Downloaded 33 times




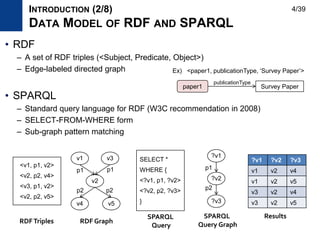
![Relational RDF Store Graph RDF Store
Storage Relational table
Adjacent list
Mainly In-memory
Query
Processing
Relational operator
Join and scan
Sub-graph isomorphism algorithm
System
Jena [WWW2004] , Sesame [ISWC2002],
Oracle [VLDB2005], SW-store [VLDBJ2009],
RDF-3X [VLDBJ2010]
GRIN [AAAI2007], Dogma [ISWC2009],
PIG [SemData2010], gStore [VLDBJ2013]
Pros
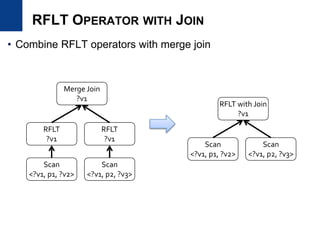
Batch processing using Join operator
Large-scale RDF processing [VLDB2012]
Reduce search space of the graph
traversal using the graph structure
Cons Not using the graph structure
Not scalable
Inappropriate for large-scale
processing
INTRODUCTION (3/8)
TWO TYPES OF RDF STORES
5/39](https://image.slidesharecdn.com/rdfqueryoptimization-170305223816/85/SPARQL-and-RDF-query-optimization-5-320.jpg)
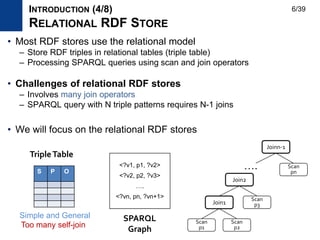
![• Storage approaches
– Clustered property table
– Jena [WWW2004] , Sesame [ISWC2002], Oracle [VLDB2005]
– Cluster properties which are accessed together frequently
– Sorted triple tables (multiple indexing)
– SW-store [VLDBJ2009], RDF-3X [VLDBJ2010]
– Store triples as sorted in a column-oriented store or clustered B+ trees
ID Name age gender
Clustered PropertyTable
S P O
SortedTripleTable
S
S P O
P
S P O
O
INTRODUCTION (5/8)
EXISTING RELATIONAL RDF STORE
Reduce joins
Limited flexibility, Cluster decision
Null value, Multi value
Fast retrieval of matching triples
Fast merge join
Storage overhead, update
7/39](https://image.slidesharecdn.com/rdfqueryoptimization-170305223816/85/SPARQL-and-RDF-query-optimization-7-320.jpg)
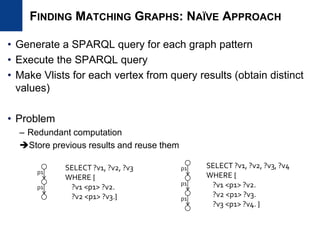
![• Handling intermediate results approaches
– Finding optimal plan
– Static and traditional approach
– Propose RDF-specific histograms
– RDF-3X [VLDBJ2010], Characteristics set [ICDE2011], ARQ [WWW2008]
– Dynamic filtering method
– Build dynamic filters and use subsequent operators
– U-SIP [SIGMOD2009]
• Existing methods do not exploit graph structure of RDF graphs
Scan
p1
Scan
p2
Merge Join
Scan
p3
Hash Join
Next Information
Domain Filter
Scan
p1
Scan
p2
Merge Join
Scan
p3
Hash Join
Finding Optimal Plan (static) Dynamic Filtering Method
INTRODUCTION (6/8)
EXISTING RELATIONAL RDF STORE
8/39](https://image.slidesharecdn.com/rdfqueryoptimization-170305223816/85/SPARQL-and-RDF-query-optimization-8-320.jpg)



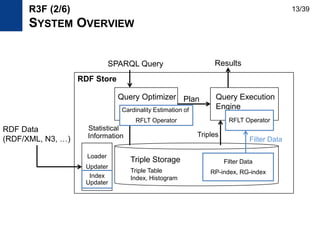
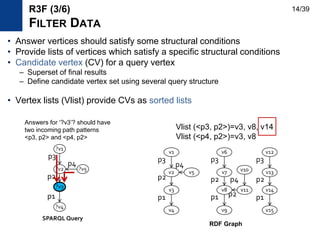

