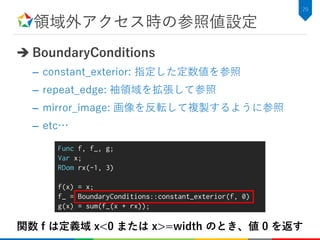
DeepLearningにおけるConvolution
Convolutional NeuralNetwork
– 画像認識に使用されるニューラルネットワーク
– 推論時はConvolution層が全体の処理時間の50%以上を占める
• 最近のネットワークではConvolution層の多段化により
さらに処理時間が増加
Convolution層の高速化はとても重要!
33
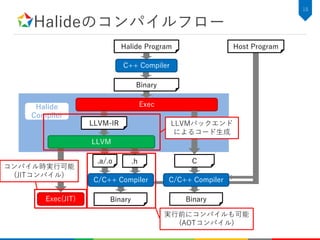
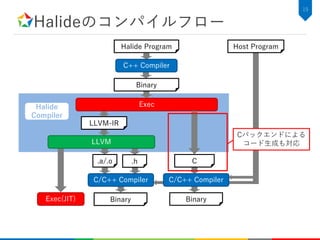
Convolution層
LeNetのネットワーク図
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning
applied to document recognition. Proceedings of the IEEE, november 1998.
35.
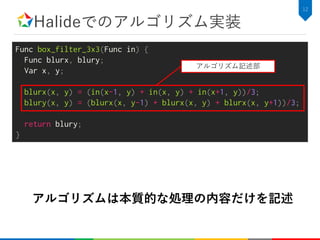
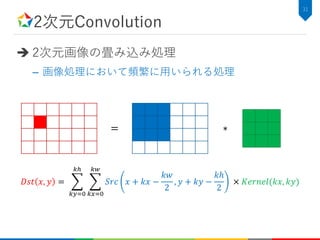
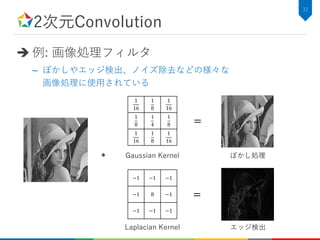
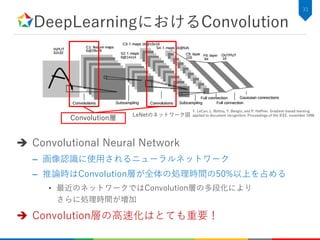
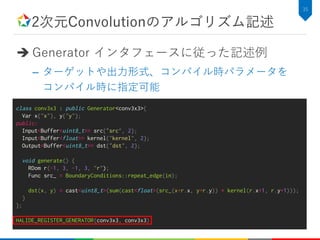
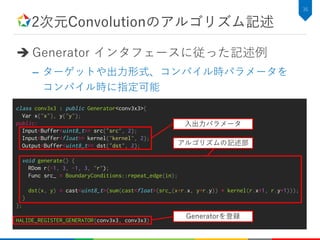
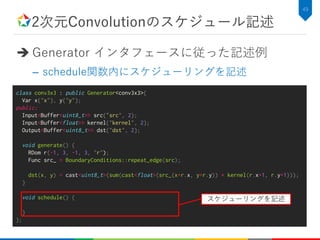
2次元Convolutionのアルゴリズム記述
C++での実装例
34
void conv3x3(constuint8_t* src, const float* kernel, uint8_t* dst,
int height, int width) {
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
float tmp = .0f;
for (int ky=0; ky<kh; ky++) {
for (int kx=0; kx<kw; kx++) {
tmp += src[y+ky-kh/2][x+kx-kw/2] * kernel[ky][kx];
}
}
dst[y][x] = tmp;
}
}
}


![DeepLearningの台頭
28.2
25.8
16.4
11.7
6.7
3.57
0
5
10
15
20
25
30
2010
NEC America
2011
Xerox
2012
AlexNet
2013
Clarifai
2014
GoogLeNet
2015
ResNet
Top-5Error[%]
ILSVRC ImageNet Classification
1
Deep Neural Networkによる
劇的な精度向上
http://image-net.org/challenges/talks/ilsvrc2015_deep_residual_learning_kaiminghe.pdf](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-2-320.jpg)





