Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Masayuki Tanaka
6,095 views
RBMを応用した事前学習とDNN学習
Restricted Boltzmann Machinesの 基礎と実装
Science
◦
Related topics:
Deep Learning
•
Read more
19
Save
Share
Embed
Embed presentation
1
/ 58
2
/ 58
3
/ 58
4
/ 58
5
/ 58
6
/ 58
7
/ 58
8
/ 58
9
/ 58
10
/ 58
11
/ 58
12
/ 58
13
/ 58
14
/ 58
15
/ 58
16
/ 58
17
/ 58
18
/ 58
19
/ 58
20
/ 58
21
/ 58
22
/ 58
23
/ 58
24
/ 58
25
/ 58
26
/ 58
27
/ 58
28
/ 58
29
/ 58
30
/ 58
31
/ 58
32
/ 58
33
/ 58
34
/ 58
35
/ 58
36
/ 58
37
/ 58
38
/ 58
39
/ 58
40
/ 58
41
/ 58
42
/ 58
43
/ 58
44
/ 58
45
/ 58
46
/ 58
47
/ 58
48
/ 58
49
/ 58
50
/ 58
51
/ 58
52
/ 58
53
/ 58
54
/ 58
55
/ 58
56
/ 58
57
/ 58
58
/ 58
More Related Content
PDF
制限ボルツマンマシン入門
by
佑馬 斎藤
PDF
深層学習 勉強会第5回 ボルツマンマシン
by
Yuta Sugii
PDF
MIRU2016 チュートリアル
by
Shunsuke Ono
PDF
Sparse estimation tutorial 2014
by
Taiji Suzuki
PDF
深層学習による非滑らかな関数の推定
by
Masaaki Imaizumi
PDF
Chapter 8 ボルツマンマシン - 深層学習本読み会
by
Taikai Takeda
PPTX
確率的バンディット問題
by
jkomiyama
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
制限ボルツマンマシン入門
by
佑馬 斎藤
深層学習 勉強会第5回 ボルツマンマシン
by
Yuta Sugii
MIRU2016 チュートリアル
by
Shunsuke Ono
Sparse estimation tutorial 2014
by
Taiji Suzuki
深層学習による非滑らかな関数の推定
by
Masaaki Imaizumi
Chapter 8 ボルツマンマシン - 深層学習本読み会
by
Taikai Takeda
確率的バンディット問題
by
jkomiyama
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
What's hot
PDF
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料)
by
Takuma Yagi
PDF
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PDF
PRML8章
by
弘毅 露崎
PPTX
独立性基準を用いた非負値行列因子分解の効果的な初期値決定法(Statistical-independence-based efficient initia...
by
Daichi Kitamura
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PDF
Mean Teacher
by
harmonylab
PDF
Recurrent Neural Networks
by
Seiya Tokui
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
強化学習その1
by
nishio
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
PDF
PRML輪読#7
by
matsuolab
PDF
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
PPTX
Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について
by
Yusuke Nakata
PPTX
G社のNMT論文を読んでみた
by
Toshiaki Nakazawa
PDF
PRML 5章 PP.227-PP.247
by
Tomoki Hayashi
PPTX
[DL輪読会]大規模分散強化学習の難しい問題設定への適用
by
Deep Learning JP
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PPTX
PRML読み会第一章
by
Takushi Miki
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料)
by
Takuma Yagi
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PRML8章
by
弘毅 露崎
独立性基準を用いた非負値行列因子分解の効果的な初期値決定法(Statistical-independence-based efficient initia...
by
Daichi Kitamura
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
Mean Teacher
by
harmonylab
Recurrent Neural Networks
by
Seiya Tokui
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
強化学習その1
by
nishio
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話)
by
Yoshitake Takebayashi
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
PRML輪読#7
by
matsuolab
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について
by
Yusuke Nakata
G社のNMT論文を読んでみた
by
Toshiaki Nakazawa
PRML 5章 PP.227-PP.247
by
Tomoki Hayashi
[DL輪読会]大規模分散強化学習の難しい問題設定への適用
by
Deep Learning JP
変分ベイズ法の説明
by
Haruka Ozaki
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PRML読み会第一章
by
Takushi Miki
Similar to RBMを応用した事前学習とDNN学習
PDF
Implement for Deep Learning of RBM Network in C.
by
Masato Nakai
PPTX
Statistical machine learning
by
ilove2dgirl
PDF
20140726.西野研セミナー
by
Hayaru SHOUNO
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PDF
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
PDF
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
PPTX
Deep learning basics described
by
Naoki Watanabe
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
Deep learning実装の基礎と実践
by
Seiya Tokui
PDF
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計
by
Yuta Sugii
PDF
NN, CNN, and Image Analysis
by
Yuki Shimada
PDF
社内機械学習勉強会 #5
by
shingo suzuki
PDF
Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾)
by
Ohsawa Goodfellow
PPTX
Deep Learningについて(改訂版)
by
Brains Consulting, Inc.
PPTX
ディープボルツマンマシン入門〜後半〜
by
sakaizawa
PPTX
Deepboltzmannmachine
by
ilove2dgirl
PDF
03_深層学習
by
CHIHIROGO
PDF
Report2
by
YoshikazuHayashi3
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
20170422 数学カフェ Part1
by
Kenta Oono
Implement for Deep Learning of RBM Network in C.
by
Masato Nakai
Statistical machine learning
by
ilove2dgirl
20140726.西野研セミナー
by
Hayaru SHOUNO
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
Deep learning basics described
by
Naoki Watanabe
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
Deep learning実装の基礎と実践
by
Seiya Tokui
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計
by
Yuta Sugii
NN, CNN, and Image Analysis
by
Yuki Shimada
社内機械学習勉強会 #5
by
shingo suzuki
Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾)
by
Ohsawa Goodfellow
Deep Learningについて(改訂版)
by
Brains Consulting, Inc.
ディープボルツマンマシン入門〜後半〜
by
sakaizawa
Deepboltzmannmachine
by
ilove2dgirl
03_深層学習
by
CHIHIROGO
Report2
by
YoshikazuHayashi3
深層学習の数理
by
Taiji Suzuki
20170422 数学カフェ Part1
by
Kenta Oono
More from Masayuki Tanaka
PDF
Slideshare breaking inter layer co-adaptation
by
Masayuki Tanaka
PDF
PRMU201902 Presentation document
by
Masayuki Tanaka
PDF
Gradient-Based Low-Light Image Enhancement
by
Masayuki Tanaka
PDF
Year-End Seminar 2018
by
Masayuki Tanaka
PPTX
遠赤外線カメラと可視カメラを利用した悪条件下における画像取得
by
Masayuki Tanaka
PPTX
Learnable Image Encryption
by
Masayuki Tanaka
PDF
クリエイティブ・コモンズ
by
Masayuki Tanaka
PDF
デザイン4原則
by
Masayuki Tanaka
PDF
メラビアンの法則
by
Masayuki Tanaka
PDF
類似性の法則
by
Masayuki Tanaka
PDF
権威に訴える論証
by
Masayuki Tanaka
PDF
Chain rule of deep neural network layer for back propagation
by
Masayuki Tanaka
PDF
Give Me Four
by
Masayuki Tanaka
PDF
Tech art 20170315
by
Masayuki Tanaka
PDF
My Slide Theme
by
Masayuki Tanaka
PDF
Font Memo
by
Masayuki Tanaka
PPT
One-point for presentation
by
Masayuki Tanaka
PPTX
ADMM algorithm in ProxImaL
by
Masayuki Tanaka
PPTX
Intensity Constraint Gradient-Based Image Reconstruction
by
Masayuki Tanaka
PPTX
Least Square with L0, L1, and L2 Constraint
by
Masayuki Tanaka
Slideshare breaking inter layer co-adaptation
by
Masayuki Tanaka
PRMU201902 Presentation document
by
Masayuki Tanaka
Gradient-Based Low-Light Image Enhancement
by
Masayuki Tanaka
Year-End Seminar 2018
by
Masayuki Tanaka
遠赤外線カメラと可視カメラを利用した悪条件下における画像取得
by
Masayuki Tanaka
Learnable Image Encryption
by
Masayuki Tanaka
クリエイティブ・コモンズ
by
Masayuki Tanaka
デザイン4原則
by
Masayuki Tanaka
メラビアンの法則
by
Masayuki Tanaka
類似性の法則
by
Masayuki Tanaka
権威に訴える論証
by
Masayuki Tanaka
Chain rule of deep neural network layer for back propagation
by
Masayuki Tanaka
Give Me Four
by
Masayuki Tanaka
Tech art 20170315
by
Masayuki Tanaka
My Slide Theme
by
Masayuki Tanaka
Font Memo
by
Masayuki Tanaka
One-point for presentation
by
Masayuki Tanaka
ADMM algorithm in ProxImaL
by
Masayuki Tanaka
Intensity Constraint Gradient-Based Image Reconstruction
by
Masayuki Tanaka
Least Square with L0, L1, and L2 Constraint
by
Masayuki Tanaka
RBMを応用した事前学習とDNN学習
1.
