Downloaded 906 times


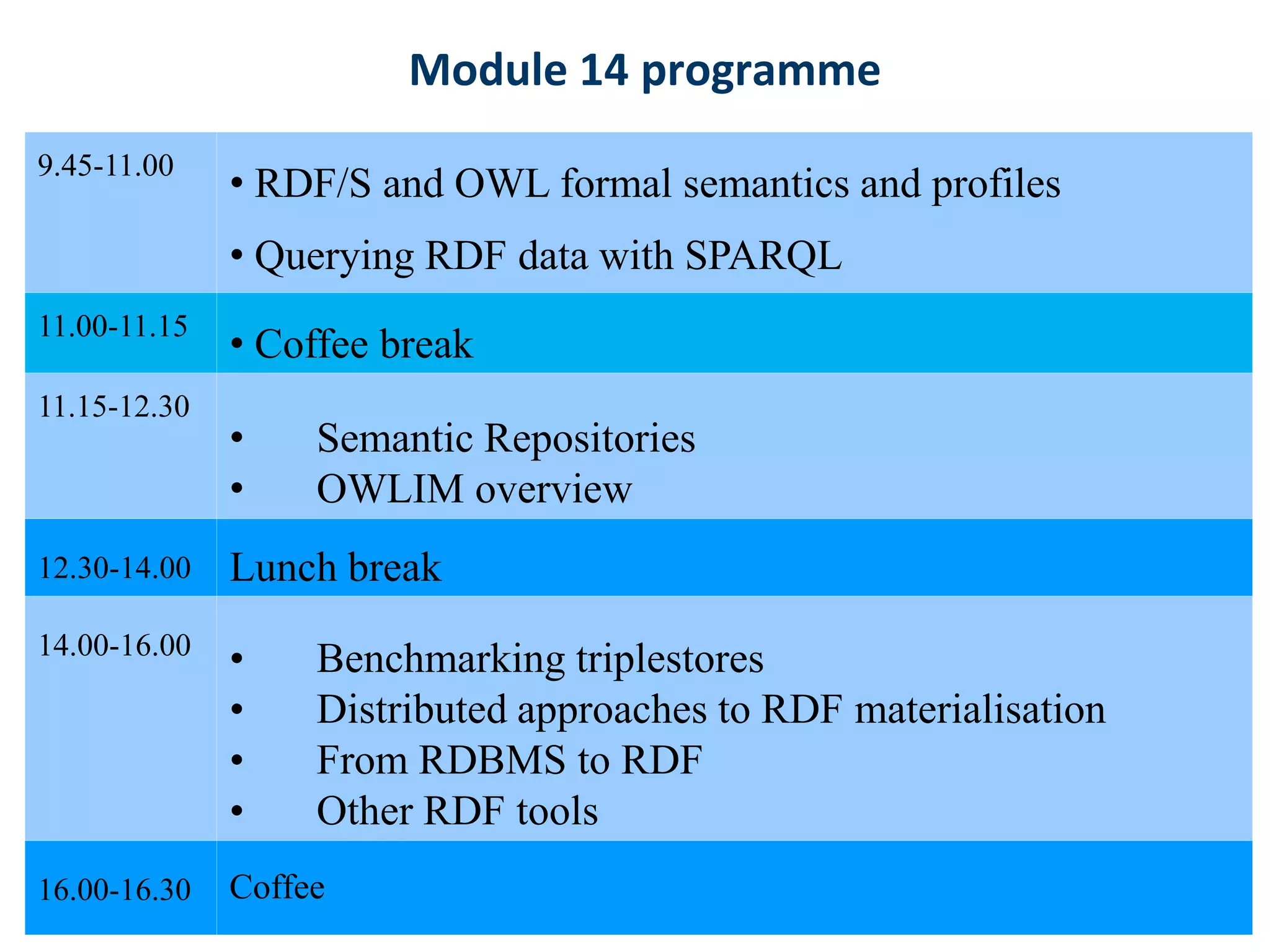


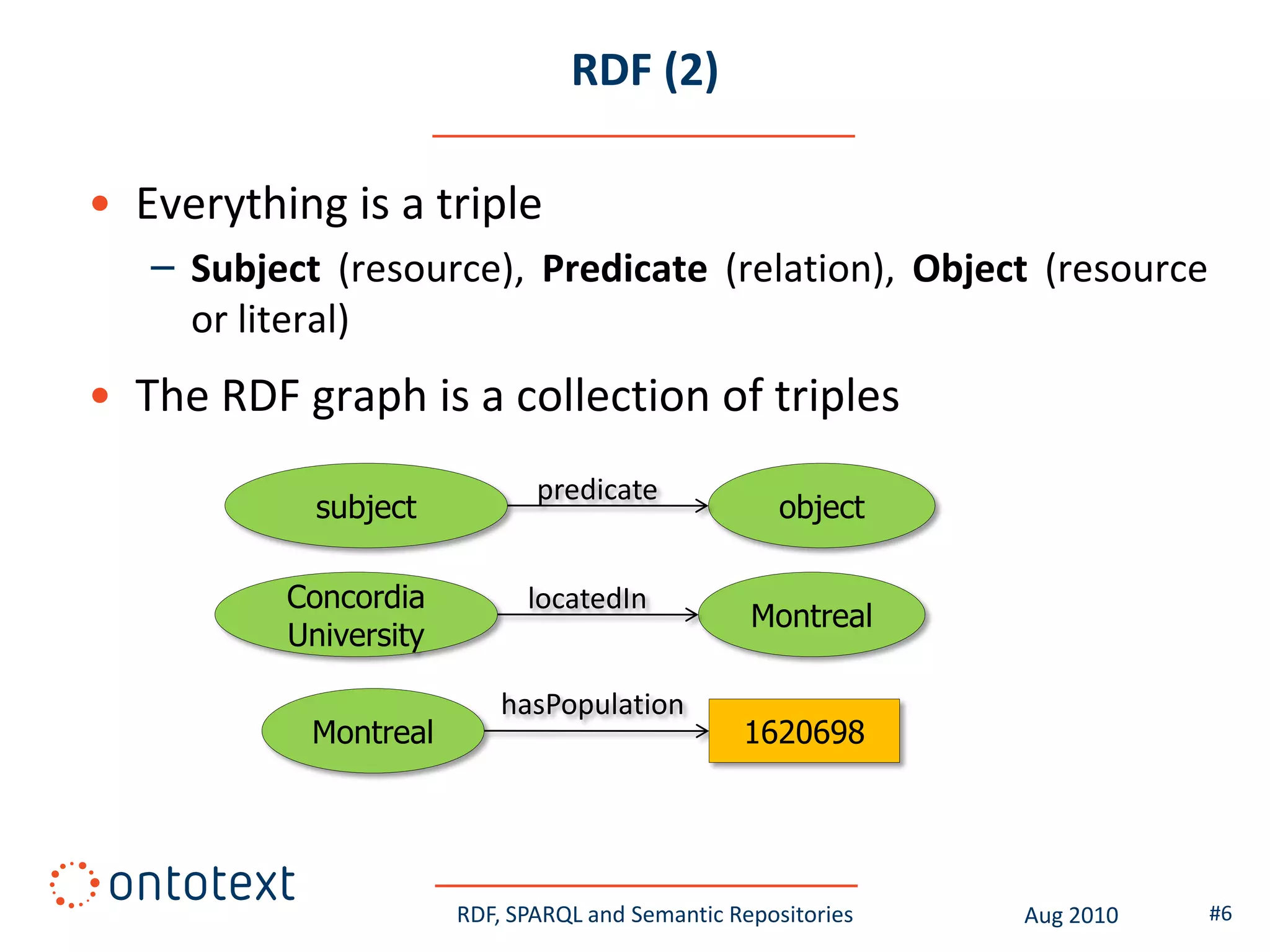