![C++でのIntel向け手動最適化コード
9
void box_filter_3x3(const Image &in, Image &blury) {
__m128i one_third = _mm_set1_epi16(21846);
#pragma omp parallel for
for (int yTile = 0; yTile < in.height(); yTile += 32) {
__m128i a, b, c, sum, avg;
__m128i blurx[(256/8)*(32+2)]; // allocate tile blurx array
for (int xTile = 0; xTile < in.width(); xTile += 256) {
__m128i *blurxPtr = blurx;
for (int y = -1; y < 32+1; y++) {
const uint16_t *inPtr = &(in[yTile+y][xTile]);
for (int x = 0; x < 256; x += 8) {
a = _mm_loadu_si128((__m128i*)(inPtr-1));
b = _mm_loadu_si128((__m128i*)(inPtr+1));
c = _mm_load_si128((__m128i*)(inPtr));
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(blurxPtr++, avg);
inPtr += 8;
}
}
blurxPtr = blurx;
for (int y = 0; y < 32; y++) {
__m128i *outPtr = (__m128i *)(&(blury[yTile+y][xTile]));
for (int x = 0; x < 256; x += 8) {
a = _mm_load_si128(blurxPtr+(2*256)/8);
b = _mm_load_si128(blurxPtr+256/8);
c = _mm_load_si128(blurxPtr++);
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(outPtr++, avg);
}
}
}
}
}](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-10-320.jpg)
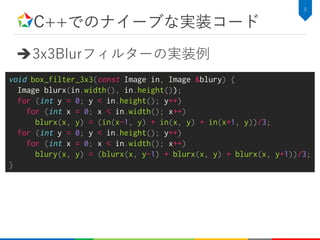
![C++でのIntel向け手動最適化コード
10
void box_filter_3x3(const Image &in, Image &blury) {
__m128i one_third = _mm_set1_epi16(21846);
#pragma omp parallel for
for (int yTile = 0; yTile < in.height(); yTile += 32) {
__m128i a, b, c, sum, avg;
__m128i blurx[(256/8)*(32+2)]; // allocate tile blurx array
for (int xTile = 0; xTile < in.width(); xTile += 256) {
__m128i *blurxPtr = blurx;
for (int y = -1; y < 32+1; y++) {
const uint16_t *inPtr = &(in[yTile+y][xTile]);
for (int x = 0; x < 256; x += 8) {
a = _mm_loadu_si128((__m128i*)(inPtr-1));
b = _mm_loadu_si128((__m128i*)(inPtr+1));
c = _mm_load_si128((__m128i*)(inPtr));
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(blurxPtr++, avg);
inPtr += 8;
}
}
blurxPtr = blurx;
for (int y = 0; y < 32; y++) {
__m128i *outPtr = (__m128i *)(&(blury[yTile+y][xTile]));
for (int x = 0; x < 256; x += 8) {
a = _mm_load_si128(blurxPtr+(2*256)/8);
b = _mm_load_si128(blurxPtr+256/8);
c = _mm_load_si128(blurxPtr++);
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(outPtr++, avg);
}
}
}
}
}](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-11-320.jpg)

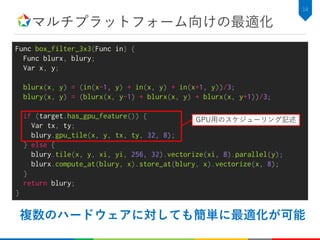
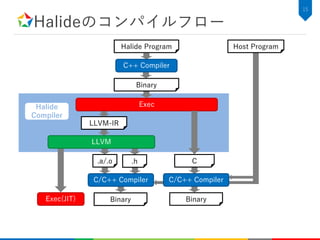
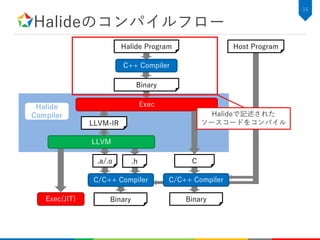
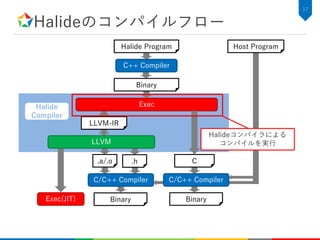