田中正行 東京工業大学 Restricted Boltzmann Machinesの 基礎と実装 ~RBMを応用した事前学習とDNN学習~
2.
概要 1. ディープラーニング 2. RBMからディープニューラルネットワーク 3.
ディープニューラルネットワーク – 誤差逆伝搬法(教師有学習) 4. RBM( Restricted Boltzmann Machine ) – RBMの基礎,確率モデル,推論モデル – CD法による事前学習(教師無学習) 5. 分布を考慮したNN推論 1 実行はできるけど中身はわからない. 理論的バックグランドがわかった!
3.
ディープラーニングの例 2 – MNIST (handwritten
digits benchmark) MNIST 文字認識のベンチマークでトップ
4.
ディープラーニングの例 3 CIFAR10 – CIFAR (image
classification benchmark) 画像認識のベンチマークでトップ
5.
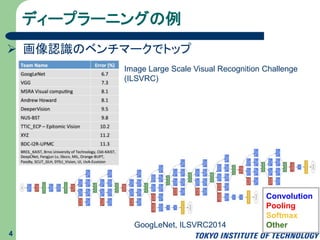
ディープラーニングの例 4 Convolution Pooling Softmax OtherGoogLeNet, ILSVRC2014 Image Large
Scale Visual Recognition Challenge (ILSVRC) 画像認識のベンチマークでトップ
6.
ディープラーニングの例 5 http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en//archive/uns upervised_icml2012.pdf YouTubeの映像を学習データとして与えると, 人の顔に反応するニューロン ネコの顔に反応するニューロン などを自動的に獲得 1000万枚の学習データ 1000台のPCで3日間学習 5 ネコ細胞の自動生成
7.
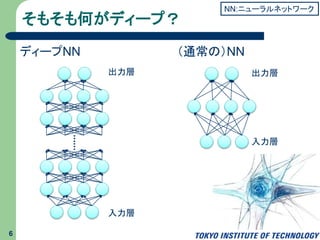
そもそも何がディープ? 6 入力層 出力層 (通常の)NN 入力層 出力層 ディープNN NN:ニューラルネットワーク
8.
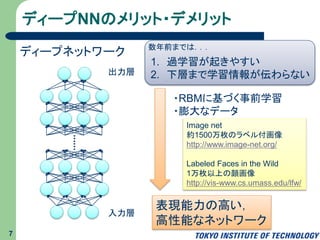
ディープNNのメリット・デメリット 7 入力層 出力層 ディープネットワーク 数年前までは... 1. 過学習が起きやすい 2.
下層まで学習情報が伝わらない ・RBMに基づく事前学習 ・膨大なデータ Image net 約1500万枚のラベル付画像 http://www.image-net.org/ Labeled Faces in the Wild 1万枚以上の顔画像 http://vis-www.cs.umass.edu/lfw/ 表現能力の高い, 高性能なネットワーク
9.
概要 1. ディープラーニング 2. RBMからディープニューラルネットワーク 3.
ディープニューラルネットワーク – 誤差逆伝搬法(教師有学習) 4. RBM( Restricted Boltzmann Machine ) – RBMの基礎,確率モデル,推論モデル – CD法による事前学習(教師無学習) 5. 分布を考慮したNN推論 8
10.
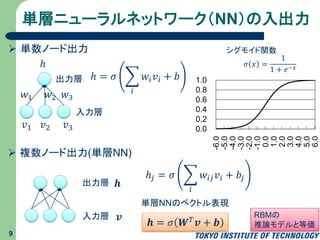
単層ニューラルネットワーク(NN)の入出力 9 入力層 𝑣1 𝑣2 𝑣3 ℎ 出力層 𝑤1
𝑤2 𝑤3 ℎ = 𝜎 𝑖 𝑤𝑖 𝑣𝑖 + 𝑏 𝜎 𝑥 = 1 1 + 𝑒−𝑥 シグモイド関数 0.0 0.2 0.4 0.6 0.8 1.0 -6.0 -5.0 -4.0 -3.0 -2.0 -1.0 0.0 1.0 2.0 3.0 4.0 5.0 6.0 単数ノード出力 複数ノード出力(単層NN) 𝒉出力層 入力層 𝒗 ℎ𝑗 = 𝜎 𝑖 𝑤𝑖𝑗 𝑣𝑖 + 𝑏𝑗 𝒉 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 単層NNのベクトル表現 RBMの 推論モデルと等価
11.
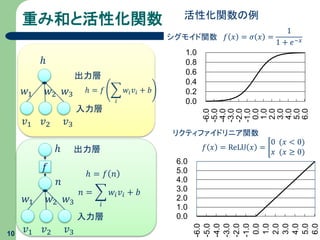
重み和と活性化関数 10 入力層 𝑣1 𝑣2 𝑣3 ℎ
出力層 𝑤1 𝑤2 𝑤3 𝑛 𝑓 ℎ = 𝑓 𝑛 𝑛 = 𝑖 𝑤𝑖 𝑣𝑖 + 𝑏 入力層 𝑣1 𝑣2 𝑣3 ℎ 出力層 𝑤1 𝑤2 𝑤3 ℎ = 𝑓 𝑖 𝑤𝑖 𝑣𝑖 + 𝑏 𝑓 𝑥 = 𝜎 𝑥 = 1 1 + 𝑒−𝑥シグモイド関数 0.0 0.2 0.4 0.6 0.8 1.0 -6.0 -5.0 -4.0 -3.0 -2.0 -1.0 0.0 1.0 2.0 3.0 4.0 5.0 6.0 活性化関数の例 0.0 1.0 2.0 3.0 4.0 5.0 6.0 -6.0 -5.0 -4.0 -3.0 -2.0 -1.0 0.0 1.0 2.0 3.0 4.0 5.0 6.0 リクティファイドリニア関数 𝑓 𝑥 = ReLU 𝑥 = 0 (𝑥 < 0) 𝑥 (𝑥 ≥ 0)
12.
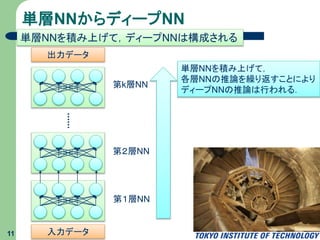
単層NNからディープNN 11 単層NNを積み上げて,ディープNNは構成される 第1層NN 第2層NN 第k層NN 出力データ 入力データ 単層NNを積み上げて, 各層NNの推論を繰り返すことにより ディープNNの推論は行われる.
13.
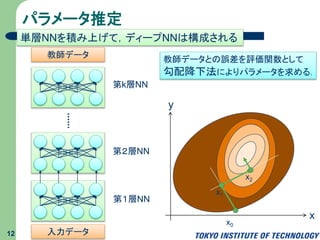
ディープNNのパラメータ推定 12 単層NNを積み上げて,ディープNNは構成される 第1層NN 第2層NN 第k層NN 教師データ 入力データ 教師データとの誤差を評価関数として 勾配降下法によりパラメータを求める. x y x0 x1 x2
14.
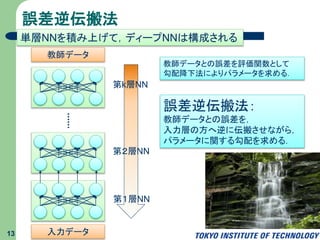
誤差逆伝搬法 13 単層NNを積み上げて,ディープNNは構成される 第1層NN 第2層NN 第k層NN 教師データ 入力データ 誤差逆伝搬法: 教師データとの誤差を, 入力層の方へ逆に伝搬させながら, パラメータに関する勾配を求める. 教師データとの誤差を評価関数として 勾配降下法によりパラメータを求める.