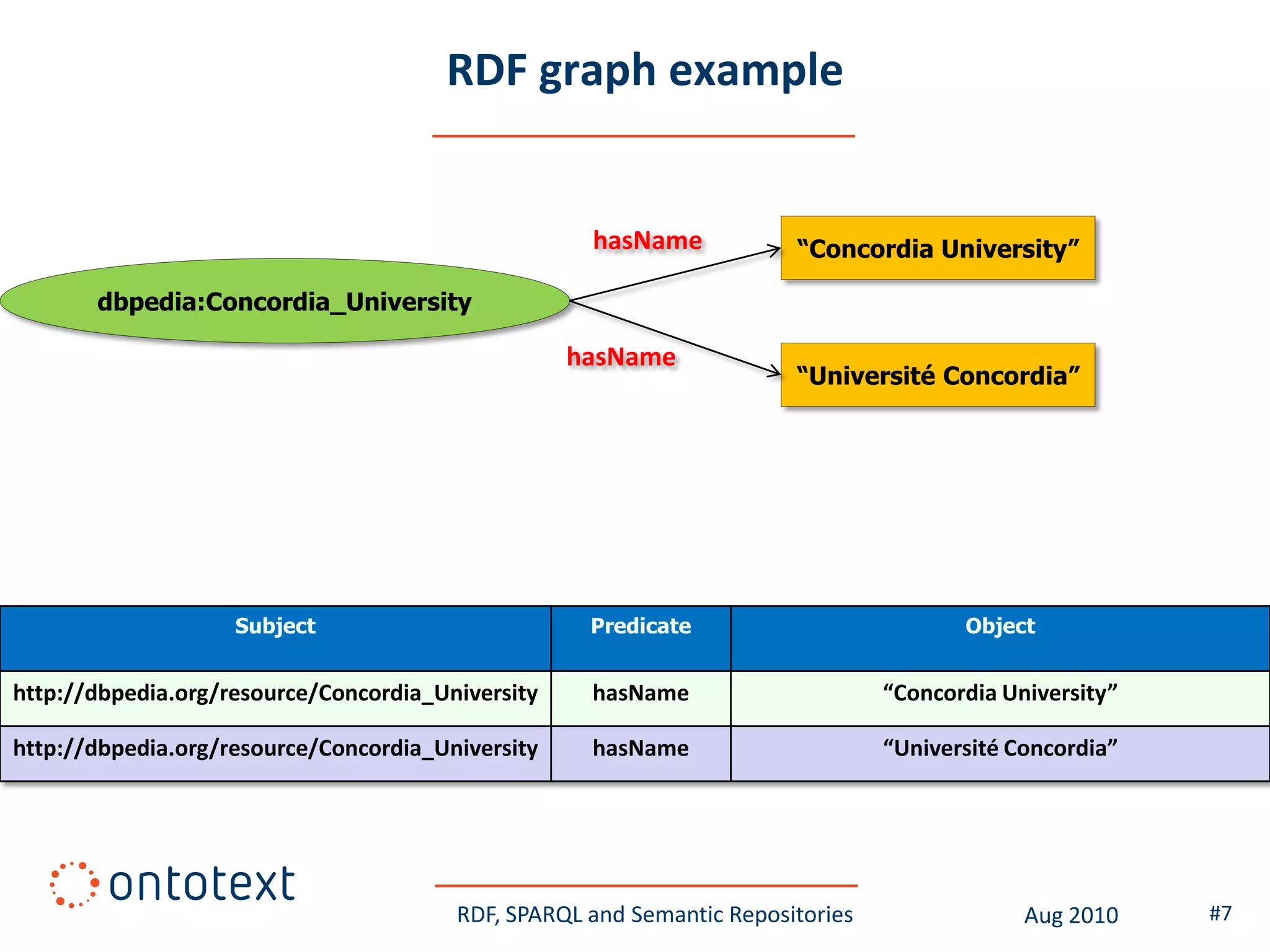
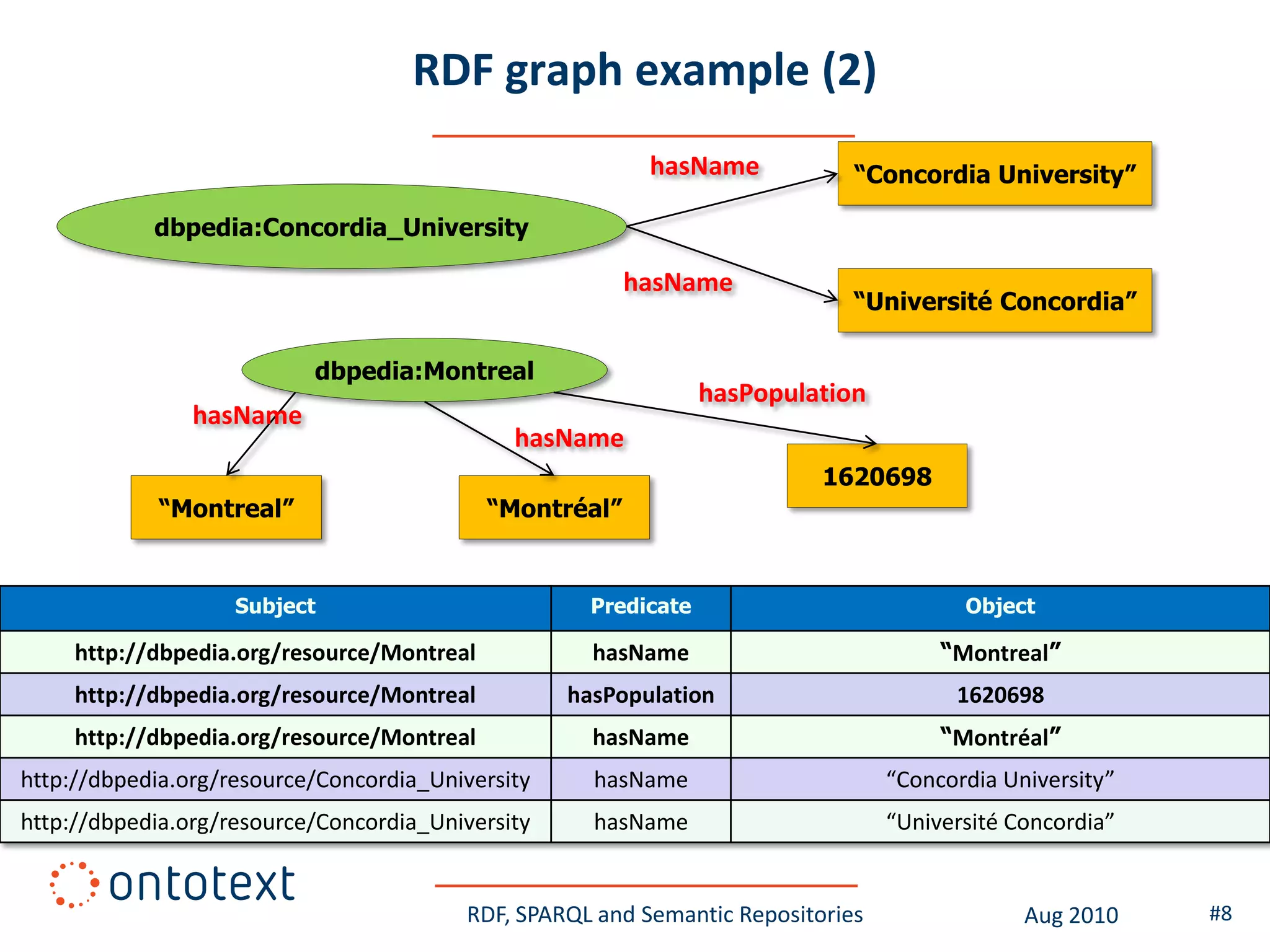
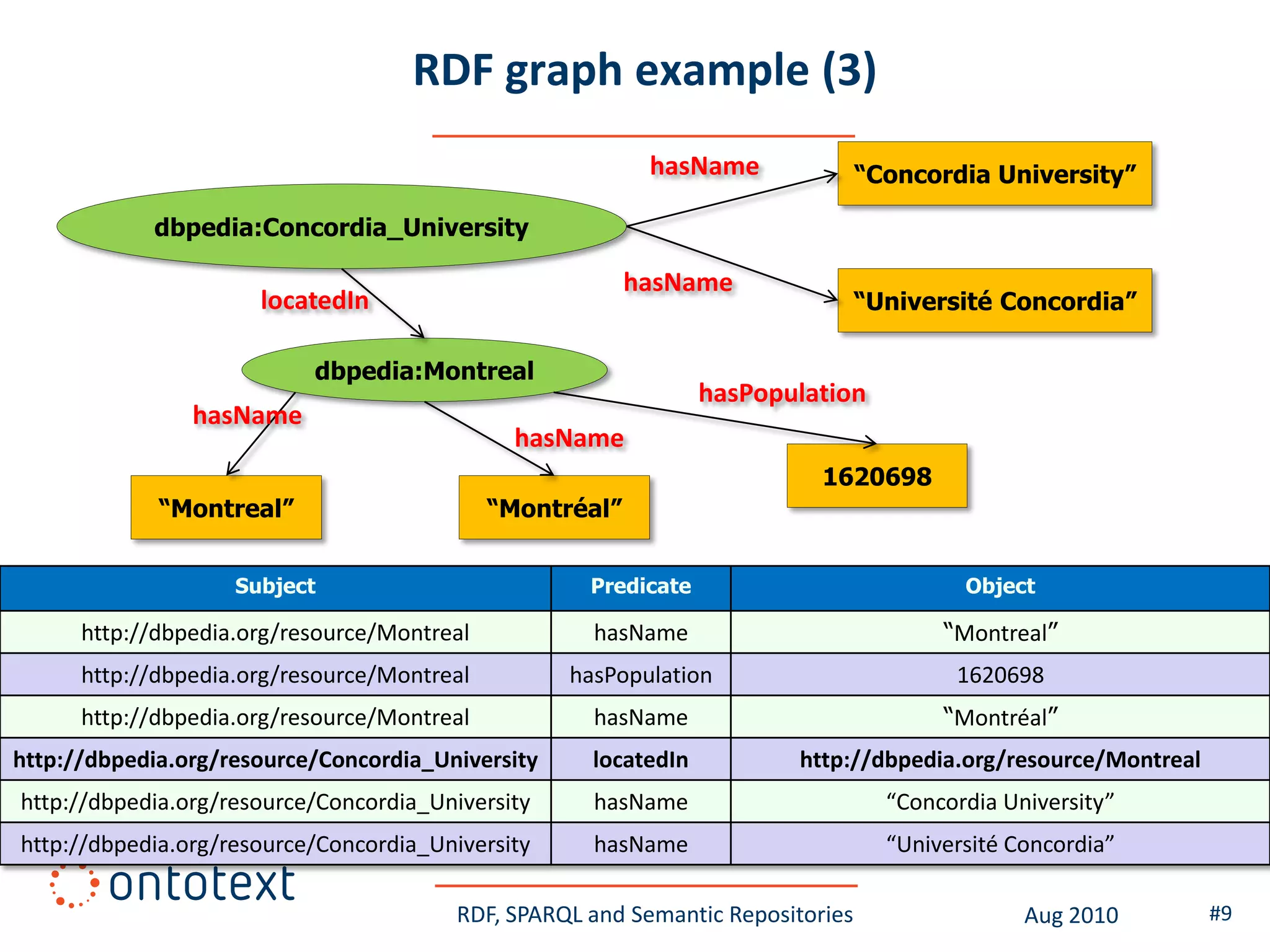




