Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Saya Katafuchi
14,061 views
ディープボルツマンマシン入門
ゼミで発表した資料のまとめ ディープラーニングの基本的な部分の説明です
Related topics:
Deep Learning
•
Read more
38
Save
Share
Embed
Embed presentation
Download
Downloaded 198 times
1
/ 76
2
/ 76
3
/ 76
4
/ 76
5
/ 76
6
/ 76
7
/ 76
8
/ 76
9
/ 76
10
/ 76
11
/ 76
12
/ 76
13
/ 76
14
/ 76
15
/ 76
16
/ 76
17
/ 76
18
/ 76
19
/ 76
20
/ 76
21
/ 76
22
/ 76
23
/ 76
24
/ 76
25
/ 76
26
/ 76
27
/ 76
28
/ 76
29
/ 76
30
/ 76
31
/ 76
32
/ 76
33
/ 76
34
/ 76
35
/ 76
36
/ 76
37
/ 76
38
/ 76
39
/ 76
40
/ 76
41
/ 76
42
/ 76
43
/ 76
44
/ 76
45
/ 76
46
/ 76
47
/ 76
48
/ 76
49
/ 76
50
/ 76
51
/ 76
52
/ 76
53
/ 76
54
/ 76
55
/ 76
56
/ 76
57
/ 76
58
/ 76
59
/ 76
60
/ 76
61
/ 76
62
/ 76
63
/ 76
64
/ 76
65
/ 76
66
/ 76
67
/ 76
68
/ 76
69
/ 76
70
/ 76
71
/ 76
72
/ 76
73
/ 76
74
/ 76
75
/ 76
76
/ 76
More Related Content
PDF
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料)
by
Takuma Yagi
PPTX
RBMを応用した事前学習とDNN学習
by
Masayuki Tanaka
PDF
スパースモデリング
by
harapon
PDF
Fisher線形判別分析とFisher Weight Maps
by
Takao Yamanaka
PDF
Chapter 8 ボルツマンマシン - 深層学習本読み会
by
Taikai Takeda
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
PRML輪読#11
by
matsuolab
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料)
by
Takuma Yagi
RBMを応用した事前学習とDNN学習
by
Masayuki Tanaka
スパースモデリング
by
harapon
Fisher線形判別分析とFisher Weight Maps
by
Takao Yamanaka
Chapter 8 ボルツマンマシン - 深層学習本読み会
by
Taikai Takeda
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PRML輪読#11
by
matsuolab
変分ベイズ法の説明
by
Haruka Ozaki
What's hot
PPTX
PRML読み会第一章
by
Takushi Miki
PPTX
マルコフ連鎖モンテカルロ法
by
Masafumi Enomoto
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PDF
深層学習 勉強会第5回 ボルツマンマシン
by
Yuta Sugii
PDF
「統計的学習理論」第1章
by
Kota Matsui
PDF
制限ボルツマンマシン入門
by
佑馬 斎藤
PDF
Prml4.4 ラプラス近似~ベイズロジスティック回帰
by
Yuki Matsubara
PPTX
ベイズ深層学習5章 ニューラルネットワークのベイズ推論 Bayesian deep learning
by
ssuserca2822
PDF
強化学習その2
by
nishio
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
pymcとpystanでベイズ推定してみた話
by
Classi.corp
PDF
基礎からのベイズ統計学第5章
by
hiro5585
PDF
[Dl輪読会]introduction of reinforcement learning
by
Deep Learning JP
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
PRML Chapter 14
by
Masahito Ohue
PPTX
劣モジュラ最適化と機械学習1章
by
Hakky St
PDF
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
by
Kenichi Hironaka
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PDF
パターン認識と機械学習 §8.3.4 有向グラフとの関係
by
Prunus 1350
PPTX
ノンパラメトリックベイズを用いた逆強化学習
by
Shota Ishikawa
PRML読み会第一章
by
Takushi Miki
マルコフ連鎖モンテカルロ法
by
Masafumi Enomoto
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
深層学習 勉強会第5回 ボルツマンマシン
by
Yuta Sugii
「統計的学習理論」第1章
by
Kota Matsui
制限ボルツマンマシン入門
by
佑馬 斎藤
Prml4.4 ラプラス近似~ベイズロジスティック回帰
by
Yuki Matsubara
ベイズ深層学習5章 ニューラルネットワークのベイズ推論 Bayesian deep learning
by
ssuserca2822
強化学習その2
by
nishio
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
pymcとpystanでベイズ推定してみた話
by
Classi.corp
基礎からのベイズ統計学第5章
by
hiro5585
[Dl輪読会]introduction of reinforcement learning
by
Deep Learning JP
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PRML Chapter 14
by
Masahito Ohue
劣モジュラ最適化と機械学習1章
by
Hakky St
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
by
Kenichi Hironaka
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
パターン認識と機械学習 §8.3.4 有向グラフとの関係
by
Prunus 1350
ノンパラメトリックベイズを用いた逆強化学習
by
Shota Ishikawa
Viewers also liked
PPTX
ディープボルツマンマシン入門〜後半〜
by
sakaizawa
PDF
DL勉強会 01ディープボルツマンマシン
by
marujirou
PDF
Semi-Supervised Classification with Graph Convolutional Networks @ICLR2017読み会
by
Eiji Sekiya
PDF
言葉のもつ広がりを、モデルの学習に活かそう -one-hot to distribution in language modeling-
by
Takahiro Kubo
PPTX
医療データ解析界隈から見たICLR2017
by
RIKEN, Medical Sciences Innovation Hub Program (MIH)
PDF
ICLR読み会 奥村純 20170617
by
Jun Okumura
PDF
[ICLR2017読み会 @ DeNA] ICLR2017紹介
by
Takeru Miyato
PDF
ICLR2017読み会 Data Noising as Smoothing in Neural Network Language Models @Dena
by
Takanori Nakai
PDF
170614 iclr reading-public
by
Katsuhiko Ishiguro
PDF
Q prop
by
Reiji Hatsugai
ディープボルツマンマシン入門〜後半〜
by
sakaizawa
DL勉強会 01ディープボルツマンマシン
by
marujirou
Semi-Supervised Classification with Graph Convolutional Networks @ICLR2017読み会
by
Eiji Sekiya
言葉のもつ広がりを、モデルの学習に活かそう -one-hot to distribution in language modeling-
by
Takahiro Kubo
医療データ解析界隈から見たICLR2017
by
RIKEN, Medical Sciences Innovation Hub Program (MIH)
ICLR読み会 奥村純 20170617
by
Jun Okumura
[ICLR2017読み会 @ DeNA] ICLR2017紹介
by
Takeru Miyato
ICLR2017読み会 Data Noising as Smoothing in Neural Network Language Models @Dena
by
Takanori Nakai
170614 iclr reading-public
by
Katsuhiko Ishiguro
Q prop
by
Reiji Hatsugai
Similar to ディープボルツマンマシン入門
PDF
深層学習(講談社)のまとめ 第8章
by
okku apot
PPTX
Statistical machine learning
by
ilove2dgirl
PPTX
Deepboltzmannmachine
by
ilove2dgirl
PDF
社内機械学習勉強会 #5
by
shingo suzuki
PDF
確率的深層学習における中間層の改良と高性能学習法の提案
by
__106__
PDF
深層学習 第6章
by
KCS Keio Computer Society
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PDF
PATTERN RECOGNITION AND MACHINE LEARNING (1.1)
by
Yuma Yoshimoto
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
Implement for Deep Learning of RBM Network in C.
