Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Taiji Suzuki
24,848 views
機械学習におけるオンライン確率的最適化の理論
情報処理学会連続セミナー2013
Technology
◦
Read more
72
Save
Share
Embed
Embed presentation
Download
Downloaded 297 times
1
/ 54
2
/ 54
Most read
3
/ 54
4
/ 54
5
/ 54
6
/ 54
Most read
7
/ 54
8
/ 54
9
/ 54
10
/ 54
11
/ 54
12
/ 54
13
/ 54
14
/ 54
15
/ 54
16
/ 54
17
/ 54
18
/ 54
19
/ 54
20
/ 54
Most read
21
/ 54
22
/ 54
23
/ 54
24
/ 54
25
/ 54
26
/ 54
27
/ 54
28
/ 54
29
/ 54
30
/ 54
31
/ 54
32
/ 54
33
/ 54
34
/ 54
35
/ 54
36
/ 54
37
/ 54
38
/ 54
39
/ 54
40
/ 54
41
/ 54
42
/ 54
43
/ 54
44
/ 54
45
/ 54
46
/ 54
47
/ 54
48
/ 54
49
/ 54
50
/ 54
51
/ 54
52
/ 54
53
/ 54
54
/ 54
More Related Content
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
PDF
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
PDF
PRML輪読#1
by
matsuolab
PPTX
劣モジュラ最適化と機械学習1章
by
Hakky St
PDF
Active Learning 入門
by
Shuyo Nakatani
数学で解き明かす深層学習の原理
by
Taiji Suzuki
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
PRML輪読#1
by
matsuolab
劣モジュラ最適化と機械学習1章
by
Hakky St
Active Learning 入門
by
Shuyo Nakatani
What's hot
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PDF
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PDF
最適化計算の概要まとめ
by
Yuichiro MInato
PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半
by
Ohsawa Goodfellow
PDF
PRML上巻勉強会 at 東京大学 資料 第1章後半
by
Ohsawa Goodfellow
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
“機械学習の説明”の信頼性
by
Satoshi Hara
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
PDF
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
XGBoostからNGBoostまで
by
Tomoki Yoshida
PDF
PRML輪読#2
by
matsuolab
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PDF
機械学習 入門
by
Hayato Maki
PPTX
Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について
by
Yusuke Nakata
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
最適輸送の計算アルゴリズムの研究動向
by
ohken
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PRML第6章「カーネル法」
by
Keisuke Sugawara
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
最適化計算の概要まとめ
by
Yuichiro MInato
PRML上巻勉強会 at 東京大学 資料 第1章前半
by
Ohsawa Goodfellow
PRML上巻勉強会 at 東京大学 資料 第1章後半
by
Ohsawa Goodfellow
深層学習の数理
by
Taiji Suzuki
“機械学習の説明”の信頼性
by
Satoshi Hara
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
階層ベイズとWAIC
by
Hiroshi Shimizu
XGBoostからNGBoostまで
by
Tomoki Yoshida
PRML輪読#2
by
matsuolab
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
機械学習 入門
by
Hayato Maki
Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について
by
Yusuke Nakata
Similar to 機械学習におけるオンライン確率的最適化の理論
PDF
[読会]Long tail learning via logit adjustment
by
shima o
PDF
オンライン学習 : Online learning
by
Daiki Tanaka
PDF
「統計的学習理論」第1章
by
Kota Matsui
PDF
クラシックな機械学習の入門 7. オンライン学習
by
Hiroshi Nakagawa
PDF
公平性を保証したAI/機械学習 アルゴリズムの最新理論
by
Kazuto Fukuchi
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PPTX
PRML読み会第一章
by
Takushi Miki
PPTX
Machine Learning Seminar (1)
by
Tomoya Nakayama
PDF
FOBOS
by
Hidekazu Oiwa
PPTX
数理最適化と機械学習の 融合アプローチ -分類と新しい枠組み-(改訂版)
by
MIKIOKUBO3
PDF
オンライン凸最適化と線形識別モデル学習の最前線_IBIS2011
by
