More Related Content

PDF

PDF

PDF

PPTX

ZIP

PDF
ARM CPUにおけるSIMDを用いた高速計算入門 ![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介 
PDF
What's hot

PDF
Pythonの理解を試みる 〜バイトコードインタプリタを作成する〜 
PDF

PDF

PDF

PDF

PPT

PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか) 
PDF

PDF
Intro to SVE 富岳のA64FXを触ってみた 
PDF
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~ 
PDF
z変換をやさしく教えて下さい (音響学入門ペディア) 
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~ 
PDF
Transformerを多層にする際の勾配消失問題と解決法について 
PPTX
![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Focal Loss for Dense Object Detection 
PDF

PDF

PDF

PDF

PDF
Similar to AVX-512(フォーマット)詳解

PDF

PDF

PDF
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen 
PDF
Intel AVX2を使用したailia sdkの最適化 
PDF

PDF

PPTX

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PPTX

PPTX

PPTX

PDF
More from MITSUNARI Shigeo

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法 
PDF

PDF

PDF
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化 
PDF

PDF

PDF

PDF
AVX-512(フォーマット)詳解
- 1.
- 2.
- 3.
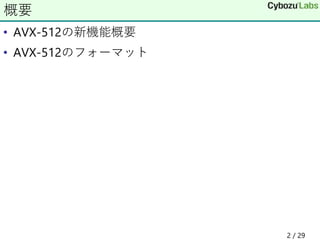
• 32個の512 bitSIMDレジスタ
• zmm0, zmm1, ..., zmm31
• 一つのSIMDレジスタには整数や小数が複数入る
• double(64bit) x 8, qword(64bit) x 8, float(32bit) x 16
• dword(32bit) x 16, word(16bit) x 32, byte(8bit) x 64など
• 一部の整数は符号あり・符号無しを選択可能
• 下位256bitは従来のymmレジスタとしてアクセス可能
• その下位128bitは従来のxmmレジスタとしてアクセス可能
AVX-512
zmm0
ymm0
xmm0
63 31 15 0
3 / 29
- 4.
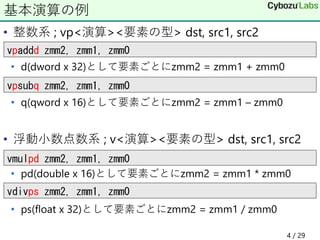
• 整数系 ;vp<演算><要素の型> dst, src1, src2
• d(dword x 32)として要素ごとにzmm2 = zmm1 + zmm0
• q(qword x 16)として要素ごとにzmm2 = zmm1 – zmm0
• 浮動小数点数系 ; v<演算><要素の型> dst, src1, src2
• pd(double x 16)として要素ごとにzmm2 = zmm1 * zmm0
• ps(float x 32)として要素ごとにzmm2 = zmm1 / zmm0
基本演算の例
vpaddd zmm2, zmm1, zmm0
vpsubq zmm2, zmm1, zmm0
vmulpd zmm2, zmm1, zmm0
vdivps zmm2, zmm1, zmm0
4 / 29
- 5.
• AVX512F(foundation)
• blend,pcmp, ptest, compress等
• CD(Conflict Detection)
• 競合検出 ループ処理での補助
• ER(Exponential and Reciprocal)
• 指数と逆数
• PF(prefetch)
• プリフェッチ
• BW(byte, word), DQ(dword, qword)
• VL(Vector length)
• xmm, ymmレジスタ利用可能
演算グループ(1/2)
5 / 29
- 6.
• VBMI(Vector byteManipulation Instructions)
• pcompress, pexpand, pshld, vpermi2bなど
• IFMA(Integer Fused Multiply Add)
• 52bit整数の積の上位/下位52bitを加算
• 4FMAPS
(Fused Multiply Accumulation Packed Single Precision)
• 16個のfloat[]の積和演算4個を1命令で
• 4VNNIW(Vector Neural Network Instructions Word
variable precision)
• 4個のword[]の積和(結果はdword)16個を1命令で
