Recommended
PDF
PPTX
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
PDF
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
PDF
PPTX
PPTX
PDF
トップカンファレンスへの論文採択に向けて(AI研究分野版)/ Toward paper acceptance at top conferences (AI...
PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
PDF
Tech-Circle #18 Pythonではじめる強化学習 OpenAI Gym 体験ハンズオン
PDF
PDF
PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
PDF
PPTX
PDF
PDF
PDF
PDF
PPTX
PPTX
PDF
PDF
クラシックな機械学習入門:付録:よく使う線形代数の公式
PDF
PDF
[DL輪読会]Control as Inferenceと発展
PPTX
Reinforcement Learning(方策改善定理)
PDF
PDF
More Related Content
PDF
PPTX
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
PDF
PPTX
強化学習の基礎と深層強化学習(東京大学 松尾研究室 深層強化学習サマースクール講義資料)
PDF
PPTX
PPTX
What's hot
PDF
トップカンファレンスへの論文採択に向けて(AI研究分野版)/ Toward paper acceptance at top conferences (AI...
PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
PDF
Tech-Circle #18 Pythonではじめる強化学習 OpenAI Gym 体験ハンズオン
PDF
PDF
PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
PDF
PPTX
PDF
PDF
PDF
PDF
PPTX
PPTX
PDF
PDF
クラシックな機械学習入門:付録:よく使う線形代数の公式
PDF
PDF
[DL輪読会]Control as Inferenceと発展
PPTX
Reinforcement Learning(方策改善定理)
Viewers also liked
PDF
PDF
PDF
ZIP
PDF
Pythonではじめる OpenAI Gymトレーニング
PDF
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料)
PDF
PDF
PPTX
NIPS2015読み会: Ladder Networks
PDF
PDF
機械学習プロフェッショナルシリーズ 深層学習 chapter3 確率的勾配降下法
PDF
Deep Learningと他の分類器をRで比べてみよう in Japan.R 2014
PDF
"Playing Atari with Deep Reinforcement Learning"
PDF
PDF
Icml2015 論文紹介 sparse_subspace_clustering_with_missing_entries
PPTX
Paper intoduction "Playing Atari with deep reinforcement learning"
PDF
Similar to 強化学習入門
PPTX
PPTX
最新の多様な深層強化学習モデルとその応用(第40回強化学習アーキテクチャ講演資料)
PDF
[Dl輪読会]introduction of reinforcement learning
PDF
PDF
PDF
NIPS KANSAI Reading Group #7: 逆強化学習の行動解析への応用
PDF
PPTX
PDF
分散型強化学習手法の最近の動向と分散計算フレームワークRayによる実装の試み
PDF
PDF
Reinforcement Learning: An Introduction 輪読会第1回資料
PDF
PDF
ICLR2018読み会@PFN 論文紹介:Intrinsic Motivation and Automatic Curricula via Asymmet...
PPTX
Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement ...
PDF
PPTX
PDF
Computational Motor Control: Reinforcement Learning (JAIST summer course)
KEY
LS for Reinforcement Learning
PDF
PPTX
More from Shunta Saito
KEY
PDF
Deep LearningフレームワークChainerと最近の技術動向
PDF
DeepPose: Human Pose Estimation via Deep Neural Networks
PDF
A brief introduction to recent segmentation methods
PDF
[unofficial] Pyramid Scene Parsing Network (CVPR 2017)
PDF
Building and road detection from large aerial imagery
PDF
[5 minutes LT] Brief Introduction to Recent Image Recognition Methods and Cha...
KEY
PDF
Building detection with decision fusion
PDF
PDF
Automatic selection of object recognition methods using reinforcement learning
PDF
Recently uploaded
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
PDF
PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
PPTX
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
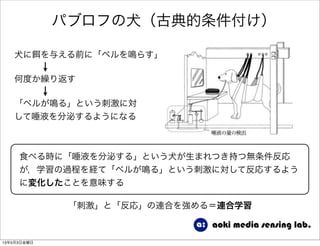
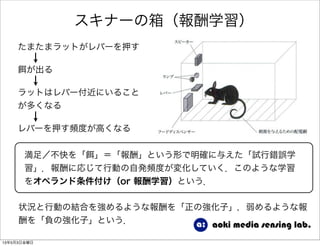
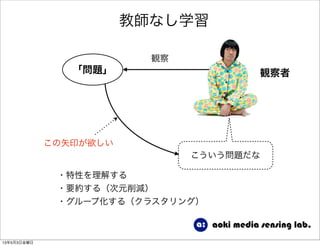
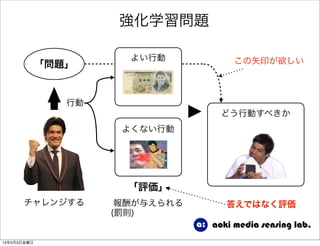
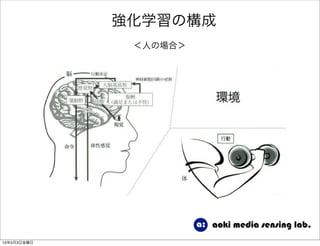
強化学習入門 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 強化学習の目的
E
" 1X
t=0
t
R(st, at, st+1)
#
, 8s0 2 S, 8a0 2 A目的関数
⇡⇤
(a|s) ⌘ arg max
⇡
E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
を最大にする政策関数が最適政策関数
つまり…
どうやって求めるか?
