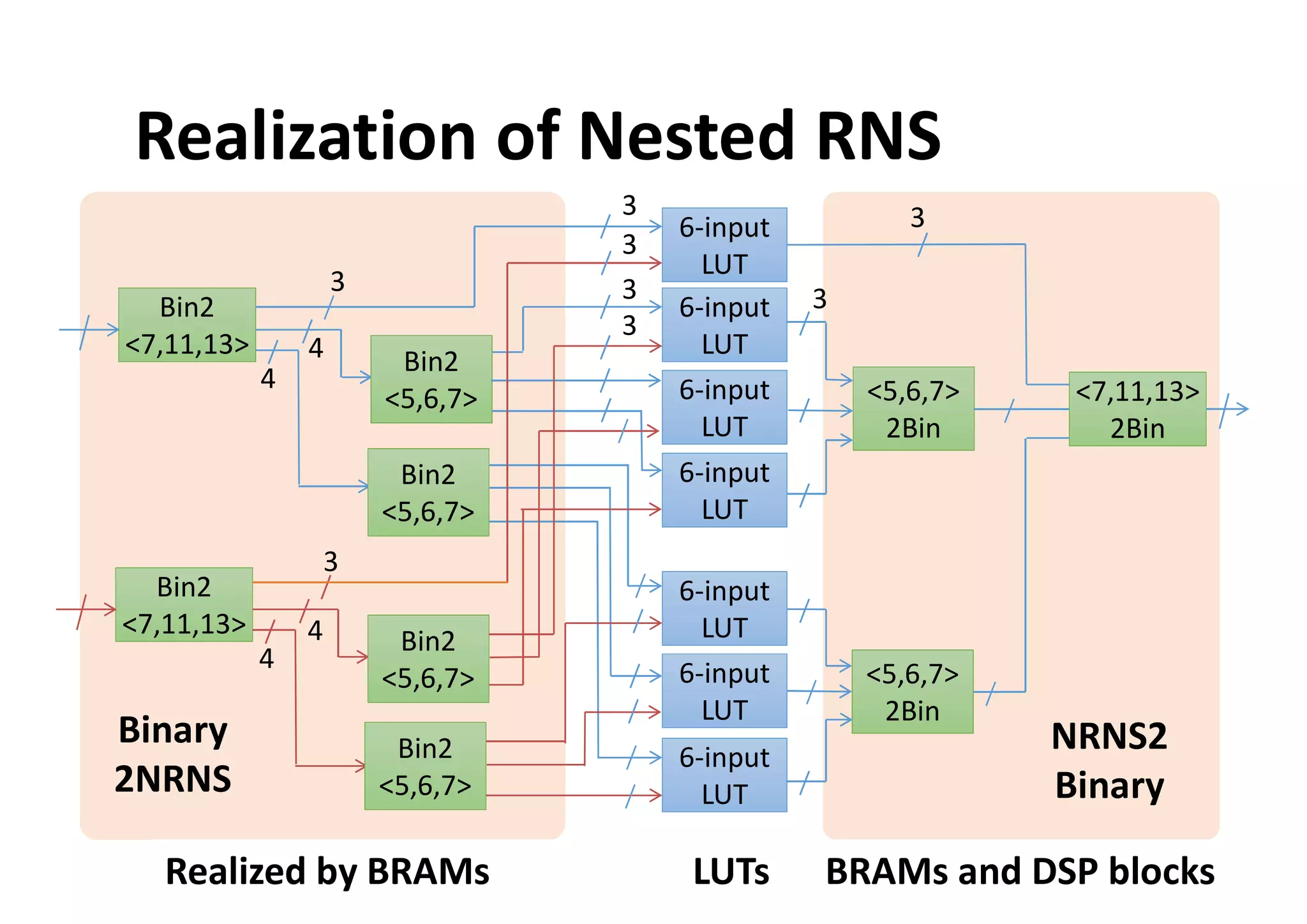

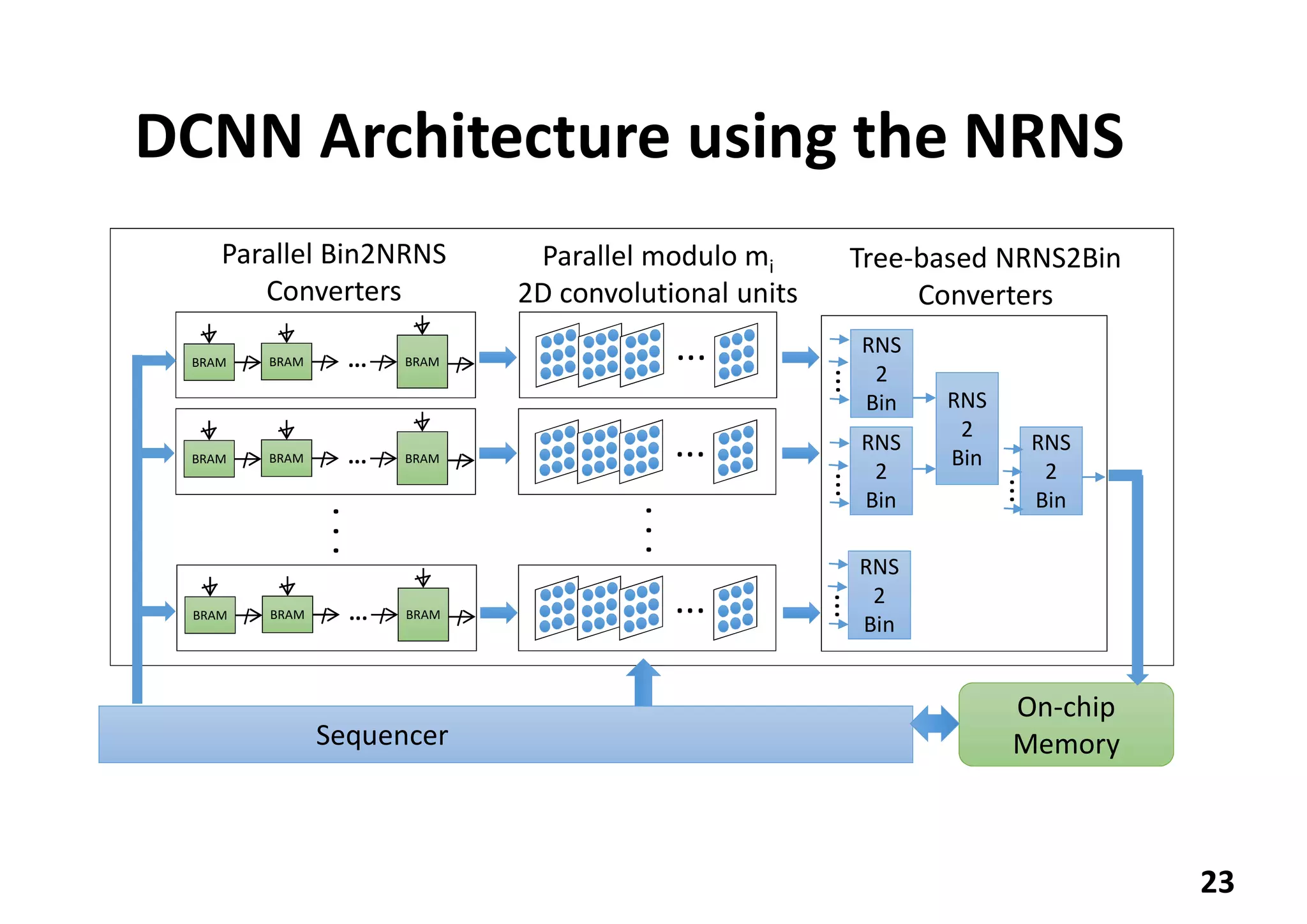


![Comparison
26
NVivia Pascal
GTX1080Ti
NetFPGA-SUME
Speed [FPS] 20.64 3.84
Power [W] 60.0 3.5
Efficiency [FPS/W] 0.344 1.097](https://image.slidesharecdn.com/iscas2018nrnsyolov2v2pdfversion-180530153809/75/ISCAS-18-A-Deep-Neural-Network-on-the-Nested-RNS-NRNS-on-an-FPGA-Applied-to-YOLOv2-26-2048.jpg)


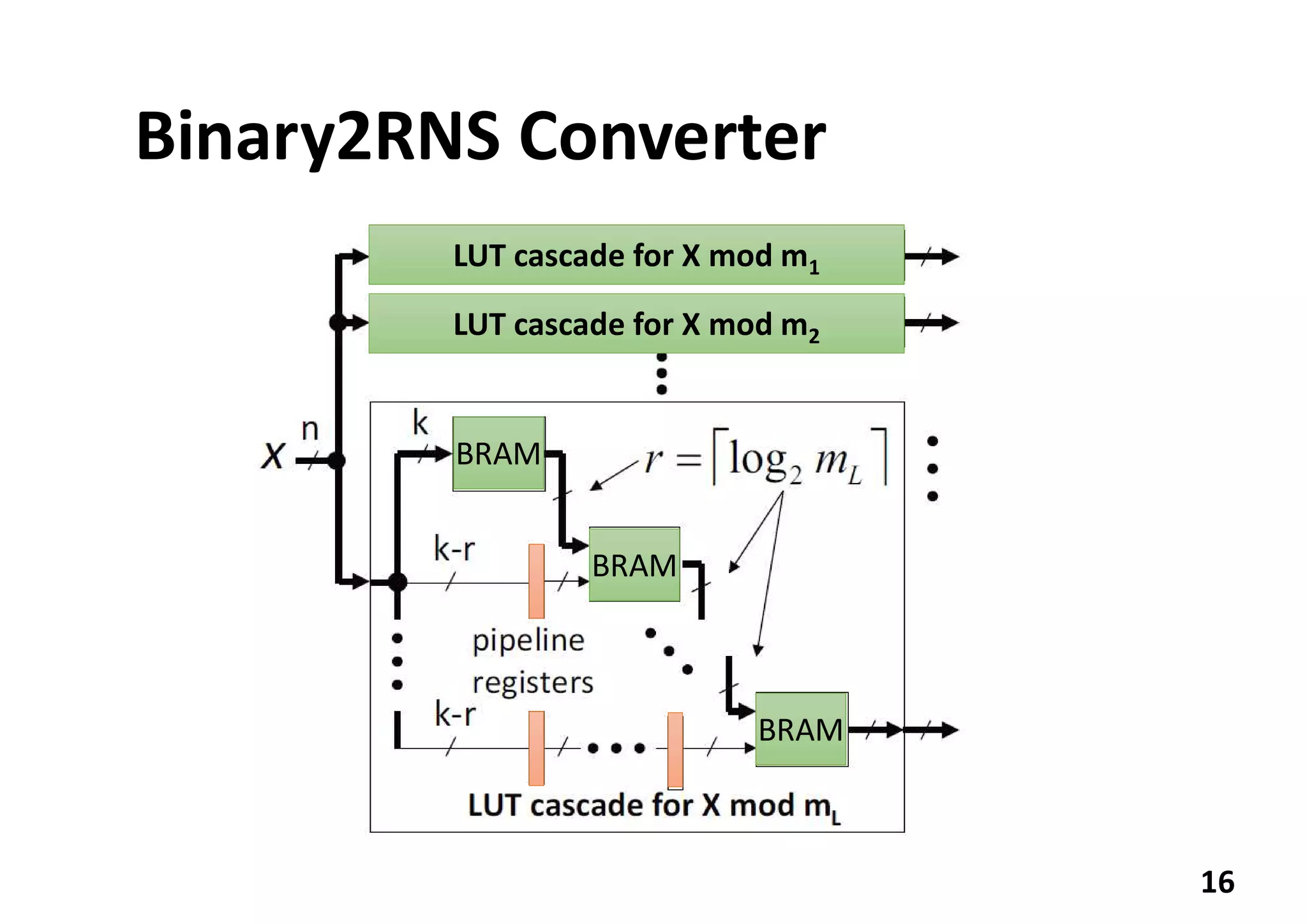
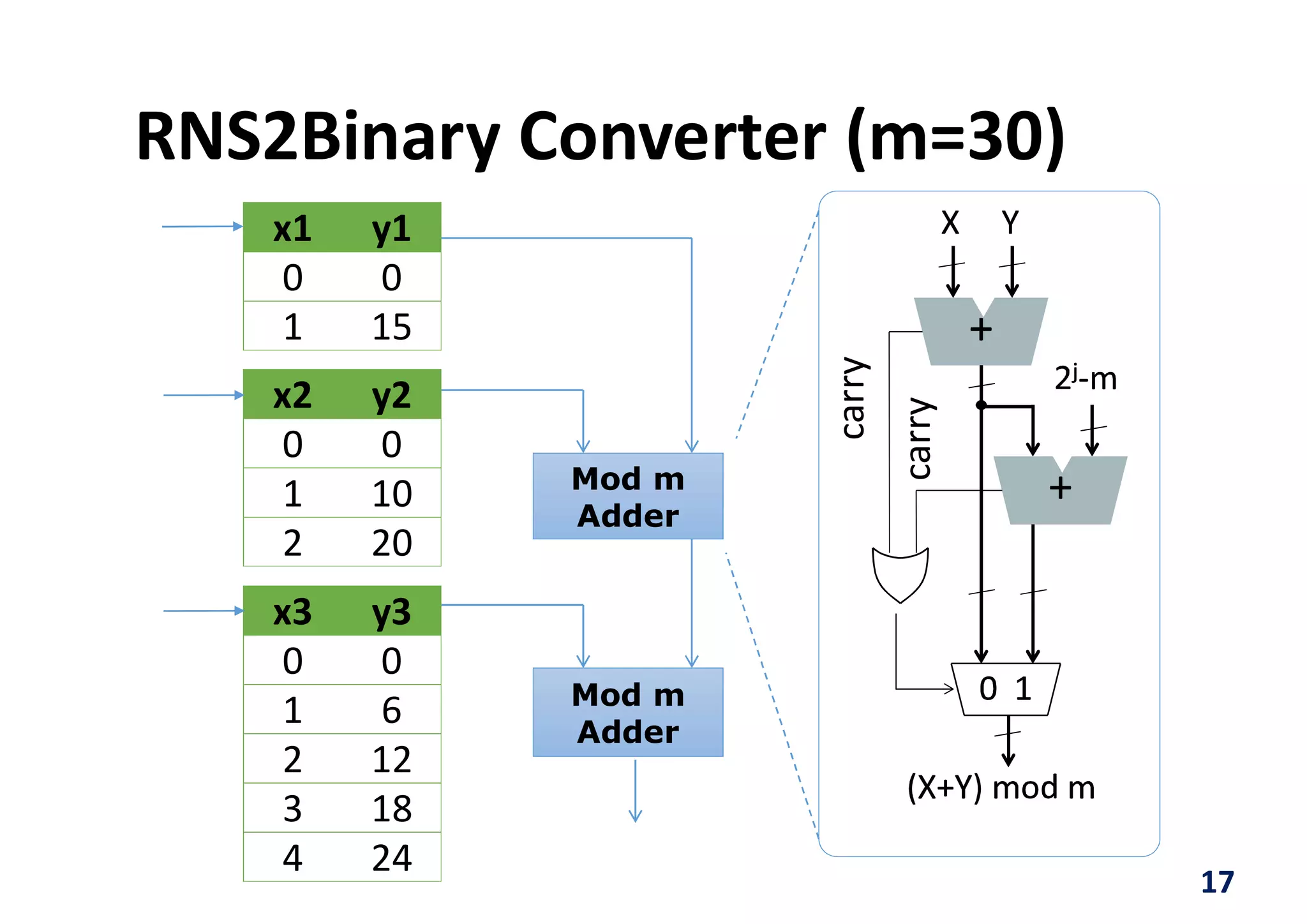
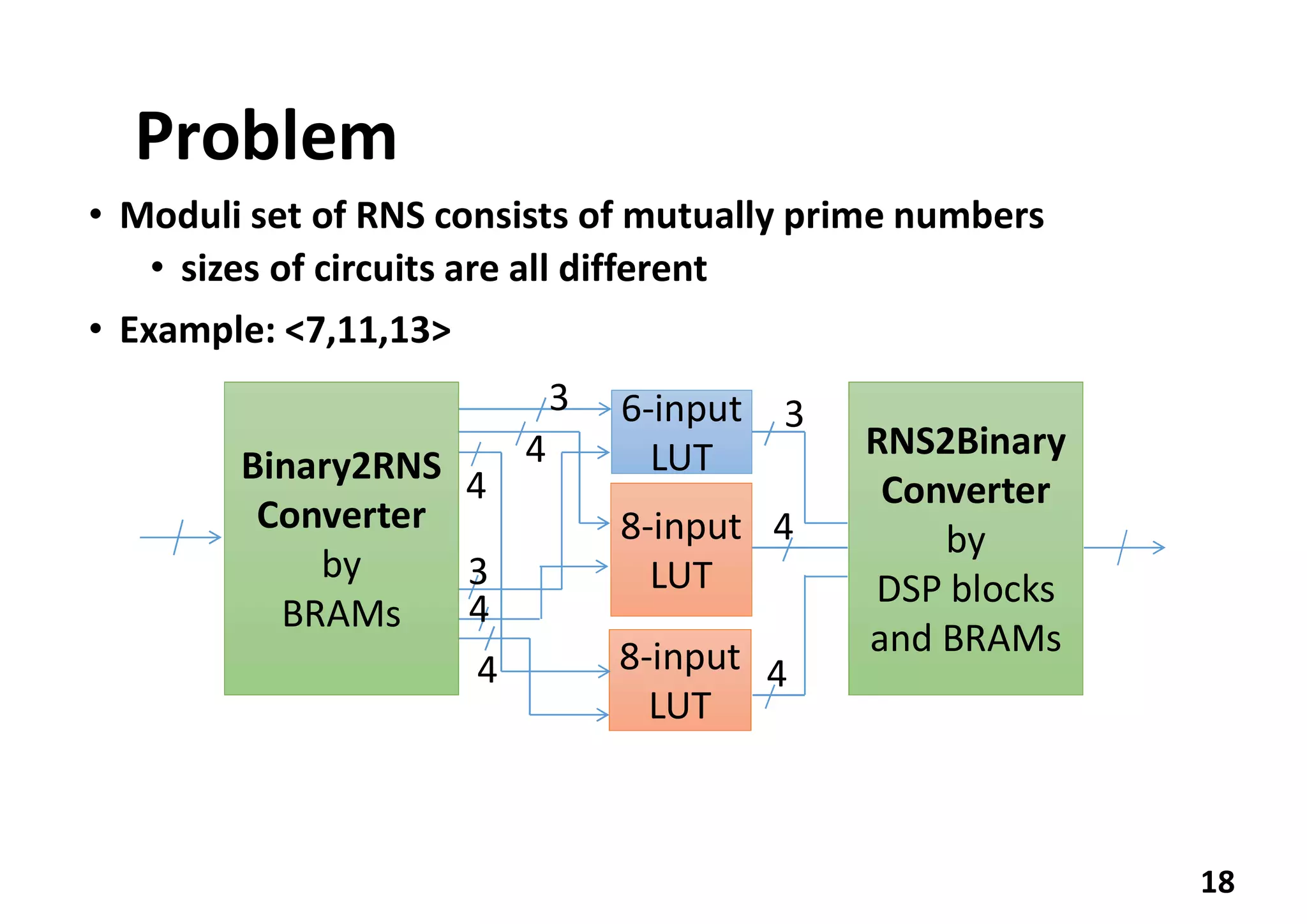
The document discusses implementing a deep neural network object detector called YOLOv2 on an FPGA using a technique called Nested Residue Number System (NRNS). Key points: 1. YOLOv2 is used for real-time object detection but requires high performance and low power. 2. NRNS decomposes large integer operations into smaller ones using a nested set of prime number moduli, enabling parallelization on FPGA. 3. The authors implemented a Tiny YOLOv2 model using NRNS on a NetFPGA-SUME board, achieving 3.84 FPS at 3.5W power and 1.097 FPS/W efficiency.
















![[PR12] PR-036 Learning to Remember Rare Events](https://cdn.slidesharecdn.com/ss_thumbnails/pr12pr-036learningtoremeberrareevents-170917140144-thumbnail.jpg?width=640&height=640&fit=bounds)






































