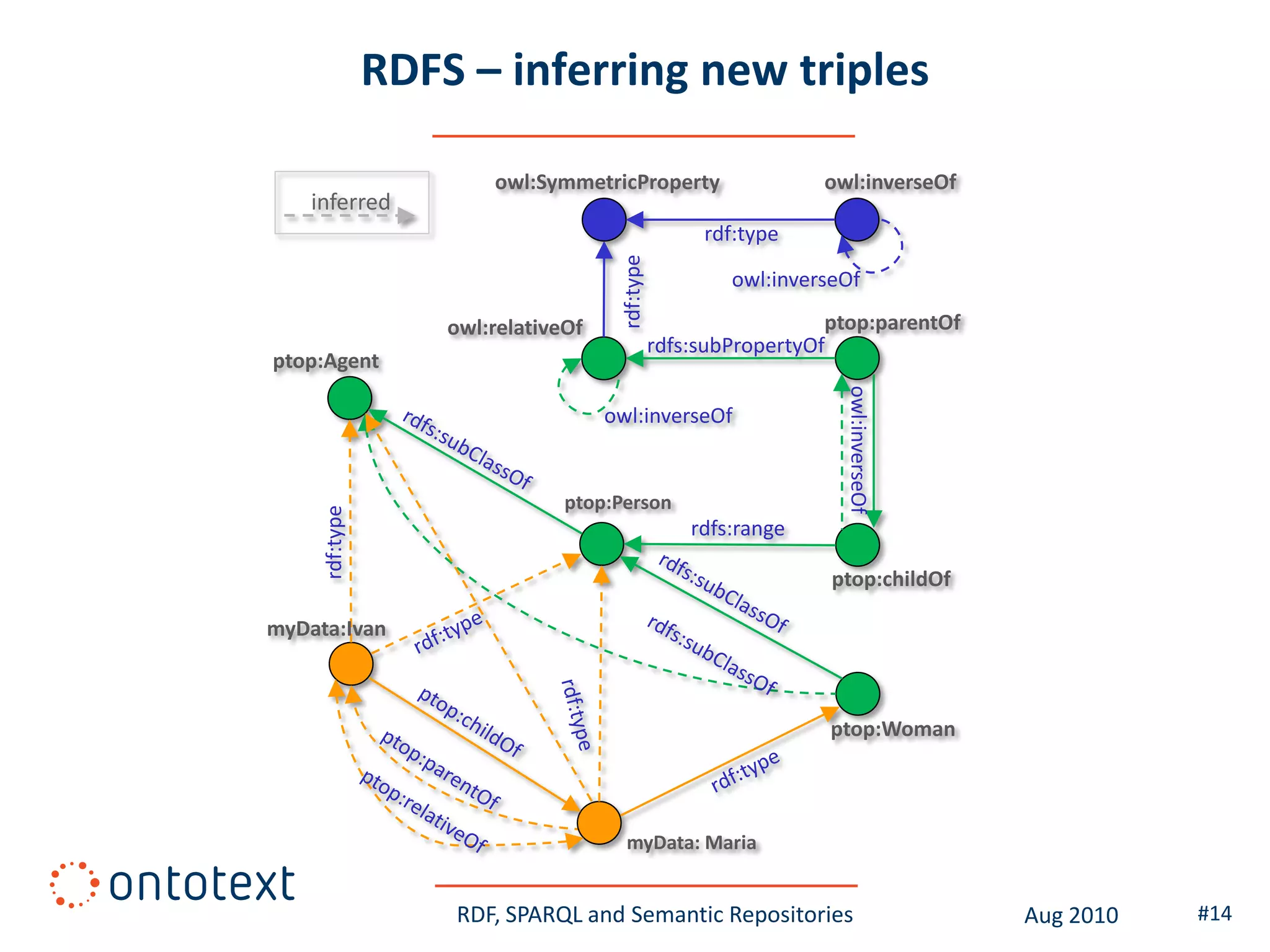



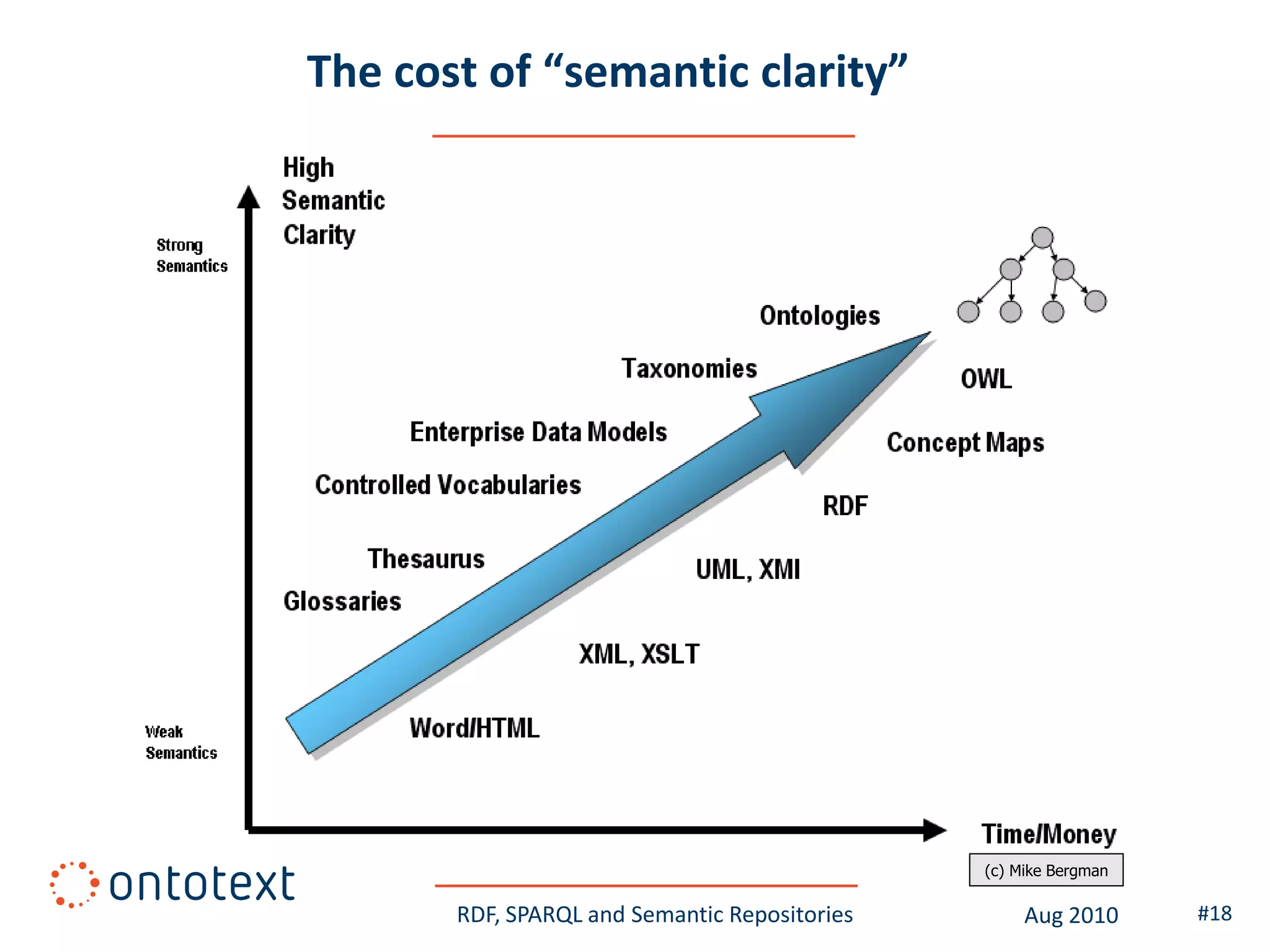




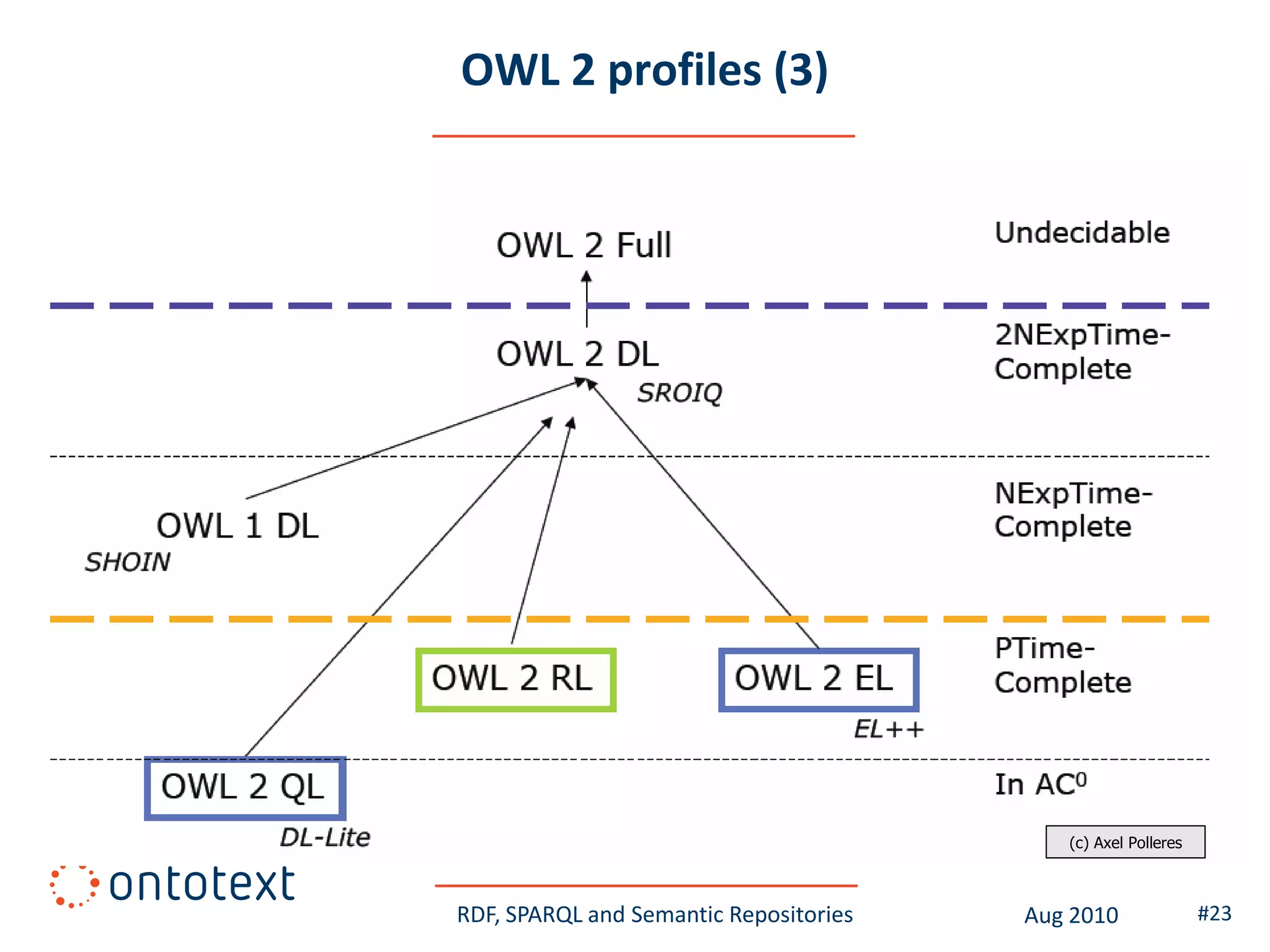


















