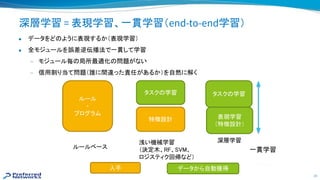
深層学習における代表的なタスク
11
The graph wasexcerpted from https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/object_localization_and_detection.html
29
The “large batch”problem
From Keskar et al.
“On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima”
“It has been observed in practice that when using a larger batch
there is a significant degradation in the quality of the model, as
measured by its ability to generalize”
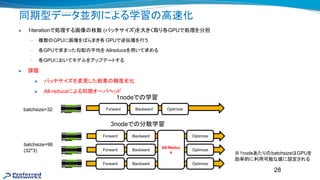
1. Computed gradients in each iteration is an average of larger number of samples
→ gradients are “less stochastic”, which makes it difficult to escape from local minima
2. Total number of iterations (=updates) is smaller
(number of iterations in 1epoch = number of images / batchsize)
Local minima
Better model
28.
30
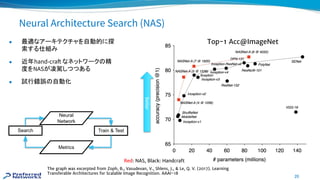
“Linear scaling rule”for large batch problem
“If minibatch-size is k times larger, increase learning rate by k times”
29.
31
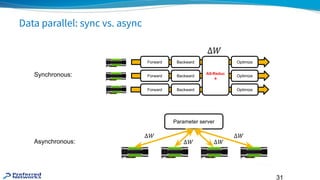
Data parallel: syncvs. async
All-Reduc
e
Forward
Forward
Forward
Backward
Backward
Backward
Optimize
Optimize
Optimize
Synchronous:
Parameter server
Asynchronous:
30.
32
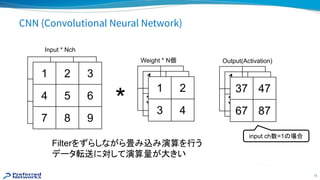
Reduce communication: useFP16
Compute gradients
Convert FP32 to FP16
Allreduce (with NCCL)
Convert FP16 to FP32 and update
31.
33
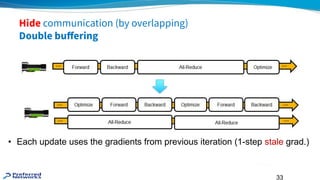
Hide communication (byoverlapping)
Double buffering
• Each update uses the gradients from previous iteration (1-step stale grad.)
32.
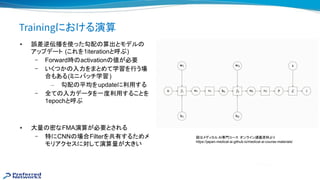
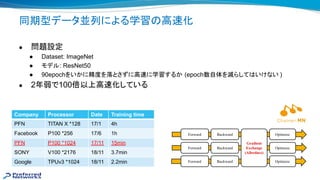
同期型データ並列による学習 高 化
●問題設定
● Dataset: ImageNet
● モデル: ResNet50
● 90epochをいかに精度を落とさずに高 に学習するか (epoch数自体を減らして いけない )
● 2年弱で100倍以上高 化している
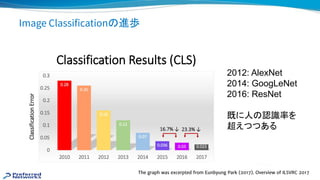
Company Processor Date Training time
PFN TITAN X *128 17/1 4h
Facebook P100 *256 17/6 1h
PFN P100 *1024 17/11 15min
SONY V100 *2176 18/11 3.7min
Google TPUv3 *1024 18/11 2.2min







![9
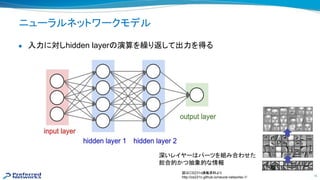
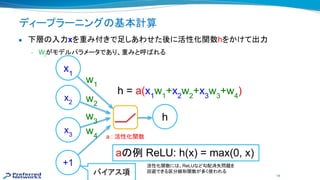
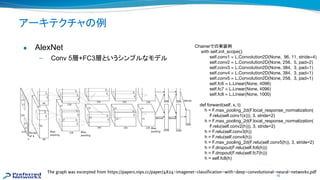
ディープラーニング(深層学習)と
● 層が深く、幅も広いニューラルネットワーク
を利用した機械学習手法 一手法
● 2012年 大ブレーク以来、研究コミュニティ
みならず産業界に多く使われてきた
● 画像認識、音声認識、強化学習、自然言語処理
などで劇的な精度向上を果たし、そ 多くが既に実用化されている
2014年 一般画像認識コンテストで優勝した
22層からなる GoogLeNet 例 [Google 2014]
*http://memkite.com/deep-learning-bibliography/](https://image.slidesharecdn.com/dasymposiumhwswfortraininginferenceslideshare-190911111040/85/DA-2019-Training-Inference-HW-SW-hare-7-320.jpg)








































![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)


![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[基調講演] Deep Learning: IoT's Driving Engine](https://cdn.slidesharecdn.com/ss_thumbnails/dllabdaykeynotenishikawa-180704002744-thumbnail.jpg?width=640&height=640&fit=bounds)






