Preferred Networks
PDF
20170422 数学カフェ Part2
by
Kenta Oono
PDF
Prml1.2.5~1.2.6
by
Tomoyuki Hioki
PPTX
PRML1.2
by
Tomoyuki Hioki
PPTX
頻度論とベイズ論と誤差最小化について
by
Shohei Miyashita
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
NLPforml5
by
Hidekazu Oiwa
PPTX
海鳥の経路予測のための逆強化学習
by
Tsubasa Hirakawa
PPTX
数理最適化と機械学習の 融合アプローチ -分類と新しい枠組み-
by
MIKIOKUBO3
[読会]Long tail learning via logit adjustment
by
shima o
オンライン学習 : Online learning
by
Daiki Tanaka
「統計的学習理論」第1章
by
Kota Matsui
クラシックな機械学習の入門 7. オンライン学習
by
Hiroshi Nakagawa
公平性を保証したAI/機械学習 アルゴリズムの最新理論
by
Kazuto Fukuchi
機械学習の理論と実践
by
Preferred Networks
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PRML読み会第一章
by
Takushi Miki
Machine Learning Seminar (1)
by
Tomoya Nakayama
FOBOS
by
Hidekazu Oiwa
数理最適化と機械学習の 融合アプローチ -分類と新しい枠組み-(改訂版)
by
MIKIOKUBO3
オンライン凸最適化と線形識別モデル学習の最前線_IBIS2011
by
Preferred Networks
20170422 数学カフェ Part2
by
Kenta Oono
Prml1.2.5~1.2.6
by
Tomoyuki Hioki
PRML1.2
by
Tomoyuki Hioki
頻度論とベイズ論と誤差最小化について
by
Shohei Miyashita
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
NLPforml5
by
Hidekazu Oiwa
海鳥の経路予測のための逆強化学習
by
Tsubasa Hirakawa
数理最適化と機械学習の 融合アプローチ -分類と新しい枠組み-
by
MIKIOKUBO3
More from Taiji Suzuki
PPTX
[ICLR2021 (spotlight)] Benefit of deep learning with non-convex noisy gradien...
by
Taiji Suzuki
PDF
[NeurIPS2020 (spotlight)] Generalization bound of globally optimal non convex...
by
Taiji Suzuki
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PPTX
Iclr2020: Compression based bound for non-compressed network: unified general...
by
Taiji Suzuki
PDF
はじめての機械学習
by
Taiji Suzuki
PDF
Minimax optimal alternating minimization \\ for kernel nonparametric tensor l...
by
Taiji Suzuki
PDF
Ibis2016
by
Taiji Suzuki
PDF
Sparse estimation tutorial 2014
by
Taiji Suzuki
PDF
Stochastic Alternating Direction Method of Multipliers
by
Taiji Suzuki
PDF
PAC-Bayesian Bound for Gaussian Process Regression and Multiple Kernel Additi...
by
Taiji Suzuki
PPT
Jokyokai
by
Taiji Suzuki
PDF
Jokyokai2
by
Taiji Suzuki
[ICLR2021 (spotlight)] Benefit of deep learning with non-convex noisy gradien...
by
Taiji Suzuki
[NeurIPS2020 (spotlight)] Generalization bound of globally optimal non convex...
by
Taiji Suzuki
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
Iclr2020: Compression based bound for non-compressed network: unified general...
by
Taiji Suzuki
はじめての機械学習
by
Taiji Suzuki
Minimax optimal alternating minimization \\ for kernel nonparametric tensor l...
by
Taiji Suzuki
Ibis2016
by
Taiji Suzuki
Sparse estimation tutorial 2014
by
Taiji Suzuki
Stochastic Alternating Direction Method of Multipliers
by
Taiji Suzuki
PAC-Bayesian Bound for Gaussian Process Regression and Multiple Kernel Additi...
by
Taiji Suzuki
Jokyokai
by
Taiji Suzuki
Jokyokai2
by
Taiji Suzuki
機械学習におけるオンライン確率的最適化の理論
1.
機械学習における オンライン確率的最適化の理論 鈴木 大慈 東京大学 情報理工学系研究科 数理情報学専攻 2013/6/26 1
2.
本発表の狙い オンライン確率的最適化の理論 いろいろな手法 簡単な手法を軸にして基本となる考え方を紹介 2
3.
発表の構成 • 最適化問題としての定式化 • オンライン確率的最適化 –
確率的勾配降下法 – 正則化学習におけるオンライン確率的最適化 – 構造的正則化学習におけるオンライン確率的最適化 • バッチデータに対する確率的最適化 3
4.
