Downloaded 41 times

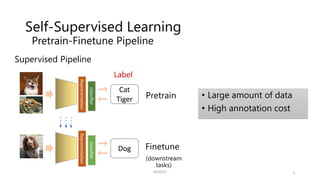
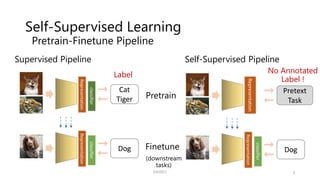
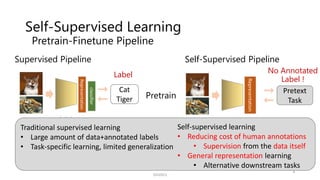

![Self-Supervised Learning
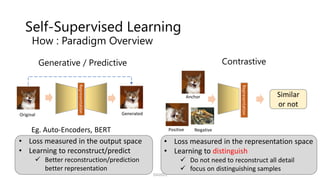
How : Paradigm Overview
SSII2021
Generative / Predictive
Representation
• Loss measured in the output space
• Learning to reconstruct/predict
Better reconstruction/prediction
better representation
Original Generated
Eg. Auto-Encoders, BERT
Top: Drawing of a dollar bill from memory
Down: Drawing subsequently made with a
dollar bill present. [Image source: Epstein, 2016]](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-7-320.jpg)
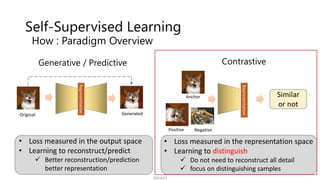
![Contrastive Learning
Point: distinguish features among different instances
9
SSII2021
Representation
Positive (𝒙+
)
Negative
(𝐱𝐣, 𝒕𝒉𝒆 𝒐𝒕𝒉𝒆𝒓 𝒔𝒂𝒎𝒑𝒍𝒆𝒔)
Anchor (𝒙)
Positive
Anchor Negative
Anchor
similar dissimilar
InfoNCE Loss [Gutmann+, AISTATS’10]](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-9-320.jpg)
![Contrastive Learning
• MoCo: Momentum contrast for unsupervised visual
representation learning [CVPR’20]
• SimCLR: A Simple Framework for Contrastive Learning
of Visual Representations [ICML’20]
SSII2021 10
Recent related works
Increase negatives
Increase positives](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-10-320.jpg)
![MoCo[CVPR’20]
Points (Negative samples)
He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." CVPR2020.
SSII2021
11](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-11-320.jpg)
![MoCo[CVPR’20]
He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." CVPR2020.
SSII2021
12
End-to-end:
• Negative
• All the other samples (-anchor/positive)
• Two encoders
• q: anchor; k:positive/negative
• Benefit from large batch size
• Memory problem](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-12-320.jpg)
![MoCo[CVPR’20]
He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." CVPR2020.
SSII2021
13
Memory Bank(MB):
• Negative:
• Embedding stored in MB
• Random sampling from
MB
• Memory bank updating
• Computing cost problem](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-13-320.jpg)
![MoCo[CVPR’20]
He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." CVPR2020.
SSII2021
14
Momentum encoder
• Encoder:
• Only positive sample
• Negative:
• Past embeddings of positives
• Queue: save embedded features
• Updating: weight of momentum encoder](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-14-320.jpg)
![SimCLR[ICML’20]
Points
• Positive samples: data augmentation
• Random crops + color distortion
• Negative samples: larger batch size(end-to-end)
SimCLR:Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." ICML2020.
SSII2021
15](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-15-320.jpg)
![Effect of Recent Works
SSII2021 16
source: [SimCLR: A Simple Framework for Contrastive Learning of Visual Representations]
• Performance approaching
supervised methods
• Limitation:
more time & parameters
• Less labeling cost
• High generalization
(Eg. cross-domain)](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-16-320.jpg)

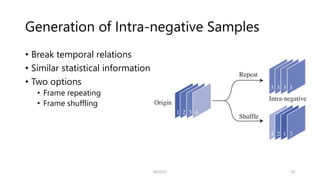
![Inter-intra Contrastive Framework [MM’20]
SSII2021 18
• Intra-positives: same instance, same class
Intra-negatives: same instance, different class
• Inter-positives: different instances, same class
Inter-negatives: different instances
Traditional contrastive learning
IIC: L. TAO, X. Wang, and T. YAMASAKI, “Self-supervised Video Representation Learning Using Inter-
intra Contrastive Framework”, ACMMM2020.
Inter-intra contrastive (IIC) learning framework
makes the most use of data](https://image.slidesharecdn.com/os2-04-210605061641/85/SSII2021-OS2-03-18-320.jpg)



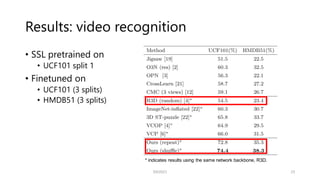




The document explores contrastive self-supervised learning, discussing its methodologies that reduce human annotation costs while promoting general representation learning. It highlights the effectiveness of various frameworks like MoCo and SimCLR, emphasizing their capabilities in distinguishing features among instances and the importance of both positive and negative samples. Additionally, the results demonstrate significant improvements in video tasks through the proposed inter-intra contrastive learning framework.
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

























![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-03] スケーラブルなロボット学習システムに向けて](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-03-220607020929-1e2b15e8-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-01] 深層学習のための効率的なデータ収集と活用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-01-220607020740-e80781dc-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS2-01] イメージング最前線](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os2-1-220607020403-b550c379-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS1-01] AI時代のチームビルディング](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os1-01-220607015404-49188612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS2] Deepfake Generation and Detection – An Overview (ディープフェイクの生成と検出)](https://cdn.slidesharecdn.com/ss_thumbnails/ss2-01-210607043612-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS3] 機械学習のアノテーションにおける データ収集 〜 精度向上のための仕組み・倫理や社会性バイアス 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts3-01-210607043121-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-03] 画像と点群を用いた、森林という広域空間のゾーニングと施業管理](https://cdn.slidesharecdn.com/ss_thumbnails/os3-04-210605062524-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-02] BIM/CIMにおいて安価に点群を取得する目的とその利活用](https://cdn.slidesharecdn.com/ss_thumbnails/os3-03-210605062350-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3-01] 設備や環境の高品質計測点群取得と自動モデル化技術](https://cdn.slidesharecdn.com/ss_thumbnails/os3-02-210605062048-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS3] 広域環境の3D計測と認識 ~ 人が活動する場のセンシングとモデル化 ~(オーガナイザーによる冒頭の導入)](https://cdn.slidesharecdn.com/ss_thumbnails/os3-01-210605061816-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Harshvardhan Jain - From Pre-Trained to Purpose-Built: Fine-T...](https://cdn.slidesharecdn.com/ss_thumbnails/zru4zmiseku5tgvu2dgw-harshvardhan-jain-from-pre-trained-to-purpose-built-fine-tuning-llms-for-high-i-260119101520-8335585f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
