Download as PDF, PPTX







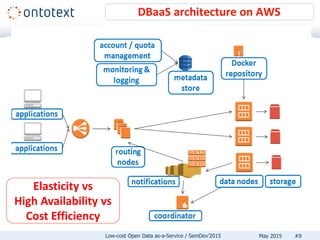
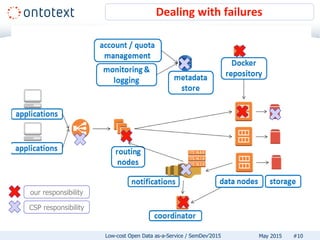








The document discusses low-cost open data as-a-service (DBaaS) emphasizing the use of RDF technology to transform and publish data efficiently. It outlines the architecture and requirements for implementing such a service, detailing the benefits of using cloud-native solutions for scalability and cost efficiency. Additionally, it highlights lessons learned and encourages users to adopt an RDF DBaaS for enhanced productivity and easier data management.

























































