教師有り学習の 最適化問題としての定式化 4
5.
5 経験リスク関数 正則化項付きリスク関数 : t個目のサンプルに対するロス : 過学習を避けるためのペナルティ項 機械学習における最適化問題 (“誤り”
へのペナルティ)
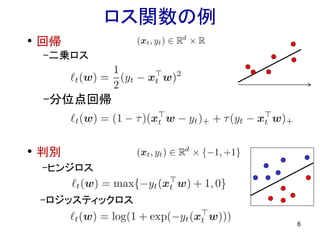
6.
6 • 回帰 -二乗ロス -分位点回帰 ロス関数の例 • 判別 -ヒンジロス -ロジッスティックロス
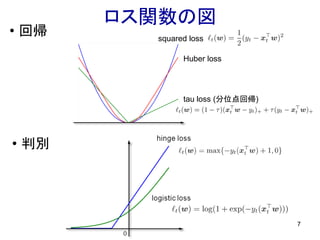
7.
7 • 回帰 ロス関数の図 • 判別 squared
loss tau loss (分位点回帰) Huber loss
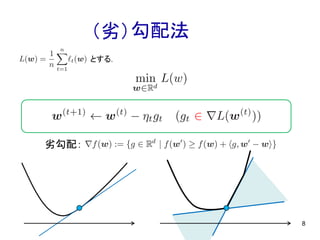
8.
勾配法 8 とする. (劣) 劣勾配:
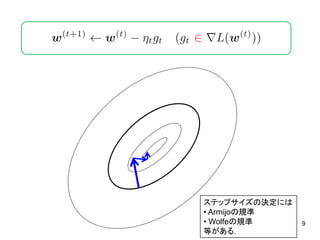
9.
9 ステップサイズの決定には • Armijoの規準 • Wolfeの規準 等がある.
10.
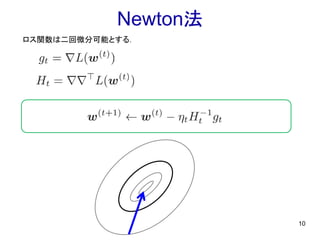
Newton法 10 ロス関数は二回微分可能とする.
11.
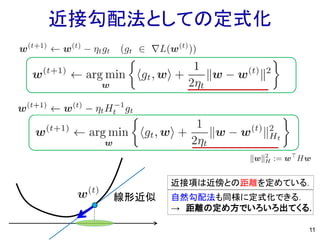
近接勾配法としての定式化 11 線形近似 近接項は近傍との距離を定めている. 自然勾配法も同様に定式化できる. → 距離の定め方でいろいろ出てくる.
12.
Mirror Descent 12 さらに一般化 (近接勾配法) Bregman-ダイバージェンス: 例:Exponentiated Gradient
[Kivinen&Warmuth,97] 有限確率分布上での最適化:KL-ダイバージェンスを近接項に用いる 一般化
13.
• これからの議論は簡単のため近接項として を用いる. • 近接勾配法としての見方は確率的最適化と の関係を明確にする(後述). •
Mirror descentのように距離を変えても以下 と同様の議論は成り立つ. 13
14.
収束レート • 最急降下法 – 滑らかな凸関数: –
強凸関数: 一次収束 • Newton法 – 二次収束 14
15.
正則化項付きリスク最小化 15c.f. FOBOS [Duchi&Singer,09],
FISTA [Beck, Teboulle 08] この更新式はオンライン学習においても重要
16.
発表の構成 • 最適化問題としての定式化 • オンライン確率的最適化 –
確率的勾配降下法 – 正則化学習におけるオンライン確率的最適化 – 構造的正則化学習におけるオンライン確率的最適化 • バッチデータに対する確率的最適化 16
17.
オンライン確率的最適化 17
18.
問題点 18 • サンプル数nが巨大な場合,関数値の評価,勾配の計算,Hessianの計算 に多大な時間がかかる. • 次から次にやってくるデータは従来の方法では処理できない(nは固定). •
巨大なデータはメモリに収められない. 確率的最適化(オンライン学習) • 機械学習で大事なのは汎化誤差 • 高度な最適化手法による速い収束も経験誤差を小さくするのみ → 最適化の精度が推定誤差に埋もれる → 少しくらいサボってもよい [Bottou&Bousquet,08]
19.
