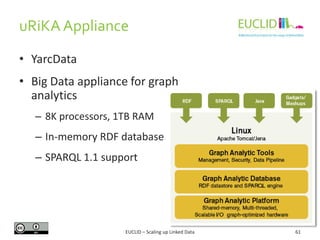
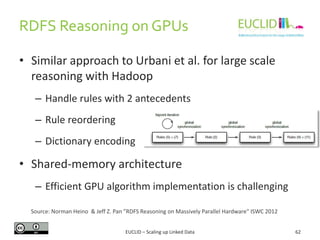
Downloaded 40 times















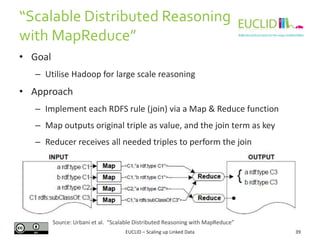
![Document Databases (2)
24
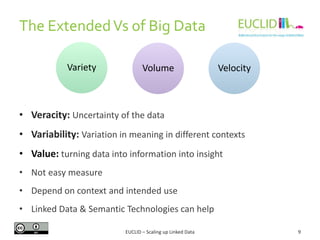
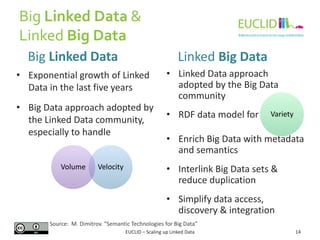
Example:
{
Homepage: "thebeatles.com",
Origin: "Liverpool",
Albums: [
{Title: "Let it be", Year: "1970", Duration: "35:16"},
{Title: "Help!", Year: "1965"},
{Title: "Revolver", Year: "1966", Duration: "35:01"}
]
}
The Beatles
{
FullName: "Elvis Aaron Presley",
Homepage: "elvis.com",
Origin: "Memphis"
Albums: [
{Title: "Blue Hawaii", Year: "1961", Duration:
"32:02"}
]
}
Elvis Presley
EUCLID – Scaling up Linked Data](https://image.slidesharecdn.com/webinar6-150312042215-conversion-gate01/85/Scaling-up-Linked-Data-24-320.jpg)














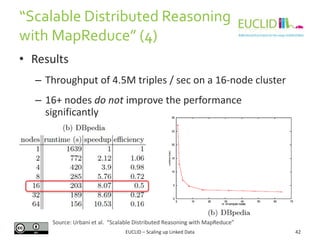




![C-SPARQL (1)
50
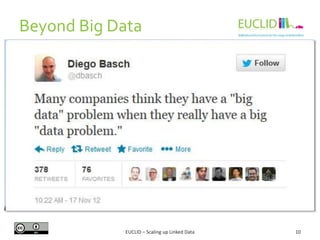
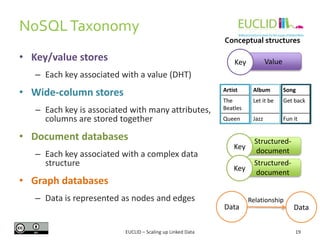
C-SPARQL is an extension of SPARQL 1.1
FromStrClause 'FROM' ['NAMED'] 'STREAM' StreamIRI
' [ RANGE' Window ']'
Window LogicalWindow | PhysicalWindow
LogicalWindow Number TimeUnit WindowOverlap
TimeUnit 'MSEC' | 'SEC' | 'MIN' | 'HOUR' |
'DAY'
WindowOverlap 'STEP' Number TimeUnit | 'TUMBLING'
PhysicalWindow 'TRIPLES' Number
1. RDF Streams: Sequence of RDF triples annotated with timestamps:
<(s,p,o), timestamp>
2. FROM STREAM extension for stream sources and windows
EUCLID – Scaling up Linked Data](https://image.slidesharecdn.com/webinar6-150312042215-conversion-gate01/85/Scaling-up-Linked-Data-49-320.jpg)