• GFNI(Galois Field系)
• 標数2の8次拡大体の元のアフィン変換/逆変換を1命令で
演算グループ(2/2)
6 / 29
- 7.
• 共通
• BAIC= AVX512{F, CD}
• 主に浮動小数点数強化系
• Knights Landing = BASIC + AVX512{ER, PF}
• Knights Mill = Knights Landing + AVX512_{4FMAPS, 4VNNIW}
• 主に整数強化系
• Skylake = BASIC + AVX512{BW, DQ, VL}
• Cannon Lake = Skylake + AVX512_{VBMI, IFMA}
• Ice Lake = Cannon Lake + AVX512_{VBMI2, VNNI, GFNI, ... }
対応CPU
7 / 29
- 8.
• SIMDは特定の要素の例外処理が面倒
• AVX2までのやり方
•vcmppdで要素ごとに(a[i] > 1.0) ? (-1) : 0のマスクMを生成
• M &= a[i] ; 要素ごとにa[i] or 0
• M *= b[i] ; 要素ごとにa[i] * b[i] or 0
• vblendvpd命令で要素ごとにa[i] * b[i]かb[i]を選択
SIMDの苦手なこと
double *a, *b, *c;
for (int i = 0; i < n; i++) {
double x = b[i];
if (a[i] > 1.0) x *= a[i];
c[i] = x;
}
8 / 29
- 9.
• 要素ごとにマスク設定が可能になった
• 64bitマスクレジスタk1,..., k7
• k0もあるがマスク設定には使えない
• 要素数だけマスクレジスタの下位bitが参照される
• 8byte x 64なら64bit, 32byte x 16なら16bit
• マスクレジスタの扱い
• 該当bitが1 ; 該当要素の処理が行われる
• 該当bitが0
• ゼロ化マスクなし
• 操作は行われない(例外や違反は発生しない)
• ゼロ化マスクあり
• 0で埋められる
AVX-512におけるマスク処理
9 / 29
- 10.
- 11.
• vmovdqu8(byte単位のレジスタコピー)
• k1レジスタのビットが立っているところだけコピー
•それ以外は0クリア
ゼロ化マスクの例
[Xf Xe Xd Xc Xb Xa X9 X8 X7 X6 X5 X4 X3 X2 X1 X0]xmm0
[Yf Ye Yd Yc Yb Ya Y9 Y8 Y7 Y6 Y5 Y4 Y3 Y2 Y1 Y0]xmm1
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0]k1
[00 00 00 00 00 00 00 00 00 00 00 X4 00 00 X1 00]xmm1
vmovdqu8 xmm1{k1}{z}, xmm0
11 / 29
- 12.
• 再掲
• AVX-512のマスクレジスタを利用
先程のサンプルの例
double*a, *b, *c;
for (int i = 0; i < n; i++) {
double x = b[i];
if (a[i] > 1.0) x *= a[i];
c[i] = x;
}
// zmm2 = [1.0 ... 1.0]を設定しておく
vmovups zmm0, [a] ; double x 16読み
vmovups zmm1, [b]
vcmppd k1, zmm2, zmm0, 1 ; k1=[(zmm2 < zmm0) ? 1 : 0]
vmulpd zmm1{k1}, zmm0, zmm1 ; a[i] > 1のところだけ乗算
vmovups [c], zmm1
12 / 29
- 13.
• マスクのコスト
• ロードでブレンド操作が行われるため少し低速
•デスティネーション(以下dstと略記)との依存関係が発生
• ゼロ化マスクではこの依存関係は切れる
• 可能な限りゼロ化マスクを使う
• メモリへの書き込みはマージmaskのみ
• 書き込みアドレスが書き込み禁止領域にまたがっていても
マスクレジスタでマスクされていると例外は発生しない
マスクレジスタの注意点
+0 +1 +2 +3 +4 +5 +6 +7 +8|+9 +a +b +c +d +e +f
[yy yy yy yy yy yy yy yy yy|xx xx xx xx xx xx xx]
書き込み禁止領域書き込み可能領域
k1 = (1 << 9) – 1のとき
13 / 29
- 14.
• 複数の条件のandやorを効率よく計算するために
マスクレジスタの演算命令が追加されている
• k<演算>{b,w,d,q}dst, src1, src2の形
• add, and, or, not, xor
• andn(x, y) := ~(x & y)
• xnor(x, y) := ~(x ^ y)
• shiftl, shiftrなど
• ZF, CF制御系
• kortest{b,w,d,q} src1, src2
• (src1 | src2) == 0ならZF = 1
• (src1 | src2) == ~0ならCF = 1
• vcomiss x, yよりvcomiss k, x, y; kortest k, kの方が速いらしい
マスクレジスタの演算
14 / 29
- 15.
• マスクレジスタが立っているところだけ集める
データ圧縮
