Downloaded 14 times





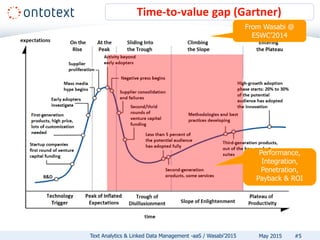



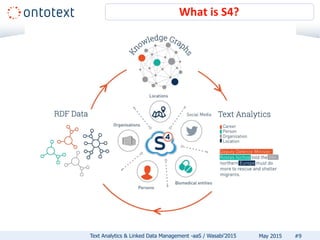

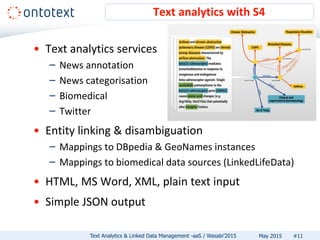
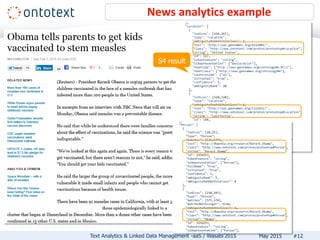

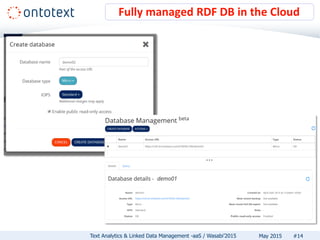

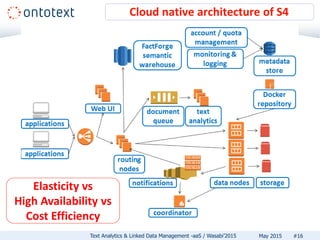




The document discusses Ontotext's text analytics and linked data management services, highlighting the Self-Service Semantic Suite (S4) which offers capabilities for content enrichment and smart data management with a focus on reducing time-to-market and risks associated with semantic technology adoption. Key features include on-demand access, a pay-per-use pricing model, and various text analytics services like news annotation and entity linking. It emphasizes the importance of a cost-aware cloud platform and the benefits of cloud-native architectures.






























































































