Downloaded 21 times





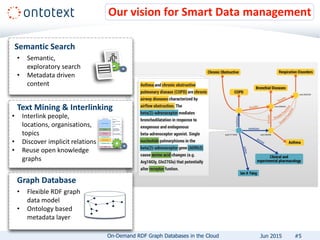





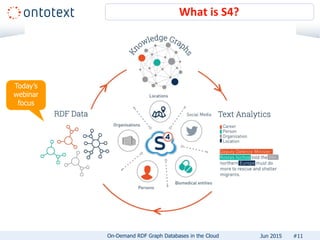


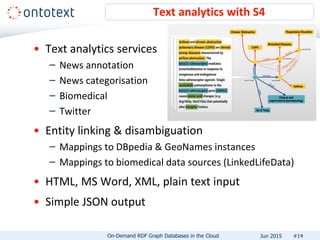


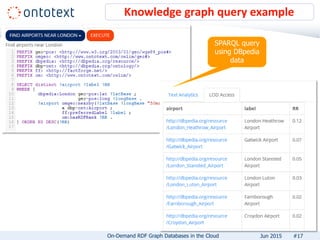


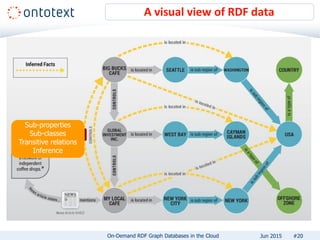

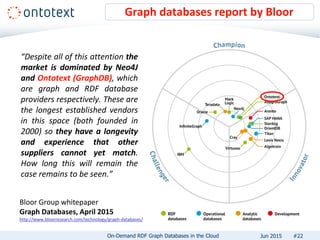




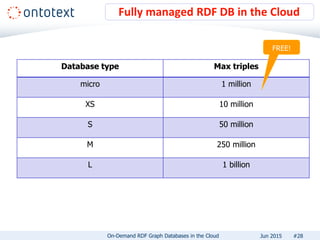
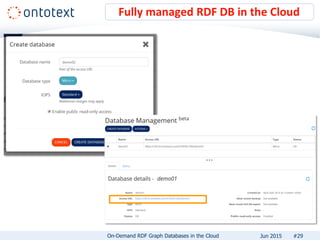



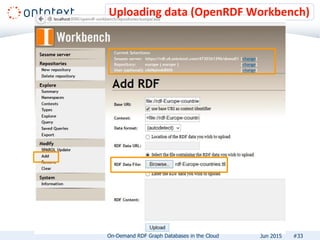
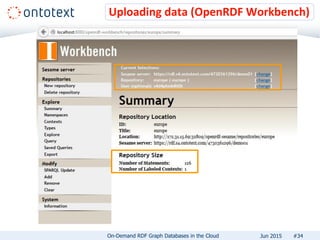
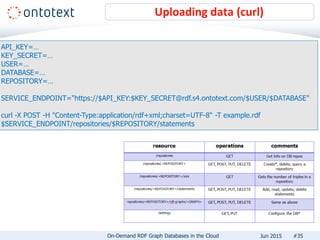


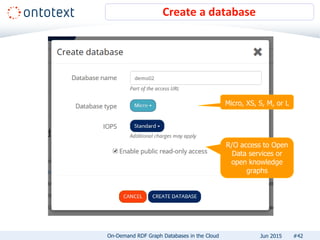
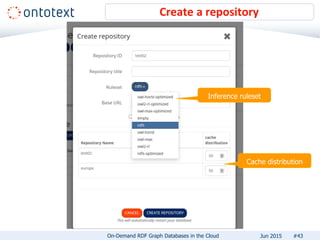
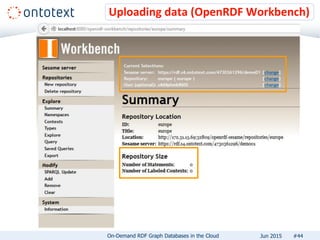
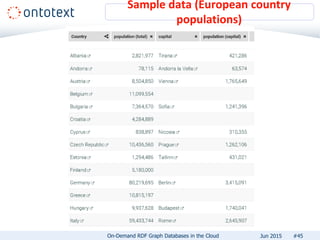
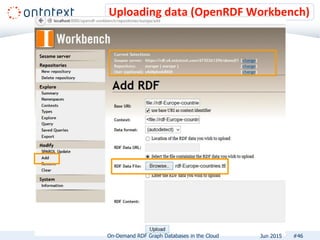
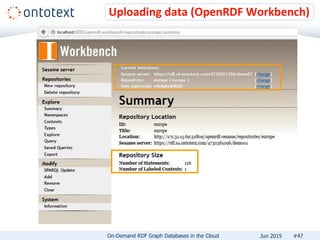
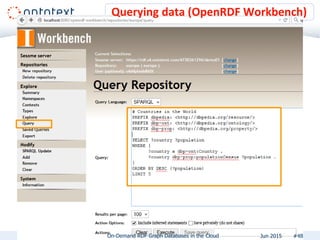
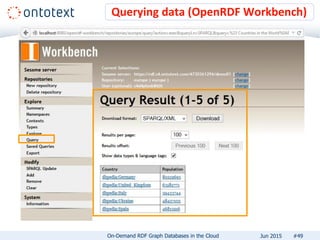
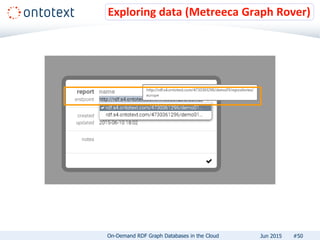
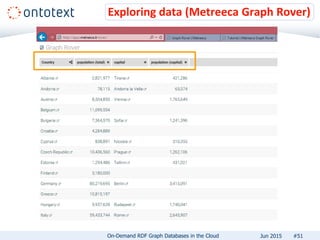
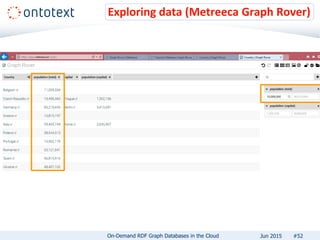
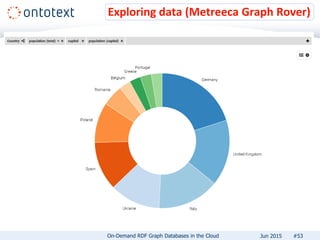






The document presents an overview of Ontotext's on-demand RDF graph databases in the cloud, highlighting their self-service semantic suite and capabilities for smart data management. It details various client profiles, including AstraZeneca and the Financial Times, outlining their goals, challenges, and how Ontotext's solutions enhance data access and decision-making. The summary also covers the features of the service, such as easy deployment, flexibility, and automated operations, along with resources for getting started.















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