by
Masato Nakai
ODP
続わかりやすいパターン認識8章
by
Akiyoshi Hara
PDF
クラシックな機械学習の入門 4. 学習データと予測性能
by
Hiroshi Nakagawa
PDF
クラシックな機械学習入門 1 導入
by
Hiroshi Nakagawa
PPTX
DQN
by
hiroki yamaoka
PDF
Deeplearning4.4 takmin
by
Takuya Minagawa
PDF
Deep Learning を実装する
by
Shuhei Iitsuka
PDF
Oshasta em
by
Naotaka Yamada
PDF
Deep learning入門
by
magoroku Yamamoto
PDF
How to study stat
by
Ak Ok
深層学習(講談社)のまとめ 第8章
by
okku apot
Statistical machine learning
by
ilove2dgirl
Deepboltzmannmachine
by
ilove2dgirl
社内機械学習勉強会 #5
by
shingo suzuki
確率的深層学習における中間層の改良と高性能学習法の提案
by
__106__
深層学習 第6章
by
KCS Keio Computer Society
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
20170422 数学カフェ Part1
by
Kenta Oono
PATTERN RECOGNITION AND MACHINE LEARNING (1.1)
by
Yuma Yoshimoto
深層学習の数理
by
Taiji Suzuki
Implement for Deep Learning of RBM Network in C.
by
Masato Nakai
続わかりやすいパターン認識8章
by
Akiyoshi Hara
クラシックな機械学習の入門 4. 学習データと予測性能
by
Hiroshi Nakagawa
クラシックな機械学習入門 1 導入
by
Hiroshi Nakagawa
DQN
by
hiroki yamaoka
Deeplearning4.4 takmin
by
Takuya Minagawa
Deep Learning を実装する
by
Shuhei Iitsuka
Oshasta em
by
Naotaka Yamada
Deep learning入門
by
magoroku Yamamoto
How to study stat
by
Ak Ok
More from Saya Katafuchi
PPTX
20190324vvvvオフ会
by
Saya Katafuchi
PDF
VJ Cardboard ブイジェーカードボード
by
Saya Katafuchi
PDF
Handson opencv! 画像処理ライブラリを使って面白いプログラムを作ろう!その2
by
Saya Katafuchi
PDF
Hands On OpenCV! 画像処理ライブラリを使って面白いプログラムを作ろう!
by
Saya Katafuchi
PDF
輪講用資料「Deep Convolutional Network Cascade for Facial Point Detection」
by
Saya Katafuchi
PDF
輪講用資料「Mitosis Detection in Breast Cancer Histology Images with Deep Neural Ne...
by
Saya Katafuchi
PDF
第一回カオス時系列解析
by
Saya Katafuchi
PDF
卒論執筆のために3年生からやる5つのこと
by
Saya Katafuchi
PDF
第3回長崎デジタルコンテストLT『リバースエンジニアリング入門』
by
Saya Katafuchi
PDF
画像認識のための深層学習
by
Saya Katafuchi
PDF
20140514在校生向けUnity&AR講座
by
Saya Katafuchi
PPTX
20140508 在校生向けUnity&AR講座
by
Saya Katafuchi
PDF
201310合同ゼミ論文紹介
by
Saya Katafuchi
PDF
VirtualDJでPCDJっぽいことをやった
by
Saya Katafuchi
PDF
ヤンデレのUnityに愛されて眠れない〜りたーんず〜
by
Saya Katafuchi
PDF
Capture the flag!
by
Saya Katafuchi
PDF
Tesseract-OCR in iOS
by
Saya Katafuchi
PDF
ヤンデレのUnityに愛されて眠れない〜Unity3分クッキング〜
by
Saya Katafuchi
PDF
マルウェア解析講座そのいち〜仮想環境下では暴れないけど質問ある?〜
by
Saya Katafuchi
PDF
Reverseengineering koukai
by
Saya Katafuchi
20190324vvvvオフ会
by
Saya Katafuchi
VJ Cardboard ブイジェーカードボード
by
Saya Katafuchi
Handson opencv! 画像処理ライブラリを使って面白いプログラムを作ろう!その2
by
Saya Katafuchi
Hands On OpenCV! 画像処理ライブラリを使って面白いプログラムを作ろう!
by
Saya Katafuchi
輪講用資料「Deep Convolutional Network Cascade for Facial Point Detection」
by
Saya Katafuchi
輪講用資料「Mitosis Detection in Breast Cancer Histology Images with Deep Neural Ne...
by
Saya Katafuchi
第一回カオス時系列解析
by
Saya Katafuchi
卒論執筆のために3年生からやる5つのこと
by
Saya Katafuchi
第3回長崎デジタルコンテストLT『リバースエンジニアリング入門』
by
Saya Katafuchi
画像認識のための深層学習
by
Saya Katafuchi
20140514在校生向けUnity&AR講座
by
Saya Katafuchi
20140508 在校生向けUnity&AR講座
by
Saya Katafuchi
201310合同ゼミ論文紹介
by
Saya Katafuchi
VirtualDJでPCDJっぽいことをやった
by
Saya Katafuchi
ヤンデレのUnityに愛されて眠れない〜りたーんず〜
by
Saya Katafuchi
Capture the flag!
by
Saya Katafuchi
Tesseract-OCR in iOS
by
Saya Katafuchi
ヤンデレのUnityに愛されて眠れない〜Unity3分クッキング〜
by
Saya Katafuchi
マルウェア解析講座そのいち〜仮想環境下では暴れないけど質問ある?〜
by
Saya Katafuchi
Reverseengineering koukai
by
Saya Katafuchi
ディープボルツマンマシン入門
1.
20140514 ディープボルツマンマシン入門 ーボルツマンマシンの確率モデルと ボルツマンマシンの学習ー 長崎県立大学 国際情報学部 情報メディア学科 B2211017 片渕
小夜
2.
目次 ボルツマンマシンの確率分布の定義 無向グラフの例(5ノード)
ボルツマンマシンの確率モデル 数式の意味ー確率モデル 数式の意味ーエネルギー関数 数式の意味 cf.白黒画像で考える ボルツマンマシンの学習とは 可視変数・隠れ変数 可視変数・隠れ変数 cf.白黒画像で考える 次週
3.
目次 ボルツマンマシンの確率分布の定義 無向グラフの例(5ノード)
ボルツマンマシンの確率モデル 数式の意味ー確率モデル 数式の意味ーエネルギー関数 数式の意味 cf.白黒画像で考える ボルツマンマシンの学習とは 可視変数・隠れ変数 可視変数・隠れ変数 cf.白黒画像で考える 次週
4.
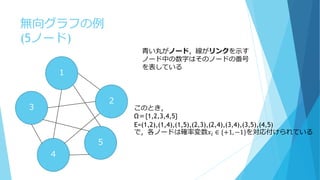
ボルツマンマシンの確率分布の定義 いくつかのノードΩ={1,2,…,|Ω|}といくつかの無向リン クEからなる無向グラフG(Ω,E)があるとする ノードiとノードjの間のリンクは(i,j)と表される.グラフG は無向グラフであるので,(i,j)と(j,i)は同一のリンクを示 す
なお,i番目のノードには確率変数𝑥𝑖 ∈ {+1, −1}を対応させ る ※無向グラフ: ノードとノードをつなぐリンクに 方向性がない
5.
