Download as PDF, PPTX







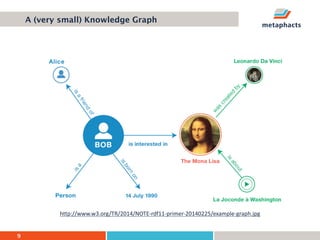

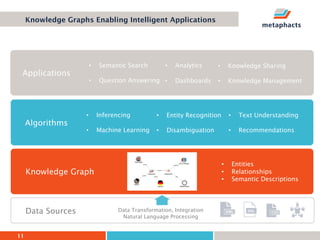


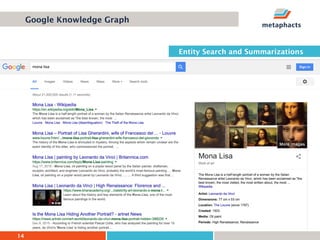
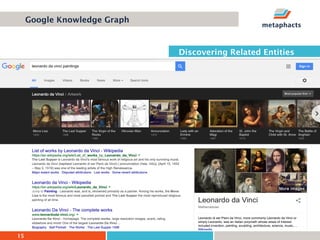
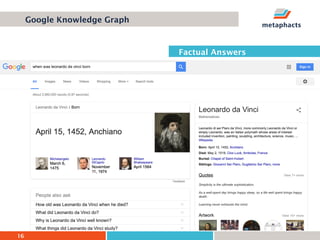
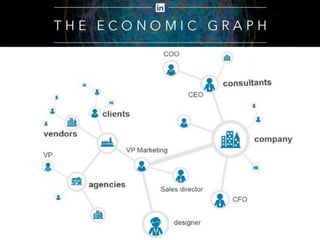

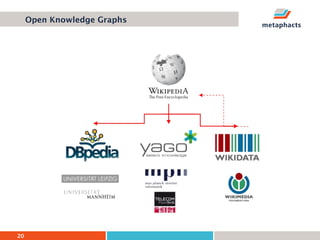


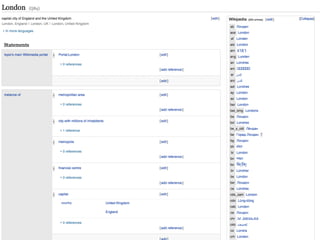
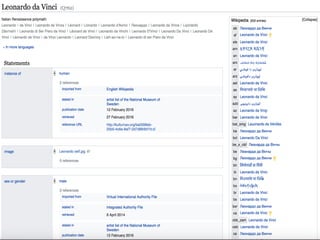
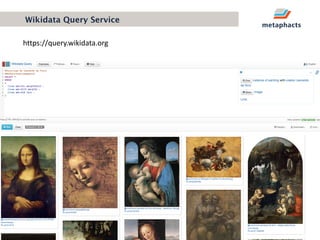

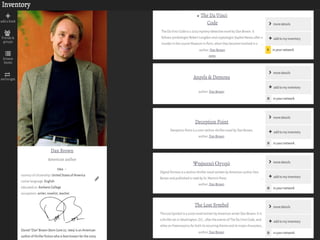
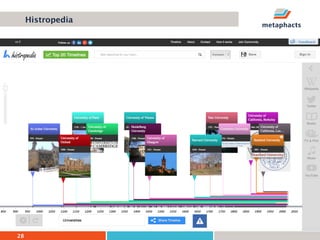



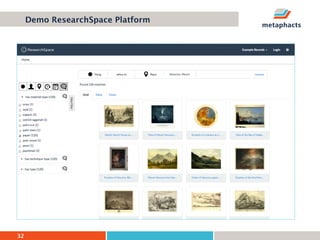


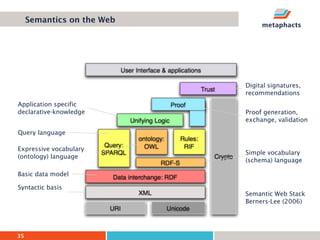
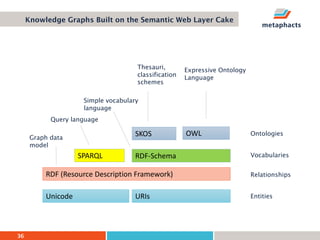
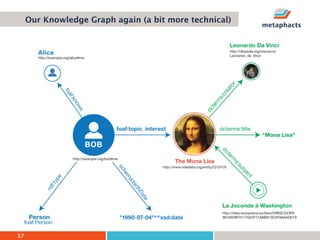





