参考資料オススメPickup
◆Deep Learning全般
Bengio, Y.(2009). Learning deep architectures for AI. Foundations and trends®
in Machine Learning, 2(1), 1-127.
(上の日本語解説)
http://www.slideshare.net/alembert2000/learning-deep-architectures-for-ai-3-deep-
learning
Kyunghyun Choの「Deep Learning: Past, Present and Future (?)」
https://drive.google.com/file/d/0B16RwCMQqrtdb05qdDFnSXprM0E/view?sle=true&pli=1
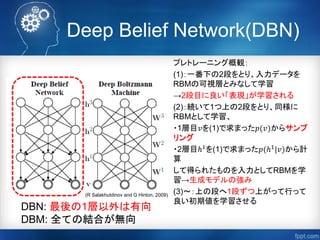
◆RBM・DBN
UCL Tutorials on Deep Belief Net(G Hinton)(考案者自身のチュートリアルスライド)
http://www.cs.toronto.edu/~hinton/ucltutorial.pdf
「Restricted Boltzmann Machineの導出に至る自分用まとめ(齋藤真樹)」
https://dl.dropboxusercontent.com/u/2048288/RestrictedBoltzmannMachine.pdf
Tutorial on Deep Learning and Applications(Honglak Lee)
http://deeplearningworkshopnips2010.files.wordpress.com/2010/09/nips10-workshop-
tutorial-final.pdf
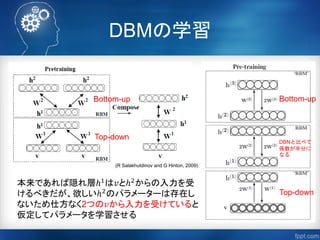
81.
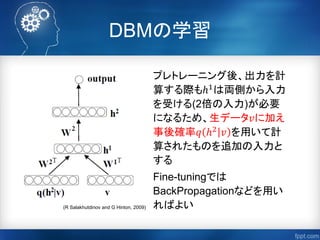
参考資料オススメPickup
◆Contrastive Divergenceを取り上げている論文
・スライド中も引用があったBengio先生のサーベイ
Bengio, Y.(2009). Learning deep architectures for AI. Foundations and trends® in
Machine Learning, 2(1), 1-127
・CD法の持つ基本的な性質を分析
Carreira-Perpinan, M. A., & Hinton, G. E. (2005, January). On contrastive divergence
learning. In Proceedings of the tenth international workshop on artificial intelligence and
statistics (pp. 33-40). NP: Society for Artificial Intelligence and Statistics.
・CD法及びその拡張が実際に効果を上げていることを実験によって証明
Fischer, A., & Igel, C. (2010). Empirical analysis of the divergence of Gibbs sampling
based learning algorithms for restricted Boltzmann machines. In Artificial Neural
Networks–ICANN 2010 (pp. 208-217). Springer Berlin Heidelberg.
・CD法を直接取り上げているわけではないが、実際にRBMで学習させる際のコツを述
べている
Hinton, G. (2010). A practical guide to training restricted Boltzmann machines.
Momentum, 9(1), 926.
82.
参考資料
◆Slideshare
「Deep Learning 三戸智浩」http://www.slideshare.net/tomohiromito/deep-learning-
22425259
「一般向けのDeepLearning(PFI 岡野原大輔)」
http://www.slideshare.net/pfi/deep-learning-22350063
「Deep Learning技術の今(PFI 得居誠也」(全脳アーキテクチャ勉強会第2回 資料)
http://www.slideshare.net/beam2d/deep-learning20140130
「DeepLearning 実装の基礎と実践(PFI 得居誠也)」
http://www.slideshare.net/beam2d/deep-learningimplementation
「Learning Deep Architectures for AI(日本語解説)」(全脳アーキテクチャ勉強会第3回 資料)
http://www.slideshare.net/alembert2000/learning-deep-architectures-for-ai-3-deep-
learning
「ディープボルツマンマシン入門」
http://www.slideshare.net/yomoyamareiji/ss-36093633
「文書校正を究める WITH DEEP LEARNING」
http://www.slideshare.net/kmt-t/ss-40706560
83.