15.
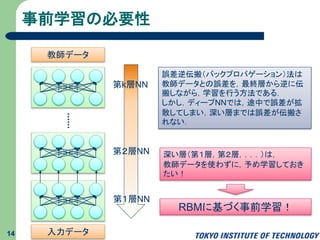
事前学習の必要性 14 第1層NN 第2層NN 第k層NN 誤差逆伝搬(バックプロパゲーション)法は 教師データとの誤差を,最終層から逆に伝 搬しながら,学習を行う方法である. しかし,ディープNNでは,途中で誤差が拡 散してしまい,深い層までは誤差が伝搬さ れない. 教師データ 深い層(第1層,第2層,...)は, 教師データを使わずに,予め学習しておき たい! RBMに基づく事前学習! 入力データ
16.
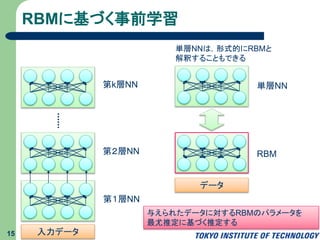
RBMに基づく事前学習 15 第1層NN 第2層NN 第k層NN 入力データ 単層NN RBM データ 単層NNは,形式的にRBMと 解釈することもできる 与えられたデータに対するRBMのパラメータを 最尤推定に基づく推定する
17.
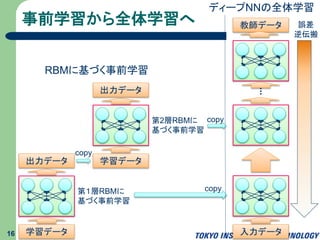
事前学習から全体学習へ 16 学習データ 出力データ 第1層RBMに 基づく事前学習 学習データ 出力データ 第2層RBMに 基づく事前学習 入力データ 教師データ 誤差 逆伝搬 copy copy copy ディープNNの全体学習 RBMに基づく事前学習
18.
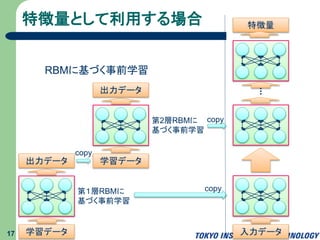
特徴量として利用する場合 17 学習データ 出力データ 第1層RBMに 基づく事前学習 学習データ 出力データ 第2層RBMに 基づく事前学習 入力データ 特徴量 copy copy copy RBMに基づく事前学習
19.
概要 1. ディープラーニング 2. RBMからディープニューラルネットワーク 3.
ディープニューラルネットワーク – 誤差逆伝搬法(教師有学習) 4. RBM( Restricted Boltzmann Machine ) – RBMの基礎,確率モデル,推論モデル – CD法による事前学習(教師無学習) 5. 分布を考慮したNN推論 18
20.
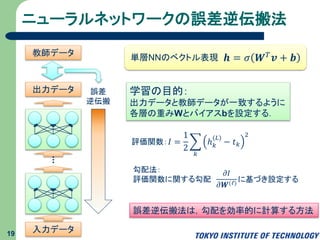
ニューラルネットワークの誤差逆伝搬法 19 入力データ 教師データ 誤差 逆伝搬 出力データ 𝒉 =
𝜎 𝑾 𝑇 𝒗 + 𝒃単層NNのベクトル表現 学習の目的: 出力データと教師データが一致するように 各層の重みWとバイアスbを設定する. 𝐼 = 1 2 𝑘 ℎ 𝑘 (𝐿) − 𝑡 𝑘 2 評価関数: 勾配法: 評価関数に関する勾配 に基づき設定する 𝜕𝐼 𝜕𝑾(ℓ) 誤差逆伝搬法は,勾配を効率的に計算する方法
21.
誤差逆伝搬法:シグモイド関数の微分 20 𝜎 𝑥 = 1 1
+ 𝑒−𝑥 シグモイド関数 シグモイド関数の微分 𝜕𝜎 𝜕𝑥 = 1 − 𝜎 𝑥 𝜎(𝑥) シグモイド関数の微分の導出 𝜕𝜎 𝜕𝑥 = 𝜕 𝜕𝑥 1 1 + 𝑒−𝑥 = − 1 1 + 𝑒−𝑥 2 × −𝑒−𝑥 = 𝑒−𝑥 1 + 𝑒−𝑥 2 = 𝑒−𝑥 1 + 𝑒−𝑥 × 1 1 + 𝑒−𝑥 = 1 − 1 1 + 𝑒−𝑥 1 1 + 𝑒−𝑥 = (1 − 𝜎 𝑥 )𝜎 𝑥
22.
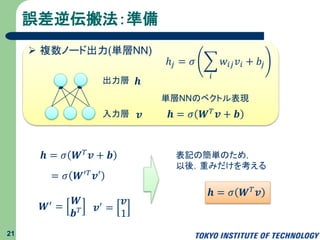
誤差逆伝搬法:準備 21 複数ノード出力(単層NN) 𝒉出力層 入力層 𝒗 ℎ𝑗
= 𝜎 𝑖 𝑤𝑖𝑗 𝑣𝑖 + 𝑏𝑗 𝒉 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 単層NNのベクトル表現 𝑾′ = 𝑾 𝒃 𝑇 𝒗′ = 𝒗 1 𝒉 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 = 𝜎 𝑾′ 𝑇 𝒗′ 表記の簡単のため, 以後,重みだけを考える 𝒉 = 𝜎 𝑾 𝑇 𝒗
23.
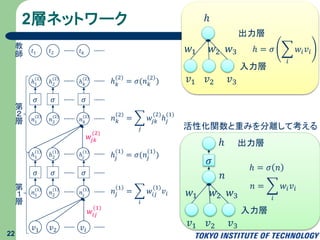
2層ネットワーク 22 ℎ 𝑘 (2) = 𝜎(𝑛
𝑘 2 ) 𝑛 𝑘 2 = 𝑗 𝑤𝑗𝑘 (2) ℎ𝑗 (1) ℎ𝑗 (1) = 𝜎(𝑛𝑗 1 ) 𝑛𝑗 1 = 𝑖 𝑤𝑖𝑗 (1) 𝑣𝑖 𝑣1 𝑣2 𝑣𝑖 𝑛1 (1) 𝜎 𝜎 𝜎 𝑤𝑖𝑗 (1) 𝑛2 (1) 𝑛𝑗 (1) ℎ1 (1) ℎ2 (1) ℎ𝑗 (1) 𝑛1 (2) 𝜎 𝜎 𝜎 𝑛2 (2) 𝑛 𝑘 (2) ℎ1 (2) ℎ2 (2) ℎ 𝑘 (2) 第 1 層 第 2 層 𝑤𝑗𝑘 (2) 𝑡1 𝑡2 𝑡 𝑘 教 師 入力層 𝑣1 𝑣2 𝑣3 ℎ 出力層 𝑤1 𝑤2 𝑤3 ℎ = 𝜎 𝑖 𝑤𝑖 𝑣𝑖 入力層 𝑣1 𝑣2 𝑣3 ℎ 出力層 𝑤1 𝑤2 𝑤3 𝑛 𝜎 ℎ = 𝜎 𝑛 𝑛 = 𝑖 𝑤𝑖 𝑣𝑖 活性化関数と重みを分離して考える
24.