[Xf XeXd Xc Xb Xa X9 X8 X7 X6 X5 X4 X3 X2 X1 X0]xmm0
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0]k1
[00 00 00 00 00 00 00 00 00 00 00 00 00 00 X4 X1]xmm1
vcompresspd xmm1{k1}, xmm0
15 / 29
- 16.
- 17.
• メイン部分
AVX-512によるデータ圧縮
// rsi= a, rdi = b, zmm0 = rax = rdx = 0
.lp:
vmovdqa32 zmm1, [rsi + rax * 4] ; zmm1 = a[]
vpcmpgtd k1, zmm1, zmm0 ; k1 = [(a > 0)?1:0]
vpcompressd zmm2{k1}, zmm1 ; zmm2 = comp(a[])
vmovdqu32 [rdi + rdx * 4], zmm2 ; b[] = zmm2
kmovd ecx, k1
popcnt rcx, rcx ; コピーした個数だけ
add rdx, rcx ; bのポインタを増やす
add rax, 16 ; aは16ずつ増やす
cmp rax, n
jne .lp
17 / 29
- 18.
• マスクレジスタが立っているところに下から入れる
データ展開
[Xf XeXd Xc Xb Xa X9 X8 X7 X6 X5 X4 X3 X2 X1 X0]xmm0
[ 0 0 0 1 0 0 0 0 0 1 0 1 0 0 1 0]k1
[00 00 00 X3 00 00 00 00 00 X2 00 X1 00 00 X0 00]xmm1
vcompresspd xmm1{k1}{z}, xmm0
18 / 29
- 19.
• 32 or64bitの値をSIMDレジスタに複数個コピー
• 従来
• AVX-512
• 外に{1to8}, {1to4}など
• レジスタ種別(xmm/ymm/zmm)と
データの型(float/double)で{1toX}のXは一意に決まる
• Xbyakではptr_b[rax]と書けるようにした
ブロードキャストフラグ
vbroadcastss zmm0, [rax] ; [rax]のfloat1個を16個コピー
vmulps zmm2, zmm1, zmm0
vmulps zmm2, zmm1, [rax]{1to16}
19 / 29
- 20.
• 従来
• 浮動小数点数の演算結果の丸め方はMXCSRレジスタに依存
•MXCSRの変更はコストが大きい
• round系は小数→小数のみ, cvtt系は小数→整数の切り捨てのみ
• AVX-512
• ほとんどの命令毎に丸め方を指定可能
• rne(round to nearest even) ; 最も近い偶数
• rd(round down) ; 切り下げ
• ru(round up) ; 切り上げ
• rz(round toward zero) ; ゼロへの丸め
• 同時に例外抑制SAE(suppress all exceptions)も行われる
組み込み丸め操作
vcvtsd2si eax,xmm0,{rz-sae} ;小数→整数のゼロへの丸め
20 / 29
- 21.
• 1bitが3個の入力x, y,zに対して1bitのwを出力する関数f
• f(x, y, z) = w ; fは8bit定数imm8を一つ決めると決まる
• vpternlog x, y, z, imm8 ; x = f(x, y, z)
imm8=e8h
• 例)SHA関数の中のf(a, b, c) = ((a | b) & c) | (a & b)や
f(a, b, c) = a ^ (b ^ (c ^ a))はvpternlog1命令にできる
3値論理(ternary logic)
x y z w
0 0 0 0
0 0 1 0
0 1 0 0
0 1 1 1
1 0 0 0
1 0 1 1
1 1 0 1
1 1 1 1
21 / 29
- 22.
• ModR/M
• movdst, src / mov dst, [src] / mov dst, [src + disp]
などの1byteエンコーディング規則
• mod
• 00 ; dst, [src]
• 01 ; dst, [src + disp8](8bitオフセット)
• 10 ; dst, [src + disp32](32bitオフセット)
• 11 ; dst, src
• reg
• 8種類のレジスタを3bitで指定
• r/m
• srcのレジスタを指定
IA-32のフォーマット復習(1/2)
[ 7 6| 5 4 3| 2 1 0]
[ mod | reg | r/m ]
22 / 29
- 23.
• SIB(Scale IndexByte)
• mov eax, [ecx + edx * 4 + disp]などのエンコーディング規則
• [base + index * scale + disp]
• base
• レジスタ種別
• index
• レジスタ種別
• scale
• 1, 2, 4, 8倍をそれぞれ00, 01, 10, 11で表現
IA-32のフォーマット復習(2/2)
[ 7 6| 5 4 3| 2 1 0]
[scale| index | base ]
23 / 29
- 24.
• modR/M +SIB
• ~32bit, レジスタ8個
• REXプレフィクス(1byte)
• inc/dec reg16を廃止して利用