無向グラフの例 (5ノード) 3 4 5 1 2 青い丸がノード,線がリンクを示す ノード中の数字はそのノードの番号 を表している このとき, Ω={1,2,3,4,5} E=(1,2),(1,4),(1,5),(2,3),(2,4),(3,4),(3,5),(4,5) で,各ノードは確率変数𝑥𝑖 ∈ {+1,
−1}を対応付けられている
6.
目次 ボルツマンマシンの確率分布の定義 無向グラフの例(5ノード)
ボルツマンマシンの確率モデル 数式の意味ー確率モデル 数式の意味ーエネルギー関数 数式の意味 cf.白黒画像で考える ボルツマンマシンの学習とは 可視変数・隠れ変数 可視変数・隠れ変数 cf.白黒画像で考える 次週
7.
ボルツマンマシンの確率モデル 𝑃𝐵 𝑋 𝜃,
𝜔 ≔ 1 𝑍 𝐵 𝜃, 𝜔 exp(−Φ 𝑋 𝜃, 𝜔 ) Φ 𝑋 𝜃, 𝜔 ≔ − 𝜃𝑖 𝑋𝑖 𝑖∈Ω − 𝜔𝑖𝑗 𝑋𝑖 𝑋𝑗 (𝑖,𝑗)∈𝐸 バイアス項 相互作用項 𝑃(𝑋)はデータ生成の確率規則となる データ生成モデル 𝑃 𝑋 𝜃 はパラメータθを持った学習モデル ここで指数関数の引数に指定されているのはエネルギー関数であり,
8.
数式の意味 ー確率モデル 𝑃𝐵 𝑋 𝜃,
𝜔 ≔ 1 𝑍 𝐵 𝜃, 𝜔 exp(−Φ 𝑋 𝜃, 𝜔 ) 指数関数の引数が,エネルギー関数の負となっている →エネルギーが低いXのパターンが高確率で出現するようになっている
9.
数式の意味 ーエネルギー関数 Φ 𝑋 𝜃,
𝜔 ≔ − 𝜃𝑖 𝑋𝑖 𝑖∈Ω − 𝜔𝑖𝑗 𝑋𝑖 𝑋𝑗 (𝑖,𝑗)∈𝐸 𝜃𝑖 > 0のとき,𝑋𝑖 = +1のほうがエネルギーを低くする(確率が高くなる) 𝜃𝑖 < 0のとき,𝑋𝑖 = −1のほうがエネルギーを低くする(確率が高くなる) →𝜽𝒊の正負によって𝑿𝒊の値の出現確率に偏りが出るので,𝜽はバイアスと呼ばれる 𝜔𝑖𝑗 > 0のとき,𝑋𝑖と𝑋𝑗は同じ値をとったほうがエネルギーが低くなる 𝜔𝑖𝑗 < 0のとき,𝑋𝑖と𝑋𝑗は異なる値をとったほうがエネルギーが低くなる →ωはリンクで結ばれた変数同士の値の関連性(そろいやすさ・そろい難さ)を調整する
10.
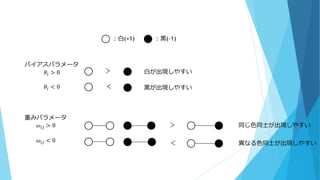
数式の意味 cf.白黒画像で考える 確率変数𝑋𝑖は白(+1)か黒(-1)をとり,これを各ピクセルに対応させる 白黒画像における ボルツマンマシンのグラフ構造 最も近いピクセル同士は強く依存しあうであろうという仮定の元に, リンクは最近説のピクセル間のみに存在するとする バイアスパラメータ:ピクセルの色の偏り(白になりやすさ,黒になりやすさ) 重みパラメータ:隣同士のピクセルの色の揃いやすさ
11.
:白(+1) :黒(-1) バイアスパラメータ 𝜃𝑖 >
0 𝜃𝑖 < 0 重みパラメータ 𝜔𝑖𝑗 > 0 𝜔𝑖𝑗 < 0 > > < < 白が出現しやすい 黒が出現しやすい 同じ色同士が出現しやすい 異なる色同士が出現しやすい
12.
目次 ボルツマンマシンの確率分布の定義 無向グラフの例(5ノード)
ボルツマンマシンの確率モデル 数式の意味ー確率モデル 数式の意味ーエネルギー関数 数式の意味 cf.白黒画像で考える ボルツマンマシンの学習とは 可視変数・隠れ変数 可視変数・隠れ変数 cf.白黒画像で考える 次週
13.
ボルツマンマシンの学習とは ボルツマンマシンの学習 実際に観測したデータの出現確率に沿うようにパラメータ {𝜃, 𝜔}の値を調整する 観測データからのボルツマンマシンの学習方法とは どんなものか?
14.
目次 ボルツマンマシンの確率分布の定義 無向グラフの例(5ノード)
ボルツマンマシンの確率モデル 数式の意味ー確率モデル 数式の意味ーエネルギー関数 数式の意味 cf.白黒画像で考える ボルツマンマシンの学習とは 可視変数・隠れ変数 可視変数・隠れ変数 cf.白黒画像で考える 次週
15.
可視変数・隠れ変数 少し前に発表していた可視ユニット、非可視ユニットのこ と 可視変数(visible
variable) データに対応している変数 非可視変数(hidden variable) データに直接対応しない変数
16.
可視変数・非可視変数 cf.白黒画像で考える 各確率変数は画像の各ピクセルに対応 観測データ点として、欠損のない完全な白黒画像が得られるとき、全ての確率 変数に対応したデータが存在する
観測データ点として、カメラの劣化などの原因で画像の一部に欠損の生じた画 像が得られるとき、欠損部に対応する確率変数は存在しない データに対応する変数が可視変数であるので、可視変数のみのボルツマンマシン 対応する観測データが得られない変数を含むので、非可視変数を含むボルツマンマシン
17.
目次 ボルツマンマシンの確率分布の定義 無向グラフの例(5ノード)
ボルツマンマシンの確率モデル 数式の意味ー確率モデル 数式の意味ーエネルギー関数 数式の意味 cf.白黒画像で考える ボルツマンマシンの学習とは 可視変数・隠れ変数 可視変数・隠れ変数 cf.白黒画像で考える 次週
18.
次週 可視変数のみのボルツマンマシン学習 最尤法とは
最尤法の別の視点「カルバック・ライブラー情報量」とは
19.
20140528 ディープボルツマンマシン入門 ー可視変数のみのボルツマンマシン・最尤法ー 長崎県立大学 国際情報学部 情報メディア学科 B2211017 片渕
小夜
20.
目次 可視変数のみのボルツマンマシンとは cf.白黒画像で考える
最尤法とは 最尤法を用いた計算ー対数尤度関数 カルバック・ライブラー情報量とは 最尤法をKL情報量の観点で見る ボルツマンマシンがなぜ有用でないとされてきたか ボルツマンマシンが見直されてきた理由
21.
目次 可視変数のみのボルツマンマシンとは cf.白黒画像で考える
最尤法とは 最尤法を用いた計算ー対数尤度関数 カルバック・ライブラー情報量とは 最尤法をKL情報量の観点で見る ボルツマンマシンがなぜ有用でないとされてきたか ボルツマンマシンが見直されてきた理由
22.
