Downloaded 210 times







![Training models
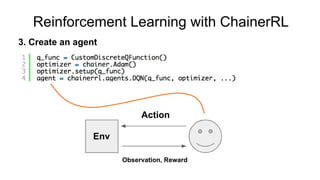
model = LeNet5()
model = L.Classifier(model)
# Dataset is a list! ([] to access, having __len__)
dataset = [(x1, t1), (x2, t2), ...]
# iterator to return a mini-batch retrieved from dataset
it = iterators.SerialIterator(dataset, batchsize=32)
# Optimization methods (you can easily try various methods by changing SGD to
# MomentumSGD, Adam, RMSprop, AdaGrad, etc.)
opt = optimizers.SGD(lr=0.01)
opt.setup(model)
updater = training.StandardUpdater(it, opt, device=0) # device=-1 if you use CPU
trainer = training.Trainer(updater, stop_trigger=(100, 'epoch'))
trainer.run()
For more details, refer to official examples: https://github.com/pfnet/chainer/tree/master/examples](https://image.slidesharecdn.com/extintroductiontochainer-170728005749/85/Introduction-to-Chainer-10-320.jpg)




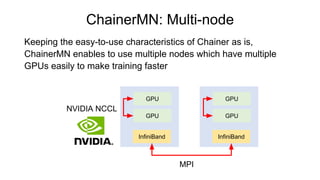
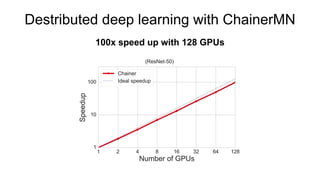
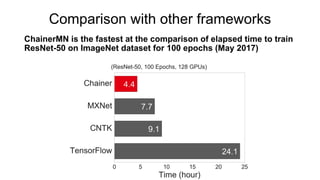
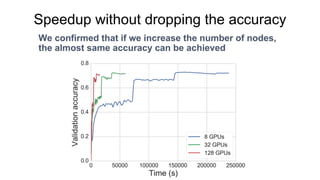
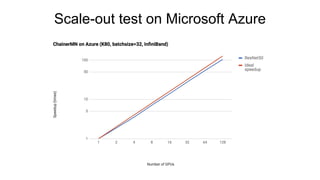

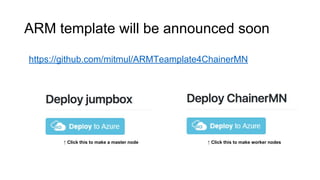
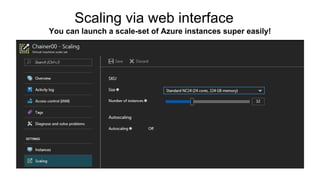


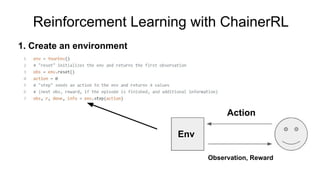






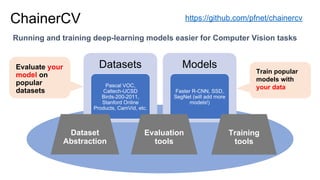



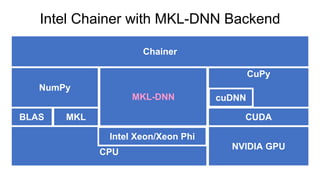




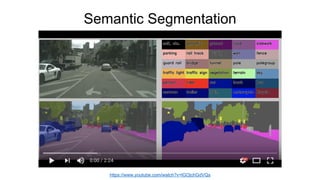

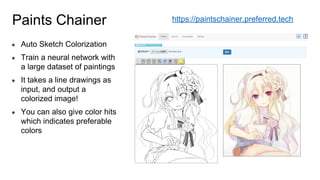









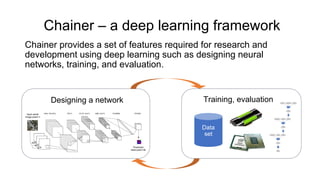
Chainer is a flexible deep learning framework that supports a variety of neural network designs and GPU acceleration. With features like define-by-run for dynamic computation graphs, various network layers, and multiple optimizers, Chainer facilitates intuitive model creation and debugging. It also supports tools for distributed learning and computer vision, making it suitable for a wide array of deep learning applications.















![[251] implementing deep learning using cu dnn](https://cdn.slidesharecdn.com/ss_thumbnails/215implementingdeeplearningusingcudnn-150915052020-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Update] PyTorch Tutorial for NTU Machine Learing Course 2017](https://cdn.slidesharecdn.com/ss_thumbnails/pytorchtutorial-2017-1103-171103060015-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DLHacks]Introduction to ChainerCV](https://cdn.slidesharecdn.com/ss_thumbnails/ltchainercv-180619053220-thumbnail.jpg?width=640&height=640&fit=bounds)









![Deep learning in python ommunic [CNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythoncnn-251207084743-a5c807e1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[5 minutes LT] Brief Introduction to Recent Image Recognition Methods and Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/fashion-tech-2017-06-06-170626055616-thumbnail.jpg?width=640&height=640&fit=bounds)




























