Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Sotetsu KOYAMADA(小山田創哲)
PDF, PPTX
79,307 views
EMアルゴリズム
EMアルゴリズムについてのスライド 2014.06.26@ATR
Data & Analytics
◦
Read more
64
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 55
2
/ 55
3
/ 55
4
/ 55
5
/ 55
6
/ 55
7
/ 55
8
/ 55
9
/ 55
10
/ 55
11
/ 55
12
/ 55
13
/ 55
14
/ 55
15
/ 55
16
/ 55
17
/ 55
18
/ 55
Most read
19
/ 55
Most read
20
/ 55
21
/ 55
22
/ 55
23
/ 55
24
/ 55
25
/ 55
26
/ 55
Most read
27
/ 55
28
/ 55
29
/ 55
30
/ 55
31
/ 55
32
/ 55
33
/ 55
34
/ 55
35
/ 55
36
/ 55
37
/ 55
38
/ 55
39
/ 55
40
/ 55
41
/ 55
42
/ 55
43
/ 55
44
/ 55
45
/ 55
46
/ 55
47
/ 55
48
/ 55
49
/ 55
50
/ 55
51
/ 55
52
/ 55
53
/ 55
54
/ 55
55
/ 55
More Related Content
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PDF
PRML Chapter 14
by
Masahito Ohue
PDF
深層学習 勉強会第5回 ボルツマンマシン
by
Yuta Sugii
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PDF
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PDF
サポートベクトルマシン(SVM)の勉強
by
Kazuki Adachi
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PRML Chapter 14
by
Masahito Ohue
深層学習 勉強会第5回 ボルツマンマシン
by
Yuta Sugii
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PRML 上 2.3.6 ~ 2.5.2
by
禎晃 山崎
機械学習の理論と実践
by
Preferred Networks
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
サポートベクトルマシン(SVM)の勉強
by
Kazuki Adachi
What's hot
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PPTX
Sliced Wasserstein距離と生成モデル
by
ohken
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PDF
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PPTX
劣モジュラ最適化と機械学習1章
by
Hakky St
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PPTX
Noisy Labels と戦う深層学習
by
Plot Hong
PPTX
データサイエンス概論第一 5 時系列データの解析
by
Seiichi Uchida
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
最適輸送入門
by
joisino
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
変分ベイズ法の説明
by
Haruka Ozaki
機械学習のためのベイズ最適化入門
by
hoxo_m
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
Sliced Wasserstein距離と生成モデル
by
ohken
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
機械学習モデルの判断根拠の説明
by
Satoshi Hara
劣モジュラ最適化と機械学習1章
by
Hakky St
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
Noisy Labels と戦う深層学習
by
Plot Hong
データサイエンス概論第一 5 時系列データの解析
by
Seiichi Uchida
数学で解き明かす深層学習の原理
by
Taiji Suzuki
最適輸送入門
by
joisino
Viewers also liked
PDF
数式を使わずイメージで理解するEMアルゴリズム
by
裕樹 奥田
PPTX
確率ロボティクス第13回
by
Ryuichi Ueda
PDF
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
PDF
パターン認識 04 混合正規分布
by
sleipnir002
PDF
ニューラルネットワークの数理
by
Task Ohmori
PDF
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料)
by
Takuma Yagi
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
PDF
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
PPTX
NIPS2015読み会: Ladder Networks
by
Eiichi Matsumoto
数式を使わずイメージで理解するEMアルゴリズム
by
裕樹 奥田
確率ロボティクス第13回
by
Ryuichi Ueda
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
パターン認識 04 混合正規分布
by
sleipnir002
ニューラルネットワークの数理
by
Task Ohmori
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料)
by
Takuma Yagi
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
NIPS2015読み会: Ladder Networks
by