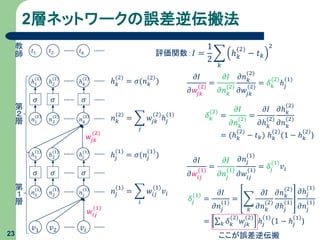
2層ネットワークの誤差逆伝搬法 23 ℎ 𝑘 (2) = 𝜎(𝑛
𝑘 2 ) 𝑛 𝑘 2 = 𝑗 𝑤𝑗𝑘 (2) ℎ𝑗 (1) ℎ𝑗 (1) = 𝜎(𝑛𝑗 1 ) 𝑛𝑗 1 = 𝑖 𝑤𝑖𝑗 (1) 𝑣𝑖 𝑣1 𝑣2 𝑣𝑖 𝑛1 (1) 𝜎 𝜎 𝜎 𝑤𝑖𝑗 (1) 𝑛2 (1) 𝑛𝑗 (1) ℎ1 (1) ℎ2 (1) ℎ𝑗 (1) 𝑛1 (2) 𝜎 𝜎 𝜎 𝑛2 (2) 𝑛 𝑘 (2) ℎ1 (2) ℎ2 (2) ℎ 𝑘 (2) 第 1 層 第 2 層 𝑤𝑗𝑘 (2) 𝑡1 𝑡2 𝑡 𝑘 教 師 𝐼 = 1 2 𝑘 ℎ 𝑘 (2) − 𝑡 𝑘 2 評価関数: 𝜕𝐼 𝜕𝑤𝑗𝑘 (2) = 𝜕𝐼 𝜕𝑛 𝑘 (2) 𝜕𝑛 𝑘 (2) 𝜕𝑤𝑗𝑘 (2) = 𝛿 𝑘 (2) ℎ𝑗 (1) 𝛿 𝑘 (2) = 𝜕𝐼 𝜕𝑛 𝑘 (2) = 𝜕𝐼 𝜕ℎ 𝑘 (2) 𝜕ℎ 𝑘 (2) 𝜕𝑛 𝑘 (2) = (ℎ 𝑘 (2) − 𝑡 𝑘) ℎ 𝑘 2 (1 − ℎ 𝑘 2 ) 𝜕𝐼 𝜕𝑤𝑖𝑗 (1) = 𝜕𝐼 𝜕𝑛𝑗 (1) 𝜕𝑛𝑗 (1) 𝜕𝑤𝑖𝑗 (1) = 𝛿𝑗 (1) 𝑣𝑖 𝛿𝑗 (1) = 𝜕𝐼 𝜕𝑛𝑗 (1) = 𝑘 𝜕𝐼 𝜕𝑛 𝑘 (2) 𝜕𝑛 𝑘 (2) 𝜕ℎ𝑗 (1) 𝜕ℎ𝑗 (1) 𝜕𝑛𝑗 (1) = 𝑘 𝛿 𝑘 (2) 𝑤𝑗𝑘 (2) ℎ𝑗 1 (1 − ℎ𝑗 1 ) ここが誤差逆伝搬
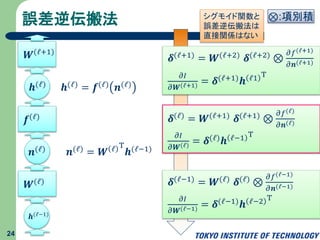
25.
誤差逆伝搬法 24 𝒉(ℓ−1) 𝑾(ℓ) 𝒏(ℓ) 𝒏(ℓ) = 𝑾
ℓ T 𝒉(ℓ−1) 𝒇(ℓ) 𝒉(ℓ) = 𝒇(ℓ) 𝒏(ℓ)𝒉(ℓ) 𝑾(ℓ+1) 𝜹(ℓ) = 𝑾(ℓ+1) 𝜹(ℓ+1) ⊗ 𝜕𝑓(ℓ) 𝜕𝒏(ℓ) 𝜕𝐼 𝜕𝑾(ℓ) = 𝜹(ℓ) 𝒉 ℓ−1 T ⊗:項別積 𝜹(ℓ+1) = 𝑾(ℓ+2) 𝜹(ℓ+2) ⊗ 𝜕𝑓(ℓ+1) 𝜕𝒏(ℓ+1) 𝜕𝐼 𝜕𝑾(ℓ+1) = 𝜹(ℓ+1) 𝒉 ℓ1 T 𝜹(ℓ−1) = 𝑾(ℓ) 𝜹(ℓ) ⊗ 𝜕𝑓(ℓ−1) 𝜕𝒏(ℓ−1) 𝜕𝐼 𝜕𝑾(ℓ−1) = 𝜹(ℓ−1) 𝒉 ℓ−2 T シグモイド関数と 誤差逆伝搬法は 直接関係はない
26.
勾配計算のデバッグTIP 25 𝐼(𝜽) = 1 2 𝑘 ℎ 𝑘 𝐿 (𝒗;
𝜽) − 𝑡 𝑘 2 𝜕𝐼 𝜕𝜃𝑖 評価関数 誤差逆伝搬法により 計算された勾配 𝜕𝐼 𝜕𝜃𝑖 = lim 𝜀→0 𝐼 𝜽 + 𝜀𝟏𝑖 − 𝐼 𝜽 𝜀 𝟏𝑖:i番目の要素が1,他は0 ∆𝑖 𝐼 = 𝐼 𝜽 + 𝜀𝟏𝑖 − 𝐼 𝜽 𝜀 計算効率高い 実装難しい 計算効率低い 実装容易 勾配の定義式 差分による近似勾配 十分𝜀が小さければ,∆𝑖 𝐼 ≑ 𝜕𝐼 𝜕𝜃𝑖
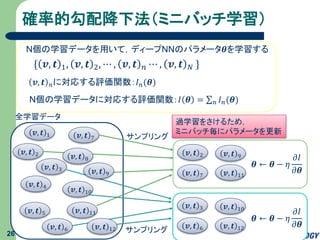
27.
確率的勾配降下法(ミニバッチ学習) 26 { 𝒗, 𝒕
1, 𝒗, 𝒕 2, ⋯ , 𝒗, 𝒕 𝑛 ⋯ , 𝒗, 𝒕 𝑁 } N個の学習データを用いて,ディープNNのパラメータ𝜽を学習する 𝒗, 𝒕 𝑛に対応する評価関数:𝐼 𝑛(𝜽) N個の学習データに対応する評価関数:𝐼 𝜽 = 𝑛 𝐼 𝑛(𝜽) 𝒗, 𝒕 7 𝒗, 𝒕 10 𝒗, 𝒕 1 𝒗, 𝒕 2 𝒗, 𝒕 3 𝒗, 𝒕 4 𝒗, 𝒕 11𝒗, 𝒕 5 𝒗, 𝒕 6 𝜽 ← 𝜽 − 𝜂 𝜕𝐼 𝜕𝜽𝒗, 𝒕 7 𝒗, 𝒕 9𝒗, 𝒕 2 𝒗, 𝒕 11 サンプリング 𝒗, 𝒕 6 𝒗, 𝒕 10𝒗, 𝒕 3 𝒗, 𝒕 12 𝒗, 𝒕 9 𝜽 ← 𝜽 − 𝜂 𝜕𝐼 𝜕𝜽 サンプリング𝒗, 𝒕 12 𝒗, 𝒕 8 過学習をさけるため, ミニバッチ毎にパラメータを更新 全学習データ
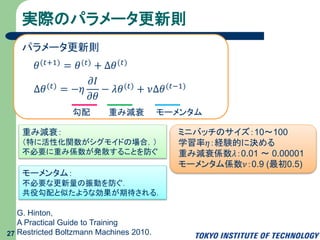
28.
実際のパラメータ更新則 27 G. Hinton, A Practical
Guide to Training Restricted Boltzmann Machines 2010. ミニバッチのサイズ:10~100 学習率𝜂:経験的に決める 重み減衰係数𝜆:0.01 ~ 0.00001 モーメンタム係数𝜈:0.9 (最初0.5) 𝜃(𝑡+1) = 𝜃(𝑡) + ∆𝜃(𝑡) ∆𝜃(𝑡) = −𝜂 𝜕𝐼 𝜕𝜃 − 𝜆𝜃(𝑡) + 𝜈∆𝜃(𝑡−1) パラメータ更新則 勾配 重み減衰 モーメンタム 重み減衰: (特に活性化関数がシグモイドの場合,) 不必要に重み係数が発散することを防ぐ モーメンタム: 不必要な更新量の振動を防ぐ. 共役勾配と似たような効果が期待される.
29.
概要 1. ディープラーニング 2. RBMからディープニューラルネットワーク 3.
ディープニューラルネットワーク – 誤差逆伝搬法(教師有学習) 4. RBM( Restricted Boltzmann Machine ) – RBMの基礎,確率モデル,推論モデル – CD法による事前学習(教師無学習) 5. 分布を考慮したNN推論 28
30.
