(The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition. Springer, 2009.)
















![3-2 :線形回帰モデルと最小二乗法.12
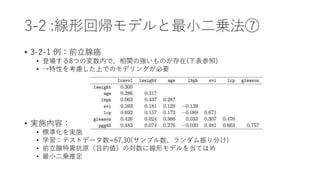
• θを推定する際の統計量 𝜃のMSEは
• 𝑀𝑆𝐸 𝜃 = 𝐸 𝜃 − 𝜃
2
= 𝑉𝑎𝑟 𝜃 + [𝐸 𝜃 − 𝜃 ]2
となる
• 第一項は分散、第二項はバイアスの二乗
• 最小二乗推定量はあらゆる線形の不偏推定量の中で最も小さい平均二乗誤差を持
つことが示されている
• 一方、より小さい平均二乗誤差を持つ不偏でない推定量が存在する可能性はある
(例:最小二乗係数の幾つかを縮小、あるいは0にする)
• そうしたケースにおいては少しのバイアス増加と引き換えに、分散を減少させる
(正則化等。現実世界のモデルは不偏でない推定を行うことが大半)
• 現実にはバイアス、バリアンスをバランスさせるものを選ぶ(7章にて)](https://image.slidesharecdn.com/random-170511024210/85/_3-18-320.jpg)

























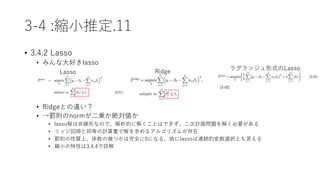









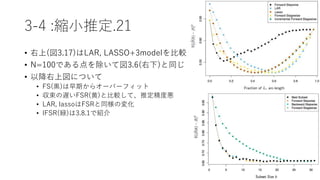








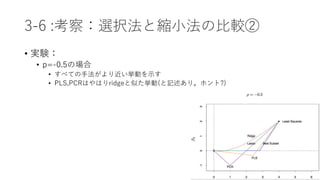


![3-8 :lassoと関連する解追跡アルゴリズム
に関する詳細①
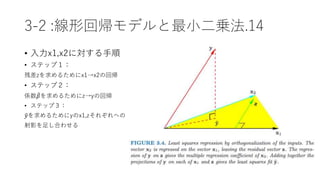
• 3.8.1 逐次前向き段階的回帰(IFSR)
• 16.2で詳解されるforward stagewise boostingの線形回帰ver
• 現在の残差と最も相関の高い変数の係数を少しずつ更新する
• 実際の動き:
• 1. 係数𝛽1 … 𝛽 𝑝 = 0、残差r = y、変数は全て標準化した状態からスタート
• 2. 残差rと最も相関の高い変数𝑥𝑗を見つける
• 3. 𝛽𝑗 ← 𝛽𝑗 + δ𝑗, 𝑟 ← 𝑟 − δ𝑗 𝑥𝑗 ここでδ𝑗 = 𝜖・𝑠𝑖𝑔𝑛[< 𝑥𝑗, 𝑟 >]、 𝜖 > 0は更新幅
• 4. ステップ2,3を残差、説明変数の相関がなくなるまで実施
※更新幅が残差に対する𝑗番目説明変数の最小二乗係数である場合、3.3.3FSと同一](https://image.slidesharecdn.com/random-170511024210/85/_3-69-320.jpg)


























![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)














![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)


