Eiichi Matsumoto
Similar to EMアルゴリズム
PDF
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
PPTX
Gmm勉強会
by
Hayato Ohya
PDF
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
PDF
PRML輪読#9
by
matsuolab
PDF
情報幾何勉強会 EMアルゴリズム
by
Shinagawa Seitaro
PDF
PRML 9章
by
ぱんいち すみもと
PDF
Data-Intensive Text Processing with MapReduce ch6.1
by
Sho Shimauchi
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
Prml sec6
by
Keisuke OTAKI
PPTX
機械学習理論入門 7章 emアルゴリズム_遠藤
by
Wataru Endo
PDF
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
PDF
Oshasta em
by
Naotaka Yamada
PPTX
Abstract of Extreme Learning Machine
by
Takenobu Sasatani
PDF
Dynamic panel in tokyo r
by
Shota Yasui
PDF
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
PDF
PRML_from5.1to5.3.1
by
禎晃 山崎
PPTX
[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging
by
Yu Otsuka
PDF
prml_titech_9.0-9.2
by
Taikai Takeda
PDF
How to study stat
by
Ak Ok
混合ガウスモデルとEMアルゴリスム
by
貴之 八木
Gmm勉強会
by
Hayato Ohya
PRML復々習レーン#15 前回までのあらすじ
by
sleepy_yoshi
PRML輪読#9
by
matsuolab
情報幾何勉強会 EMアルゴリズム
by
Shinagawa Seitaro
PRML 9章
by
ぱんいち すみもと
Data-Intensive Text Processing with MapReduce ch6.1
by
Sho Shimauchi
PRML第6章「カーネル法」
by
Keisuke Sugawara
Prml sec6
by
Keisuke OTAKI
機械学習理論入門 7章 emアルゴリズム_遠藤
by
Wataru Endo
Bishop prml 9.3_wk77_100408-1504
by
Wataru Kishimoto
Oshasta em
by
Naotaka Yamada
Abstract of Extreme Learning Machine
by
Takenobu Sasatani
Dynamic panel in tokyo r
by
Shota Yasui
クラシックな機械学習の入門 9. モデル推定
by
Hiroshi Nakagawa
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
PRML_from5.1to5.3.1
by
禎晃 山崎
[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging
by
Yu Otsuka
prml_titech_9.0-9.2
by
Taikai Takeda
How to study stat
by
Ak Ok
More from Sotetsu KOYAMADA(小山田創哲)
PDF
【論文紹介】Reward Augmented Maximum Likelihood for Neural Structured Prediction
by
Sotetsu KOYAMADA(小山田創哲)
PDF
【論文紹介】PGQ: Combining Policy Gradient And Q-learning
by
Sotetsu KOYAMADA(小山田創哲)
PDF
【強化学習】Montezuma's Revenge @ NIPS2016
by
Sotetsu KOYAMADA(小山田創哲)
PDF
KDD2016論文読み会資料(DeepIntent)
by
Sotetsu KOYAMADA(小山田創哲)
PDF
強化学習勉強会・論文紹介(Kulkarni et al., 2016)
by
Sotetsu KOYAMADA(小山田創哲)
PDF
強化学習勉強会・論文紹介(第22回)
by
Sotetsu KOYAMADA(小山田創哲)
PDF
Principal Sensitivity Analysis
by
Sotetsu KOYAMADA(小山田創哲)
PDF
KDD2015論文読み会
by
Sotetsu KOYAMADA(小山田創哲)
PDF
KDD2014勉強会 発表資料
by
Sotetsu KOYAMADA(小山田創哲)
PDF
知能型システム論(後半)
by
Sotetsu KOYAMADA(小山田創哲)
PDF
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
【論文紹介】Reward Augmented Maximum Likelihood for Neural Structured Prediction
by
Sotetsu KOYAMADA(小山田創哲)
【論文紹介】PGQ: Combining Policy Gradient And Q-learning
by
Sotetsu KOYAMADA(小山田創哲)
【強化学習】Montezuma's Revenge @ NIPS2016
by
Sotetsu KOYAMADA(小山田創哲)
KDD2016論文読み会資料(DeepIntent)
by
Sotetsu KOYAMADA(小山田創哲)
強化学習勉強会・論文紹介(Kulkarni et al., 2016)
by
Sotetsu KOYAMADA(小山田創哲)
強化学習勉強会・論文紹介(第22回)
by
Sotetsu KOYAMADA(小山田創哲)
Principal Sensitivity Analysis
by
Sotetsu KOYAMADA(小山田創哲)
KDD2015論文読み会
by
Sotetsu KOYAMADA(小山田創哲)
KDD2014勉強会 発表資料
by
Sotetsu KOYAMADA(小山田創哲)
知能型システム論(後半)
by
Sotetsu KOYAMADA(小山田創哲)
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
EMアルゴリズム
1.