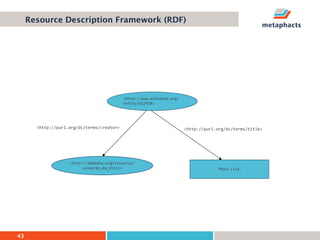













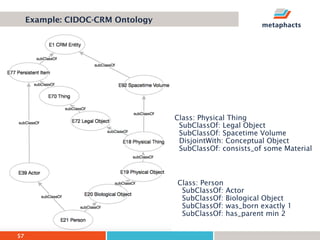





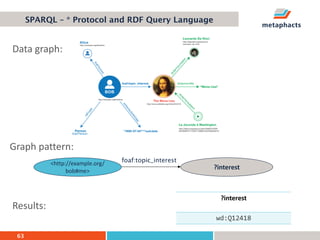
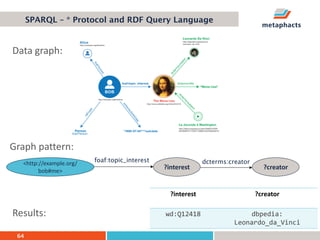














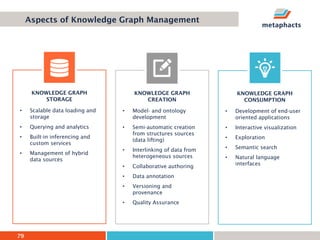
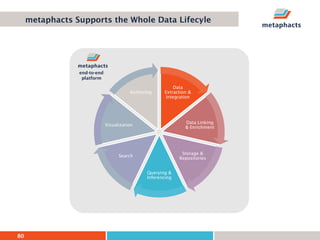

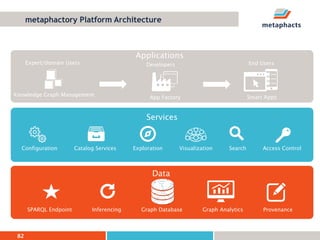
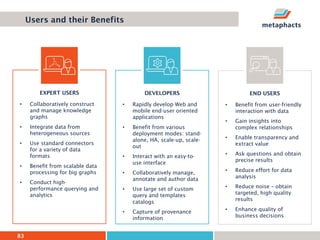




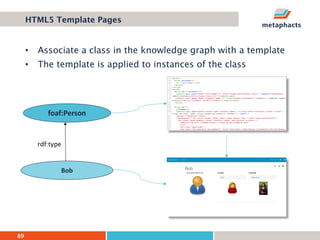



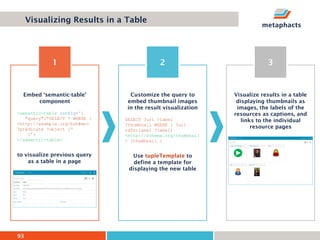
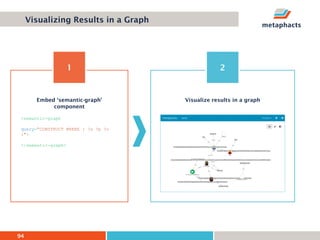
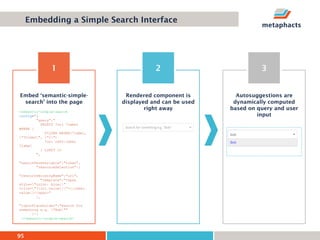




The document provides an overview of knowledge graphs and introduces metaphactory, a knowledge graph platform. It discusses what knowledge graphs are, examples like Wikidata, and standards like RDF. It also outlines an agenda for a hands-on session on loading sample data into metaphactory and exploring a knowledge graph.


















































