確率的勾配降下法 19 (Stochastic Gradient Descent,
SGD) ではない. •t個目のサンプルのみを用いて更新ができる. •ステップサイズは が普通(後述). •バッチの最適化と比べてステップサイズは重要. Polyak-Ruppert平均化:
20.
収束レート解析:用語の定義 • ロス関数の滑らかさ 20 • 目的関数の強凸性 ある正の定数
が存在して,
21.
ステップサイズ でもPolyak-Ruppert平均化すれ ば強凸性に適応して収束が速くなる.[Bach&Moulines,11] 収束レート • 一般の凸ロス関数 21 •
期待リスクが滑らかな強凸関数 :期待リスク(汎化誤差) ※本当はもっと細かい条件が必要だが,ここでは省略 これらの収束レートはミニマックス最適[Nemirovski&Yudin,83][Agarwal+etal,10]
22.
• 滑らかでない一般の強凸リスクの収束レート 22 強凸期待リスクに対する収束レートの理論はまだまだ発展途上 例:ステップサイズ は滑らかでない場合でも
にして良いか? • Polyak-Ruppert 平均化 • α-suffix平均化 • 多項式減衰平均化 [Rakhlin et al. (2011), Shamir&Zhang (2012)] [Lacoste-Julien et al. (2012), Shamir&Zhang (2012)] ステップサイズ:
23.
バッチ最適化との比較 23 なめらかな強凸関数において比較する. :minimax最適レート だけ得をする →サンプル数が巨大な時は確率的最適化が有用 [Nemirovski&Yudin,83][Agarwal+etal,10] (最悪な期待リスク) :経験リスクと期待リスクの差 [Bottou,10]
24.
正則化学習における オンライン確率的最適化 24
25.
正則化学習での確率的勾配法 25 を小さくしたい. c.f. FOBOS [Duchi&Singer,09] 例:L1正則化
(高次元モデルにおけるスパース学習) Soft threshold 更新途中でもスパース!
26.
26 : proximal operation 先の更新式は次のように書ける: proximal
operationが簡単に計算できる正則化関数の例. ① グループ正則化 ② トレースノルム最小化( ) とSVDされている時, 低ランク性 グループスパーシティ
27.
ミニバッチ法 27 各反復での勾配計算を一サンプルだけでなく, 小規模のまとまったサンプルを用いて計算.
28.
Regularized Dual Averaging 28 RDA:
確率的最適化(オンライン最適化)の別の方法 [Xiao,09; Nesterov,09] :勾配の平均を用いる FOBOSよりも途中の解がスパースになりやすい
29.
関連手法 29 Composite Objective Mirror
Descent Adaptive Subgradient Methods [Duchi+etal,10] KL-divergenceを用いればexponentiated gradient descent あまり発火しない特徴量を強調する. [Duchi+etal,10] (FOBOS型) (RDA型)
30.
構造的正則化学習における オンライン確率的最適化 30
31.
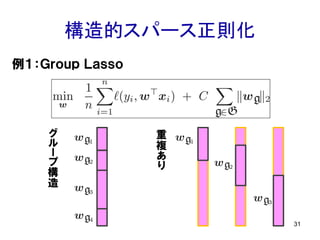
構造的スパース正則化 31 例1:Group Lasso グ ル ー プ 構 造 重 複 あ り
32.
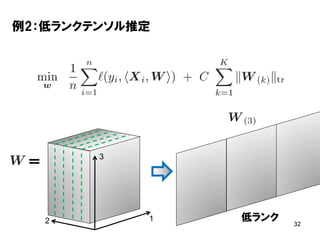
32 例2:低ランクテンソル推定 = 12 3 低ランク
33.
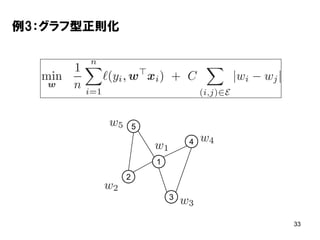
33 例3:グラフ型正則化 1 2 3 4 5
34.