Restricted Boltzmann Machines 29
ボルツマンマシン(Boltzmann Machines) 無向グラフ(ノードとエッジ)によって表現される状態の確率モデル. ここでは,ノードの状態として,{0,1}のバイナリ状態を考える. (制約無)ボルツマンマシンと制約付ボルツマンマシン(RBM) v:visible layer h:hidden layer v:visible layer h:hidden layer • (制約無)ボルツマンマシン • 制約付ボルツマンマシン(RBM) 全てのノードが接続 同一レイヤー内の接続無し これにより,解析が容易になる!
31.
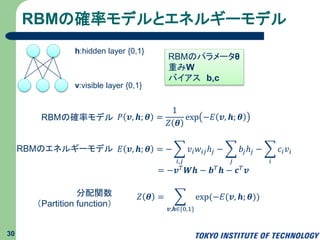
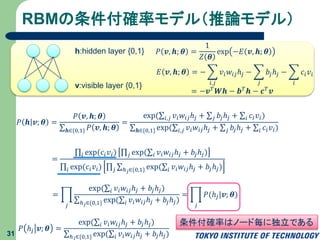
RBMの確率モデルとエネルギーモデル 30 v:visible layer {0,1} h:hidden
layer {0,1} RBMの確率モデル 𝑃 𝒗, 𝒉; 𝜽 = 1 𝑍 𝜽 exp −𝐸 𝒗, 𝒉; 𝜽 RBMのパラメータθ 重みW バイアス b,c RBMのエネルギーモデル 𝐸 𝒗, 𝒉; 𝜽 = − 𝑖,𝑗 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 − 𝑗 𝑏𝑗ℎ𝑗 − 𝑖 𝑐𝑖 𝑣𝑖 = −𝒗 𝑇 𝑾𝒉 − 𝒃 𝑇 𝒉 − 𝒄 𝑇 𝒗 分配関数 (Partition function) 𝑍 𝜽 = 𝒗,𝒉∈{0,1} exp(−𝐸(𝒗, 𝒉; 𝜽))
32.
= 𝑖 exp(𝑐𝑖 𝑣𝑖)
𝑗 exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑏𝑗ℎ𝑗) 𝑖 exp(𝑐𝑖 𝑣𝑖) 𝑗 ℎ 𝑗∈{0,1} exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑏𝑗ℎ𝑗) RBMの条件付確率モデル(推論モデル) 31 v:visible layer {0,1} h:hidden layer {0,1} 𝑃 𝒉 𝒗; 𝜽 = 𝑃 𝒗, 𝒉; 𝜽 𝒉∈{0,1} 𝑃 𝒗, 𝒉; 𝜽 = exp( 𝑖,𝑗 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑗 𝑏𝑗ℎ𝑗 + 𝑖 𝑐𝑖 𝑣𝑖) 𝒉∈{0,1} exp( 𝑖,𝑗 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑗 𝑏𝑗ℎ𝑗 + 𝑖 𝑐𝑖 𝑣𝑖) 条件付確率はノード毎に独立である 𝑃 ℎ𝑗 𝒗; 𝜽 = exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑏𝑗ℎ𝑗) ℎ 𝑗∈{0,1} exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑏𝑗ℎ𝑗) = 𝑗 exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑏𝑗ℎ𝑗) ℎ 𝑗∈{0,1} exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑏𝑗ℎ𝑗) = 𝑗 𝑃(ℎ𝑗|𝒗; 𝜽) 𝑃 𝒗, 𝒉; 𝜽 = 1 𝑍 𝜽 exp −𝐸 𝒗, 𝒉; 𝜽 𝐸 𝒗, 𝒉; 𝜽 = − 𝑖,𝑗 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 − 𝑗 𝑏𝑗ℎ𝑗 − 𝑖 𝑐𝑖 𝑣𝑖 = −𝒗 𝑇 𝑾𝒉 − 𝒃 𝑇 𝒉 − 𝒄 𝑇 𝒗
33.
RBMの条件付確率モデル(推論モデル) 32 v:visible layer {0,1} h:hidden
layer {0,1} 𝑃 ℎ𝑗 𝒗; 𝜽 = exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑏𝑗ℎ𝑗) ℎ 𝑗∈{0,1} exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 + 𝑏𝑗ℎ𝑗) 𝑃 ℎ𝑗 = 1 𝒗; 𝜽 = exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗 × 1 + 𝑏𝑗 × 1) exp 𝑖 𝑣𝑖 𝑤𝑖𝑗 × 0 + 𝑏𝑗 × 0 + exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗 × 1 + 𝑏𝑗 × 1) 𝜎 𝑥 = 1 1 + 𝑒−𝑥 = exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗 + 𝑏𝑗) exp 0 + exp( 𝑖 𝑣𝑖 𝑤𝑖𝑗 + 𝑏𝑗) = 1 1 + exp(− 𝑖 𝑣𝑖 𝑤𝑖𝑗 + 𝑏𝑗) = 𝜎 𝑖 𝑣𝑖 𝑤𝑖𝑗 + 𝑏𝑗 𝑃 𝒉 = 𝟏 𝒗; 𝜽 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 𝑃 𝒗 = 𝟏 𝒉; 𝜽 = 𝜎 𝑾𝒉 + 𝒄 𝒉 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 単層NNのベクトル表現
34.
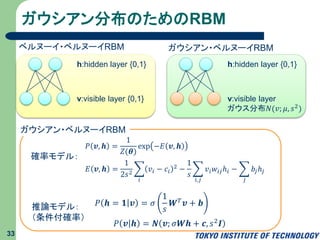
ガウシアン分布のためのRBM 33 v:visible layer {0,1} h:hidden
layer {0,1} ベルヌーイ・ベルヌーイRBM ガウシアン・ベルヌーイRBM v:visible layer ガウス分布𝑁(𝑣; 𝜇, 𝑠2 ) h:hidden layer {0,1} 𝑃 𝒗, 𝒉 = 1 𝑍(𝜽) exp −𝐸 𝒗, 𝒉 ガウシアン・ベルヌーイRBM 𝐸 𝒗, 𝒉 = 1 2𝑠2 𝑖 𝑣𝑖 − 𝑐𝑖 2 − 1 𝑠 𝑖,𝑗 𝑣𝑖 𝑤𝑖𝑗ℎ𝑖 − 𝑗 𝑏𝑗ℎ𝑗 確率モデル: 推論モデル: (条件付確率) 𝑃 𝒉 = 𝟏 𝒗 = 𝜎 1 𝑠 𝑾 𝑇 𝒗 + 𝒃 𝑃 𝒗 𝒉 = 𝑵 𝒗; 𝜎𝑾𝒉 + 𝒄, 𝑠2 𝑰
35.
概要 1. ディープラーニング 2. RBMからディープニューラルネットワーク 3.
ディープニューラルネットワーク – 誤差逆伝搬法(教師有学習) 4. RBM( Restricted Boltzmann Machine ) – RBMの基礎,確率モデル,推論モデル – CD法による事前学習(教師無学習) 5. 分布を考慮したNN推論 34
36.
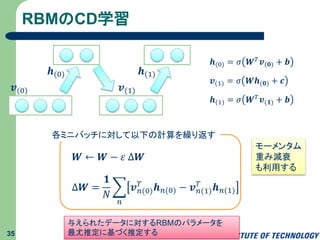
RBMのCD学習 35 𝒗(0) 𝒉(0) 𝒗(1) 𝒉(1) 𝒉(0) = 𝜎
𝑾 𝑇 𝒗(𝟎) + 𝒃 𝒗(1) = 𝜎 𝑾𝒉(𝟎) + 𝒄 𝒉(1) = 𝜎 𝑾 𝑇 𝒗(𝟏) + 𝒃 𝑾 ← 𝑾 − 𝜀 Δ𝑾 Δ𝑾 = 𝟏 𝑁 𝑛 𝒗 𝑛(0) 𝑇 𝒉 𝑛(0) − 𝒗 𝑛(1) 𝑇 𝒉 𝑛(1) 各ミニバッチに対して以下の計算を繰り返す 与えられたデータに対するRBMのパラメータを 最尤推定に基づく推定する モーメンタム 重み減衰 も利用する
37.