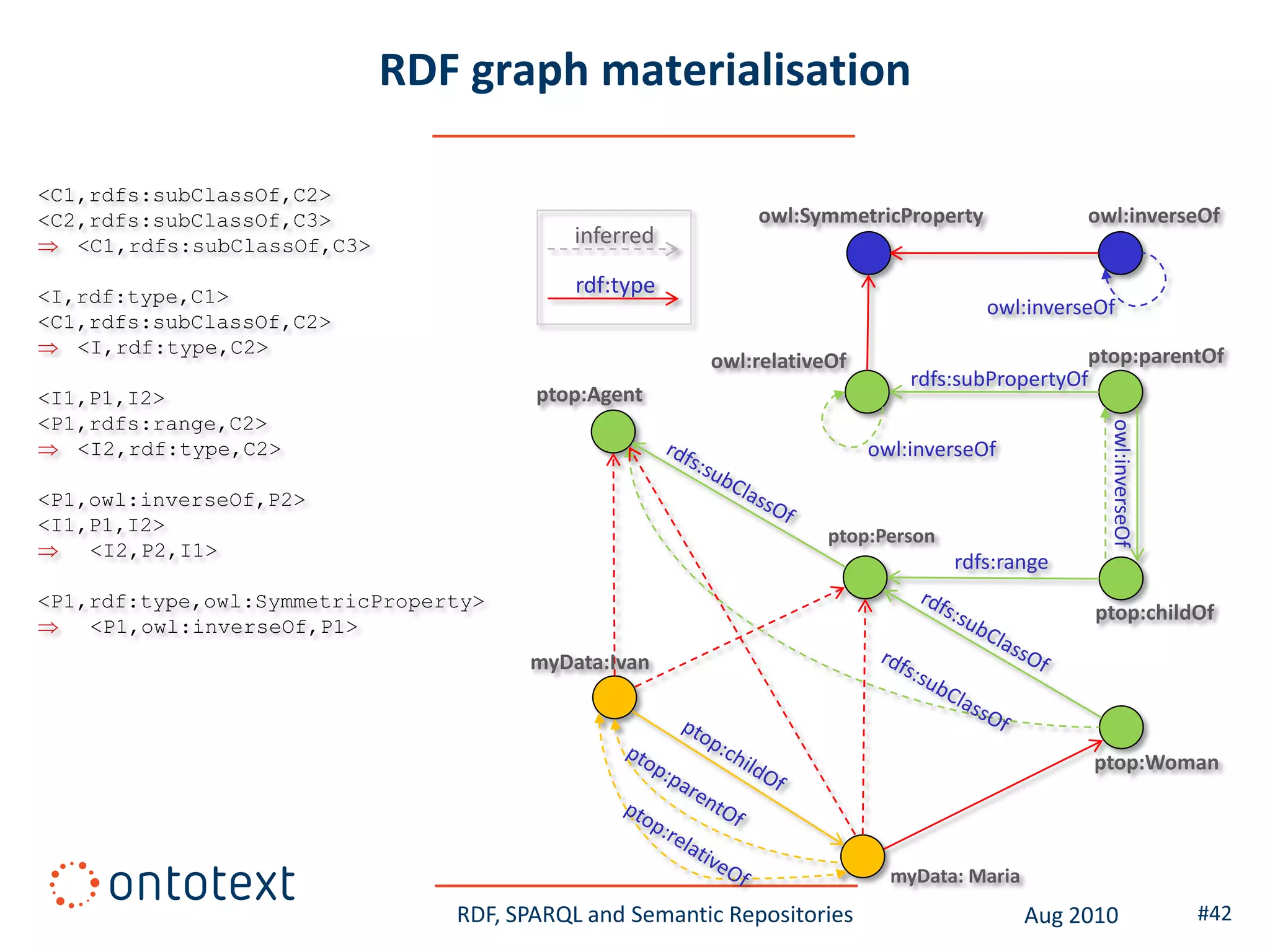







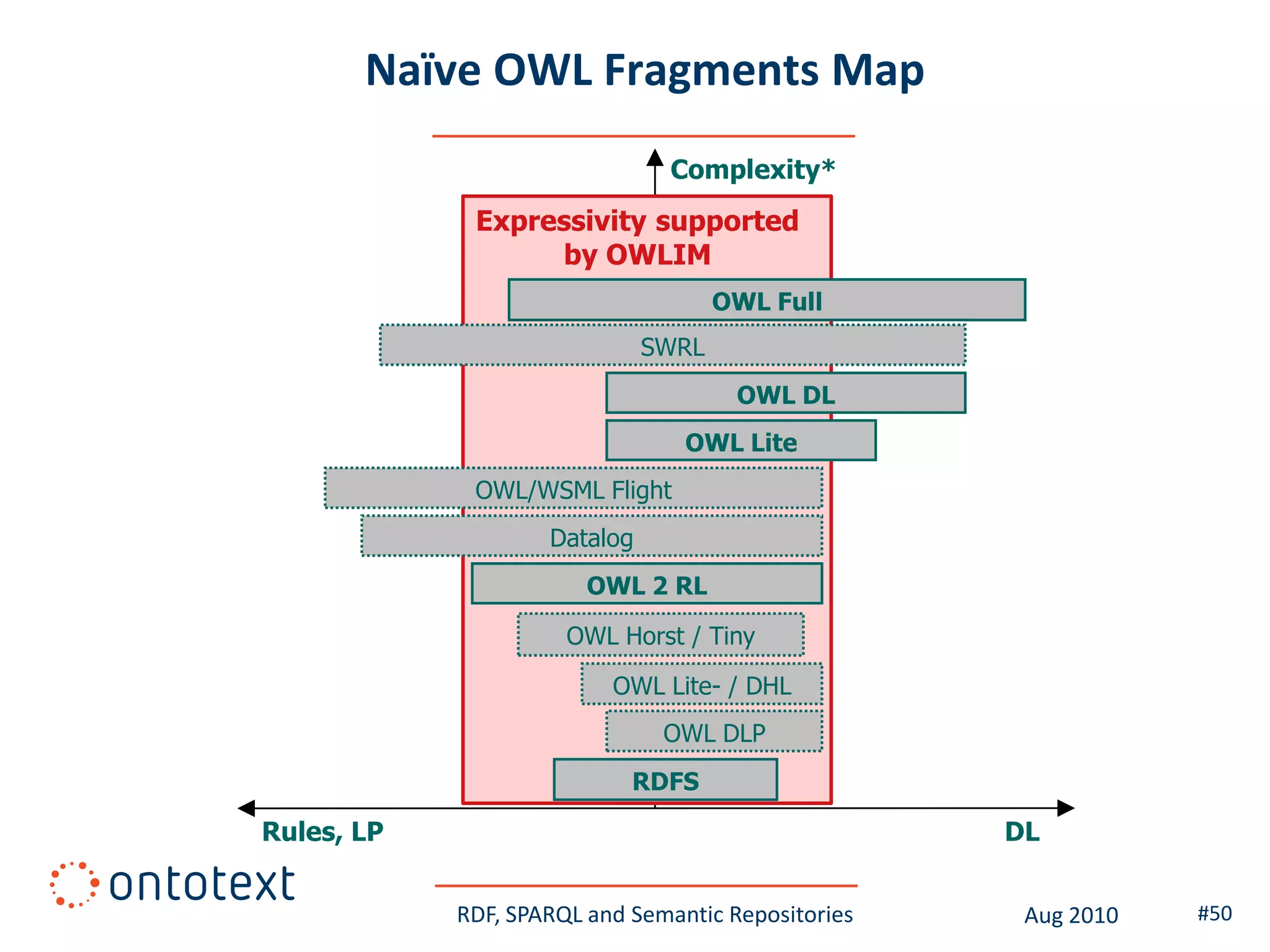


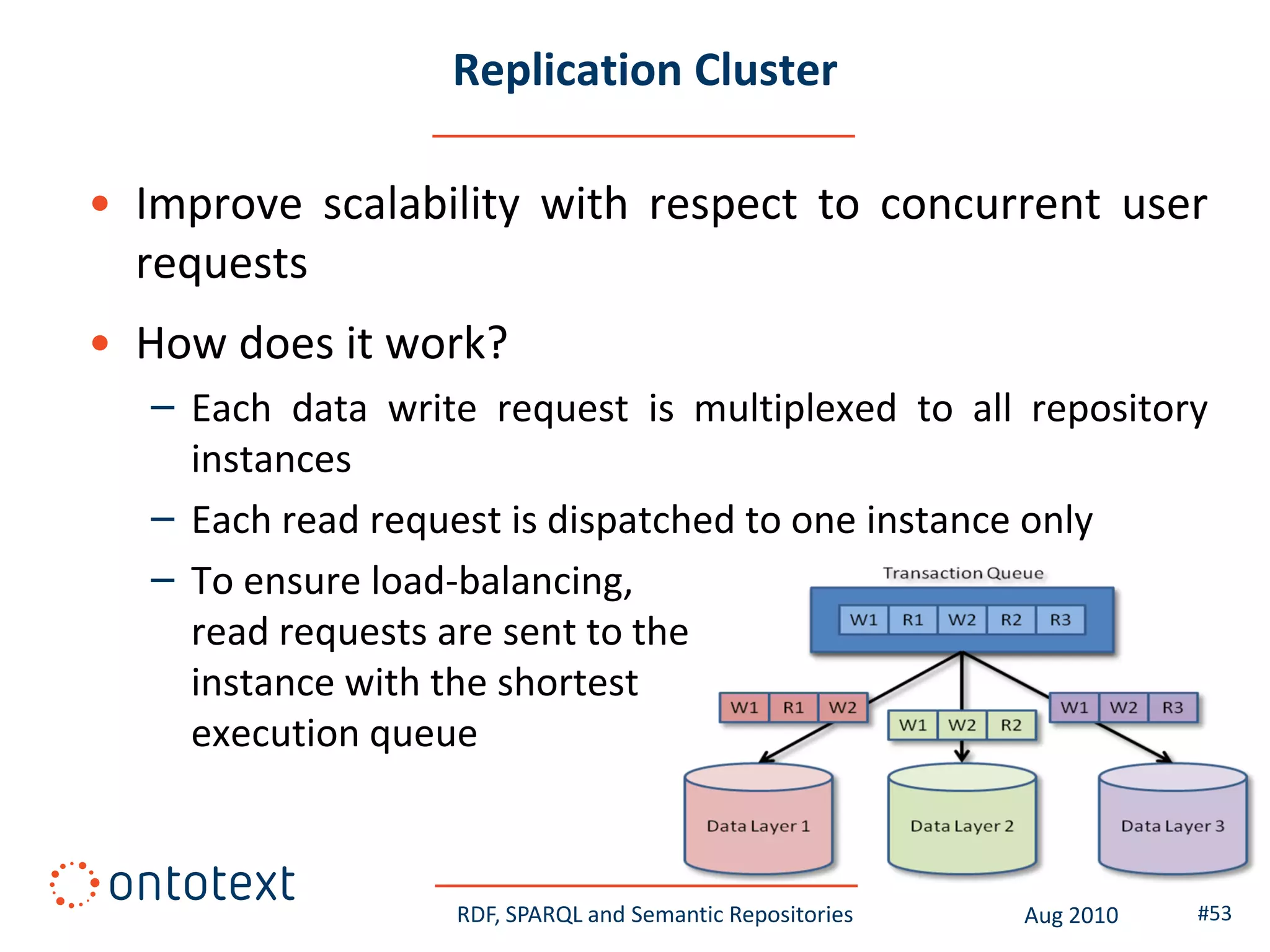



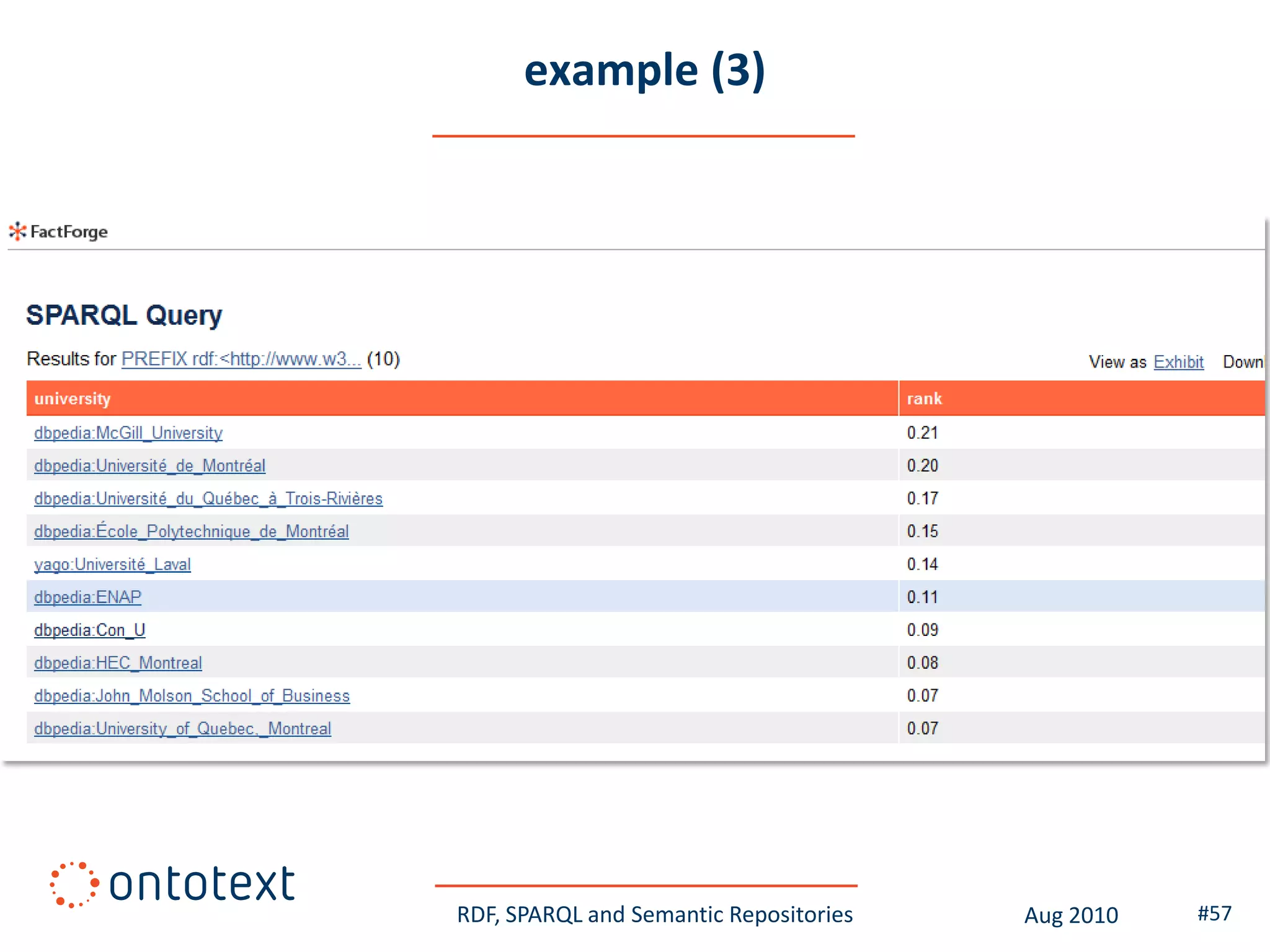