13年5月3日金曜日
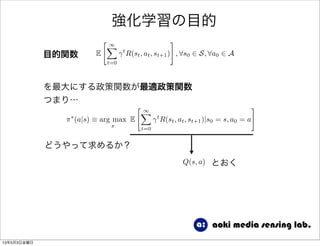
32. 強化学習の目的
E
" 1X
t=0
t
R(st, at, st+1)
#
, 8s0 2 S, 8a0 2 A目的関数
⇡⇤
(a|s) ⌘ arg max
⇡
E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
を最大にする政策関数が最適政策関数
つまり…
どうやって求めるか?
Q(s, a) とおく
13年5月3日金曜日
33. 強化学習の目的
E
" 1X
t=0
t
R(st, at, st+1)
#
, 8s0 2 S, 8a0 2 A目的関数
⇡⇤
(a|s) ⌘ arg max
⇡
E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
を最大にする政策関数が最適政策関数
つまり…
どうやって求めるか?
Q(s, a) とおく
Q(s, a) = E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
行動価値関数
13年5月3日金曜日
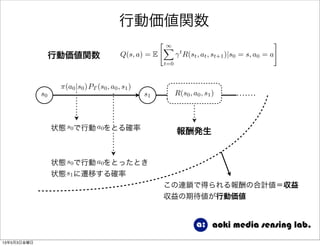
34. 行動価値関数
⇡(a0|s0)PT (s0, a0, s1)
s0 s1
状態 で行動 をとる確率s0 a0
状態 で行動 をとったとき
状態 に遷移する確率
s0 a0
s1
R(s0, a0, s1)
報酬発生
この連鎖で得られる報酬の合計値=収益
収益の期待値が行動価値
13年5月3日金曜日
35. 行動価値関数
Q(s, a) = E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
行動価値関数
⇡(a0|s0)PT (s0, a0, s1)
s0 s1
状態 で行動 をとる確率s0 a0
状態 で行動 をとったとき
状態 に遷移する確率
s0 a0
s1
R(s0, a0, s1)
報酬発生
この連鎖で得られる報酬の合計値=収益
収益の期待値が行動価値
13年5月3日金曜日
36. 行動価値関数と政策関数
⇡⇤
(a|s) ⌘ arg max
⇡
Q⇤
(s, a)
行動価値関数を最大にするような政策を知りたい強化学習の目的
1. 政策関数を適当に初期化(一様分布など)
2. 現在の政策に従って行動を起こし,報酬を観察
3. 現れた状態行動対 の価値を推定
4. 推定した を使って政策を改善
5. 1.に戻る
(s, a)
Q(s, a)
これを繰り返すことにより最適政策を近似する
13年5月3日金曜日
37. 行動価値関数と政策関数
⇡⇤
(a|s) ⌘ arg max
⇡
Q⇤
(s, a)
行動価値関数を最大にするような政策を知りたい強化学習の目的
1. 政策関数を適当に初期化(一様分布など)
2. 現在の政策に従って行動を起こし,報酬を観察
3. 現れた状態行動対 の価値を推定
4. 推定した を使って政策を改善
5. 1.に戻る
(s, a)
Q(s, a)
これを繰り返すことにより最適政策を近似する
疑問 3.の「状態行動対 の価値を推定」ってどうやる?(s, a)
4.の「推定した を使って政策を改善」ってどうやる?Q(s, a)
13年5月3日金曜日
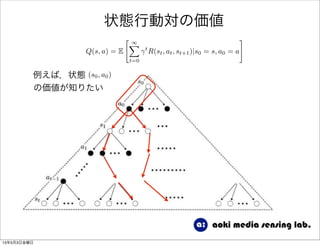
38. 状態行動対の価値
Q(s, a) = E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
例えば,状態 (s0, a0)
の価値が知りたい
13年5月3日金曜日
39. 状態行動対の価値
Q(s, a) = E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
例えば,状態 (s0, a0)
の価値が知りたい
13年5月3日金曜日
40. 状態行動対の価値
Q(s, a) = E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
例えば,状態 (s0, a0)
の価値が知りたい
13年5月3日金曜日
41. 状態行動対の価値
Q(s, a) = E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
例えば,状態 (s0, a0)
の価値が知りたい
色々なパスがあるが,
それらを全て考慮して
得られる報酬の期待値
を計算する必要がある
13年5月3日金曜日