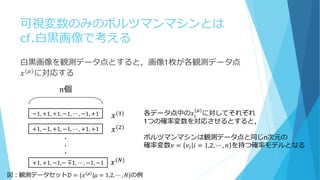
可視変数のみのボルツマンマシンとは すべての変数が可視変数であるから, 𝑋𝑖のかわりに𝑣𝑖を使用する つまり 𝑃𝐵 𝑋 𝜃,
𝜔 = 𝑃𝐵 𝑣 𝜃, 𝜔 となる n次元の観測データ点がそれぞれ統計的に独立に,同分布から N個手に入ったとき, 𝑥(𝜇) = {𝑥𝑖 𝜇 ∈ {+1, −1}|𝑖 = 1,2, ⋯ , 𝑛} と表す
23.
可視変数のみのボルツマンマシンとは cf.白黒画像で考える 白黒画像を観測データ点とすると,画像1枚が各観測データ点 𝑥(𝜇)に対応する −1, +1, +1,
−1, ⋯ , −1, +1 +1, −1, +1, −1, ⋯ , +1, +1 +1, +1, −1,− ∓1, ⋯ , −1, −1 ・ ・ ・ 𝑛個 𝑥(1) 𝑥(2) 𝑥(𝑁) 各データ点中の𝑥𝑖 (𝜇) に対してそれぞれ 1つの確率変数を対応させるとすると, ボルツマンマシンは観測データ点と同じn次元の 確率変数𝑣 = 𝑣𝑖 𝑖 = 1,2, ⋯ , 𝑛 を持つ確率モデルとなる 図:観測データセット𝒟 = {𝑥 𝜇 |𝜇 = 1,2, ⋯ , 𝑁}の例
24.
目次 可視変数のみのボルツマンマシンとは cf.白黒画像で考える
最尤法とは 最尤法を用いた計算ー対数尤度関数 カルバック・ライブラー情報量とは 最尤法をKL情報量の観点で見る ボルツマンマシンがなぜ有用でないとされてきたか ボルツマンマシンが見直されてきた理由
25.
最尤法とは 観測データセット𝒟 = {𝑥 𝜇 |𝜇
= 1,2, ⋯ , 𝑁}に対して、以下の尤度関数を定 める ℒ 𝒟 𝜃, 𝜔 ≔ 𝑃𝐵 𝑥 𝜇 𝜃, 𝜔 𝑁 𝜇=1 𝑃𝐵 𝑥 𝜇 𝜃, 𝜔 :ボルツマンマシンが観測データ点𝑥(𝜇)を生成する確率 各観測データ点は独立に発生しているので、これらの積を示す尤度関数は 観測データセット𝓓をボルツマンマシンが生成する確率となる 最尤法とは、 尤度関数を最大とするパラメータの値(最尤解)を求めること 得られた観測データセットを生成するために一番尤もらしい分布を求めること
26.
最尤法を用いた計算 ー対数尤度関数 尤度関数の自然対数をとった対数尤度関数 ℒ 𝒟 𝜃,
𝜔 ≔ 𝑙𝑛ℒ 𝒟 𝜃, 𝜔 = 𝑙𝑛𝑃𝐵(𝑥 𝜇 |𝜃, 𝜔) 𝑁 𝜇=1 を最大化するほうが便利な場合が多い ※対数関数は単純増加関数なので、最尤解は対数尤度関数を最大化するパラメー タの値と一致する
27.
最大点を求めるために、対数尤度関数を最大化するパラメータの勾配を計算する 𝜕ℒ 𝒟(𝜃, 𝜔) 𝜕𝜃𝑖 =
𝑥𝑖 (𝜇) − 𝑁𝔼 𝐵[𝑣𝑖|𝜃, 𝜔] 𝑁 𝜇=1 𝜕ℒ 𝒟(𝜃, 𝜔) 𝜕𝜔𝑖𝑗 = 𝑥𝑖 (𝜇) 𝑥𝑗 (𝜇) − 𝑁𝔼 𝐵[𝑣𝑖 𝑣𝑗|𝜃, 𝜔] 𝑁 𝜇=1 ここで𝔼 𝐵[⋯ |𝜃, 𝜔]はボルツマンマシンに関する期待値で、 𝔼 𝐵 ⋯ 𝜃, 𝜔 = (⋯ )𝑃𝐵(𝑣|𝜃, 𝜔) 𝑣 確率変数𝑣すべての実現パターンに関する総和を実行することにより得られる つまり、 𝜽の勾配と𝝎 の勾配がボルツマンマシンの期待値と一致するようなNを求 めればよい
28.
よって、以下の連立方程式が成り立つ 1 𝑁 𝑥𝑖 (𝜇) = 𝔼
𝐵[𝑣𝑖|𝜃, 𝜔] 𝑁 𝜇=1 1 𝑁 𝑥𝑖(𝜇) 𝑥𝑗 𝜇 = 𝑁 𝜇=1 𝔼 𝐵[𝑣𝑖|𝜃, 𝜔] この方程式はボルツマンマシンの学習方程式と呼ばれ、最尤解はこの方程式の解 となる 学習方程式は別名モーメントマッチング(moment matching)とも呼ばれ、多くの 確立モデルの学習の中で現れる
29.
目次 可視変数のみのボルツマンマシンとは cf.白黒画像で考える
最尤法とは 最尤法を用いた計算ー対数尤度関数 カルバック・ライブラー情報量とは 最尤法をKL情報量の観点で見る ボルツマンマシンがなぜ有用でないとされてきたか ボルツマンマシンが見直されてきた理由
30.
カルバック・ライブラー情報量とは カルバック・ライブラー(Kullback-Leibler:KL)情報量 確率変数Xに対する2つの確率分布𝑃0 𝑋
と𝑃1(𝑋)の間の近さを考える重要な量として知ら れており、以下のように定義される 𝐷(𝑃0| 𝑃1 ≔ 𝑃0 𝑋 𝑙𝑛 𝑃0(𝑋) 𝑃1(𝑋) 𝑥 KL情報量𝐷(𝑃0| 𝑃1 は0以上であり、 𝑃0 𝑋 = 𝑃1 𝑋 のときのみ𝐷(𝑃0| 𝑃1 =0となる KL情報量は2つの確率分布間の距離のようなものとして扱うことができる
31.
最尤法をKL情報量の観点で見る 観測データセット𝒟に対する経験分布(観測データ点の頻度分布のこと)を定義 𝑄 𝒟 𝑣
≔ 1 𝑁 𝛿 𝑣, 𝑥𝑖 𝜇 , 𝛿 𝑥, 𝑦 = 1𝑥 = 𝑦 0𝑥 ≠ 𝑦 𝑁 𝜇=1 𝑄 𝒟(𝑣) ≥ 0を満たし、かつ規格化条件 𝑄 𝒟(𝑣)𝑣 = 1を満たすので、確率分布である この経験分布とボルツマンマシンの間のKL情報量は以下のとおりである 𝒟(𝑄 𝒟| 𝑃𝐵 = 𝑄 𝒟 𝑣 𝑙𝑛 𝑄 𝒟(𝑣) 𝑃𝐵(𝑣|𝜃, 𝜔) 𝑣 このとき、𝒟(𝑄 𝒟| 𝑃𝐵 が最小となるようなパラメータの値を求めると、微分したと き0となる条件から、最尤法と同様にボルツマンマシンの学習方程式が成り立つ KL情報量の観点からみると、最尤法は観測データセットの経験分布と ボルツマンマシンを最も近づける方法である。
32.
目次 可視変数のみのボルツマンマシンとは cf.白黒画像で考える
最尤法とは 最尤法を用いた計算ー対数尤度関数 カルバック・ライブラー情報量とは 最尤法をKL情報量の観点で見る ボルツマンマシンがなぜ有用でないとされてきたか ボルツマンマシンが見直されてきた理由
33.