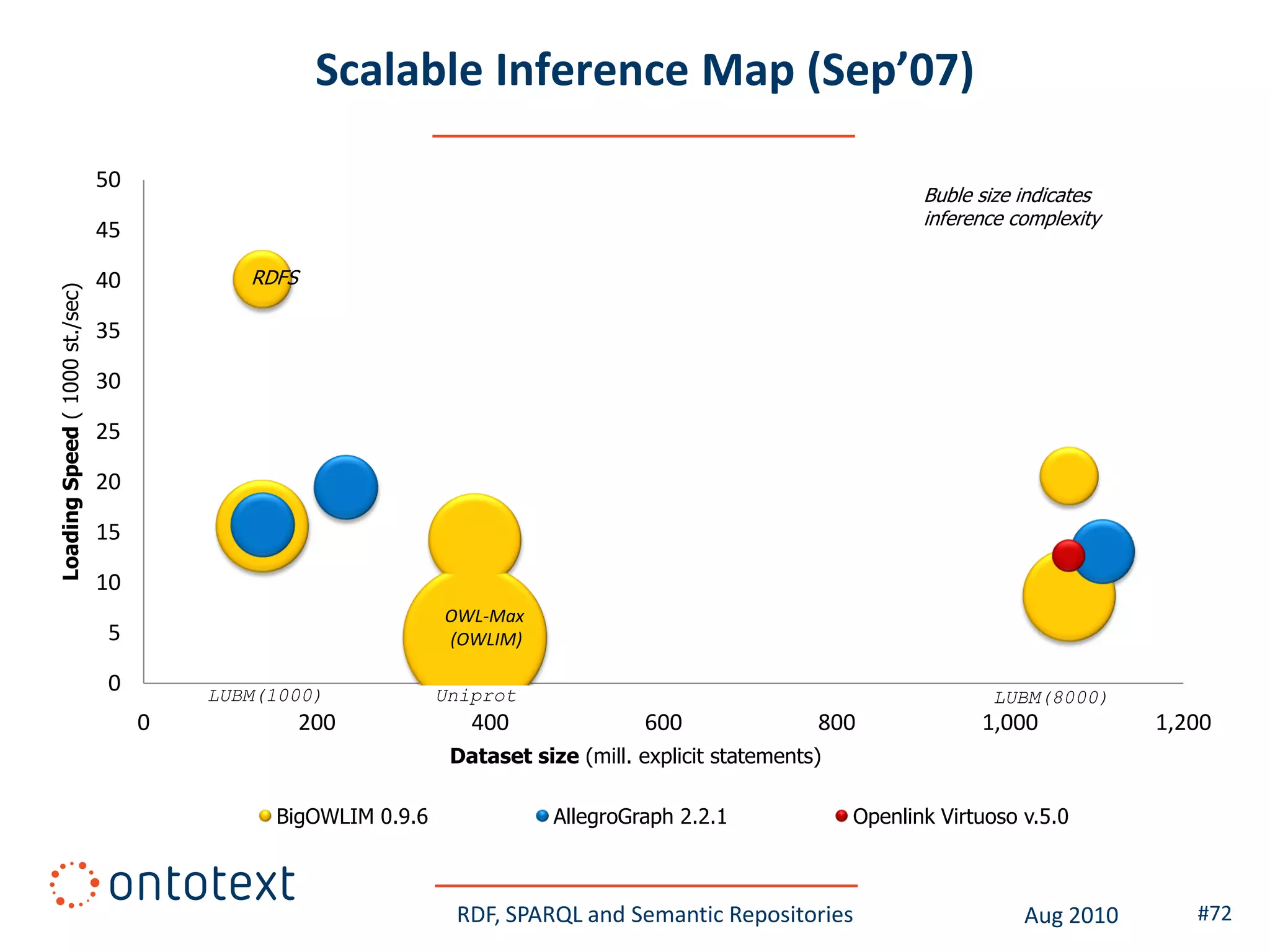
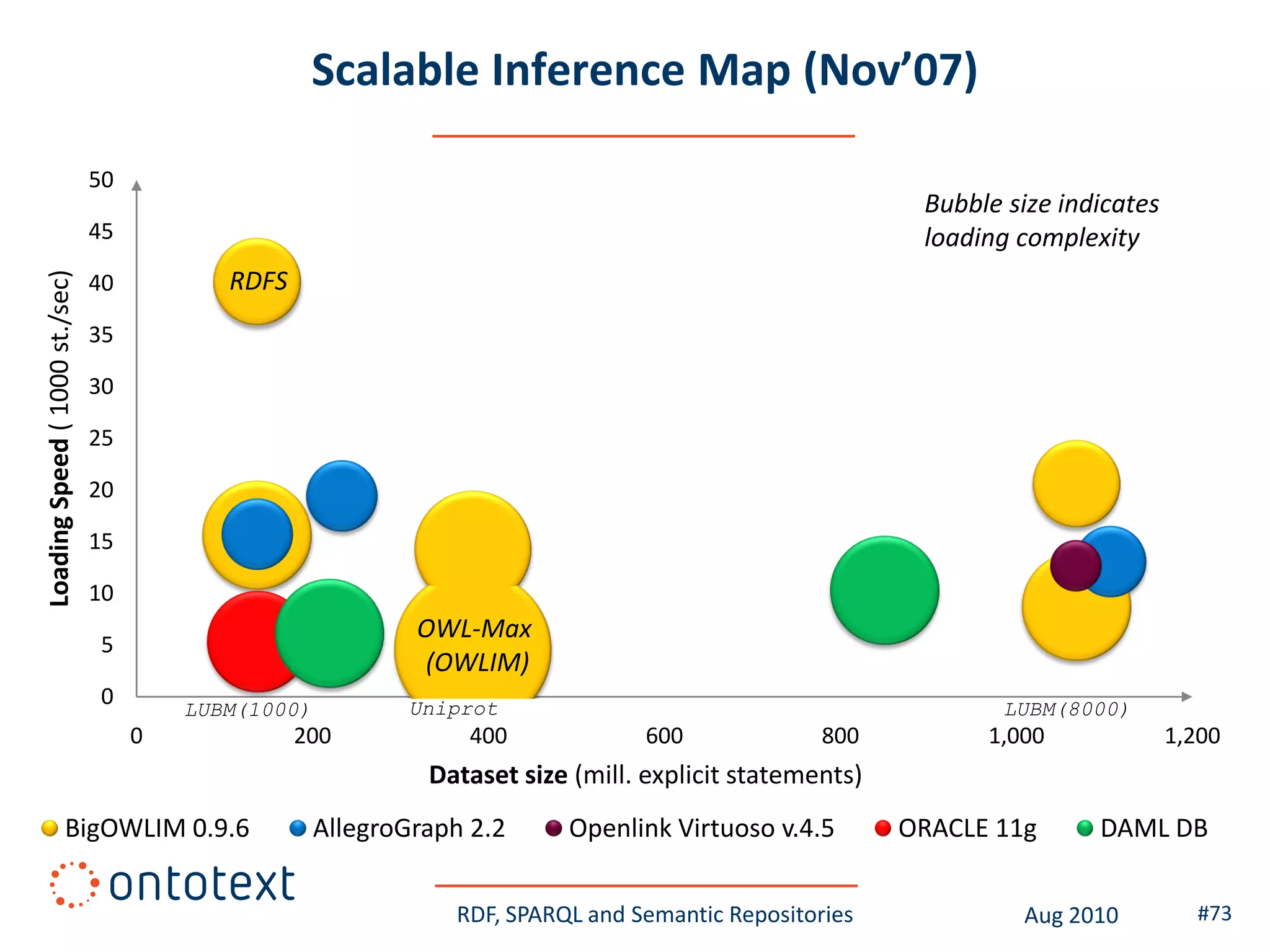
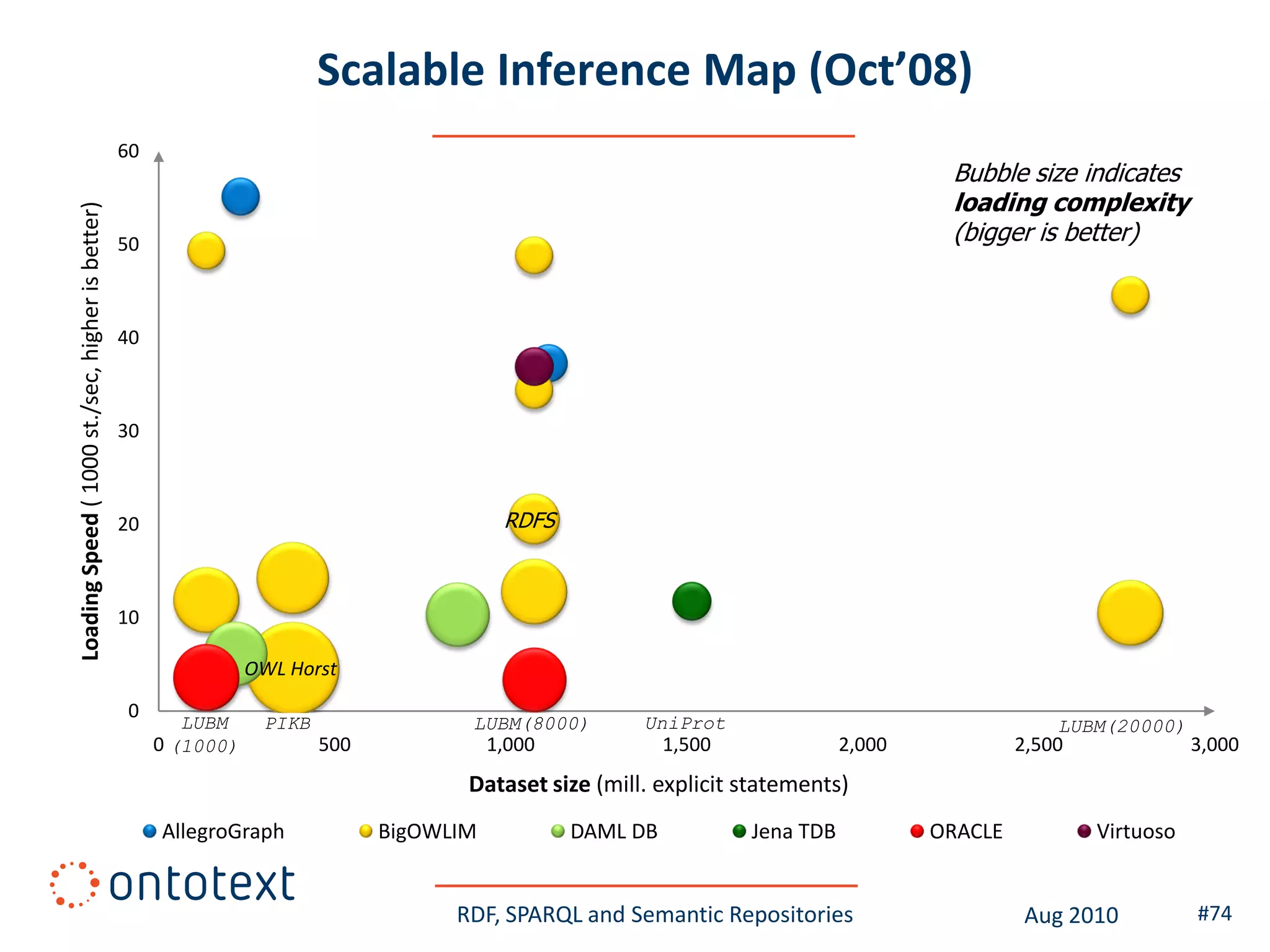
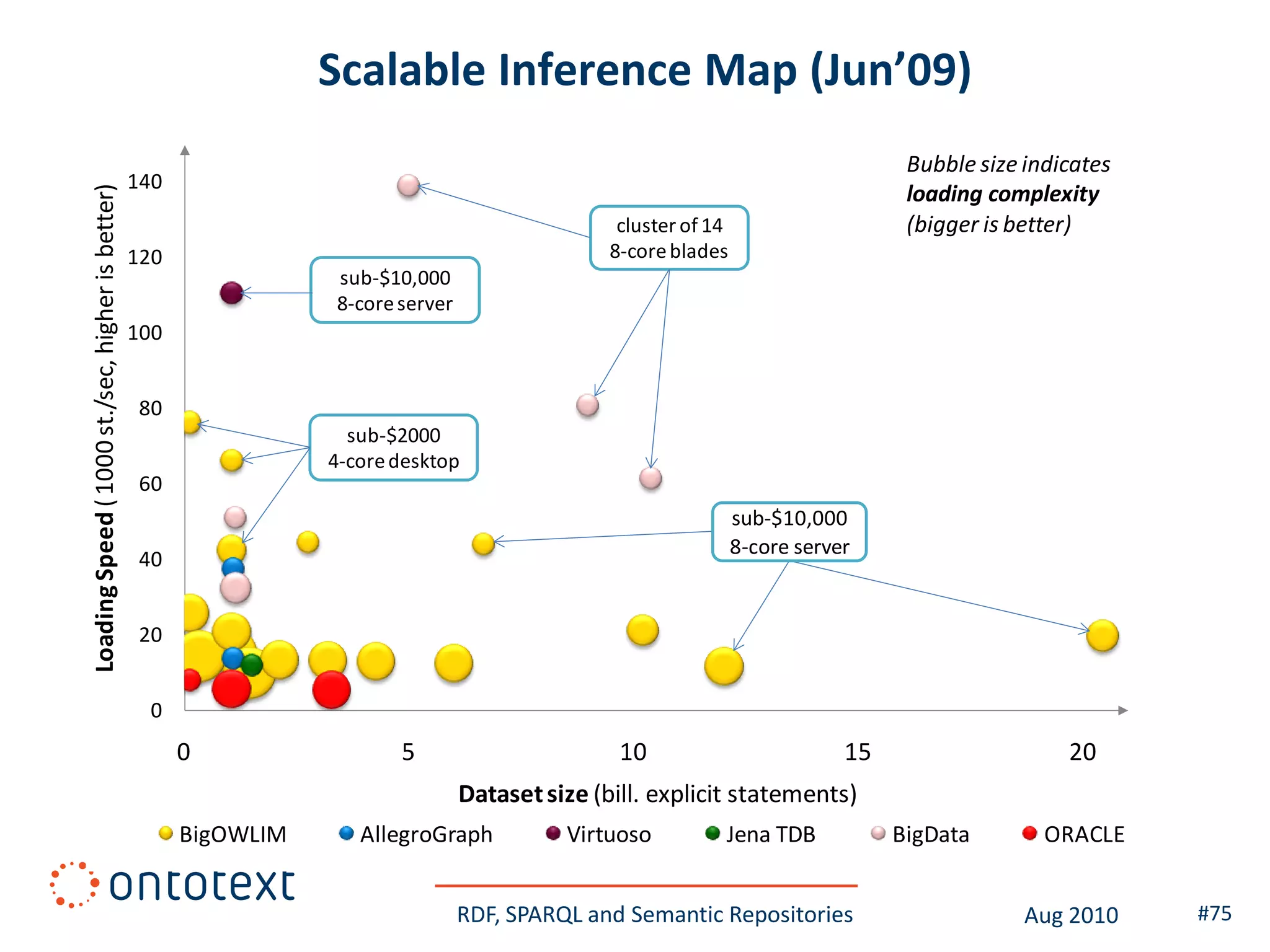