EM algorithm 2014.6.26 TN輪講@ATR 京大情報学M2
小山田 創哲
2.
Contents 1. Generative model(準備) 2. EMアルゴリズム(メイン) 1. 例)Gaussian
mixtureの最尤推定 2. EMアルゴリズムの説明 3. 自由エネルギーを使った再解釈 3. 変分ベイズ(少しだけ)
3.
Generative model
4.
Generative model Generative modelとは一言で言えば, のことであり,立てたモデル(のパラメー タ)は観測データから推定される 比較)Discriminative
model 観測データを生成するモデル
5.
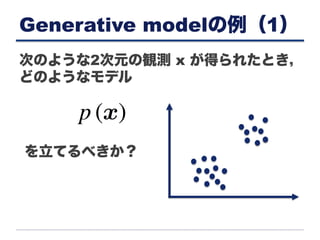
Generative modelの例(1) 次のような2次元の観測 x
が得られたとき, どのようなモデル を立てるべきか?
6.
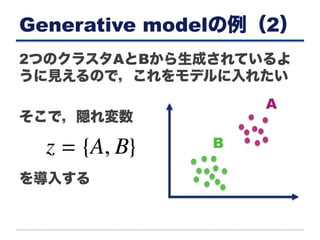
Generative modelの例(2) 2つのクラスタAとBから生成されているよ うに見えるので,これをモデルに入れたい そこで,隠れ変数 を導入する A B
7.
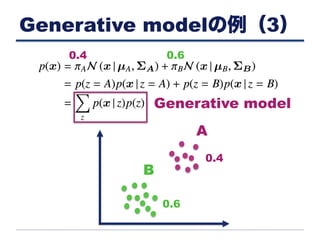
Generative modelの例(3) A B 0.4 0.6 0.4 0.6 Generative
model
8.
Generative modelと同時分布 観測データの背後にある因果(隠れ変数) まで含めた同時分布のモデルを立てている ことに相当している
9.
EM algorithm
10.
EMアルゴリズム EMアルゴリズムとは一言で言えば, である 隠れ変数を含むモデルの学習 に使われるアルゴリズム まずGaussian mixtureの最尤推定を例に EMアルゴリズムの必要性と流れを紹介する
11.
Contents 1. Generative model(準備) 2. EMアルゴリズム(メイン) 1. 例)Gaussian
mixtureの最尤推定 2. EMアルゴリズムの説明 3. 自由エネルギーを使った再解釈 3. 変分ベイズ(少しだけ)
12.
例)Gaussian mixture ガウス分布の線形結合で表されるモデル
13.
例)Gaussian mixture Generative model として捉えられる
14.
事後分布 観測変数 x は実際に観測データが与えられ るのに対し,隠れ変数
z はデータが与えら れないので,事後分布を考えることになる この事後分布を負担率とよぶ
15.
例)Gaussian mixture 2通りの見方が出来る 1. 観測変数 x
だけのモデル 2. 観測変数 x と 隠れ変数 z のモデル
16.
例)Gaussian mixture 2通りの見方が出来る 1. 観測変数 x
だけのモデル まず,1の見方で最尤推定をする その過程でEMアルゴリズムの必要性と EMアルゴリズムと等価なアルゴリズムを 説明する
17.
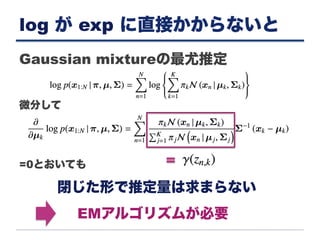
Gaussian mixtureの最尤推定 対数尤度を計算して,最大化する log が
exp に直接かからない!!