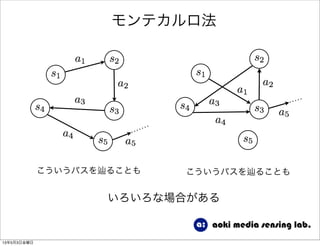
42. 状態行動対の価値
a1
s3
a4
s5
報酬の期待値(収益)は
左のようなパスを通った場合,
⇡(a0|s0)P(s0, a0, s1)R(s0, a0, s1)
+ ⇡(a1|s1)P(s1, a1, s3)R(s1, a1, s3)
+ 2
⇡(a4|s3)P(s3, a4, s5)R(s3, a4, s5)
Q⇡
(s, a) = E
" 1X
t=0
t
R(st, at, st+1)|s0 = s, a0 = a
#
これを 以降の全ての場合における
状態→行動選択確率(政策)と状態行動対
→次状態への遷移確率についての期待値を
計算すると がわかる
s0 ! a0
Q⇡(s0, a0)
さらにそれを全ての について計算す
る必要がある
(s, a)
13年5月3日金曜日
43. 44. 45. 46. 47. 48. 49. 50. 学習の流れ
⇡⇤
(a|s) ⌘ arg max
⇡
Q⇤
(s, a)
行動価値関数を最大にするような政策を知りたい強化学習の目的
1. 政策関数を適当に初期化(一様分布など)
2. 現在の政策に従って行動を起こし,報酬を観察
3. 現れた状態行動対 の価値を推定
4. 推定した を使って政策を改善
5. 1.に戻る
(s, a)
Q(s, a)
これを繰り返すことにより最適政策を近似する
疑問 3.の「状態行動対 の価値を推定」ってどうやる?(s, a)
4.の「推定した を使って政策を改善」ってどうやる?Q(s, a)
13年5月3日金曜日
51. 52. 準備
0 1 2
3 4 5
6 7 8
• 9マスある
• それぞれに ○ , , 空 の3状態
• 盤面ごとに状態番号をふると,3^9状態
13年5月3日金曜日
53. 準備
0 1 2
3 4 5
6 7 8
• 9マスある
• それぞれに ○ , , 空 の3状態
• 盤面ごとに状態番号をふると,3^9状態
_人人人人_
> 多い <
 ̄Y^Y^Y ̄
13年5月3日金曜日
54. 準備
0 1 2
3 4 5
6 7 8
• 9マスある
• それぞれに ○ , , 空 の3状態
• 盤面ごとに状態番号をふると,3^9状態
_人人人人_
> 多い <
 ̄Y^Y^Y ̄
0 1 2
3 4 5
6 7 8
左のように,45度回転の組み合わ
せで同じ状態に持っていけるものは
ひとつの状態として扱う
13年5月3日金曜日
55. 状態の圧縮
o x
x o
o
一つの状態を9ケタの3進数で表現する
0 ... 空
1 ... o
2 ... x
左の盤面は 120021100
ある状態が入力されてきたら,回転変換を施したものも含めた8状態
の3進数表現を計算する
8種類の3進数を10進数に変換する
8種類の10進数の値のうち一番小さいものを状態番号とする
1.
2.
3.
13年5月3日金曜日
56. 57. 58. 59. 60. 61. 62.

























![強化学習の目的
将来得られる報酬の総和が最大になるように政策を学習する
(発散しないように)割引率 を定義し,これを乗じた報酬を
将来に渡り加えた総和を収益とし,この期待値を最大化する!
E
" 1X
t=0
t
R(st, at, st+1)
#
, 8s0 2 S, 8a0 2 A目的関数
下記の目的関数を最大にする政策関数 を求める⇡
at ⇠ ⇡(at|st)
st+1 ⇠ PT (st+1|st, at)
st 2 S, at 2 A
2 (0, 1]
制約条件
A : ありうるすべての行動集合
S : ありうるすべての状態集合
13年5月3日金曜日](https://image.slidesharecdn.com/random-130502115820-phpapp02/85/slide-30-320.jpg)


































![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)

![[5 minutes LT] Brief Introduction to Recent Image Recognition Methods and Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/fashion-tech-2017-06-06-170626055616-thumbnail.jpg?width=640&height=640&fit=bounds)













