Downloaded 12 times

![3
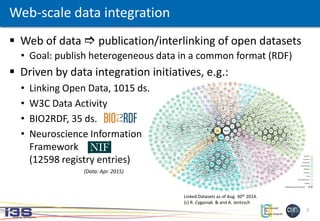
Web-scale data integration
Need to access data from the Deep Web [1]
• Strd./unstrd. data
hardly indexed by search engines,
hardly linked with other data sources
Exponential data growth goes on
• Various types of DBs:
RDB, NoSQL, NewSQL, Native XML,
LDAP directory, OODB...
• Heterogeneous data models and
query capabilities
[1] B. He, M. Patel, Z. Zhang, and K. C.-C. Chang. Accessing the deep web. Communications of the ACM, 50(5):94–101, 2007](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-3-320.jpg)






![11
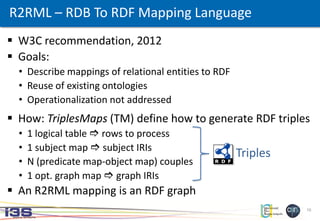
R2RML – RDB To RDF Mapping Language
Id Acronym Centre_Id
10 CAC2010 4
Id Name address
4 Pasteur ...
Study
Centre
FK
R2RML mapping graph:
Produced RDF:
<#Centre> a rr:TriplesMap;
rr:logicalTable [ rr:tableName "Centre" ];
rr:subjectMap [ rr:class ex:Centre;
rr:template "http://example.org/centre#{Name}"; ].
<#Study> a rr:TriplesMap;
rr:logicalTable [ rr:tableName “Study" ];
rr:subjectMap [ rr:class ex:Study;
rr:template "http://example.org/study#{Id}"; ];
rr:predicateObjectMap [
rr:predicate ex:hasName;
rr:objectMap [ rr:column "Acronym" ]; ];
rr:predicateObjectMap [
rr:predicate ex:locatedIn;
rr:objectMap [
rr:parentTriplesMap <#Centre>;
rr:joinCondition [
rr:child "Centre_id";
rr:parent "Id";
]; ]; ].
<http://example.org/centre#Pasteur> a ex:Centre.
<http://example.org/study#10> a ex:Study;
ex:hasName "CAC2010";
ex:locatedIn <http://example.org/centre#Pasteur>.](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-11-320.jpg)
![12
<#Centre>
rml:logicalSource [
rml:source “http://example.org/Centres.xml";
rml:referenceFormulation ql:XPath;
rml:iterator “/centres/centre”:
];
rr:subjectMap [
rr:class ex:Centre;
rr:template
"http://example.org/centre#{//centre/@Id}";
];
rr:predicateObjectMap [
rr:predicate ex:hasName;
rr:objectMap [
rml:reference "//centre/name" ];
];
RML extensions to R2RML
<centres>
<centre @Id="4">
<name>Pasteur</name>
</centre>
<centre @Id="6">
<name>Pontchaillou</name>
</centre>
</centres>
Advantages:
• Extends to CSV, JSON, XML sources
• Map several sources simultaneously
Limitations:
• Fixed list of reference formulations
• No distinction between reference
formulation and query language
• No RDF collections
RML mapping graph:XML document:](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-12-320.jpg)

