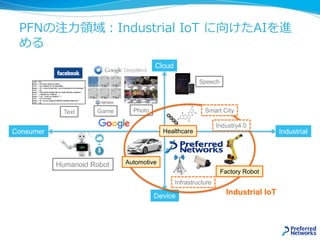
Accurate, Large MinibatchSGD: Training
ImageNet in 1 Hour [Goyal et.al 2017]
With these simple techniques, our Caffe2-based system trains ResNet- 50
with a minibatch size of 8192 on 256 GPUs in one hour, while matching
small minibatch accuracy. Using commodity hardware, our
implementation achieves ∼90% scaling efficiency when moving from 8
to 256 GPUs.








![典型的な計算負荷: U-Netの場合 [Ronneburger+2015]
NVIDIA TITAN で 10時間 (医療画像の2クラス分類)
https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/ より引用](https://image.slidesharecdn.com/20180227-nttcom-export-180305011204/85/20180227_-GPU-MN-1-10-320.jpg)
![自然言語によるロボット制御 [Hatori+2017]](https://image.slidesharecdn.com/20180227-nttcom-export-180305011204/85/20180227_-GPU-MN-1-11-320.jpg)
![GAN(Generative Adversarial Net)敵対的生成モデル
[Goodfellow+14]
二人のプレイヤーが競い合うことで学習する
ニセモノを作る人(Generator)
目標はDiscriminatorを騙すこと
本物そっくりのお金を作るように学習されていく
ニセモノを見破る人(Discriminator)
目標はGeneratorの嘘を見破ること
ほんのわずかな違いも見抜けるように学習されていく
Generator
本物のお金
Discriminator
本物かな ?偽物のお金
1/2でどちらか
選ばれる](https://image.slidesharecdn.com/20180227-nttcom-export-180305011204/85/20180227_-GPU-MN-1-13-320.jpg)

![画像生成のマルチタスク学習 [Miyato+2018]
8GPU 1週間
(1試行あたり)](https://image.slidesharecdn.com/20180227-nttcom-export-180305011204/85/20180227_-GPU-MN-1-15-320.jpg)

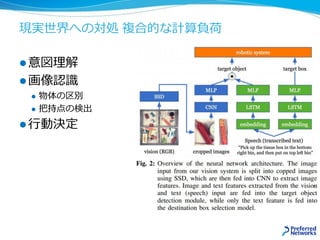
![代表的な学習手法
教師あり学習
入力xから出力yへの写像 y=f(x)を獲得する
学習データは正解のペア{(x, y)}
強化学習
環境において将来期待報酬を最大化する行動を獲得する
学習データは自分がとった状態とその時の報酬{(x, ri)}
教師なし学習
学習データはデータの集合{(xi)}、教師シグナルはそれ以外無い
観測情報はいくらでも得られる
[Doya 99]
大脳基底核
小脳
大脳皮質](https://image.slidesharecdn.com/20180227-nttcom-export-180305011204/85/20180227_-GPU-MN-1-17-320.jpg)






![機械学習による
LINPACKベンチマークの改善
LINPACK(HPL)
大規模行列計算(連立方程式の解を求める)
性能におおきな影響がある多数のパラメータ
計算の規模 (N) 計算の配置 (P, Q)
ブロードキャストアルゴリズムやさまざまなスレッショルド
パラメータの「勘と経験による調整」を自動化
Hyperopt[Bergstra+2011]
機械学習によるパラメータチューニングライブラリ
今回のLINPACKの最適化に適用
とはいえ、小規模から徐々に規模を増やしつつ探索範囲を狭めて
いかないと組み合わせ爆発+実行時間の拡大で大変なことになる
それなりのノウハウは依然必要
PFN鈴木](https://image.slidesharecdn.com/20180227-nttcom-export-180305011204/85/20180227_-GPU-MN-1-25-320.jpg)



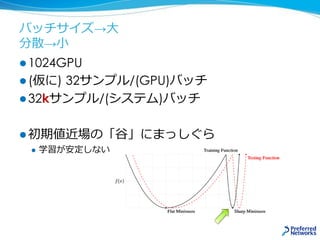
![Sharp Minima [Keskar et.al, 2016]](https://image.slidesharecdn.com/20180227-nttcom-export-180305011204/85/20180227_-GPU-MN-1-30-320.jpg)
![Accurate, Large Minibatch SGD: Training
ImageNet in 1 Hour [Goyal et.al 2017]
With these simple techniques, our Caffe2-based system trains ResNet- 50
with a minibatch size of 8192 on 256 GPUs in one hour, while matching
small minibatch accuracy. Using commodity hardware, our
implementation achieves ∼90% scaling efficiency when moving from 8
to 256 GPUs.](https://image.slidesharecdn.com/20180227-nttcom-export-180305011204/85/20180227_-GPU-MN-1-32-320.jpg)
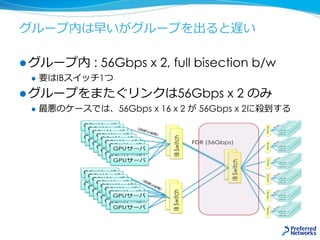
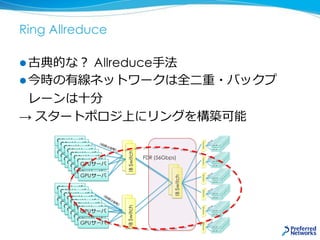
![ImageNet in 15min. ポイント [Akiba et.al 2017]
NVIDIA製NCCL2を利用
ノードをまたぐ集団通信アルゴリズムもオーバーヘッドが少ない
学習率の変更やチューニング
Goyalとほぼ同じ方式
Optimizerを学習初期の
RMSPropからスムーズに
SGDに入れ替える
通信だけfp16 計算はfp32
32k sample/バッチ
1024GPUでも
比較的順当にスケール](https://image.slidesharecdn.com/20180227-nttcom-export-180305011204/85/20180227_-GPU-MN-1-33-320.jpg)







































![[基調講演] Deep Learning: IoT's Driving Engine](https://cdn.slidesharecdn.com/ss_thumbnails/dllabdaykeynotenishikawa-180704002744-thumbnail.jpg?width=640&height=640&fit=bounds)






![[db analytics showcase Sapporo 2017] B14: GPU コンピューティング最前線 by エヌビディア 佐々木邦暢](https://cdn.slidesharecdn.com/ss_thumbnails/20170630dbassprnvidia-170707074715-thumbnail.jpg?width=640&height=640&fit=bounds)






