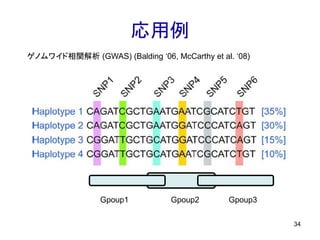
応用例 34 ゲノムワイド相関解析 (GWAS) (Balding
‘06, McCarthy et al. ‘08) Gpoup1 Gpoup2 Gpoup3
35.
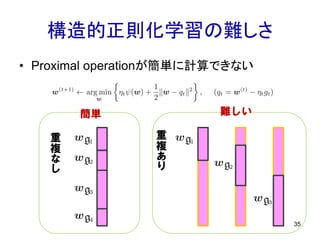
構造的正則化学習の難しさ • Proximal operationが簡単に計算できない 35 重 複 あ り 重 複 な し 簡単
難しい
36.
•各正則化関数に応じた賢い方法で解く [Yuan et
al. 2011] •変数を増やして問題を簡単にする (汎用的) を満たし が計算しやすい • 重複ありグループ正則化 36 重 複 あ り グループ間に変数の絡み • 解決策 を利用する. idea:
37.
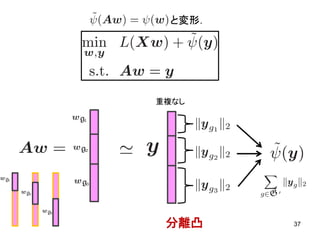
37分離凸 と変形. 重複なし
38.
• FOBOS型ADMM 38 • RDA型ADMM 線形近似
スムージング 確率的ADMM 交互方向乗数法 + 確率的最適化 [Suzuki, ICML2013] [Ouyang+etal, ICML2013]
39.
確率的ADMM • FOBOS型ADMM 39 • RDA型ADMM 交互方向乗数法
+ 確率的最適化 実装が簡単! [Suzuki, ICML2013] [Ouyang+etal, ICML2013]
40.
収束レート 40 条件 データ: • 一般の凸ロス関数 • 強凸正則化関数 •データはi.i.d.系列 •ロスと正則化項はLipschitz連続 •wのドメインは有界
41.
数値実験:確率的ADMM 41 人工データ 実データ(Adult, a9a @LIVSVM
data sets) 1,024次元 512サンプル 重複ありグループ正則化 15,252次元 32,561サンプル 重複ありグループ正則化+ L1正則化 最 適 値 と の 差 テ ス ト デ ー タ で の 判 別 誤 差 提案手法 [Suzuki, ICML2013]
42.
発表の構成 • 最適化問題としての定式化 • オンライン確率的最適化 –
確率的勾配降下法 – 正則化学習におけるオンライン確率的最適化 – 構造的正則化学習におけるオンライン確率的最適化 • バッチデータに対する確率的最適化 42
43.
43 バッチデータに対する 確率的最適化
44.
• オンライン最適化: サンプルを一回しか見ないことを想定 • バッチの設定: 44 サンプルを何度も利用してよいなら もっと速い収束が望めるのでは? →
Yes - Stochastic Average Gradient (SAG): Le Roux, Schmidt, Bach (NIPS 2012) - Stochastic Dual Coordinate Ascent (SDCA): Shalev-Shwartz, Zhang (NIPS OPT-WS 2012 ) 線形収束 (目的関数が指数的に減少)
45.
Stochastic Average Gradient (SAG) 45 [Le
Roux, Schmidt, Bach (NIPS 2012)] 各ステップにおいて をランダムに選択し, ロス関数が滑らか,かつ目的関数Lが強凸の時, とすると 指数的収束
46.
46 [Le Roux, Schmidt,
Bach,12] データ1 データ2 データ3 経験リスク 期待リスク 判別誤差 緑色がSAG
47.
SAGの性質 • 指数的収束→サンプルを複数回観測すると確率的勾配法よりも 高い精度を得る. • 一回の更新にかかる計算時間は確率的勾配法と同じオーダー. •
バッチ最適化と確率的勾配法の中間的位置づけ. • 問題点:全てのサンプルでの勾配の値を記憶しておかなくてはい けない. →巨大データではメモリが足りなくなる. 次に紹介するSDCAではメモリの問題がない. 47
48.
