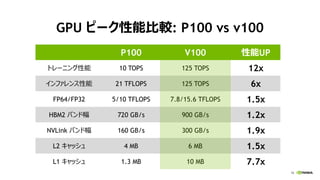
3
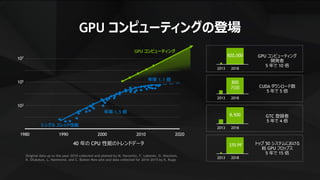
GPU コンピューティングの登場
370 PF
20182013
トップ50 システムにおける
総 GPU フロップス
5 年で 15 倍
1980 1990 2000 2010 2020
40 年の CPU 性能のトレンドデータ
Original data up to the year 2010 collected and plotted by M. Horowitz, F. Labonte, O. Shacham,
K. Olukotun, L. Hammond, and C. Batten New plot and data collected for 2010-2015 by K. Rupp
103
105
107
年率 1.5 倍
年率 1.1 倍
シングル スレッド性能
GPU コンピューティング
8,500
20182013
800
万回
20182013
820,000
20182013
GTC 登録者
5 年で 4 倍
CUDA ダウンロード数
5 年で 5 倍
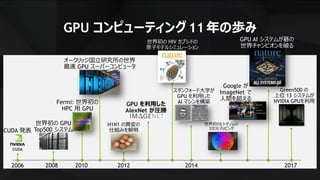
GPU コンピューティング
開発者
5 年で 10 倍















![22
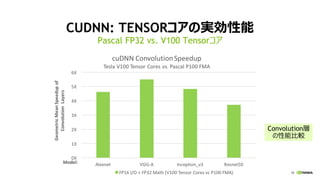
TensorFlow
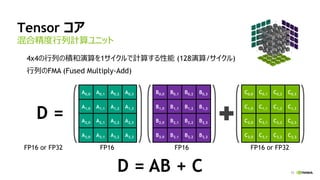
Tensorコア: TensorFlow 1.4で対応
データ型をFP16にすると、Tensorコアを使用
ウェイトFP32更新: 可能
ロススケーリング: 可能
tf.cast(tf.get_variable(..., dtype=tf.float32), tf.float16)
scale = 128
grads = [grad / scale for grad in tf.gradients(loss * scale, params)]](https://image.slidesharecdn.com/rnug6-part4-180423010908/85/GPU-22-320.jpg)


























![[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...](https://cdn.slidesharecdn.com/ss_thumbnails/20170922mapd-170926064811-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Track2-2] 最新のNVIDIA AmpereアーキテクチャによるNVIDIA A100 TensorコアGPUの特長とその性能を引き出す方法](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)




