ボルツマンマシンがなぜ有用でないと されてきたか ボルツマンマシンの確率モデルの計算のミソはその期待値にある 期待値計算は確率変数の全実現可能パターンに関する和であるため、単純にn次元のボ ルツマンマシンにおける期待値計算は2 𝑛 個の多重和の計算となる n
time 10 約0.00001秒 30 約0.18分 50 約130日 70 約37万4000年 100 約4000億年 nの増加に伴い計算時間が爆発的に増加 →計算量爆発と呼ばれる
34.
ボルツマンマシンが見直されてきた 理由 確率伝搬法(loopy belief
propagation) 疑似最尤法(maximum pseudo-likehood estimation:MPLE) 複合最尤法(maximum composite likehood estimation) スコアマッチング コンストラクティブ・ダイバージェンス(CD)法 などの現実的な時間内で実行することが可能な近似学習法が開発された この中でも、疑似最尤法は実装の簡便さと高い学習性能をもつことからよく利用 されている
35.
次週 隠れ変数を含むボルツマンマシン学習
36.
20140611 ディープボルツマンマシン入門 ー非可視変数ありのボルツマンマシン 長崎県立大学 国際情報学部 情報メディア学科 B2211017 片渕
小夜
37.
目次 非可視変数を含むボルツマンマシン 非可視変数を含むボルツマンマシンの確率モデル
KL情報量最小化の観点 非可視変数がある場合のボルツマンマシンの学習方程式 非可視変数の意味とは 学習モデルの表現能力とモデル誤差 学習モデルを複雑化する方法 次週
38.
目次 非可視変数を含むボルツマンマシン 非可視変数を含むボルツマンマシンの確率モデル
KL情報量最小化の観点 非可視変数がある場合のボルツマンマシンの学習方程式 非可視変数の意味とは 学習モデルの表現能力とモデル誤差 学習モデルを複雑化する方法 次週
39.
非可視変数を含むボルツマンマシン 1 3 2 4 5 (n+m)次元の変数のうち、ノード番号(確率変数の添え字) の若い順に並べ、最初のn次元を各観測データに対応させる(可視変数) 残りのm次元の変数は観測データとは関係のない変数(非可視変数)とする ここで、 観測データ点に対応するノード番号の集合を𝑉 =
1, ⋯ , 𝑛 とし、 対応しないノード番号の集合を𝐻 = 𝑛 + 1, ⋯ , 𝑛 + 𝑚 とする ノード全体の集合はΩ = 𝑉 + 𝐻で表すことができる。 3次元の観測データセットに対し、5次元のボルツマンマシンを用いて 学習するとき、 𝑉 = 1,2,3 𝐻 = 4,5 𝑋 = 𝑋1, 𝑋2, 𝑋3, 𝑋4, 𝑋5 = {𝑣1, 𝑣2, 𝑣3, ℎ4, ℎ5} であり、ノード1~3は可視変数、ノード4,5は非可視変数として扱われる3次元の観測データセットを 5次元のボルツマンマシンを使って学習する例
40.
非可視変数を含むボルツマンマシンの 確率モデル 非可視変数を含む場合でも、基本的に最尤法に基づいた学習を行うことに変わりはな い 隠れ変数がある場合は、隠れ変数に関して周辺化した可視変数vのみのn次元の確率分 布 𝑃𝑉 𝑋 𝜃,
𝜔 ≔ 𝑃𝐵 𝑣, ℎ 𝜃, 𝜔 ℎ を用いることとなる。 可視変数のみの確率分布であるから前週紹介した方法で尤度関数を作ることができ、 ℒ 𝒟 𝐻 𝜃, 𝜔 ≔ 𝑙𝑛𝑃𝑉(𝑥 𝜇 |𝜃, 𝜔) 𝑁 𝜇=1 で表すことができる。最尤解は、この対数尤度関数を最大化するパラメータである。
41.
KL情報量最小化の観点 KL情報量:観測データセットの経験分布とボルツマンマシンを最も近づける方法 以下のKL情報量を最小化することで学習は達成される 𝐷(𝑄 𝒟|
𝑃𝑉 = 𝑄 𝒟 𝑣 𝑙𝑛 𝑄 𝒟(𝑣) 𝑃𝑣(𝑣|𝜃, 𝜔) 𝑣 ※𝑄 𝒟 𝑣 は観測データセットの経験分布
42.
非可視変数がある場合のボルツマンマシ ンの学習方程式 対数尤度関数最大化の条件、KL情報量最小化の条件より、 𝑧𝑖 𝑃 𝐻|𝑉
ℎ 𝑣, 𝜃, 𝜔 𝑄 𝒟 𝑣 = 𝔼 𝐵[𝑧𝑖|𝜃, 𝜔] 𝑣,ℎ 𝑧𝑖 𝑧𝑗 𝑃 𝐻|𝑉 ℎ 𝑣, 𝜃, 𝜔 𝑄 𝒟 𝑣 = 𝔼 𝐵[𝑧𝑖 𝑧𝑗|𝜃, 𝜔] 𝑣,ℎ ここで𝑧𝑖は、 𝑧𝑖 = 𝑣𝑖𝑖 ∈ 𝑉 ∈ Ω ℎ𝑖𝑖 ∈ 𝐻 ∈ Ω のように、ノードiが可視変数ノードか非可視変数ノードかに応じて変換される変数で ある。
43.
また、𝑃 𝐻|𝑉 ℎ
𝑣, 𝜃, 𝜔 は可視変数が与えられたもとでの非可視変数の確率で、 ベイズの公式より 𝑃 𝐻|𝑉 ℎ 𝑣, 𝜃, 𝜔 = 𝑃𝐵(𝑣, ℎ|𝜃, 𝜔) 𝑃𝑉(𝑣|𝜃, 𝜔) によって与えられる。 𝔼 𝐵 ⋯ 𝜃, 𝜔 はこれまでと同様にボルツマンマシンの期待値であり、ボルツマンマ シンが取り得るすべての確率変数の出現パターンの総和である。非可視変数を含 む場合は𝔼 𝐵 ⋯ 𝜃, 𝜔 = (⋯ )𝑃𝐵(𝑣, ℎ|𝜃, 𝜔)𝑣,ℎ である。 ※ベイズの公式(定理) 事象Bのベイズ確率について、 𝑃 𝐵 𝐴 = 𝑃 𝐴 𝐵 𝑃(𝐵) 𝑃(𝐴) P(A):事象Aが起こる確率 P(B):事象Aが起きる前の事象Bが起こる確率(事前確率) P(B|A):事象Aが起きた後に事象Bが起こる確率(事後確率) P(A|B):尤度(事象Aが起きた後に事象Bが起こる尤もらしさ)
44.
目次 非可視変数を含むボルツマンマシン 非可視変数を含むボルツマンマシンの確率モデル
KL情報量最小化の観点 非可視変数がある場合のボルツマンマシンの学習方程式 非可視変数の意味とは 学習モデルの表現能力とモデル誤差 学習モデルを複雑化する方法 次週
45.
非可視変数の意味とは 「何らかの原因で一部のデータが得られない場合に,得ら れないデータに対応した変数を非可視変数として扱う」 学習の表現能力を向上させる 表現能力:パラメータの値を変化させることで再現することの できる確率分布の種類の多さ
46.