正則化学習の双対問題 48 Fenchel双対定理 Fenchel双対定理:例えばRockafeller, Convex Analysis
(1970) のCorollary 31.2.1 双対問題 主問題 L*らはLをLegendre変換したもの(次ページ) SDCAの定式化
49.
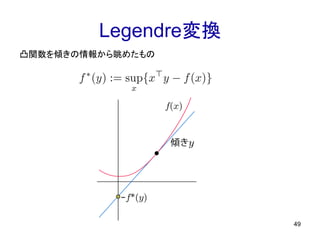
Legendre変換 49 凸関数を傾きの情報から眺めたもの
50.
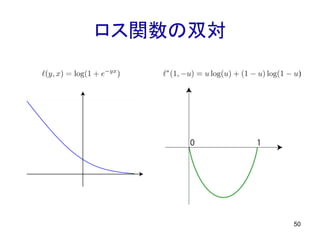
ロス関数の双対 50
51.
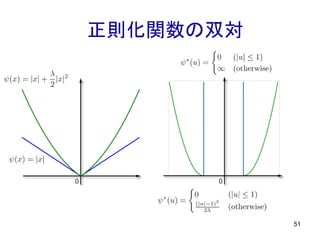
51 正則化関数の双対
52.
Stochastic Dual Coordinate
Ascent 52 1. をランダムに選択 2.次元 方向に最適化 3. 上の1,2を繰り返す. が強凸で が滑らかな時, 双対ギャップの期待値 [Shalev-Shwartz&Zhang,2012] 指数的収束 関連手法:Lacoste-Julien et al., 2012 (Stochastic block-coordinate Frank-Wolfe法) (一次元最適化) ※ 正則化関数(の双対関数)を線形近似することも可能.
53.
53 指数的収束 [Shalev-Shwartz&Zhang,2012]
54.
まとめ • オンライン確率的最適化 – 大サンプル学習問題においてサンプルを一つ見るごとに 逐次的に更新する手法 –
経験誤差最小化は厳密に解く必要はない • バッチデータに対する確率的最適化 – サンプルを複数回利用可能 → 逐次的更新で指数オーダの収束 54 一般のロス関数: (滑らかな)強凸リスク関数:収束レート
Download







![Mirror Descent
12
さらに一般化
(近接勾配法)
Bregman-ダイバージェンス:
例:Exponentiated Gradient [Kivinen&Warmuth,97]
有限確率分布上での最適化:KL-ダイバージェンスを近接項に用いる
一般化](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-12-320.jpg)


![正則化項付きリスク最小化
15c.f. FOBOS [Duchi&Singer,09], FISTA [Beck, Teboulle 08]
この更新式はオンライン学習においても重要](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-15-320.jpg)


![問題点
18
• サンプル数nが巨大な場合,関数値の評価,勾配の計算,Hessianの計算
に多大な時間がかかる.
• 次から次にやってくるデータは従来の方法では処理できない(nは固定).
• 巨大なデータはメモリに収められない.
確率的最適化(オンライン学習)
• 機械学習で大事なのは汎化誤差
• 高度な最適化手法による速い収束も経験誤差を小さくするのみ
→ 最適化の精度が推定誤差に埋もれる
→ 少しくらいサボってもよい
[Bottou&Bousquet,08]](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-18-320.jpg)


![ステップサイズ でもPolyak-Ruppert平均化すれ
ば強凸性に適応して収束が速くなる.[Bach&Moulines,11]
収束レート
• 一般の凸ロス関数
21
• 期待リスクが滑らかな強凸関数
:期待リスク(汎化誤差)
※本当はもっと細かい条件が必要だが,ここでは省略
これらの収束レートはミニマックス最適[Nemirovski&Yudin,83][Agarwal+etal,10]](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-21-320.jpg)
![• 滑らかでない一般の強凸リスクの収束レート
22
強凸期待リスクに対する収束レートの理論はまだまだ発展途上
例:ステップサイズ は滑らかでない場合でも にして良いか?
• Polyak-Ruppert 平均化
• α-suffix平均化
• 多項式減衰平均化
[Rakhlin et al. (2011), Shamir&Zhang (2012)]
[Lacoste-Julien et al. (2012), Shamir&Zhang (2012)]
ステップサイズ:](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-22-320.jpg)
![バッチ最適化との比較
23
なめらかな強凸関数において比較する.