• 64bit, レジスタ16個対応
• VEXプレフィクス(2-3byte, Vector Extension)
• les, ldsの隙間を利用
• 3オペランド, 256bitレジスタ対応
• デコーダの負担を低減
• EVEXプレフィクス(4byte, Enhanced VEX)
• 64bitモードで廃止されていたbound(0x62)始まり
• 512bit, レジスタ32個対応
• マスクレジスタ、丸めモード、ブロードキャストなど
エンコーディングの歴史
24 / 29
- 25.
• テスト
• mmとppは従来のVEXプレフィクス関係
•zはゼロ化フラグ, L’Lはレジスタ長や丸めモード
EVEX
| EVEX |
|62 P0 P1 P2| opcode ModRM/M [SIB] [Disp] [Imm]
| 7 6 5 4 3 2 1 0 |
P0 | R | X | B | R'| 0 | 0 | m | m |
P1 | W | v | v | v | v | 1 | p | p |
P2 | z | L'| L | b | V'| a | a | a |
vaddpd a4a3a2a1a0,{k_aaa},b4b3b2b1b0,c4c3c2c1c0
| P0 | P1 | P2 |
62|!a3 !c4 !c3 !a4 0001|1 b3 b2 b1 b0 101|0100 !b4 aaa|
| ModRM/M |
<opcode> |11 a2 a1 a0 c2 c1 c0| [SIB] [Disp]
25 / 29
- 26.
• メモリアクセスのディスプレースメント(disp)は
符号つき8bit以内なら1byte, それ以外は4byte必要
•AVX-512ではzmm1個で64byteなので2個分のオフセッ
ト(128)でオーバーする
• これはデコーダに辛い
• 通常ループアンロールなどで使うのは0x40, 0x80, 0xc0など
64byteの倍数のはず
• オフセットがN(=64など)の倍数なら圧縮disp8を使う変更
圧縮disp8*N(1/2)
mov rax, [rax + 0x7f] ; 48 8B 40 7F ; disp8
mov rax, [rax + 0x80] ; 48 8B 80 80 00 00 00 ; disp32
vaddpd zmm0, zmm1, [rax] ;62F1F5485800 6byte
vaddpd zmm0, zmm1, [rax+0x80];62F1F548588080000000 10byte
26 / 29
- 27.
• 命令長が7byteに収まる
• その代わり[rax+1]などはdisp8でなくdisp32で表現
•余談
• 命令毎にdisp8*NのNの値のパターンが異なる
• Tuple TypeはInputSizeにより変わるのでややこしい
圧縮disp8*N(2/2)
vaddpd zmm0, zmm1, [rax+64] ; 62F1F548584001
vaddpd zmm0, zmm1, [rax+128]; 62F1F548584002
vaddpd zmm0, zmm1, [rax+192]; 62F1F548584003
vaddpd zmm0, zmm1, [rax+256]; 62F1F548584004
vaddpd zmm0, zmm1, [rax+1] ; 62F1F548588001000000
27 / 29
- 28.
• v4fmaddps zmm1,zmm<base>, [mem]
• zmm<base>, ..., zmm<base+3>とfloat mem[4]の積和を
zmm1に加算(baseは4の倍数)
• zmm4を指定すればzmm4, zmm5, zmm6, zmm7が参照される
• 擬似コード
• デコーダの負担を減らすため?
v4fmaddps(Knights Mill以降)
v4fmaddps(zmm dest, zmm[base], float mem[4]) {
floatX16 tmp = dest;
for (j = 0; j < 4; j++) {
for (i = 0; i < 16; i++) {
tmp[i] += zmm[base + j][i] * msrc[j];
}
dest = tmp;
} }
28 / 29
- 29.
• Intelのマニュアル&エミュレータ(SDE)
• https://software.intel.com/en-us/articles/intel-sdm
•https://software.intel.com/en-us/articles/intel-software-
development-emulator
• software developer‘s manual(325383-065US)の間違い
• p.1312のVSQRTPD xmm1 {k1}{z}, xmm2/m128/m32bcst
などはm64bcstの間違い
• Optimization Reference Manual(248966-039)の間違い
• p.540のvmovaps zmm1{k1}{z}, zmm0の結果の図がおかしい
• p.552の図15.5 Data Expand Operationがおかしい
• @tanakmuraさんのAVX-512 Advent Calendar 2014
• https://qiita.com/advent-calendar/2014/avx512
参考文献
29 / 29