RBMに基づく事前学習概要 36 v:visible layer {0,1} h:hidden
layer {0,1} RBMのパラメータθ:重みW,バイアス b,c 𝑃 𝒗, 𝒉; 𝜽 = 1 𝑍 𝜽 exp −𝐸 𝒗, 𝒉; 𝜽 𝐸 𝒗, 𝒉; 𝜽 = − 𝑖,𝑗 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 − 𝑗 𝑏𝑗ℎ𝑗 − 𝑖 𝑐𝑖 𝑣𝑖 = −𝒗 𝑇 𝑾𝒉 − 𝒃 𝑇 𝒉 − 𝒄 𝑇 𝒗 • 学習データ{vn}に対する尤度最大化(最尤法)によりパラメータ推定 • Hidden dataが得られないので,(近似)EMアルゴリズムを活用 • 分配関数の評価にギブスサンプリングを活用 • 一回のサンプリングで近似 CD学習(Contrastive Divergence Learning)概要
38.
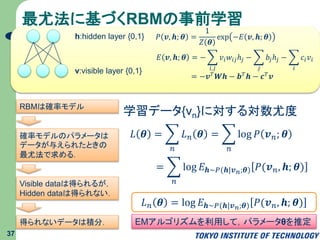
最尤法に基づくRBMの事前学習 37 v:visible layer {0,1} h:hidden
layer {0,1} 𝑃 𝒗, 𝒉; 𝜽 = 1 𝑍 𝜽 exp −𝐸 𝒗, 𝒉; 𝜽 𝐸 𝒗, 𝒉; 𝜽 = − 𝑖,𝑗 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 − 𝑗 𝑏𝑗ℎ𝑗 − 𝑖 𝑐𝑖 𝑣𝑖 = −𝒗 𝑇 𝑾𝒉 − 𝒃 𝑇 𝒉 − 𝒄 𝑇 𝒗 RBMは確率モデル 確率モデルのパラメータは データが与えられたときの 最尤法で求める. Visible dataは得られるが, Hidden dataは得られない. 得られないデータは積分. 学習データ{vn}に対する対数尤度 𝐿 𝜽 = 𝑛 𝐿 𝑛 𝜽 = 𝑛 log 𝑃 𝒗 𝑛; 𝜽 = 𝑛 log 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽) 𝑃(𝒗 𝑛, 𝒉; 𝜽) EMアルゴリズムを利用して,パラメータθを推定 𝐿 𝑛 𝜽 = log 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽) 𝑃(𝒗 𝑛, 𝒉; 𝜽)
39.
EMアルゴリズム 38 参考文献:これなら分かる最適化数学,金谷健一 𝐿 𝑛
𝜽 = log 𝑃 𝒗 𝑛; 𝜽 = log 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽) 𝑃(𝒗 𝑛, 𝒉; 𝜽) 学習データvnに対する対数尤度 EMアルゴリズムにより対数尤度は単調に増大する EMアルゴリズム 1. パラメータ𝜽を初期化𝜽0 する.𝜏 = 0とする. 2. 次の関数を計算する(Eステップ) 3. 𝑄 𝜏 𝜽 を最大にする𝜽 𝜏とする(Mステップ) 4. 𝜏←𝜏 + 1としてステップ2に戻り、これを収束するまで反復する。 𝑄 𝜏 𝜽 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) log 𝑃(𝒗 𝑛, 𝒉; 𝜽) ※CD学習では、ステップ3の最大化は完全には行われない.
40.
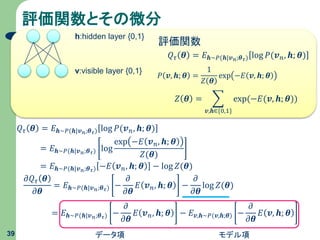
評価関数とその微分 39 𝑃 𝒗, 𝒉;
𝜽 = 1 𝑍 𝜽 exp −𝐸 𝒗, 𝒉; 𝜽 𝑍 𝜽 = 𝒗,𝒉∈{0,1} exp(−𝐸(𝒗, 𝒉; 𝜽)) 𝑄 𝜏 𝜽 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) log 𝑃(𝒗 𝑛, 𝒉; 𝜽) = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) log exp −𝐸 𝒗 𝑛, 𝒉; 𝜽 𝑍(𝜽) = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) −𝐸 𝒗 𝑛, 𝒉; 𝜽 − log 𝑍(𝜽) 𝑄 𝜏 𝜽 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) log 𝑃(𝒗 𝑛, 𝒉; 𝜽) 評価関数 v:visible layer {0,1} h:hidden layer {0,1} 𝜕𝑄 𝜏 𝜽 𝜕𝜽 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) − 𝜕 𝜕𝜽 𝐸 𝒗 𝑛, 𝒉; 𝜽 − 𝜕 𝜕𝜽 log 𝑍(𝜽) = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) − 𝜕 𝜕𝜽 𝐸 𝒗 𝑛, 𝒉; 𝜽 − 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽) − 𝜕 𝜕𝜽 𝐸 𝒗, 𝒉; 𝜽 データ項 モデル項
41.
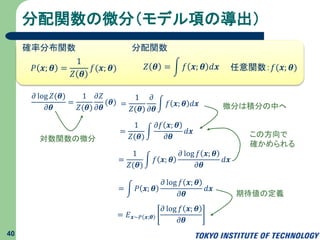
分配関数の微分(モデル項の導出) 40 𝜕 log 𝑍(𝜽) 𝜕𝜽 = 1 𝑍(𝜽) 𝜕𝑍 𝜕𝜽 (𝜽)
= 1 𝑍(𝜽) 𝜕 𝜕𝜽 𝑓 𝒙; 𝜽 𝑑𝒙 = 1 𝑍(𝜽) 𝜕𝑓 𝒙; 𝜽 𝜕𝜽 𝑑𝒙 = 1 𝑍(𝜽) 𝑓 𝒙; 𝜽 𝜕 log 𝑓 𝒙; 𝜽 𝜕𝜽 𝑑𝒙 𝑃 𝒙; 𝜽 = 1 𝑍 𝜽 𝑓(𝒙; 𝜽) 𝑍 𝜽 = 𝑓 𝒙; 𝜽 𝑑𝒙 確率分布関数 分配関数 任意関数:𝑓(𝒙; 𝜽) = 𝑃 𝒙; 𝜽 𝜕 log 𝑓 𝒙; 𝜽 𝜕𝜽 𝑑𝒙 = 𝐸 𝒙∼𝑃 𝒙;𝜽 𝜕 log 𝑓 𝒙; 𝜽 𝜕𝜽 この方向で 確かめられる 対数関数の微分 微分は積分の中へ 期待値の定義
42.
評価関数とその微分 41 𝜕𝑄 𝜏 𝜽 𝜕𝜽 =
𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) − 𝜕 𝜕𝜽 𝐸 𝒗 𝑛, 𝒉; 𝜽 − 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽) − 𝜕 𝜕𝜽 𝐸 𝒗, 𝒉; 𝜽 𝑃 𝒗, 𝒉; 𝜽 = 1 𝑍 𝜽 exp −𝐸 𝒗, 𝒉; 𝜽 𝑄 𝜏 𝜽 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) log 𝑃(𝒗 𝑛, 𝒉; 𝜽) 評価関数 v:visible layer {0,1} h:hidden layer {0,1} 𝐸 𝒗, 𝒉; 𝜽 = − 𝑖,𝑗 𝑣𝑖 𝑤𝑖𝑗ℎ𝑗 − 𝑗 𝑏𝑗ℎ𝑗 − 𝑖 𝑐𝑖 𝑣𝑖 = −𝒗 𝑇 𝑾𝒉 − 𝒃 𝑇 𝒉 − 𝒄 𝑇 𝒗 𝜕 𝜕𝑾 𝐸 𝒗, 𝒉; 𝜽 = −𝒗 𝑻 𝒉 𝜕𝑄 𝜏 𝜽 𝜏 𝜕𝑾 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) 𝒗 𝑛 𝑇 𝒉 − 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽 𝜏) 𝒗 𝑻 𝒉 𝜕𝑄 𝜏 𝜽 𝜏 𝜕𝜽 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) − 𝜕 𝜕𝜽 𝐸 𝒗 𝑛, 𝒉; 𝜽 − 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽 𝜏) − 𝜕 𝜕𝜽 𝐸 𝒗, 𝒉; 𝜽 データ項(計算容易) モデル項(計算困難) ギブスサンプリングで近似
43.