![15
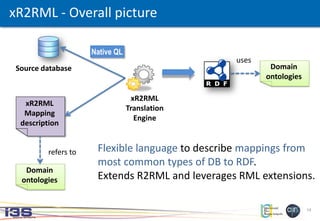
xR2RML: Logical source
<#Centre>
xrr:logicalSource [
xrr:query ’’’for $x in doc(“centres.xml”)/centres/centre
where ... return $x’’’;
];
rr: R2RML vocabulary
xrr: xR2RML vocabulary
<centres>
<centre @Id="4">
<name>Pasteur</name>
</centre>
<centre @Id="6">
<name>Pontchaillou</name>
</centre>
</centres>
XML database
supporting XQuey:
xR2RML mapping graph:](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-15-320.jpg)
![16
xR2RML: Data element references
<#Centre>
xrr:logicalSource [
xrr:query ’’’for $x in doc(“centres.xml”)/centres/centre
where ... return $x’’’;
];
rr:subjectMap [
rr:class ex:Centre;
rr:template
"http://example.org/centre#{//centre/@Id}";
];
rr:predicateObjectMap [
rr:predicate ex:hasName;
rr:objectMap [
xrr:reference "//centre/name" ];
];
rr: R2RML vocabulary
xrr: xR2RML vocabulary
<centres>
<centre @Id="4">
<name>Pasteur</name>
</centre>
<centre @Id="6">
<name>Pontchaillou</name>
</centre>
</centres>
XML database
supporting XQuey:
xR2RML mapping graph:](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-16-320.jpg)
![17
xR2RML: Data element references
<centres>
<centre @Id="4">
<name>Pasteur</name>
</centre>
<centre @Id="6">
<name>Pontchaillou</name>
</centre>
</centres>
XML database
supporting XQuey:
xR2RML mapping graph:
rr: R2RML vocabulary
xrr: xR2RML vocabulary
<#Centre>
xrr:logicalSource [
xrr:query ’’’for $x in doc(“centres.xml”)/centres/centre
where ... return $x’’’;
];
rr:subjectMap [
rr:class ex:Centre;
rr:template
"http://example.org/centre#{//centre/@Id}";
];
rr:predicateObjectMap [
rr:predicate ex:hasName;
rr:objectMap [
xrr:reference “//centre/name" ];
];
xR2RML engine usage guidelines
Types of DB xrr:query
xrr:reference
rr:template
RDB, Column
stores
SQL, CQL, HQL Column name
Native XML DB XQuery XPath
NoSQL doc. Store Proprietary JS-based JSONPath
SPARQL endpoint SPARQL
Variable name,
Column name (s, p, o)
Neo4J (graph db) Cypher Column name (s, p, o)
LDAP directory LDAP Query Attribute name
... ... ...](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-17-320.jpg)
![18
{ "studyid": 10,
"acronym": "CAC2010",
"centres": [
{ "centreid": 4, "name": "Pasteur" },
{ "centreid": 6, "name": "Pontchaillou" }
]
}
xR2RML: multiple values vs. RDF list/container
Mapping case: link the study
with the centres it involves
<http://example.org/study#10> ex:involves “Pasteur”.
<http://example.org/study#10> ex:involves “Pontchaillou”.
<http://example.org/study#10>
ex:involvesCenters ( “Pasteur” “Pontchaillou” )](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-18-320.jpg)
![19
{ "studyid": 10,
"acronym": "CAC2010",
"centres": [
{ "centreid": 4, "name": "Pasteur" },
{ "centreid": 6, "name": "Pontchaillou" }
]
}
xR2RML: multiple values vs. RDF list/container
Mapping case: link the study
with the centres it involves
rr:objectMap [
xrr:reference "$.centres.*.name“;
rr:termType xrr:RdfList;
];
R2RML
term types
rr:IRI,
rr:Literal,
rr:BlankNode
xR2RML
term types
xrr:RdfList,
xrr:RdfSeq,
xrr:RdfBag,
xrr:RdfAlt](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-19-320.jpg)
![20
xR2RML: nested collections
From structured values (XML, JSON...):
nested collections and key-value associations...
... to RDF:
generate nested lists/containers,
qualify members (data type,
language tag...)
rr:objectMap [
xrr:reference “...";
rr:termType xrr:RdfList;
xrr:nestedTermMap [
xrr:reference “...";
rr:termType xrr:RdfList;
xrr:nestedTermMap [
rr:datatype xsd:string;
]; ]; ];
(
( “John”^^xsd:string “Bob”^^xsd:string )
( “Ted”^^xsd:string “Mark”^^xsd:string )
)
E.g.: produce a list of lists of strings](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-20-320.jpg)
![21
Collection “studies”:
{ “studyid”: 10,
“acronym”: “CAC2010”,
“centres”: [ 4, 6 ]
}
Collection “centres”:
{ “centreid”: 4,
“name”: “Pasteur” },
{ “centreid”: 6,
“name”: “Pontchaillou”}
xR2RML: cross-references
<#Centre>
xrr:logicalSource [ ... ]; rr:subjectMap [ ... ].
<#Study>
xrr:logicalSource [ .. ]; rr:subjectMap [ ... ];
rr:predicateObjectMap [
rr:predicate ex:involvesSeq;
rr:objectMap [
rr:parentTriplesMap <#Centre>;
rr:joinCondition [
rr:child "$.centres.*";
rr:parent "$.centreid";
];
rr:termType xrr:RdfSeq;
];
].
<http://example.org/study#10> ex:involvesSeq
[ a rdf:Seq;
rdf:_1 <http://example.org/centre#Pasteur>;
rdf:_2 <http://example.org/centre#Pontchaillou>; ].
xR2RML mapping graph:MongoDB database:
Produced RDF:](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-21-320.jpg)
![22
Collection “studies”:
{ “studyid”: 10,
“acronym”: “CAC2010”,
“centres”: [ 4, 6 ]
}
Collection “centres”:
{ “centreid”: 4,
“name”: “Pasteur” },
{ “centreid”: 6,
“name”: “Pontchaillou”}
xR2RML: cross-references
<#Centre>
xrr:logicalSource [ ... ]; rr:subjectMap [ ... ].
<#Study>
xrr:logicalSource [ .. ]; rr:subjectMap [ ... ];
rr:predicateObjectMap [
rr:predicate ex:involvesSeq;
rr:objectMap [
rr:parentTriplesMap <#Centre>;
rr:joinCondition [
rr:child "$.centres.*";
rr:parent "$.centreid";
];
rr:termType xrr:RdfSeq;
];
].
xR2RML mapping graph:MongoDB database:
Joint query pushed to the DB
if supported, performed by
the xR2RML engine otherwise
<http://example.org/study#10> ex:involvesSeq
[ a rdf:Seq;
rdf:_1 <http://example.org/centre#Pasteur>;
rdf:_2 <http://example.org/centre#Pontchaillou>; ].
Produced RDF:](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-22-320.jpg)
![23
<#Centre>
xrr:logicalSource [
xrr:sourceName "STAFF";
];
...
rr:predicateObjectMap [
rr:predicate ex:fist-name;
rr:objectMap [
xrr:reference
"Column(Name)/JSONPath($.FirstName)" ];
];
xR2RML: content with mixed formats
Data with mixed content
Relational table “STAFF”, column “Name”
contains JSON data:
... Name ...
... {
“FirstName”: “Bob”,
“LastName: “Smith”
}
...
xR2RML mapping graph:](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-23-320.jpg)
![24
<#Centre>
xrr:logicalSource [
xrr:sourceName "STAFF";
];
...
rr:predicateObjectMap [
rr:predicate ex:fist-name;
rr:objectMap [
xrr:reference
"Column(Name)/JSONPath($.FirstName)" ];
];
xR2RML: content with mixed formats
Data with mixed content
Relational table “STAFF”, column “Name”
contains JSON data:
... Name ...
... {
“FirstName”: “Bob”,
“LastName: “Smith”
}
...
Data
format
Syntax path constructor
Row Column(), CSV(), TSV()
XML XPath()
JSON JSONPath()
... ...
xR2RML mapping graph:](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-24-320.jpg)