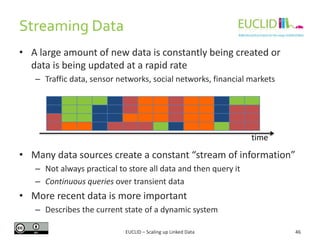
![C-SPARQL (3)
52
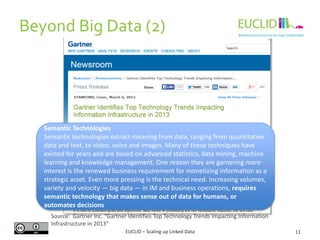
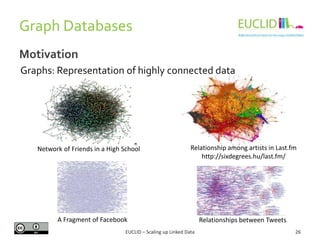
Example
REGISTER QUERY CarsEnteringInDistricts AS
SELECT DISTINCT ?district ?car
FROM STREAM <www.uc.eu/tollgates.trdf> [RANGE 40 SEC STEP 10 SEC]
WHERE {
?toll t:registers ?car .
?toll c:placedIn ?street .
?district c:contains ?street . }
Query: Retrieve the cars and districts, where the car was registered in a toll.
Source: Barbieri, Davide Francesco, et al. "Querying rdf streams with c-sparql." ACM SIGMOD
Record 39.1 (2010): 20-26.
EUCLID – Scaling up Linked Data](https://image.slidesharecdn.com/webinar6-150312042215-conversion-gate01/85/Scaling-up-Linked-Data-51-320.jpg)
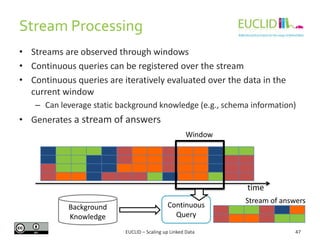
![SPARQLStream(1)
54
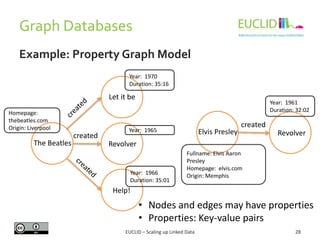
• Utilizes the same definition of RDF streams as in C-SPARQL:
• The language is defined as follows:
<(s,p,o), timestamp>
NamedStream 'FROM' ['NAMED'] 'STREAM' StreamIRI ' [' Window ']'
Window 'NOW-' Integer TimeUnit [UpperBound] [Slide]
UpperBound 'TO NOW-' Integer TimeUnit
Slide 'SLIDE' Integer TimeUnit
TimeUnit 'MS' | 'S' | 'MINUTES' | 'HOURS' | 'DAY'
Select 'SELECT' [XStream] [DISTINCT | REDUCED] …
Xstream 'ISTREAM' | 'DSTREAM' | 'RSTREAM'
Source: Jean-Paul Calbimonte and Oscar Corcho. ”SPARQLStream: Ontology-based access to data
streams." Tutorial at ISWC 2013
EUCLID – Scaling up Linked Data](https://image.slidesharecdn.com/webinar6-150312042215-conversion-gate01/85/Scaling-up-Linked-Data-53-320.jpg)
![SPARQLStream(2)
55
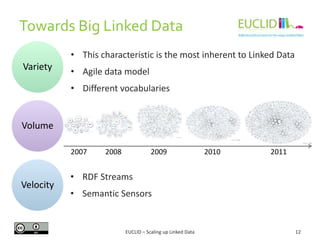
Example
Query: Retrieve a rstream with the observations captured by all sensors in the last
10 minutes.
PREFIX ssn: <http://purl.oclc.org/NET/ssnx/ssn>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns/#>
SELECT RSTREAM ?sensor ?observation
FROM STREAM <www.semsorgrid4env.eu/SensorReadings.srdf>
[FROM NOW – 10 MINUTES TO NOW STEP 1 MINUTE]
WHERE {
?observation a ssn:Observation;
ssn:observedBy ?sensor .
}
EUCLID – Scaling up Linked Data](https://image.slidesharecdn.com/webinar6-150312042215-conversion-gate01/85/Scaling-up-Linked-Data-54-320.jpg)









The document discusses the development of a music-based portal using linked data technologies and explores various mechanisms for managing and processing large volumes of linked data. It highlights the importance of semantic technologies in big data management, providing an overview of NoSQL databases, Hadoop, and stream processing relevant to linked data. The chapter aims to address challenges in linked data integration, querying, and scalability through the use of contemporary technologies and methodologies.