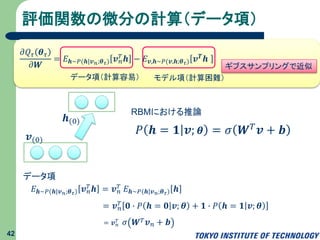
評価関数の微分の計算(データ項) 42 𝜕𝑄 𝜏 𝜽
𝜏 𝜕𝑾 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) 𝒗 𝑛 𝑇 𝒉 − 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽 𝜏) 𝒗 𝑻 𝒉 データ項(計算容易) モデル項(計算困難) ギブスサンプリングで近似 𝒗(0) 𝒉(0) 𝑃 𝒉 = 𝟏 𝒗; 𝜽 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 RBMにおける推論 データ項 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) 𝒗 𝑛 𝑇 𝒉 = 𝒗 𝑛 𝑇 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) 𝒉 = 𝒗 𝑛 𝑇 𝟎 ∙ 𝑃 𝒉 = 𝟎 𝒗; 𝜽 + 𝟏 ∙ 𝑃 𝒉 = 𝟏 𝒗; 𝜽 = 𝒗 𝑛 𝑇 𝜎 𝑾 𝑇 𝒗 𝑛 + 𝒃
44.
モンテカルロ法による近似期待値計算(モデル項) 43 𝜕𝑄 𝜏 𝜽
𝜏 𝜕𝑾 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) 𝒗 𝑛 𝑇 𝒉 − 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽 𝜏) 𝒗 𝑻 𝒉 データ項(計算容易) モデル項(計算困難) ギブスサンプリングで近似 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽 𝜏) 𝒗 𝑻 𝒉 ≑ 1 𝑁 𝑖 𝒗(𝑖) 𝑇 𝒉(𝑖) 𝒗(𝑖) 𝑇 , 𝒉(𝑖) ∼ 𝑃(𝒗, 𝒉; 𝜽 𝜏) 確率分布からの独立なサンプリング モンテカルロ法による近似期待値計算 どうやって,サンプリング? ギブスサンプリング
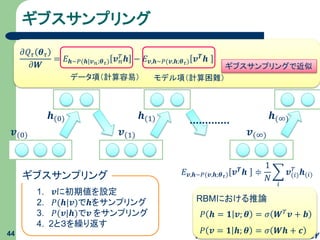
45.
ギブスサンプリング 44 𝒗(0) 𝒉(0) 𝑃 𝒉 =
𝟏 𝒗; 𝜽 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 RBMにおける推論 𝑃 𝒗 = 𝟏 𝒉; 𝜽 = 𝜎 𝑾𝒉 + 𝒄 𝒗(1) 𝒉(1) 𝒗(∞) 𝒉(∞) ギブスサンプリング 1. 𝒗に初期値を設定 2. 𝑃(𝒉|𝒗)で𝒉をサンプリング 3. 𝑃(𝒗|𝒉)で𝒗 をサンプリング 4. 2と3を繰り返す 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽 𝜏) 𝒗 𝑻 𝒉 ≑ 1 𝑁 𝑖 𝒗(𝑖) 𝑇 𝒉(𝑖) 𝜕𝑄 𝜏 𝜽 𝜏 𝜕𝑾 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) 𝒗 𝑛 𝑇 𝒉 − 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽 𝜏) 𝒗 𝑻 𝒉 データ項(計算容易) モデル項(計算困難) ギブスサンプリングで近似
46.
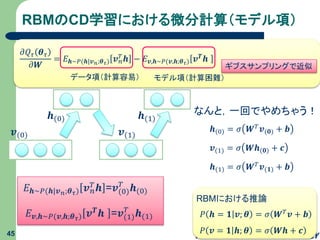
RBMのCD学習における微分計算(モデル項) 45 𝒗(0) 𝒉(0) 𝒗(1) 𝒉(1) なんと,一回でやめちゃう! 𝒉(0) = 𝜎
𝑾 𝑇 𝒗(𝟎) + 𝒃 𝑃 𝒉 = 𝟏 𝒗; 𝜽 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 RBMにおける推論 𝑃 𝒗 = 𝟏 𝒉; 𝜽 = 𝜎 𝑾𝒉 + 𝒄 𝒗(1) = 𝜎 𝑾𝒉(𝟎) + 𝒄 𝒉(1) = 𝜎 𝑾 𝑇 𝒗(𝟏) + 𝒃 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) 𝒗 𝑛 𝑇 𝒉 =𝒗(0) 𝑇 𝒉(0) 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽 𝜏) 𝒗 𝑻 𝒉 =𝒗(1) 𝑇 𝒉(1) 𝜕𝑄 𝜏 𝜽 𝜏 𝜕𝑾 = 𝐸 𝒉∼𝑃(𝒉|𝒗 𝑛;𝜽 𝜏) 𝒗 𝑛 𝑇 𝒉 − 𝐸 𝒗,𝒉∼𝑃(𝒗,𝒉;𝜽 𝜏) 𝒗 𝑻 𝒉 データ項(計算容易) モデル項(計算困難) ギブスサンプリングで近似
47.
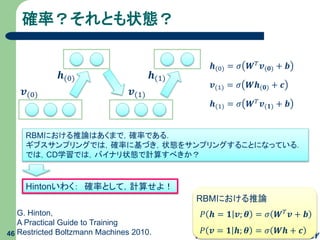
確率?それとも状態? 46 𝒗(0) 𝒉(0) 𝒗(1) 𝒉(1) 𝒉(0) = 𝜎
𝑾 𝑇 𝒗(𝟎) + 𝒃 𝒗(1) = 𝜎 𝑾𝒉(𝟎) + 𝒄 𝒉(1) = 𝜎 𝑾 𝑇 𝒗(𝟏) + 𝒃 𝑃 𝒉 = 𝟏 𝒗; 𝜽 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 RBMにおける推論 𝑃 𝒗 = 𝟏 𝒉; 𝜽 = 𝜎 𝑾𝒉 + 𝒄 G. Hinton, A Practical Guide to Training Restricted Boltzmann Machines 2010. RBMにおける推論はあくまで,確率である. ギブスサンプリングでは,確率に基づき,状態をサンプリングすることになっている. では,CD学習では,バイナリ状態で計算すべきか? Hintonいわく: 確率として,計算せよ!
48.
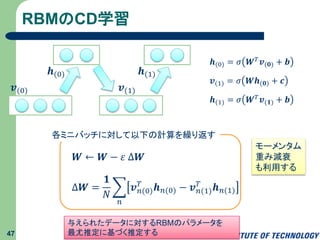
RBMのCD学習 47 𝒗(0) 𝒉(0) 𝒗(1) 𝒉(1) 𝒉(0) = 𝜎
𝑾 𝑇 𝒗(𝟎) + 𝒃 𝒗(1) = 𝜎 𝑾𝒉(𝟎) + 𝒄 𝒉(1) = 𝜎 𝑾 𝑇 𝒗(𝟏) + 𝒃 𝑾 ← 𝑾 − 𝜀 Δ𝑾 Δ𝑾 = 𝟏 𝑁 𝑛 𝒗 𝑛(0) 𝑇 𝒉 𝑛(0) − 𝒗 𝑛(1) 𝑇 𝒉 𝑛(1) 各ミニバッチに対して以下の計算を繰り返す 与えられたデータに対するRBMのパラメータを 最尤推定に基づく推定する モーメンタム 重み減衰 も利用する
49.
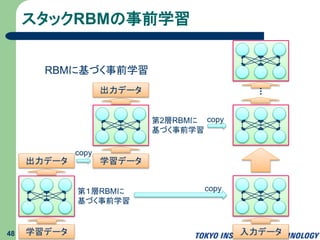
スタックRBMの事前学習 48 学習データ 出力データ 第1層RBMに 基づく事前学習 学習データ 出力データ 第2層RBMに 基づく事前学習 入力データ copy copy copy RBMに基づく事前学習
50.