![27
Ongoing work [2]: Construction of a SKOS1 thesaurus based
on TAXREF
• Import of TAXREF/JSON into MongoDB
• Use of the Morph-xR2RML prototype implementation of
xR2RML, to convert the MongoDB data to RDF
• Make alignments with existing well-adopted ontologies
(e.g. NCBI Taxonomic Classification, GeoNames...)
• Static alignments at mapping design time
• Using automatic alignment methods
Use case in Digital Humanities
1 SKOS: Simple Knowledge Organization System, W3C RDF-based standard to represent controlled
vocabularies, taxonomies and thesauri. Bridge the gap between existing KOS and the Semantic Web
and Linked Data.](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-27-320.jpg)

![30
Contacts:
Franck Michel
Johan Montagnat
Catherine Faron-Zucker
[2] C. Callou, F. Michel, C. Faron-Zucker, C. Martin, J. Montagnat. Towards a Shared Reference Thesaurus for
Studies on History of Zoology, Archaeozoology and Conservation Biology. In SW4SH workshop, ESWC’15.
[3] F. Michel, L. Djimenou, C. Faron-Zucker, and J. Montagnat. xR2RML: Non-Relational Databases to RDF
Mapping Language. Research report. ISRN I3S/RR 2014-04-FR. http://hal.archives-ouvertes.fr/hal-01066663
https://github.com/frmichel/morph-xr2rml/](https://image.slidesharecdn.com/20150530xr2rmlwebist15-2-final-150601155324-lva1-app6892/85/Translation-of-Relational-and-Non-Relational-Databases-into-RDF-with-xR2RML-30-320.jpg)

xR2RML is a mapping language that extends R2RML and RML to enable the translation of heterogeneous data sources, including relational databases, NoSQL databases, XML documents, JSON documents and more, to RDF. xR2RML provides a unified approach for describing mappings from various data models and query languages to RDF through the use of logical sources, references to data elements, and support for nested collections and cross-references between data sources. This allows for standardized translation of diverse data to the semantic web.

































































































