



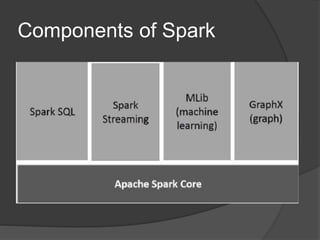

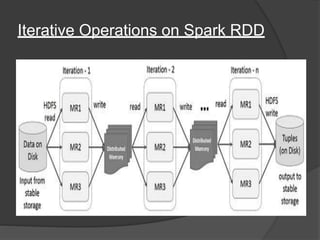
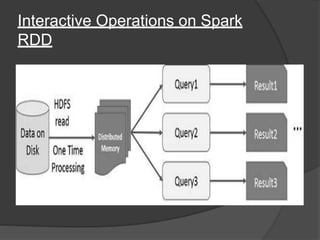
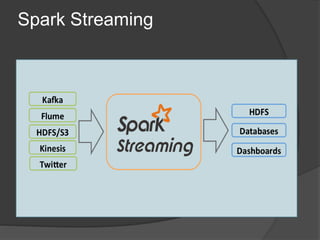






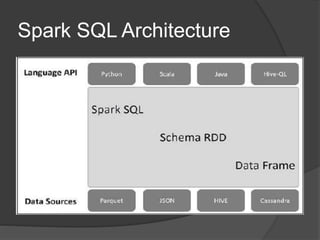



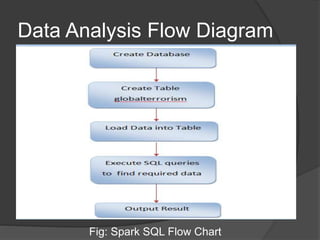


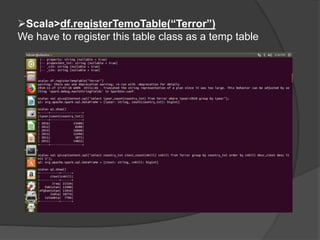

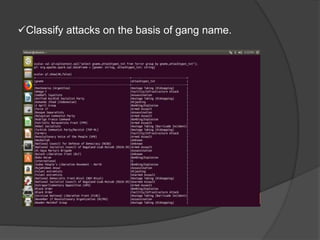
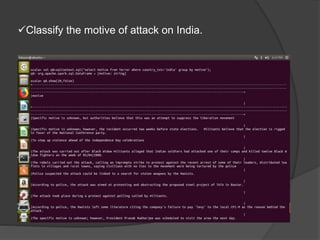




Spark is an open-source cluster computing framework that allows processing of large datasets in parallel. It supports multiple languages and provides advanced analytics capabilities. Spark SQL was built to overcome limitations of Apache Hive by running on Spark and providing a unified data access layer, SQL support, and better performance on medium and small datasets. Spark SQL uses DataFrames and a SQLContext to allow SQL queries on different data sources like JSON, Hive tables, and Parquet files. It provides a scalable architecture and integrates with Spark's RDD API.





























































![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)