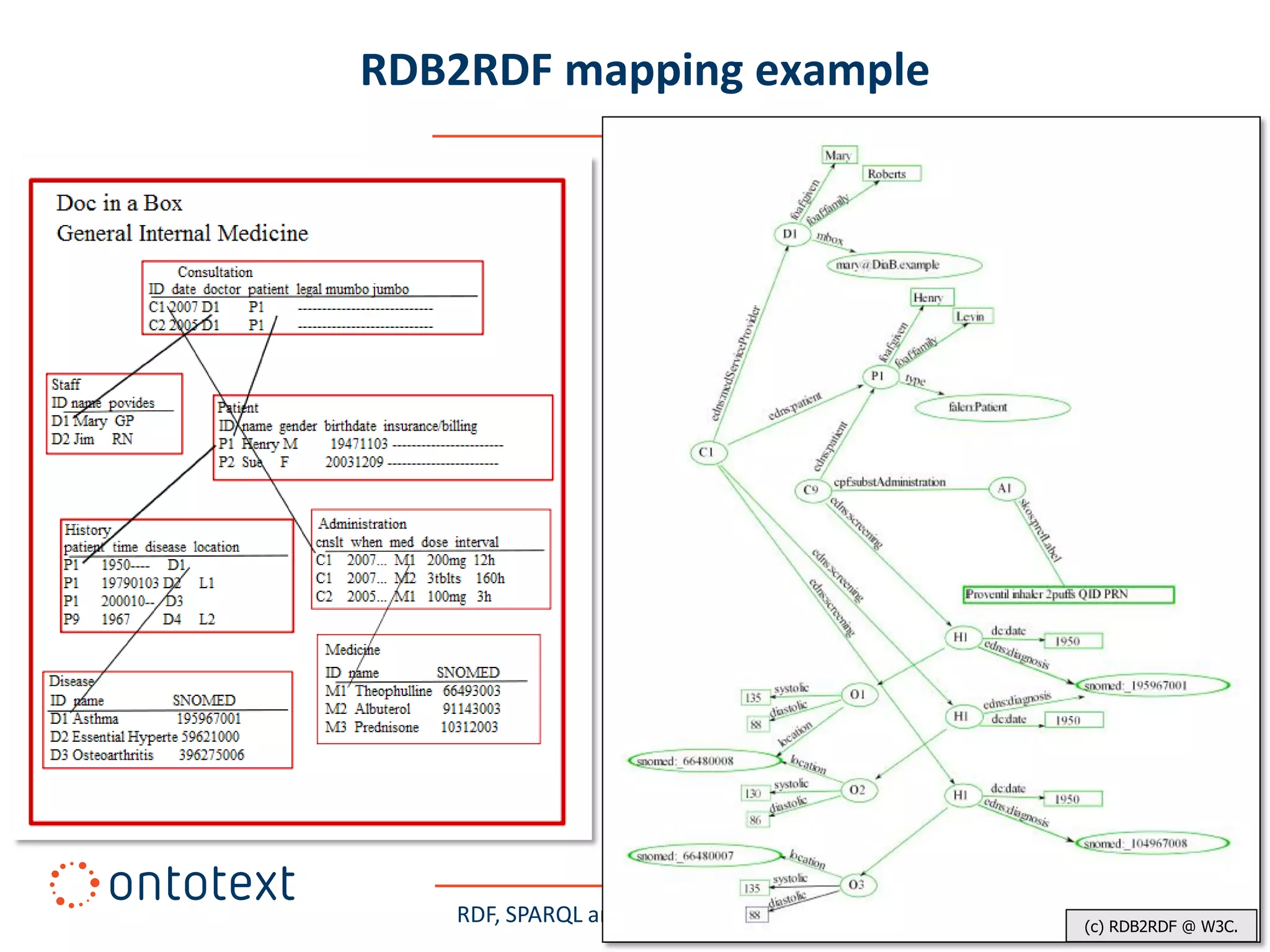

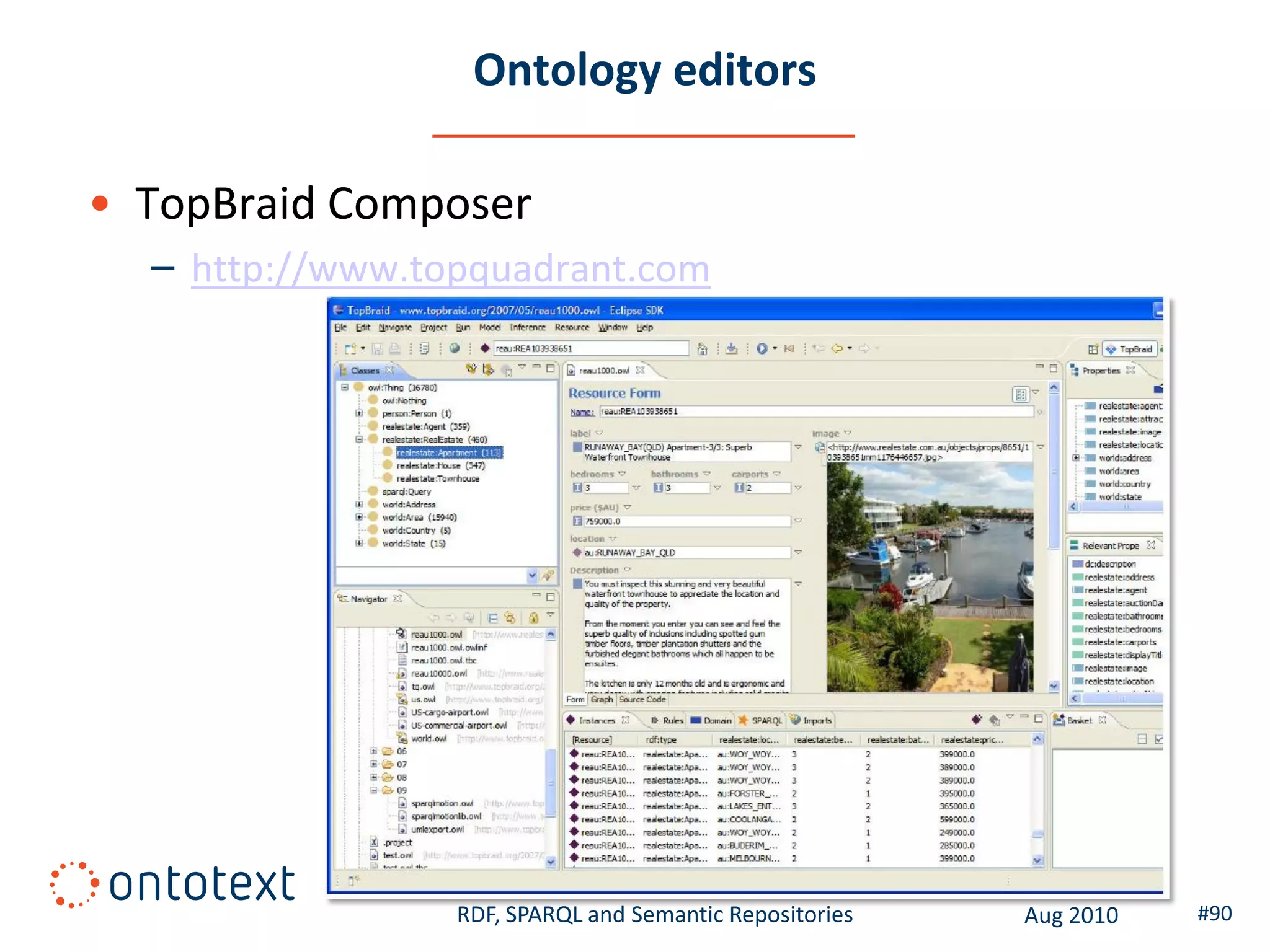
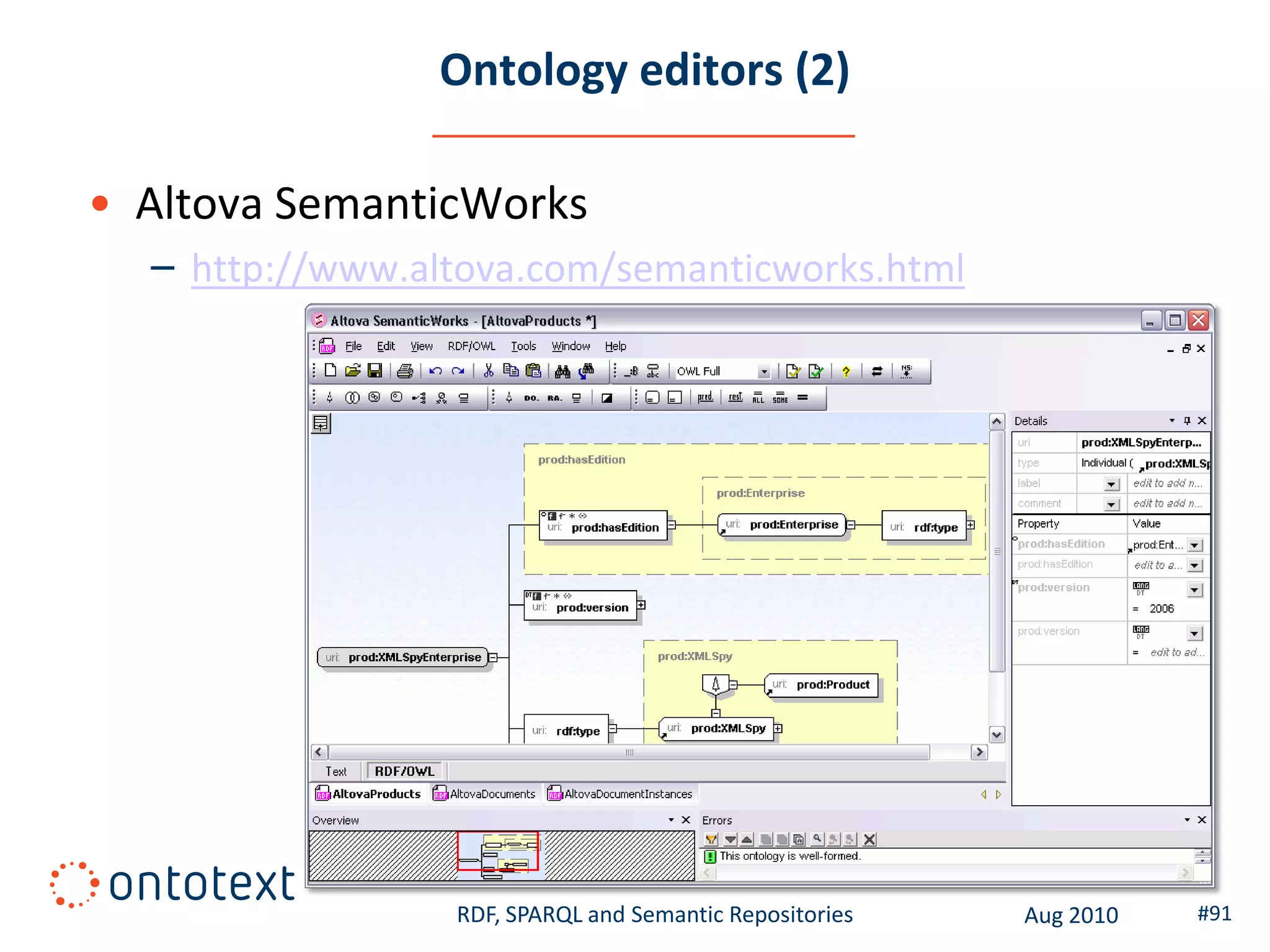