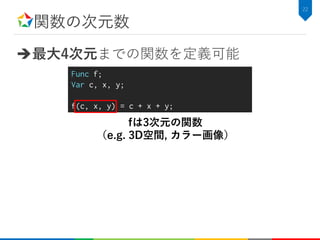
![関数の定義
アルゴリズムは純粋関数として定義される
– 関数: Halide::Func
– 次元変数: Halide::Var
21
Func f;
Var x, y;
f(x, y) = x + y;
意味: 関数f は定義域 x, yに対して x + y を値域に持つ
名前空間 Halide:: は以下省略
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
f[y][x] = x + y;
}
}
等価なC++ソースコードHalideで書かれたソースコード](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-22-320.jpg)
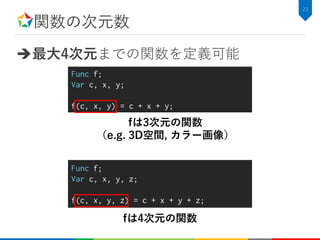



![RDomと畳み込み関数
リダクションドメイン: Rdom
– RDom(min, extent)
– 指定された次元で[min, min+extent-1]の領域を動く
ループ変数
27
rx は[-1, 1] を動くループ変数
Func f, g;
Var x;
RDom rx(-1, 3)
f(x) = x;
g(x) = sum(f(x + rx));
for (int x=0; x<width; x++) {
T sum = 0;
for (int rx=-1; rx<2; rx++) {
sum += x + rx;
}
g[x] = sum;
}
等価なC++ソースコード](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-28-320.jpg)
![RDomと畳み込み関数
畳み込み関数:
– RDomで指定した領域を畳み込んで演算を行う関数
• 例: sum/product/maximum/minimum/argmin/argmax
28
Func f, g;
Var x;
RDom rx(-1, 3)
f(x) = x;
g(x) = sum(f(x + rx));
関数 g は各xにおいて、x-1, x+0, x+1の総和を値域に持つ
for (int x=0; x<width; x++) {
T sum = 0;
for (int rx=-1; rx<2; rx++) {
sum += x + rx;
}
g[x] = sum;
}
等価なC++ソースコード](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-29-320.jpg)

![2次元Convolutionのアルゴリズム記述
C++での実装例
34
void conv3x3(const uint8_t* src, const float* kernel, uint8_t* dst,
int height, int width) {
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
float tmp = .0f;
for (int ky=0; ky<kh; ky++) {
for (int kx=0; kx<kw; kx++) {
tmp += src[y+ky-kh/2][x+kx-kw/2] * kernel[ky][kx];
}
}
dst[y][x] = tmp;
}
}
}](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-35-320.jpg)



![計算タイミングの指定
Func::compute_root
– 関数の全領域の計算結果がメモリに保持される
• 〇計算量が削減できる可能性あり
• ×必要メモリ量は多くなる
40
Func blur_x, blur_y;
Var x, y;
blur_x(x, y) =
in(x, y) + in(x+1, y);
blur_y(x, y) =
(blur_x(x, y) + blur_x(x, y+1)) / 4;
blur_x.compute_root();
blur_xはblur_yを評価する前に全領域が計算される
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
blur_x[y][x] = in[y][x] + in[y][x+1];
}
}
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
blur_y[y][x] =
(blur_x[y][x] + blur_x[y+1][x]) / 4;
}
}](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-41-320.jpg)
![計算タイミングの指定
Func::compute_at
– 指定した関数の次元のループ内で必要な領域のみの
計算結果がメモリに保持される
• 計算量・メモリ使用量共に
compute_inlineとcompute_rootの中間となる
41
blur_xはblur_yのyループ内で必要な領域が計算される
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
blur_x[0][x] = in[y][x] + in[y][x+1];
blur_x[1][x] =
in[y+1][x] + in[y+1][x+1];
}
for (int x=0; x<width; x++) {
blur_y[y][x] =
(blur_x[0][x] + blur_x[1][x]) / 4;
}
}
Func blur_x, blur_y;
Var x, y;
blur_x(x, y) =
in(x, y) + in(x+1, y);
blur_y(x, y) =
(blur_x(x, y) + blur_x(x, y+1)) / 4;
blur_x.compute_at(blue_y, y);](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-42-320.jpg)