:minimax最適レート
だけ得をする
→サンプル数が巨大な時は確率的最適化が有用
[Nemirovski&Yudin,83][Agarwal+etal,10]
(最悪な期待リスク)
:経験リスクと期待リスクの差
[Bottou,10]](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-23-320.jpg)

![正則化学習での確率的勾配法
25
を小さくしたい.
c.f. FOBOS [Duchi&Singer,09]
例:L1正則化 (高次元モデルにおけるスパース学習)
Soft threshold
更新途中でもスパース!](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-25-320.jpg)


![Regularized Dual Averaging
28
RDA: 確率的最適化(オンライン最適化)の別の方法 [Xiao,09; Nesterov,09]
:勾配の平均を用いる
FOBOSよりも途中の解がスパースになりやすい](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-28-320.jpg)
![関連手法
29
Composite Objective Mirror Descent
Adaptive Subgradient Methods
[Duchi+etal,10]
KL-divergenceを用いればexponentiated gradient descent
あまり発火しない特徴量を強調する.
[Duchi+etal,10]
(FOBOS型)
(RDA型)](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-29-320.jpg)

![•各正則化関数に応じた賢い方法で解く [Yuan et al. 2011]
•変数を増やして問題を簡単にする (汎用的)
を満たし が計算しやすい
• 重複ありグループ正則化
36
重
複
あ
り
グループ間に変数の絡み
• 解決策
を利用する.
idea:](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-36-320.jpg)
![• FOBOS型ADMM
38
• RDA型ADMM
線形近似 スムージング
確率的ADMM
交互方向乗数法 + 確率的最適化
[Suzuki, ICML2013]
[Ouyang+etal, ICML2013]](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-38-320.jpg)
![確率的ADMM
• FOBOS型ADMM
39
• RDA型ADMM
交互方向乗数法 + 確率的最適化
実装が簡単!
[Suzuki, ICML2013]
[Ouyang+etal, ICML2013]](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-39-320.jpg)

![数値実験:確率的ADMM
41
人工データ 実データ(Adult, a9a
@LIVSVM data sets)
1,024次元
512サンプル
重複ありグループ正則化
15,252次元
32,561サンプル
重複ありグループ正則化+ L1正則化
最
適
値
と
の
差
テ
ス
ト
デ
ー
タ
で
の
判
別
誤
差
提案手法
[Suzuki, ICML2013]](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-41-320.jpg)



![Stochastic Average Gradient
(SAG)
45
[Le Roux, Schmidt, Bach (NIPS 2012)]
各ステップにおいて をランダムに選択し,
ロス関数が滑らか,かつ目的関数Lが強凸の時, とすると
指数的収束](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-45-320.jpg)
![46
[Le Roux, Schmidt, Bach,12]
データ1
データ2
データ3
経験リスク 期待リスク 判別誤差
緑色がSAG](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-46-320.jpg)


![Stochastic Dual Coordinate Ascent
52
1. をランダムに選択
2.次元 方向に最適化
3. 上の1,2を繰り返す.
が強凸で が滑らかな時,
双対ギャップの期待値
[Shalev-Shwartz&Zhang,2012]
指数的収束
関連手法:Lacoste-Julien et al., 2012 (Stochastic block-coordinate Frank-Wolfe法)
(一次元最適化)
※ 正則化関数(の双対関数)を線形近似することも可能.](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-52-320.jpg)
![53
指数的収束
[Shalev-Shwartz&Zhang,2012]](https://image.slidesharecdn.com/bigdata2013-130703091104-phpapp02/85/slide-53-320.jpg)















![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)







![[読会]Long tail learning via logit adjustment](https://cdn.slidesharecdn.com/ss_thumbnails/long-taillearningvialogitadjustment-211229095016-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[ICLR2021 (spotlight)] Benefit of deep learning with non-convex noisy gradien...](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2021-210331133549-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NeurIPS2020 (spotlight)] Generalization bound of globally optimal non convex...](https://cdn.slidesharecdn.com/ss_thumbnails/neurips2020spotlight-210331133014-thumbnail.jpg?width=640&height=640&fit=bounds)