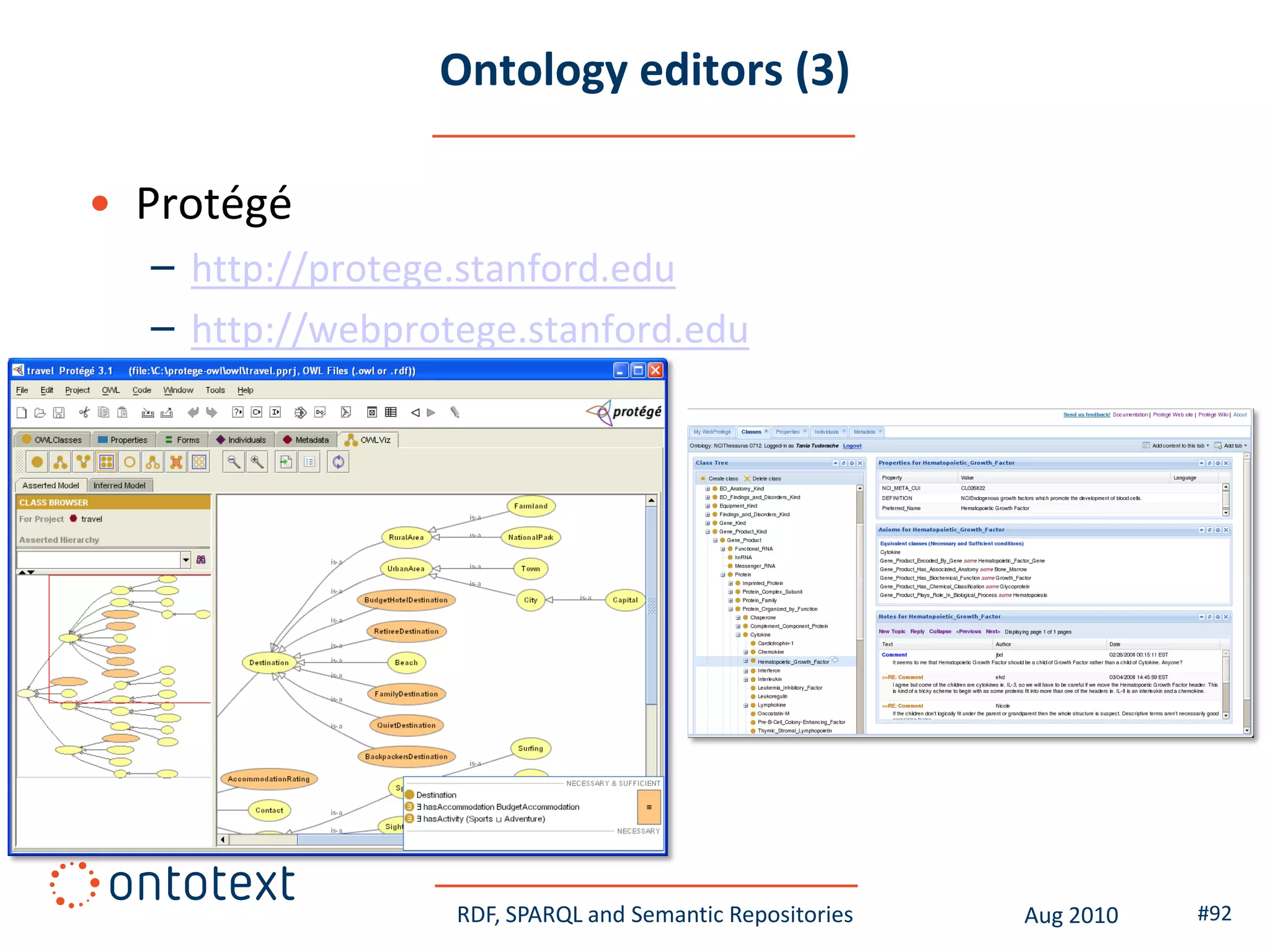
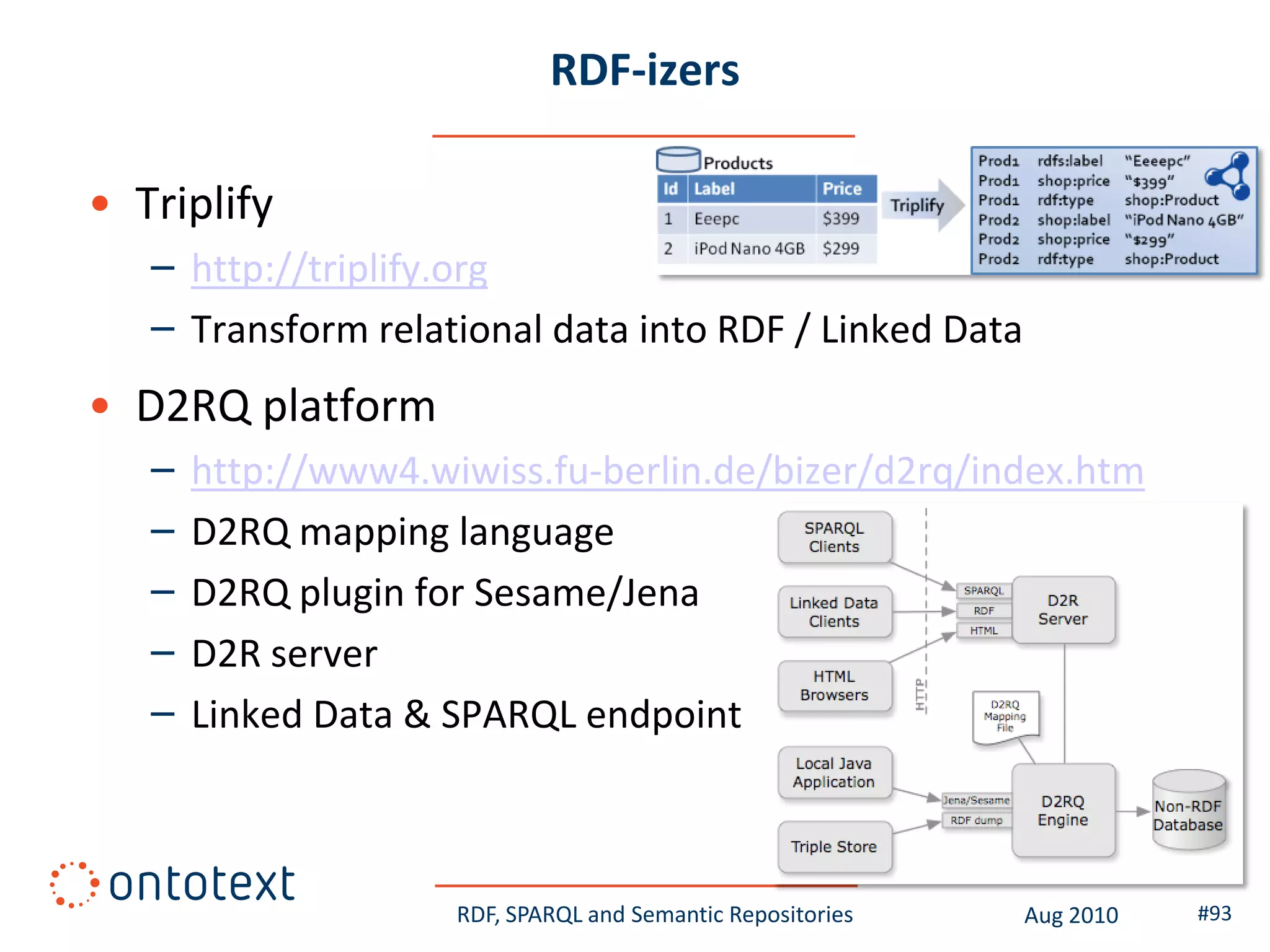