![• VBMI(Vector byte Manipulation Instructions)
• pcompress, pexpand, pshld, vpermi2bなど
• IFMA(Integer Fused Multiply Add)
• 52bit整数の積の上位/下位52bitを加算
• 4FMAPS
(Fused Multiply Accumulation Packed Single Precision)
• 16個のfloat[]の積和演算4個を1命令で
• 4VNNIW(Vector Neural Network Instructions Word
variable precision)
• 4個のword[]の積和(結果はdword)16個を1命令で
• GFNI(Galois Field系)
• 標数2の8次拡大体の元のアフィン変換/逆変換を1命令で
演算グループ(2/2)
6 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-6-320.jpg)

![• SIMDは特定の要素の例外処理が面倒
• AVX2までのやり方
• vcmppdで要素ごとに(a[i] > 1.0) ? (-1) : 0のマスクMを生成
• M &= a[i] ; 要素ごとにa[i] or 0
• M *= b[i] ; 要素ごとにa[i] * b[i] or 0
• vblendvpd命令で要素ごとにa[i] * b[i]かb[i]を選択
SIMDの苦手なこと
double *a, *b, *c;
for (int i = 0; i < n; i++) {
double x = b[i];
if (a[i] > 1.0) x *= a[i];
c[i] = x;
}
8 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-8-320.jpg)

![• vmovdqu8(byte単位のレジスタコピー)
• k1レジスタのビットが立っているところだけコピー
マスクの例
[Xf Xe Xd Xc Xb Xa X9 X8 X7 X6 X5 X4 X3 X2 X1 X0]xmm0
[Yf Ye Yd Yc Yb Ya Y9 Y8 Y7 Y6 Y5 Y4 Y3 Y2 Y1 Y0]xmm1
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0]k1
[Yf Ye Yd Yc Yb Ya Y9 Y8 Y7 Y6 Y5 X4 Y3 Y2 X1 Y0]xmm1
vmovdqu8 xmm1{k1}, xmm0
10 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-10-320.jpg)
![• vmovdqu8(byte単位のレジスタコピー)
• k1レジスタのビットが立っているところだけコピー
• それ以外は0クリア
ゼロ化マスクの例
[Xf Xe Xd Xc Xb Xa X9 X8 X7 X6 X5 X4 X3 X2 X1 X0]xmm0
[Yf Ye Yd Yc Yb Ya Y9 Y8 Y7 Y6 Y5 Y4 Y3 Y2 Y1 Y0]xmm1
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0]k1
[00 00 00 00 00 00 00 00 00 00 00 X4 00 00 X1 00]xmm1
vmovdqu8 xmm1{k1}{z}, xmm0
11 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-11-320.jpg)
![• 再掲
• AVX-512のマスクレジスタを利用
先程のサンプルの例
double *a, *b, *c;
for (int i = 0; i < n; i++) {
double x = b[i];
if (a[i] > 1.0) x *= a[i];
c[i] = x;
}
// zmm2 = [1.0 ... 1.0]を設定しておく
vmovups zmm0, [a] ; double x 16読み
vmovups zmm1, [b]
vcmppd k1, zmm2, zmm0, 1 ; k1=[(zmm2 < zmm0) ? 1 : 0]
vmulpd zmm1{k1}, zmm0, zmm1 ; a[i] > 1のところだけ乗算
vmovups [c], zmm1
12 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-12-320.jpg)
![• マスクのコスト
• ロードでブレンド操作が行われるため少し低速
• デスティネーション(以下dstと略記)との依存関係が発生
• ゼロ化マスクではこの依存関係は切れる
• 可能な限りゼロ化マスクを使う
• メモリへの書き込みはマージmaskのみ
• 書き込みアドレスが書き込み禁止領域にまたがっていても
マスクレジスタでマスクされていると例外は発生しない
マスクレジスタの注意点
+0 +1 +2 +3 +4 +5 +6 +7 +8|+9 +a +b +c +d +e +f
[yy yy yy yy yy yy yy yy yy|xx xx xx xx xx xx xx]
書き込み禁止領域書き込み可能領域
k1 = (1 << 9) – 1のとき
13 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-13-320.jpg)