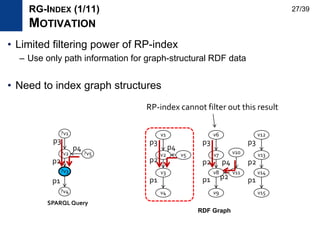
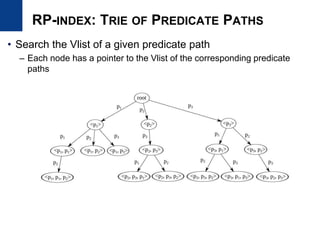
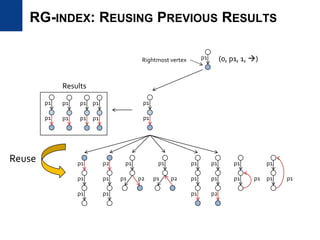
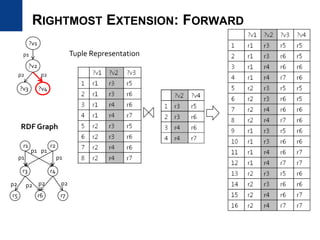
![• Motivation
– Design an index to provide vertex lists having a specific path pattern
– Efficient and updatable index
• Related work: path-based index
– DataGuide [VLDB1997], 1-index [ICDT1999], A(k)-index [ICDE2002],
D(k)-index [SIGMOD2003], M(k)-index [ICDE2004]
– Provide a concise summary of the original data for query processing
– Handle size problem by store every vertex one time in the index
• Our goal is to provide filter data efficiently
– Vertices can be stored several times and stored as sorted
– We deal with the size problem differently
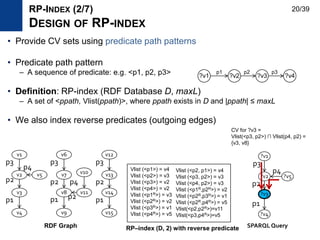
RP-INDEX (1/7)
MOTIVATION AND RELATED WORK
19/39](https://image.slidesharecdn.com/rdfqueryoptimization-170305223816/85/SPARQL-and-RDF-query-optimization-19-320.jpg)


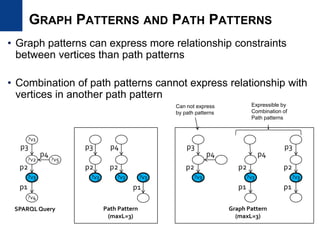
![• Graph index
– Graph-transactional setting (many small graphs)
– GraphGrep [PODS2002], gIndex [SIGMOD2004], C-tree [ICDE2006],
QuckSI [VLDB2008], Tale [ICDE2008]
– A single large graph
– GraphQL [SIGMOD2008], GADDI [EDBT2009], SPath [VLDB2010]
– For reducing the search space of the graph traversal
– Non-trivial to apply to relational RDF stores
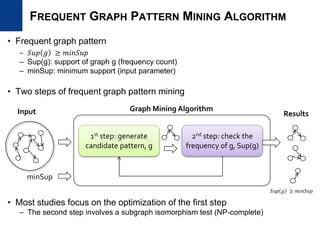
• Subgraph pattern mining
– Graph-transactional setting
– gSpan [ICDM2002], Gaston [KDD2004]
– A single large graph
– HSIGRAM, VSIGRAM [JDMKD2005]
– Not scalable for large RDF graphs
– We need to adapt existing algorithm for RDF graphs
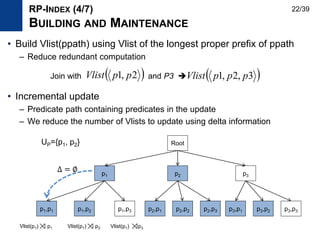
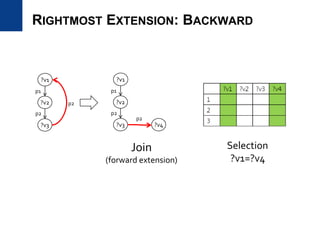
RG-INDEX (2/11)
RELATED WORK
28/39](https://image.slidesharecdn.com/rdfqueryoptimization-170305223816/85/SPARQL-and-RDF-query-optimization-28-320.jpg)
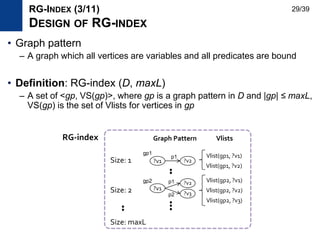
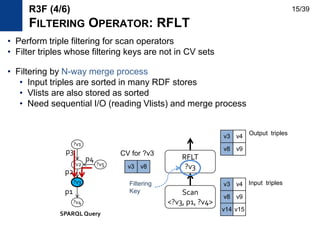
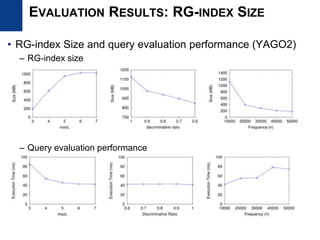
![• Use subgraph mining due to the size problem of RG-index
– Indexing only frequent subgraph patterns Frequent subgraph mining
• Adapt gSpan [Yan and Han, ICDM ’02] algorithm for RDF graphs
• gSpan
– Transactional setting
– Depth-first pattern growth approach
– Use anti-monocity property of support
– Use DFS encoding and edge extension
to prevent duplicate pattern generation
RG-INDEX (4/11)
BUILDING RG-INDEX USING SUBGRAPH MINING
size-2
size-1
size-maxL
Edge extension
pruning infrequent
or duplicate pattern
30/39](https://image.slidesharecdn.com/rdfqueryoptimization-170305223816/85/SPARQL-and-RDF-query-optimization-30-320.jpg)
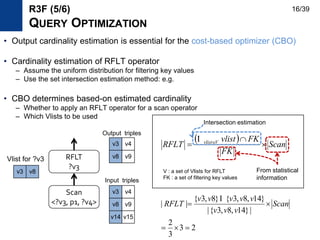
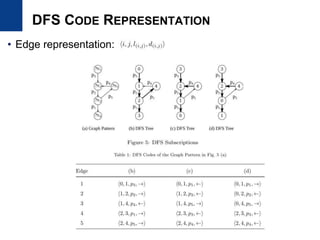
![• Pattern representation
– Use DFS code and extend it to directed edge-label graph [SIGKDD2003]
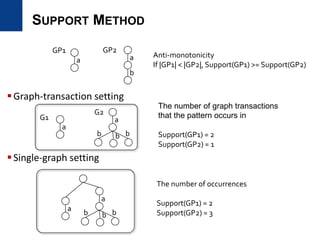
• Support definition
– Should satisfy anti-monotonicity property for efficient mining
– Most mining algorithm use MIS (maximum independent set) approach,
which is NP-hard for the single large setting
– We use support definition in [Bringmann and Nijssen, PAKDD ‘08]
as minimum matching vertex number
– Very efficient to compute and upper-bound of MIS approaches
(mining more patterns)
|)),((|min)sup( vGVlistG Vv
RG-INDEX (5/11)
ADAPTING GSPAN FOR RDF GRAPHS
31/39](https://image.slidesharecdn.com/rdfqueryoptimization-170305223816/85/SPARQL-and-RDF-query-optimization-31-320.jpg)
![• Redundant subgraph patterns
– Graph patterns with same Vlists
– Graphs having non-trivial automorphisms
• Compute occurrences of graph pattern
– Exploit depth-first style pattern generation similarly to VSIGRAM [JDMKD2005]
– Store all occurrences of a pattern to compute child patterns
– Store occurrences from root to a leaf (depth-first approach)
– We propose efficient occurrence computation method
RG-INDEX (6/11)
ADAPTING GSPAN FOR RDF GRAPHS
Redundant
patterns
32/39](https://image.slidesharecdn.com/rdfqueryoptimization-170305223816/85/SPARQL-and-RDF-query-optimization-32-320.jpg)