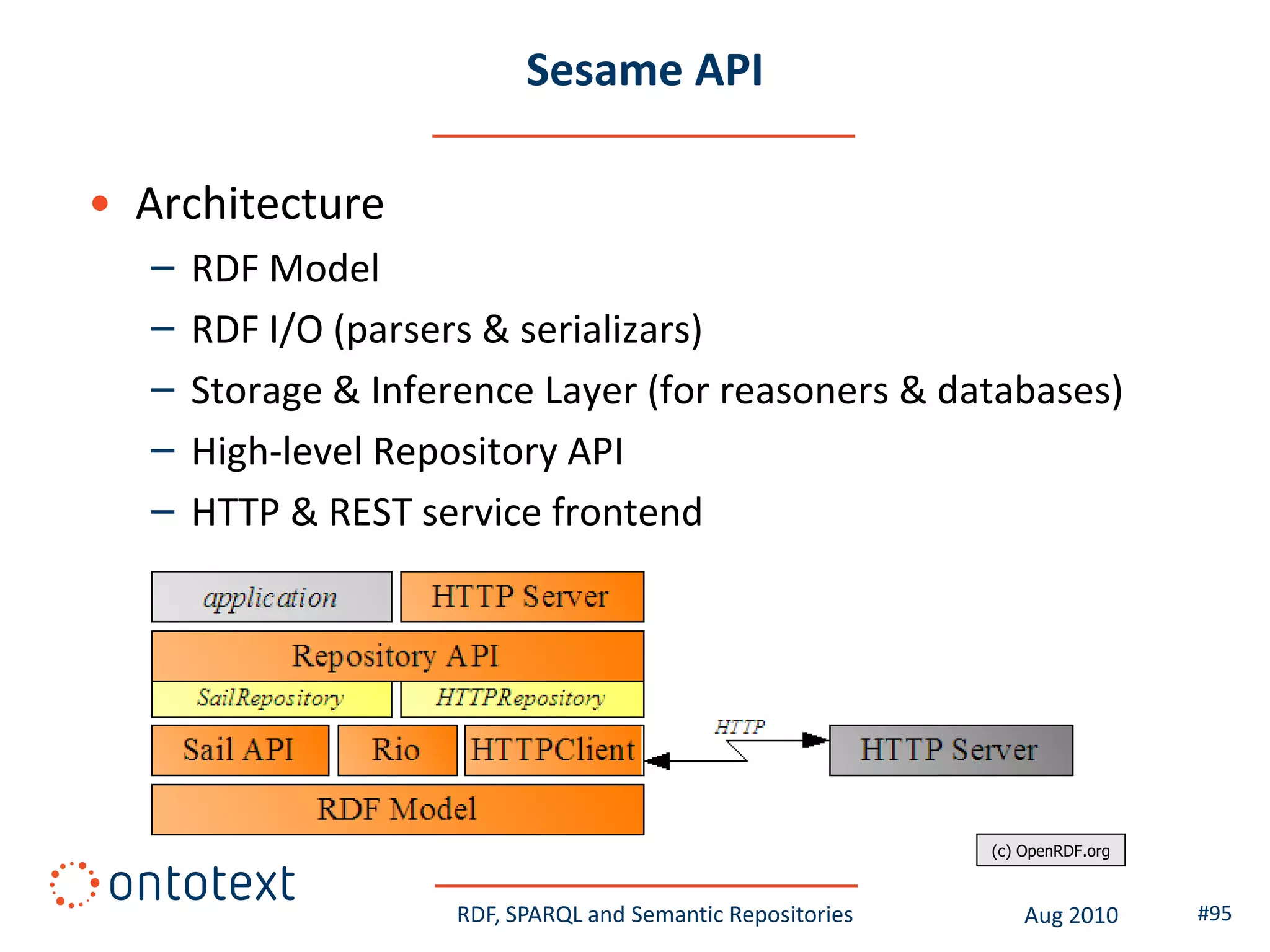

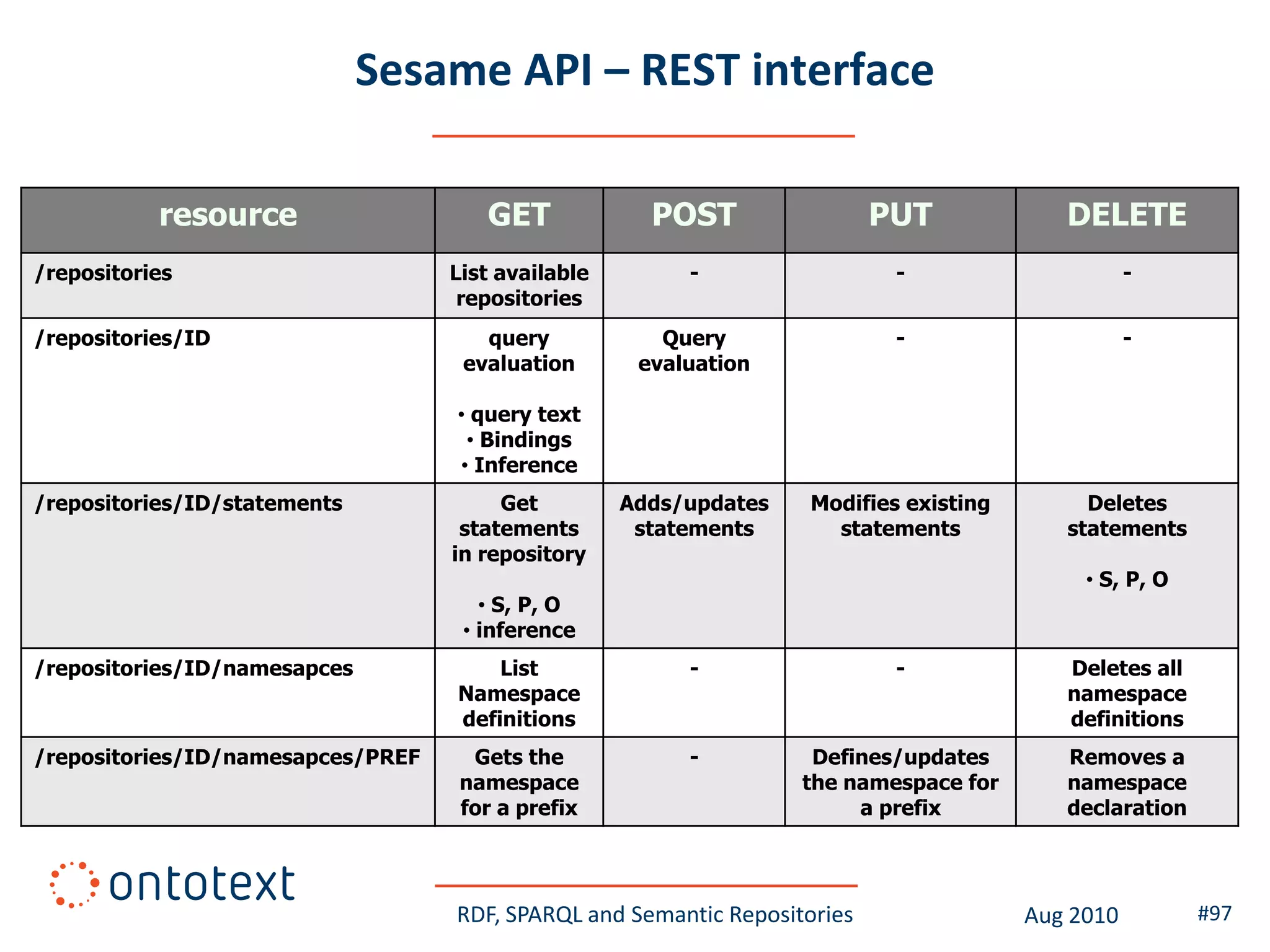
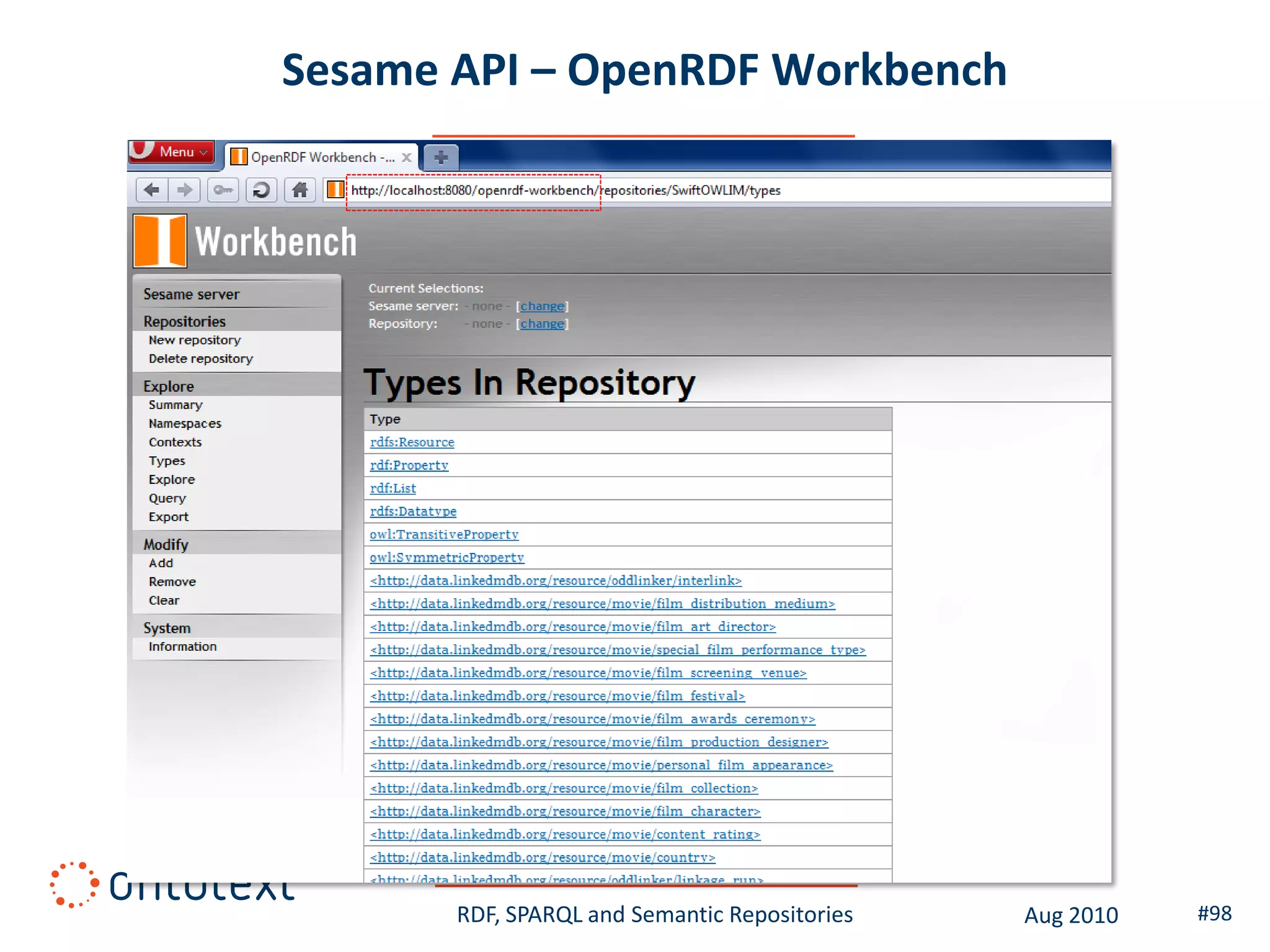




This document provides an overview of a training course on RDF, SPARQL and semantic repositories. The training course took place in August 2010 in Montreal as part of the 3rd GATE training course. The document outlines the modules covered in the course, including introductions to RDF/S and OWL semantics, querying RDF data with SPARQL, semantic repositories and benchmarking triplestores.











































































