概要 1. ディープラーニング 2. RBMからディープニューラルネットワーク 3.
ディープニューラルネットワーク – 誤差逆伝搬法(教師有学習) 4. RBM( Restricted Boltzmann Machine ) – RBMの基礎,確率モデル,推論モデル – CD法による事前学習(教師無学習) 5. 分布を考慮したNN推論 49
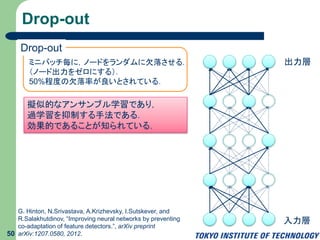
51.
Drop-out 50 擬似的なアンサンブル学習であり, 過学習を抑制する手法である. 効果的であることが知られている. Drop-out ミニバッチ毎に,ノードをランダムに欠落させる. (ノード出力をゼロにする). 50%程度の欠落率が良いとされている. G. Hinton, N.Srivastava,
A.Krizhevsky, I.Sutskever, and R.Salakhutdinov, “Improving neural networks by preventing co-adaptation of feature detectors.”, arXiv preprint arXiv:1207.0580, 2012. 入力層 出力層
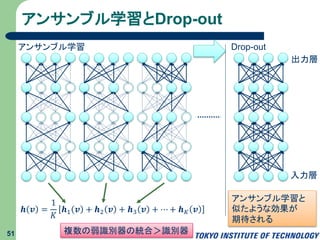
52.
アンサンブル学習とDrop-out 51 入力層 出力層 アンサンブル学習 Drop-out 複数の弱識別器の統合>識別器 𝒉 𝒗
= 1 𝐾 𝒉1 𝒗 + 𝒉2 𝒗 + 𝒉3 𝒗 + ⋯ + 𝒉 𝐾 𝒗 アンサンブル学習と 似たような効果が 期待される
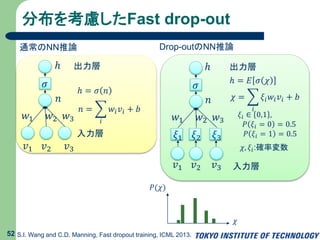
53.
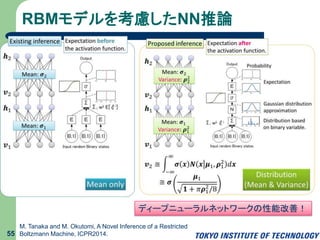
分布を考慮したFast drop-out 52 S.I.
Wang and C.D. Manning, Fast dropout training, ICML 2013. 入力層 𝑣1 𝑣2 𝑣3 ℎ 出力層 𝑤1 𝑤2 𝑤3 𝑛 𝜎 ℎ = 𝜎 𝑛 𝑛 = 𝑖 𝑤𝑖 𝑣𝑖 + 𝑏 𝑣1 𝑣2 𝑣3 ℎ 𝑤1 𝑤2 𝑤3 𝑛 𝜎 𝜉1 𝜉2 𝜉3 入力層 出力層 ℎ = 𝐸 𝜎 𝜒 𝜒 = 𝑖 𝜉𝑖 𝑤𝑖 𝑣𝑖 + 𝑏 𝜉𝑖 ∈ 0,1 , 𝑃 𝜉𝑖 = 0 = 0.5 𝑃 𝜉𝑖 = 1 = 0.5 𝜒, 𝜉𝑖:確率変数 通常のNN推論 Drop-outのNN推論 𝜒 𝑃(𝜒)
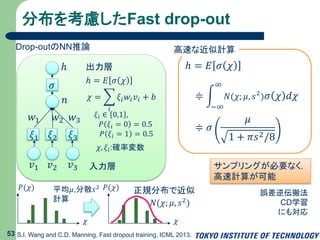
54.
分布を考慮したFast drop-out 53 S.I.
Wang and C.D. Manning, Fast dropout training, ICML 2013. 𝑣1 𝑣2 𝑣3 ℎ 𝑤1 𝑤2 𝑤3 𝑛 𝜎 𝜉1 𝜉2 𝜉3 入力層 出力層 ℎ = 𝐸 𝜎 𝜒 𝜒 = 𝑖 𝜉𝑖 𝑤𝑖 𝑣𝑖 + 𝑏 𝜉𝑖 ∈ 0,1 , 𝑃 𝜉𝑖 = 0 = 0.5 𝑃 𝜉𝑖 = 1 = 0.5 𝜒, 𝜉𝑖:確率変数 Drop-outのNN推論 𝜒 𝑃(𝜒) 𝜒 𝑃(𝜒) 正規分布で近似 𝑁(𝜒; 𝜇, 𝑠2 ) 平均𝜇,分散𝑠2 計算 ℎ = 𝐸 𝜎 𝜒 ≑ −∞ ∞ 𝑁(𝜒; 𝜇, 𝑠2 ) 𝜎 𝜒 𝑑𝜒 ≑ 𝜎 𝜇 1 + 𝜋𝑠2/8 高速な近似計算 サンプリングが必要なく, 高速計算が可能 誤差逆伝搬法 CD学習 にも対応
55.
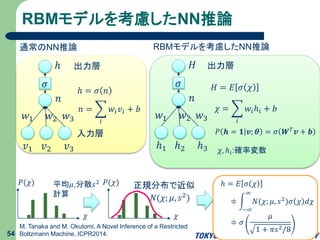
RBMモデルを考慮したNN推論 54 M. Tanaka and
M. Okutomi, A Novel Inference of a Restricted Boltzmann Machine, ICPR2014. 入力層 𝑣1 𝑣2 𝑣3 ℎ 出力層 𝑤1 𝑤2 𝑤3 𝑛 𝜎 ℎ = 𝜎 𝑛 𝑛 = 𝑖 𝑤𝑖 𝑣𝑖 + 𝑏 通常のNN推論 ℎ1 ℎ2 ℎ3 𝐻 出力層 𝑤1 𝑤2 𝑤3 𝑛 𝜎 𝐻 = 𝐸 𝜎 𝜒 𝜒 = 𝑖 𝑤𝑖ℎ𝑖 + 𝑏 RBMモデルを考慮したNN推論 𝑃 𝒉 = 𝟏 𝒗; 𝜽 = 𝜎 𝑾 𝑇 𝒗 + 𝒃 𝜒, ℎ𝑖:確率変数 𝜒 𝑃(𝜒) 𝜒 𝑃(𝜒) 正規分布で近似 𝑁(𝜒; 𝜇, 𝑠2) 平均𝜇,分散𝑠2 計算 ℎ = 𝐸 𝜎 𝜒 ≑ −∞ ∞ 𝑁(𝜒; 𝜇, 𝑠2 )𝜎 𝜒 𝑑𝜒 ≑ 𝜎 𝜇 1 + 𝜋𝑠2/8
56.
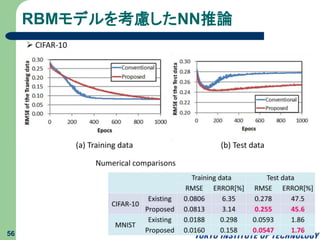
RBMモデルを考慮したNN推論 55 M. Tanaka and
M. Okutomi, A Novel Inference of a Restricted Boltzmann Machine, ICPR2014. ディープニューラルネットワークの性能改善!
57.
RBMモデルを考慮したNN推論 56
58.
概要 1. ディープラーニング 2. RBMからディープニューラルネットワーク 3.
ディープニューラルネットワーク – 誤差逆伝搬法(教師有学習) 4. RBM( Restricted Boltzmann Machine ) – RBMの基礎,確率モデル,推論モデル – CD法による事前学習(教師無学習) 5. 分布を考慮したNN推論 57 実行はできるけど中身はわからない. 理論的バックグランドがわかった! http://bit.ly/dnnicpr2014













































![[DL輪読会]大規模分散強化学習の難しい問題設定への適用](https://cdn.slidesharecdn.com/ss_thumbnails/drlapplication-180921001838-thumbnail.jpg?width=640&height=640&fit=bounds)










