![ループアンロール
Func::unroll
– 指定した次元に対してループ展開を行う
• 分岐命令の削減
• ソフトウェアパイプライニング
• レジスタの再利用(レジスタブロッキング)
45
for (int y=0; y<height; y++)
for (int x=0; x<width; x++)
f[y][x] = x + y;
unroll前の等価なC++ソースコード
Func f;
Var x, y;
f(x, y) = x + y;](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-46-320.jpg)
![ループアンロール
Func::unroll
– 指定した次元に対してループ展開を行う
• 分岐命令の削減
• ソフトウェアパイプライニング
• レジスタの再利用(レジスタブロッキング)
46
Func f;
Var x, y;
f(x, y) = x + y;
f.unroll(x, 2);
for (int y=0; y<height; y++)
for (int x=0; x<width; x+=2) {
f[y][x] = x + y;
f[x+1][y] = x+1 + y;
}
for (int y=0; y<height; y++)
for (int x=0; x<width; x++)
f[y][x] = x + y;
unroll前の等価なC++ソースコード
Unroll後の等価なC++ソースコード
Unroll](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-47-320.jpg)
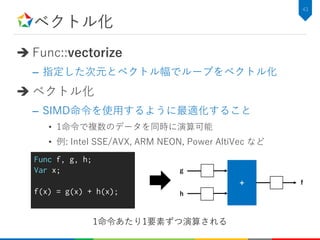
![タイリング
Func::tile
– 指定した次元とタイルサイズでループをタイル化する
• データの再利用性を高める
⇒キャッシュやローカルメモリなどを有効活用できる
47
Func f;
Var x, y;
f(x, y) = in(y, x);
f.tile(x, y, xi, yi, 16, 16);
for (int y=0; y<height; y+=16) {
for (int x=0; x<width; x+=16) {
for(int yi = 0; yi < 16; yi++) {
for(int xi = 0; xi < 16; xi++) {
f[y+yi][x+xi] = in[x+xi][y+yi];
}
}
}
}
Tile後の等価なC++ソースコード](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-48-320.jpg)


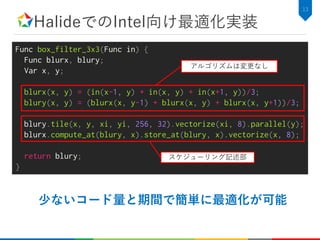
![アルゴリズム実装のみの性能
66.4
3.61
0
10
20
30
40
50
60
70
①: C++ ②: Halide
ExecutionTime[ms]
51
Halideで実装するだけで18.4倍の速度向上
– Halide版はLLVMで自動ベクトル化されているのを確認
18.4倍](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-52-320.jpg)
![ループアンロール適用後の性能
66.4
3.61 3.17
0
10
20
30
40
50
60
70
①: C++ ②: Halide ③: ②+unroll
ExecutionTime[ms]
55
20.9倍
ロード命令の削減により1.14倍の速度向上](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-56-320.jpg)
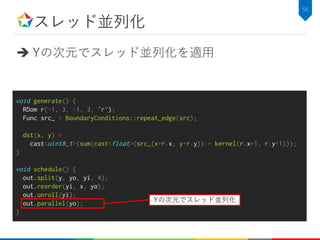
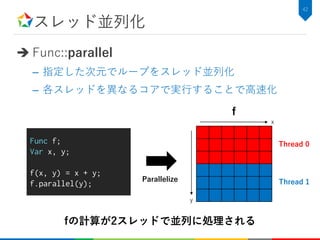
![スレッド並列化適用後の性能
66.4
3.61 3.17 0.52
0
10
20
30
40
50
60
70
①: C++ ②: Halide ③: ②+unroll ④: ③+parallel
ExecutionTime[ms]
57
127.7倍
スレッド並列化により6.10倍の速度向上
– スケジューリングを4行追加するだけで127.7倍の速度向上](https://image.slidesharecdn.com/hikalabhalide20171116public-171127022953/85/Halide-58-320.jpg)

























![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)

















