目次 非可視変数を含むボルツマンマシン 非可視変数を含むボルツマンマシンの確率モデル
KL情報量最小化の観点 非可視変数がある場合のボルツマンマシンの学習方程式 非可視変数の意味とは 学習モデルの表現能力とモデル誤差 学習モデルを複雑化する方法 次週
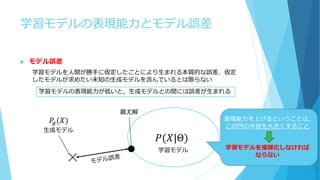
47.
学習モデルの表現能力とモデル誤差 モデル誤差 学習モデルを人間が勝手に仮定したことにより生まれる本質的な誤差.仮定 したモデルが求めたい未知の生成モデルを含んでいるとは限らない 学習モデルの表現能力が低いと,生成モデルとの間には誤差が生まれる 𝑃(𝑋|Θ) 学習モデル 𝑃𝑔(𝑋) 生成モデル 最尤解 表現能力を上げるということは, この円の半径を大きくすること 学習モデルを複雑化しなければ ならない
48.
目次 非可視変数を含むボルツマンマシン 非可視変数を含むボルツマンマシンの確率モデル
KL情報量最小化の観点 非可視変数がある場合のボルツマンマシンの学習方程式 非可視変数の意味とは 学習モデルの表現能力とモデル誤差 学習モデルを複雑化する方法 次週
49.
学習モデルを複雑化する方法 1. エネルギー関数に3次以上の相互作用の項を加えた高次ボルツマンマシン →これまで紹介してきたのは2次のボルツマンマシン(ノードの持つ値とリンクの重み) →むずかしい 2. 非可視変数の導入 →エネルギー関数の形を変えることなくモデルを複雑化することができる
50.
目次 非可視変数を含むボルツマンマシン 非可視変数を含むボルツマンマシンの確率モデル
KL情報量最小化の観点 非可視変数がある場合のボルツマンマシンの学習方程式 非可視変数の意味とは 学習モデルの表現能力とモデル誤差 学習モデルを複雑化する方法 次週
51.
次週 リストリクティッドボルツマンマシン RBMの学習方程式
ディープボルツマンマシン(DBM) 論文まとめ
52.
20140618 ディープボルツマンマシン入門 ーRBMとその学習 長崎県立大学 国際情報学部 情報メディア学科 B2211017 片渕
小夜
53.
目次 リストリクティッドボルツマンマシン(RBM)とは RBMの学習方程式
RBMの性質 (1)条件付き独立の性質 (2)RBMの周辺確率
54.
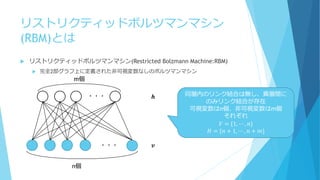
リストリクティッドボルツマンマシン (RBM)とは リストリクティッドボルツマンマシン(Restricted Bolzmann
Machine:RBM) 完全2部グラフ上に定義された非可視変数なしのボルツマンマシン ・・・ ・・・ m個 n個 𝒉 𝒗 同層内のリンク結合は無し、異層間に のみリンク結合が存在 可視変数はn個、非可視変数はm個 それぞれ 𝑉 = {1, ⋯ , 𝑛} 𝐻 = {𝑛 + 1, ⋯ , 𝑛 + 𝑚}
55.
RBMのエネルギー関数と確率モデル 可視変数を𝑣, 非可視変数をℎとすると、 Φ 𝑋
𝜃, 𝜔 = Φ(𝑣, ℎ|𝜃 𝑣 , 𝜃ℎ , 𝜔) = − 𝜃𝑖 𝑣 𝑣𝑖 − 𝜃𝑗ℎ ℎ𝑗 − 𝜔𝑖𝑗 𝑣𝑖ℎ𝑗 𝑗∈𝐻𝑖∈𝑉𝑗∈𝐻𝑖∈𝑉 𝜃 𝑣:可視変数に対するバイアス 𝜃ℎ:非可視変数に対するバイアス 上の式から、RBMの確率モデルは 𝑃𝐵 𝑣, ℎ 𝜃 𝑣 , 𝜃ℎ , 𝜔 ∝ exp(− 𝜃𝑖 𝑣 𝑣𝑖 − 𝜃𝑗ℎ ℎ𝑗 − 𝜔𝑖𝑗 𝑣𝑖ℎ𝑗 𝑗∈𝐻𝑖∈𝑉𝑗∈𝐻𝑖∈𝑉 ) で表現することができる 以下、表記の簡単化の為にパラメータをΘで表す Θ = {𝜃 𝑣 , 𝜃ℎ , 𝜔}
56.
RBMの学習方程式 RBMは非可視変数を含むボルツマンマシンのひとつ N個のn次元観測データセット𝒟を得たとすると、それぞれ可視変数,非可視変数のバイアス 項について,以下の学習方程式が成り立つ. 1 𝑁 𝑥𝑖 (𝜇) = 𝔼
𝐵 𝑣𝑖 Θ (𝑖 ∈ 𝑉) 𝑁 𝜇=1 1 𝑁 tanh 𝜃𝑖 ℎ + 𝜔𝑗𝑖 𝑥𝑗 𝜇 𝑗∈𝑉 = 𝔼 𝐵[ℎ𝑖|Θ] 𝑁 𝜇=1 (𝑖 ∈ 𝐻)
57.
この2つの式を組み合わせて、左辺にかかるバイアスを最小化し、ボルツマンマシ ンの期待値と合わせてやればよい。 1 𝑁 𝑥(𝜇) tanh( 𝜃𝑗 ℎ + 𝜔𝑗𝑖
𝑥𝑗 (𝜇) ) = 𝔼 𝐵[ℎ𝑖|Θ] 𝑗∈𝑉 𝑁 𝜇=1 (𝑖 ∈ 𝐻) 左辺は観測データセットの値から簡単に計算可能 右辺はRBMの期待値計算となるため,計算量爆発の可能性がある 何らかの近似的アプローチが必要となる
58.
RBMの性質 RBMは2部グラフという特別なグラフ構造を持ち,通常のボルツマンマシ ンにはないいくつかの有用な性質を持つ 1. 条件付き独立の性質 2. RBMの周辺確率
59.
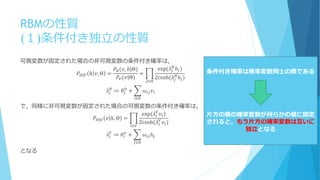
RBMの性質 (1)条件付き独立の性質 可視変数が固定された場合の非可視変数の条件付き確率は, 𝑃 𝐻|𝑉 ℎ
𝑣, Θ = 𝑃𝐵(𝑣, ℎ|Θ) 𝑃𝑉(𝑣|Θ) = exp( 𝜆𝑗 𝐻 ℎ𝑗) 2cosh( 𝜆𝑗 𝐻 ℎ𝑗) 𝑗∈𝐻 𝜆𝑗 𝐻 ≔ 𝜃𝑗 ℎ + 𝜔𝑖𝑗 𝑣𝑖 𝑖∈𝑉 で,同様に非可視変数が固定された場合の可視変数の条件付き確率は, 𝑃 𝐻|𝑉 𝑣 ℎ, Θ = exp( 𝜆𝑖 𝑉 𝑣𝑖) 2cosh( 𝜆𝑖 𝑉 𝑣𝑖) 𝑖∈𝑉 𝜆𝑖 𝑉 ≔ 𝜃𝑖 𝑣 + 𝜔𝑖𝑗ℎ𝑗 𝑗∈𝐻 となる 条件付き確率は確率変数同士の積である 片方の層の確率変数が何らかの値に固定 されると,もう片方の確率変数は互いに 独立となる
60.