18.
log が exp
に直接かかれば 【復習】単体のガウス分布の最尤推定 閉形式で最尤推定量が求まる!! 微分して
19.
log が exp
に直接かからないと Gaussian mixtureの最尤推定 微分して =0とおいても 閉じた形で推定量は求まらない EMアルゴリズムが必要
20.
最尤推定のアルゴリズム 閉じた形では推定量が求まらないことを確 認したので,次はEMアルゴリズムと等価な アルゴリズムを示す
21.
引き続き計算をする =0とおいて整理すると
22.
尤度を最大にするパラメータ もれなく負担率が入り,閉形式にはなって いないが,綺麗に整理できた
23.
交互に最適化する 負担率はパラメータの値さえ決まれば求まる パラメータは負担率さえ決まれば求まる 交互に片方を固定し,もう一方を求める
24.
最尤推定のアルゴリズム 1. 各パラメータを初期化 2. 現在のパラメータを用いて負担率を計算 3.
現在の負担率を使ってパラメータを更新 4. 対数尤度を計算し,パラメータと対数尤度の値から収 束性を判断する.収束していなければ2へ戻る.
25.
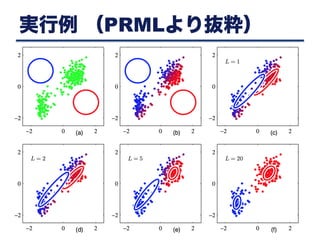
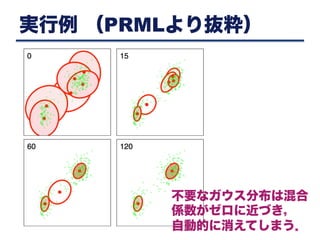
実行例 (PRMLより抜粋)
26.
Contents 1. Generative model(準備) 2. EMアルゴリズム(メイン) 1. 例)Gaussian
mixtureの最尤推定 2. EMアルゴリズムの説明 3. 自由エネルギーを使った再解釈 3. 変分ベイズ(少しだけ)
27.
説明の流れ n より一般な形のEMアルゴリズムを用いた最尤推 定の手法を説明をする n そしてそれが今求めたGaussian mixtureにお ける最尤推定のアルゴリズムと一致しているこ とをみる n ここからはθをパラメータとする生成モデルが立 てられているとして議論を進める
28.
そもそもの受難 そもそも,最尤推定量の計算が困難であっ た原因は,logが直接expにかからないこと であった 直接かけてしまえ!完全対数尤度を考える! 注)完全対数尤度を考えても閉じた形でパラメータが求まるわけではない.ただ,完全 対数尤度の最適化の方がより簡単であると仮定している.
29.
それでも z は観察できない しかし
z は観察できないので,パラメータ を特定の値に固定した事後分布で期待値を 計算する このQを最大にするθを求めることで,尤度 を大きくする 注)本当にQを大きくすることで尤度が大きくなっていることは あとで確認する
30.
EMアルゴリズム 1. 各パラメータを初期化 2. 【E
step】現在のパラメータを用いて事後分布を計算 3. 【Mステップ】Qを計算し,パラメータを更新 4. 対数尤度を計算し,パラメータと対数尤度の値から収 束性を判断する.収束していなければ2へ戻る.
31.
Qを大きくすれば尤度は増える? 【証明の準備】
32.
Qを大きくすれば尤度は増える!
33.
Gaussian mixture 再び 2通りの見方が出来る 1. 観測変数
x だけのモデル 2. 観測変数 x と 隠れ変数 z のモデル
34.
Gaussian mixture 再び 2通りの見方が出来る 1. 2.
観測変数 x と 隠れ変数 z のモデル 負担率とパラメータを交互に 最適化したアルゴリズムとEMが 等価であることをみる
35.
Gaussian mixture の復習
36.
Gaussian mixtureとEM 同時分布 完全対数尤度 Q logが直接expにかかる
37.
Gaussian mixtureとEM となるので(計算略) を最大にするパラメータは,負担率が既に固定されたパラ メータにしか依存していないことを踏まえれば,それぞれ 微分を取ることで,閉に解くことができ,前に導出した結 果と一致する. 明らかに微分しやすい
38.