参考資料
◆サーベイ・発表スライドなど
「Restricted Boltzmann Machineの導出に至る自分用まとめ(齋藤真樹)」
https://dl.dropboxusercontent.com/u/2048288/RestrictedBoltzmannMachine.pdf
「DeepLearning: Past, Present and Future(?)」
https://drive.google.com/file/d/0B16RwCMQqrtdb05qdDFnSXprM0E/view?sle=true&pli=1
「ディープラーニング チュートリアル(もしくは研究動向報告)」
http://www.vision.is.tohoku.ac.jp/files/9313/6601/7876/CVIM_tutorial_deep_learning.pdf
「Tera-scale deep learning(Googleの猫)」
http://static.googleusercontent.com/media/research.google.com/ja//archive/unsupervised_learning_talk_2012.pdf
「統計的機械学習入門(上田修功)」
http://www.nii.ac.jp/userdata/karuizawa/h23/111104_3rdlecueda.pdf
「Tutorial on Deep Learning and Applications(Honglak Lee)」
http://deeplearningworkshopnips2010.files.wordpress.com/2010/09/nips10-workshop-tutorial-final.pdf
「ImageNet Classification with Deep Convolutional Neural Networks」
http://www.image-net.org/challenges/LSVRC/2012/supervision.pdf
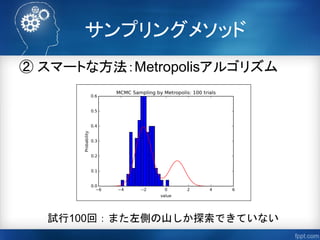
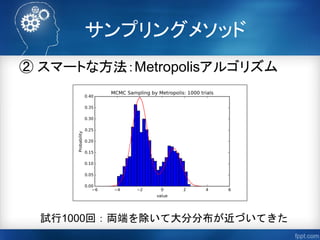
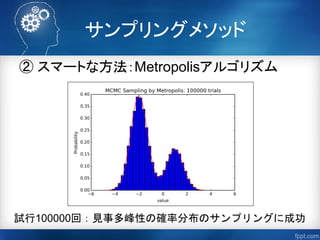
「マルコフ連鎖モンテカルロ法(山道真人)」
http://tombo.sub.jp/doc/esj55/MCMC.pdf
An Efficient Learning Algorithms for Deep Boltzmann Machine
https://www.cs.toronto.edu/~hinton/absps/efficientDBM.pdf
UCL Tutorials on Deep Belief Net(G Hinton)
http://www.cs.toronto.edu/~hinton/ucltutorial.pdf
「生成モデルに対するディープラーニング]
http://www.slideshare.net/yonetani/sec4-34880884
参考資料
◆論文
Ackley, D. H.,Hinton, G. E., & Sejnowski, T. J. (1985). A learning algorithm for boltzmann machines*.
Cognitive science, 9(1), 147-169.
Bengio, Y. (2009). Learning deep architectures for AI. Foundations and trends® in Machine Learning,
2(1), 1-127.
Bengio, Y., Lamblin, P., Popovici, D., & Larochelle, H. (2007). Greedy layer-wise training of deep
networks. Advances in neural information processing systems, 19, 153.
Carreira-Perpinan, M. A., & Hinton, G. E. (2005, January). On contrastive divergence learning.
In Proceedings of the tenth international workshop on artificial intelligence and statistics (pp. 33-40).
NP: Society for Artificial Intelligence and Statistics.
Erhan, D., Bengio, Y., Courville, A., Manzagol, P. A., Vincent, P., & Bengio, S. (2010). Why does
unsupervised pre-training help deep learning?. The Journal of Machine Learning Research, 11, 625-
660.
Fischer, A., & Igel, C. (2010). Empirical analysis of the divergence of Gibbs sampling based learning
algorithms for restricted Boltzmann machines. In Artificial Neural Networks–ICANN 2010 (pp. 208-
217). Springer Berlin Heidelberg.
Fischer, A., & Igel, C. (2012). An introduction to restricted Boltzmann machines. In Progress in Pattern
Recognition, Image Analysis, Computer Vision, and Applications (pp. 14-36). Springer Berlin
Heidelberg.
86.
参考資料
Hinton, G. E.,& Salakhutdinov, R. (2009). Replicated softmax: an undirected topic model. In Advances
in neural information processing systems (pp. 1607-1614).
Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. R. (2012). Improving
neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580.
Hinton, G. (2010). A practical guide to training restricted Boltzmann machines. Momentum, 9(1), 926.
Lee, H., Ekanadham, C., & Ng, A. Y. (2008). Sparse deep belief net model for visual area V2.
In Advances in neural information processing systems (pp. 873-880).
Le Roux, N., & Bengio, Y. (2008). Representational power of restricted Boltzmann machines and deep
belief networks. Neural Computation, 20(6), 1631-1649.
Le, Q. V. (2013, May). Building high-level features using large scale unsupervised learning. In
Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on (pp.
8595-8598). IEEE.
Montufar, G., & Ay, N. (2011). Refinements of universal approximation results for deep belief networks
and restricted Boltzmann machines. Neural Computation, 23(5), 1306-1319.
Pfeifer, R., Lungarella, M., & Iida, F. (2007). Self-organization, embodiment, and biologically inspired
robotics. science, 318(5853), 1088-1093.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Fei-Fei, L. (2014). ImageNet
Large Scale Visual Recognition Challenge. arXiv preprint arXiv:1409.0575.
Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine learning, 20(3), 273-297.
87.
参考資料
Salakhutdinov, R. (2009).Learning in Markov random fields using tempered transitions. In Advances
in neural information processing systems (pp. 1598-1606).
Salakhutdinov, R., & Hinton, G. E. (2009). Deep boltzmann machines. In International Conference on
Artificial Intelligence and Statistics (pp. 448-455).
Smolensky, P. (1986). Information processing in dynamical systems: Foundations of harmony theory.
Taylor, G. W., Hinton, G. E., & Roweis, S. T. (2006). Modeling human motion using binary latent
variables. In Advances in neural information processing systems (pp. 1345-1352).























































![参考資料
◆サーベイ・発表スライドなど
「Restricted Boltzmann Machineの導出に至る自分用まとめ(齋藤真樹)」
https://dl.dropboxusercontent.com/u/2048288/RestrictedBoltzmannMachine.pdf
「Deep Learning: Past, Present and Future(?)」
https://drive.google.com/file/d/0B16RwCMQqrtdb05qdDFnSXprM0E/view?sle=true&pli=1
「ディープラーニング チュートリアル(もしくは研究動向報告)」
http://www.vision.is.tohoku.ac.jp/files/9313/6601/7876/CVIM_tutorial_deep_learning.pdf
「Tera-scale deep learning(Googleの猫)」
http://static.googleusercontent.com/media/research.google.com/ja//archive/unsupervised_learning_talk_2012.pdf
「統計的機械学習入門(上田修功)」
http://www.nii.ac.jp/userdata/karuizawa/h23/111104_3rdlecueda.pdf
「Tutorial on Deep Learning and Applications(Honglak Lee)」
http://deeplearningworkshopnips2010.files.wordpress.com/2010/09/nips10-workshop-tutorial-final.pdf
「ImageNet Classification with Deep Convolutional Neural Networks」
http://www.image-net.org/challenges/LSVRC/2012/supervision.pdf
「マルコフ連鎖モンテカルロ法(山道真人)」
http://tombo.sub.jp/doc/esj55/MCMC.pdf
An Efficient Learning Algorithms for Deep Boltzmann Machine
https://www.cs.toronto.edu/~hinton/absps/efficientDBM.pdf
UCL Tutorials on Deep Belief Net(G Hinton)
http://www.cs.toronto.edu/~hinton/ucltutorial.pdf
「生成モデルに対するディープラーニング]
http://www.slideshare.net/yonetani/sec4-34880884](https://image.slidesharecdn.com/rbm-and-learning-141116074650-conversion-gate01/85/RBM-Deep-Learning-3-DL-83-320.jpg)












![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Opening the Black Box of Deep Neural Networks via Information](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks10161-171027055615-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)







![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DL輪読会]Deep Learning for Sampling from Arbitrary Probability Distributions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0216-180219071029-thumbnail.jpg?width=640&height=640&fit=bounds)