![• マスクレジスタが立っているところだけ集める
データ圧縮
[Xf Xe Xd Xc Xb Xa X9 X8 X7 X6 X5 X4 X3 X2 X1 X0]xmm0
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0]k1
[00 00 00 00 00 00 00 00 00 00 00 00 00 00 X4 X1]xmm1
vcompresspd xmm1{k1}, xmm0
15 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-15-320.jpg)
![• a[]が正のところだけb[]につめていく
データ圧縮の例
assert(n % 16 == 0);
uint32_t a[n];
uint32_t b[n];
j = 0;
for (int i = 0; i < n; i++) {
if (a[i] > 0) {
b[j++] = a[i];
}
}
16 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-16-320.jpg)
![• メイン部分
AVX-512によるデータ圧縮
// rsi = a, rdi = b, zmm0 = rax = rdx = 0
.lp:
vmovdqa32 zmm1, [rsi + rax * 4] ; zmm1 = a[]
vpcmpgtd k1, zmm1, zmm0 ; k1 = [(a > 0)?1:0]
vpcompressd zmm2{k1}, zmm1 ; zmm2 = comp(a[])
vmovdqu32 [rdi + rdx * 4], zmm2 ; b[] = zmm2
kmovd ecx, k1
popcnt rcx, rcx ; コピーした個数だけ
add rdx, rcx ; bのポインタを増やす
add rax, 16 ; aは16ずつ増やす
cmp rax, n
jne .lp
17 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-17-320.jpg)
![• マスクレジスタが立っているところに下から入れる
データ展開
[Xf Xe Xd Xc Xb Xa X9 X8 X7 X6 X5 X4 X3 X2 X1 X0]xmm0
[ 0 0 0 1 0 0 0 0 0 1 0 1 0 0 1 0]k1
[00 00 00 X3 00 00 00 00 00 X2 00 X1 00 00 X0 00]xmm1
vcompresspd xmm1{k1}{z}, xmm0
18 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-18-320.jpg)
![• 32 or 64bitの値をSIMDレジスタに複数個コピー
• 従来
• AVX-512
• 外に{1to8}, {1to4}など
• レジスタ種別(xmm/ymm/zmm)と
データの型(float/double)で{1toX}のXは一意に決まる
• Xbyakではptr_b[rax]と書けるようにした
ブロードキャストフラグ
vbroadcastss zmm0, [rax] ; [rax]のfloat1個を16個コピー
vmulps zmm2, zmm1, zmm0
vmulps zmm2, zmm1, [rax]{1to16}
19 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-19-320.jpg)