RBMの性質 (2)RBMの周辺確率 可視変数に関する周辺確率𝑃𝑉(𝑣|Θ)を簡単に計算できる 𝑃𝑉(𝑣|Θ) ∝ exp(−Φ
𝑉 𝑣 Θ ) Φ 𝑉 𝑣 Θ = − 𝜃𝑖 𝑣 𝑣𝑖 − 𝑙𝑛2𝑐𝑜𝑠ℎ𝜆𝑗 𝐻 𝑗∈𝐻𝑖∈𝑉 周辺確率𝑃𝑉(𝑣|Θ)を具体的に記述することができる →疑似最尤法などの隠れ変数のない場合に対して考案されている近似学習法を RBMの学習にも適用することが可能となっている 疑似最尤法を拡張した複合最尤法を利用した学習アルゴリズムも 提案されている
61.
エネルギー関数Φ 𝑉 𝑣
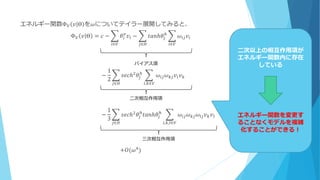
Θ を𝜔についてテイラー展開してみると、 Φ 𝑉 𝑣 Θ = 𝑐 − 𝜃𝑖 𝑣 𝑣𝑖 − 𝑡𝑎𝑛ℎ𝜃𝑗 ℎ 𝜔𝑖𝑗 𝑣𝑖 𝑖∈𝑉𝑗∈𝐻𝑖∈𝑉 − 1 2 𝑠𝑒𝑐ℎ2 𝜃𝑗 ℎ 𝜔𝑖𝑗 𝜔 𝑘𝑗 𝑣𝑖 𝑣 𝑘 𝑖,𝑘∈𝑉𝑗∈𝐻 − 1 3 𝑠𝑒𝑐ℎ2 𝜃𝑗 ℎ 𝑡𝑎𝑛ℎ𝜃𝑗 ℎ 𝜔𝑖𝑗 𝜔 𝑘𝑗 𝜔𝑙𝑗 𝑣 𝑘 𝑣𝑙 𝑖,𝑘,𝑙∈𝑉𝑗∈𝐻 +𝑂(𝜔4) 二次相互作用項 バイアス項 三次相互作用項 二次以上の相互作用項が エネルギー関数内に存在 している エネルギー関数を変更す ることなくモデルを複雑 化することができる!
62.
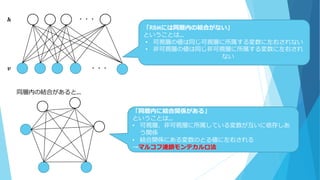
・・・ ・・・ 「RBMには同層内の結合がない」 ということは… • 可視層の値は同じ可視層に所属する変数に左右されない • 非可視層の値は同じ非可視層に所属する変数に左右され ない 𝒉 𝒗 同層内の結合があると… 「同層内に結合関係がある」 ということは… •
可視層、非可視層に所属している変数が互いに依存しあ う関係 • 結合関係にある変数のとる値に左右される →マルコフ連鎖モンテカルロ法
63.
20140618 ディープボルツマンマシン入門 ーDBMの学習とまとめ 長崎県立大学 国際情報学部 情報メディア学科 B2211017 片渕
小夜
64.
目次 ディープボルツマン(DBM)とは DBMのエネルギー関数
DBMの基本的な学習法ー貪欲学習 DBMの学習において大切なこと まとめ
65.
目次 ディープボルツマン(DBM)とは DBMのエネルギー関数
DBMの基本的な学習法ー貪欲学習 DBMの学習において大切なこと まとめ
66.
ディープボルツマンマシン(DBM)とは 非可視層を階層的に積み上 げていくことで構成される 非可視ノードありのボルツ マンマシン 𝑊(3) ℎ(1) ℎ(2) ℎ(3) 𝑊(1) 𝑊(2) 𝑣
67.
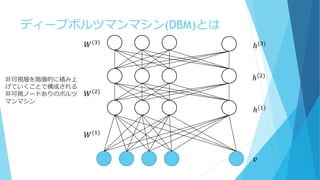
DBMのエネルギー関数 𝑉:可視層のノードの番号の集合 𝐻𝑟:第𝑟番目の隠れ層のノードの集合 𝑣 = 𝑣𝑖
∈ +1, −1 𝑖 ∈ 𝑉 :可視変数 ℎ = {ℎ𝑖 𝑟 ∈ {+1, −1}|𝑖 ∈ 𝐻𝑟}:第𝑟番目の非可視層内に存在する非可視変数 R層の隠れ層からなるエネルギー関数は, Φ 𝑣, ℎ 𝑊 = − 𝜔𝑖𝑗 1 𝑗∈𝐻1𝑖∈𝑉 𝑣𝑖ℎ𝑗 1 − 𝜔𝑖𝑗 (𝑟) ℎ𝑖 (𝑟−1) ℎ𝑗 (𝑟) 𝑗∈𝐻 𝑟𝑖∈𝐻 𝑟−1 𝑅 𝑟=2 ℎ(1) ⋯ ℎ 𝑅 をまとめてℎ,𝜔(1) ⋯ 𝜔(𝑅) をまとめて𝑊で表している
68.
DBMの基本的な学習法ー貪欲学習 貪欲学習(greedy learning) 近似アルゴリズムの最も基本的な考え方のひとつ 問題の要素を複数の部分に分割し,それぞれの部分を独立に評価を行い、評価値の高い 順に取り組んでいく学習法 DBMの学習では、階層的に積み重なったボルツマンマシンの層を分割して 学習を行っていく
69.
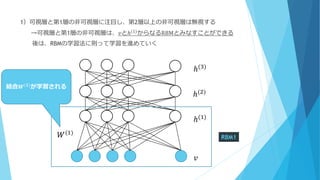
1)可視層と第1層の非可視層に注目し、第2層以上の非可視層は無視する →可視層と第1層の非可視層は、𝑣とℎ(1) からなるRBMとみなすことができる 後は、RBMの学習法に則って学習を進めていく ℎ(1) ℎ(2) ℎ(3) 𝑣 RBM1𝑊(1) 結合𝑾(𝟏) が学習される
70.
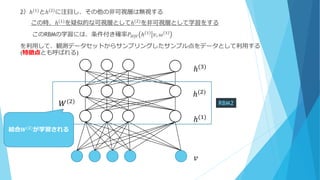
2)ℎ(1) とℎ(2) に注目し、その他の非可視層は無視する この時、ℎ(1)を疑似的な可視層としてℎ(2)を非可視層として学習をする このRBMの学習には、条件付き確率𝑃 𝐻|𝑉 ℎ
1 𝑣, 𝜔 1 を利用して、観測データセットからサンプリングしたサンプル点をデータとして利用する (特徴点とも呼ばれる) ℎ(1) ℎ(2) ℎ(3) 𝑣 RBM2𝑊(2) 結合𝑾(𝟐)が学習される
71.
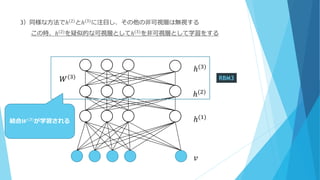
3)同様な方法でℎ(2)とℎ(3)に注目し、その他の非可視層は無視する この時、ℎ(2) を疑似的な可視層としてℎ(3) を非可視層として学習をする ℎ(1) ℎ(2) ℎ(3) 𝑣 RBM3𝑊(3) 結合𝑾(𝟑) が学習される
72.
