Downloaded 40 times




![THE SEMANTIC WEB
“The Semantic Web is a web of data…[it] provides a common
framework that allows data to be shared and reused across
application, enterprise, and community boundaries.”
[w3.org]
For the Semantic Web to happen, we would need
1. A way to structure and link data in a standardized way
2. A way to describe the relationships of these data in a
common way
3. A way to query that linked data
4. A way to infer something from that linked data (by
applying a set of rules)
but we will only focus on #1 and #3](https://image.slidesharecdn.com/69e01ebf-0e67-4127-82cd-69b43466541a-150723235336-lva1-app6892/85/Triplestore-and-SPARQL-4-320.jpg)



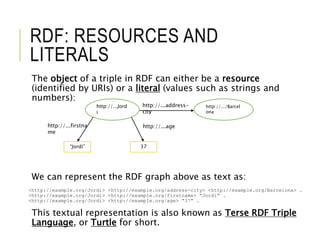
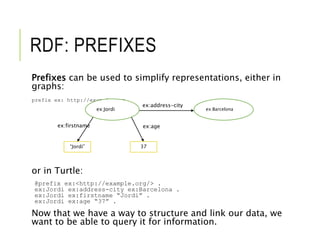

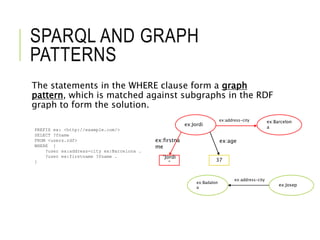






![SPARQL AND CYPHER
SPARQL:
PREFIX ex: <http://example.com/>
SELECT ?fname
FROM <users.rdf>
WHERE {
?user ex:address-city ex:Barcelona .
?user ex:firstname ?fname .
}
Cypher:
MATCH user–[:ex_firstname]->fname,
user-[:ex_address-city]->city
WHERE city.uri = “ex:Barcelona”
RETURN fname
ex:Jordi
ex:Barcelon
a
ex:address-city
“Jordi
”
37
ex:ageex:firstna
me](https://image.slidesharecdn.com/69e01ebf-0e67-4127-82cd-69b43466541a-150723235336-lva1-app6892/85/Triplestore-and-SPARQL-18-320.jpg)






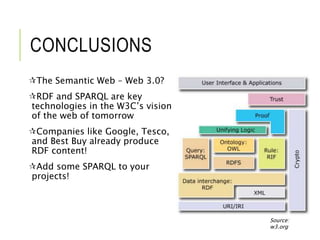


This document provides an overview of the Semantic Web, RDF, SPARQL, and triplestores. It discusses how RDF structures and links data using subject-predicate-object triples. SPARQL is introduced as a standard query language for retrieving and manipulating data stored in RDF format. Popular triplestore implementations like Apache Jena and applications of linked data like DBPedia are also summarized.































