Contents 1. Generative model(準備) 2. EMアルゴリズム(メイン) 1. 例)Gaussian
mixtureの最尤推定 2. EMアルゴリズムの説明 3. 自由エネルギーを使った再解釈 3. 変分ベイズ(少しだけ)
39.
自由エネルギーを用いた再解釈 n EMアルゴリズムを紹介したが,これを自 由エネルギーを使って再解釈する n これにより,EMアルゴリズムをより深く 理解できると共に,変分ベイズへの橋渡 しとなる 今日覚えて帰るべき唯一の式! 対数尤度 = F
+ KL(q || 事後分布)
40.
式の導出準備 (注) 本日二度目【準備】
41.
式の導出 (注) -Fは自由エネルギーと呼ばれる
42.
対数尤度最大化 qを任意のθに対して計算するのは大変なので,交互最適化を行う!
43.
実はEMと等価 【E step】 【M step】 この交互最適化を行うアルゴリズムはEMアルゴリズム と等価である.なぜなら, 【E
step】 【M step】 (θ固定)
44.
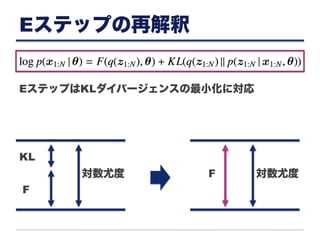
Eステップの再解釈 EステップはKLダイバージェンスの最小化に対応 対数尤度 F KL 対数尤度F
45.
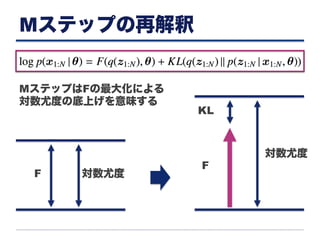
Mステップの再解釈 MステップはFの最大化による 対数尤度の底上げを意味する 対数尤度 F KL 対数尤度F
46.
下限としての解釈 KLダイバージェンスは常に非負なので,次が導かれる KLダイバージェンスが0,すなわちqが事後分布に等しく なるときに成立する. Fは対数尤度の下限
47.
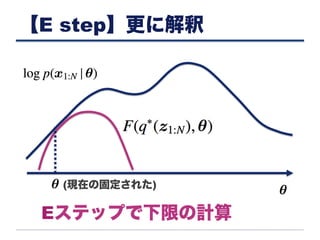
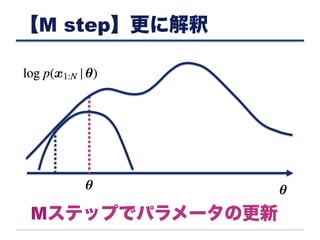
【E step】更に解釈 Eステップで下限の計算 (現在の固定された)
48.
【M step】更に解釈 Mステップでパラメータの更新
49.
変分ベイズ(少しだけ雰囲気)
50.
EMアルゴリズムの問題点 Eステップにおいて事後分布を計算している が,これが解析的にも止まらない場合はど うするのか…?
51.
自由エネルギーからの知見 Fは常に対数尤度の下界である 事後分布が計算できなくとも, よりよく事後分布を近似できればよい.
52.
平均場近似 次のように 隠れ変数の分布が独立に分解出来るとし, それぞれについて最適化することでq(z)を 近似することを考える
53.
Gaussian mixtureでの例 パラメータを全て隠れ変数とみなし,それ ぞれに事前分布をいれ,同時分布は次のよ うになる 次の独立性を仮定し,それぞれ最適化する
54.
実行例 (PRMLより抜粋) 不要なガウス分布は混合 係数がゼロに近づき, 自動的に消えてしまう.
55.
参考資料
Download


















































![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[The Elements of Statistical Learning]Chapter8: Model Inferennce and Averaging](https://cdn.slidesharecdn.com/ss_thumbnails/theelementsofstatisticallearningchapter8modelinferennceandaveraging-181109001318-thumbnail.jpg?width=640&height=640&fit=bounds)