このとき、ℎ(1) の特徴点をサンプルしたときと同様に、ℎ(2) の特徴点を条件付き確 率を用いてℎ(1) の特徴点からサンプルする 特徴点をサンプルするための数式は以下のようになる 𝑃 𝐻 𝑟|𝐻
𝑟−1 ℎ 𝑟 ℎ 𝑟−1 , 𝜔 𝑟 = exp( 𝜆𝑗 𝐻 𝑟−1 ℎ𝑗 𝑟 ) 𝑒𝑐𝑜𝑠ℎ(𝜆𝑗 𝐻 𝑟−1 ℎ𝑗 𝑟 )𝑗∈𝐻 𝑟 𝜆𝑗 𝐻 𝑟−1 = 𝜔𝑗𝑘 (𝑟) ℎ𝑗 (𝑟−1) 𝑘∈𝐻 𝑟−1 このサンプル点をデータとして,𝑊(3)を学習する
73.
目次 ディープボルツマン(DBM)とは DBMのエネルギー関数
DBMの基本的な学習法ー貪欲学習 DBMの学習において大切なこと まとめ
74.
DBMの学習において大切なこと 貪欲学習などによる事前学習 パラメータの適切な初期値設定に用いる学習. その後DBM全体に対するMCMC(マルコフ連鎖モンテカルロ法)などでパラメータを細か く調整 事前学習で決定したパラメータの初期値が学習のキーとなる
75.
まとめ DBMに適した近似的アルゴリズムを創出していかなければならない DBMは層ごとにRBMとみなしながら学習を進めていく→ 対数尤度関数を目指すものではないので学習がどのようになっているかわからない しかし計算量の問題から厳密な計算を行うことはできない DBMの構造に関して理解を深めねばならない DBMのミソはその層構造にある→ 単に非可視変数の数を増やし,モデルの表現能力を上げるのならばRBMで十分
76.
参考文献 安田 宗樹(2013)「ディープボルツマンマシン入門ーボルツマンマシン学習の基 礎ー」『人工知能学会誌』28巻3号(2013年5月号) 474pp
Download
























![最大点を求めるために、対数尤度関数を最大化するパラメータの勾配を計算する
𝜕ℒ 𝒟(𝜃, 𝜔)
𝜕𝜃𝑖
= 𝑥𝑖
(𝜇)
− 𝑁𝔼 𝐵[𝑣𝑖|𝜃, 𝜔]
𝑁
𝜇=1
𝜕ℒ 𝒟(𝜃, 𝜔)
𝜕𝜔𝑖𝑗
= 𝑥𝑖
(𝜇)
𝑥𝑗
(𝜇)
− 𝑁𝔼 𝐵[𝑣𝑖 𝑣𝑗|𝜃, 𝜔]
𝑁
𝜇=1
ここで𝔼 𝐵[⋯ |𝜃, 𝜔]はボルツマンマシンに関する期待値で、
𝔼 𝐵 ⋯ 𝜃, 𝜔 = (⋯ )𝑃𝐵(𝑣|𝜃, 𝜔)
𝑣
確率変数𝑣すべての実現パターンに関する総和を実行することにより得られる
つまり、 𝜽の勾配と𝝎 の勾配がボルツマンマシンの期待値と一致するようなNを求
めればよい](https://image.slidesharecdn.com/20140514-140619231406-phpapp01/85/slide-27-320.jpg)
![よって、以下の連立方程式が成り立つ
1
𝑁
𝑥𝑖 (𝜇)
= 𝔼 𝐵[𝑣𝑖|𝜃, 𝜔]
𝑁
𝜇=1
1
𝑁
𝑥𝑖(𝜇) 𝑥𝑗 𝜇 =
𝑁
𝜇=1
𝔼 𝐵[𝑣𝑖|𝜃, 𝜔]
この方程式はボルツマンマシンの学習方程式と呼ばれ、最尤解はこの方程式の解
となる
学習方程式は別名モーメントマッチング(moment matching)とも呼ばれ、多くの
確立モデルの学習の中で現れる](https://image.slidesharecdn.com/20140514-140619231406-phpapp01/85/slide-28-320.jpg)













![非可視変数がある場合のボルツマンマシ
ンの学習方程式
対数尤度関数最大化の条件、KL情報量最小化の条件より、
𝑧𝑖 𝑃 𝐻|𝑉 ℎ 𝑣, 𝜃, 𝜔 𝑄 𝒟 𝑣 = 𝔼 𝐵[𝑧𝑖|𝜃, 𝜔]
𝑣,ℎ
𝑧𝑖 𝑧𝑗 𝑃 𝐻|𝑉 ℎ 𝑣, 𝜃, 𝜔 𝑄 𝒟 𝑣 = 𝔼 𝐵[𝑧𝑖 𝑧𝑗|𝜃, 𝜔]
𝑣,ℎ
ここで𝑧𝑖は、
𝑧𝑖 =
𝑣𝑖𝑖 ∈ 𝑉 ∈ Ω
ℎ𝑖𝑖 ∈ 𝐻 ∈ Ω
のように、ノードiが可視変数ノードか非可視変数ノードかに応じて変換される変数で
ある。](https://image.slidesharecdn.com/20140514-140619231406-phpapp01/85/slide-42-320.jpg)











![RBMの学習方程式
RBMは非可視変数を含むボルツマンマシンのひとつ
N個のn次元観測データセット𝒟を得たとすると、それぞれ可視変数,非可視変数のバイアス
項について,以下の学習方程式が成り立つ.
1
𝑁
𝑥𝑖
(𝜇)
= 𝔼 𝐵 𝑣𝑖 Θ (𝑖 ∈ 𝑉)
𝑁
𝜇=1
1
𝑁
tanh 𝜃𝑖
ℎ
+ 𝜔𝑗𝑖 𝑥𝑗
𝜇
𝑗∈𝑉
= 𝔼 𝐵[ℎ𝑖|Θ]
𝑁
𝜇=1
(𝑖 ∈ 𝐻)](https://image.slidesharecdn.com/20140514-140619231406-phpapp01/85/slide-56-320.jpg)
![この2つの式を組み合わせて、左辺にかかるバイアスを最小化し、ボルツマンマシ
ンの期待値と合わせてやればよい。
1
𝑁
𝑥(𝜇)
tanh( 𝜃𝑗
ℎ
+ 𝜔𝑗𝑖 𝑥𝑗
(𝜇)
) = 𝔼 𝐵[ℎ𝑖|Θ]
𝑗∈𝑉
𝑁
𝜇=1
(𝑖 ∈ 𝐻)
左辺は観測データセットの値から簡単に計算可能
右辺はRBMの期待値計算となるため,計算量爆発の可能性がある
何らかの近似的アプローチが必要となる](https://image.slidesharecdn.com/20140514-140619231406-phpapp01/85/slide-57-320.jpg)






















![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)













![[ICLR2017読み会 @ DeNA] ICLR2017紹介](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2017denaiclr2017-170616173153-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)
