![• ModR/M
• mov dst, src / mov dst, [src] / mov dst, [src + disp]
などの1byteエンコーディング規則
• mod
• 00 ; dst, [src]
• 01 ; dst, [src + disp8](8bitオフセット)
• 10 ; dst, [src + disp32](32bitオフセット)
• 11 ; dst, src
• reg
• 8種類のレジスタを3bitで指定
• r/m
• srcのレジスタを指定
IA-32のフォーマット復習(1/2)
[ 7 6| 5 4 3| 2 1 0]
[ mod | reg | r/m ]
22 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-22-320.jpg)
![• SIB(Scale Index Byte)
• mov eax, [ecx + edx * 4 + disp]などのエンコーディング規則
• [base + index * scale + disp]
• base
• レジスタ種別
• index
• レジスタ種別
• scale
• 1, 2, 4, 8倍をそれぞれ00, 01, 10, 11で表現
IA-32のフォーマット復習(2/2)
[ 7 6| 5 4 3| 2 1 0]
[scale| index | base ]
23 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-23-320.jpg)

![• テスト
• mmとppは従来のVEXプレフィクス関係
• zはゼロ化フラグ, L’Lはレジスタ長や丸めモード
EVEX
| EVEX |
|62 P0 P1 P2| opcode ModRM/M [SIB] [Disp] [Imm]
| 7 6 5 4 3 2 1 0 |
P0 | R | X | B | R'| 0 | 0 | m | m |
P1 | W | v | v | v | v | 1 | p | p |
P2 | z | L'| L | b | V'| a | a | a |
vaddpd a4a3a2a1a0,{k_aaa},b4b3b2b1b0,c4c3c2c1c0
| P0 | P1 | P2 |
62|!a3 !c4 !c3 !a4 0001|1 b3 b2 b1 b0 101|0100 !b4 aaa|
| ModRM/M |
<opcode> |11 a2 a1 a0 c2 c1 c0| [SIB] [Disp]
25 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-25-320.jpg)
![• メモリアクセスのディスプレースメント(disp)は
符号つき8bit以内なら1byte, それ以外は4byte必要
• AVX-512ではzmm1個で64byteなので2個分のオフセッ
ト(128)でオーバーする
• これはデコーダに辛い
• 通常ループアンロールなどで使うのは0x40, 0x80, 0xc0など
64byteの倍数のはず
• オフセットがN(=64など)の倍数なら圧縮disp8を使う変更
圧縮disp8*N(1/2)
mov rax, [rax + 0x7f] ; 48 8B 40 7F ; disp8
mov rax, [rax + 0x80] ; 48 8B 80 80 00 00 00 ; disp32
vaddpd zmm0, zmm1, [rax] ;62F1F5485800 6byte
vaddpd zmm0, zmm1, [rax+0x80];62F1F548588080000000 10byte
26 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-26-320.jpg)
![• 命令長が7byteに収まる
• その代わり[rax+1]などはdisp8でなくdisp32で表現
• 余談
• 命令毎にdisp8*NのNの値のパターンが異なる
• Tuple TypeはInputSizeにより変わるのでややこしい
圧縮disp8*N(2/2)
vaddpd zmm0, zmm1, [rax+64] ; 62F1F548584001
vaddpd zmm0, zmm1, [rax+128]; 62F1F548584002
vaddpd zmm0, zmm1, [rax+192]; 62F1F548584003
vaddpd zmm0, zmm1, [rax+256]; 62F1F548584004
vaddpd zmm0, zmm1, [rax+1] ; 62F1F548588001000000
27 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-27-320.jpg)
![• v4fmaddps zmm1, zmm<base>, [mem]
• zmm<base>, ..., zmm<base+3>とfloat mem[4]の積和を
zmm1に加算(baseは4の倍数)
• zmm4を指定すればzmm4, zmm5, zmm6, zmm7が参照される
• 擬似コード
• デコーダの負担を減らすため?
v4fmaddps(Knights Mill以降)
v4fmaddps(zmm dest, zmm[base], float mem[4]) {
floatX16 tmp = dest;
for (j = 0; j < 4; j++) {
for (i = 0; i < 16; i++) {
tmp[i] += zmm[base + j][i] * msrc[j];
}
dest = tmp;
} }
28 / 29](https://image.slidesharecdn.com/avx-512-180217060609/85/AVX-512-28-320.jpg)