![Clustered Property
Table
Sorted Triple Storage
Reducing Intermediate
Results
Method
Reducing joins using
materialized views
Store triples as sorted and use
merge joins
Build dynamic filters for join
variables
Pros
Reduce the number of joins •Efficient retrieval of matching
triples
•Fast merge join
Reduce redundant intermediate
results
Cons
•Need user’s clustering
decision
•Incur null and multi-values
which are hard to process
•Storage overhead
•Do not handle redundant
intermediate results
Do not exploit structural
information of RDF graphs
System
Jena
[Carroll et al., WWW 2004]
Oracle
[Chong et al., VLDB 2005]
SW-store
[Abadi et al., VLDB 2007]
RDF-3X
[Neumann and Weikum, VLDB 2008]
U-SIP
[Neumann and Weikum, SIGMOD’09]
EXISTING RELATIONAL RDF STORE](https://image.slidesharecdn.com/rdfqueryoptimization-170305223816/85/SPARQL-and-RDF-query-optimization-57-320.jpg)

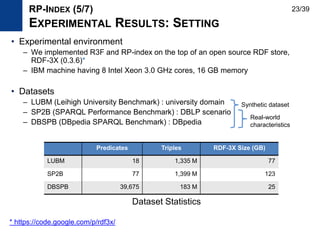
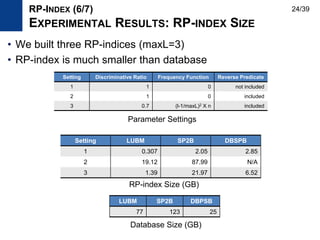
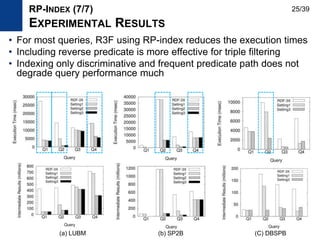
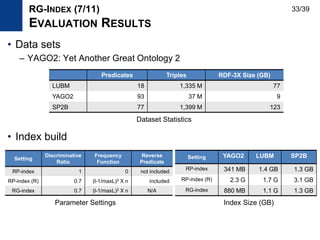
The document presents Kisung Kim's Ph.D defense presentation on techniques for processing SPARQL queries over RDF graphs stored in a relational database. It introduces an RDF triple filtering framework called R3F that uses the structural information of RDF graphs to filter irrelevant triples and reduce redundant intermediate results during query processing. Two indices, the RP-index and RG-index, are proposed as part of R3F to provide efficient filtering of triples based on path patterns and subgraph patterns in the RDF graph.




















































































