H2OのRパッケージ{h2o}のインストールは簡単
2014/12/6
21
> install.packages("h2o", + repos=(c("http://s3.amazonaws.com/h2o-release/h2o/master/1542/R", + getOption("repos"))))
> library("h2o", lib.loc="C:/Program Files/R/R-3.0.2/library")
要求されたパッケージ RCurl をロード中です
要求されたパッケージ bitops をロード中です
要求されたパッケージ rjson をロード中です
要求されたパッケージ statmod をロード中です
要求されたパッケージ survival をロード中です
要求されたパッケージ splines をロード中です
要求されたパッケージ tools をロード中です
----------------------------------------------------------------------
Your next step is to start H2O and get a connection object (named
'localH2O', for example): > localH2O = h2o.init()
For H2O package documentation, ask for help: > ??h2o
After starting H2O, you can use the Web UI at http://localhost:54321
For more information visit http://docs.0xdata.com
----------------------------------------------------------------------
# 以下略(これはWindows版のケースです)
23.
H2OインスタンスをRから立ち上げる
2014/12/6
22
> localH2O <- h2o.init(ip = "localhost", port = 54321, startH2O = TRUE, nthreads=-1)
H2O is not running yet, starting it now...
Note: In case of errors look at the following log files:
C:¥Users¥XXX¥AppData¥Local¥Temp¥RtmpghjvGo/h2o_XXX_win_started_from_r.out
C:¥Users¥XXX¥AppData¥Local¥Temp¥RtmpghjvGo/h2o_XXX_win_started_from_r.err
java version "1.7.0_67“
Java(TM) SE Runtime Environment (build 1.7.0_67-b01)
Java HotSpot(TM) 64-Bit Server VM (build 24.65-b04, mixed mode)
Successfully connected to http://localhost:54321
R is connected to H2O cluster:
H2O cluster uptime: 1 seconds 506 milliseconds
H2O cluster version: 2.7.0.1542
H2O cluster name: H2O_started_from_R
H2O cluster total nodes: 1
H2O cluster total memory: 7.10 GB
H2O cluster total cores: 8
H2O cluster allowed cores: 8
H2O cluster healthy: TRUE
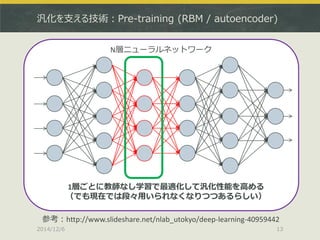
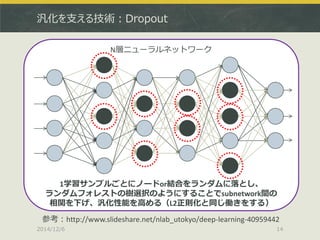
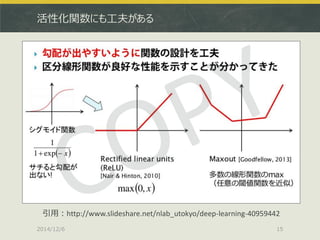
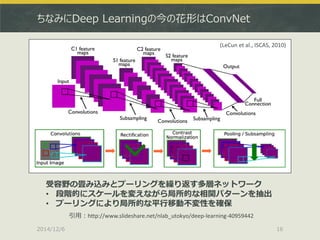
64bit推奨 (32bitだと警告が出る)







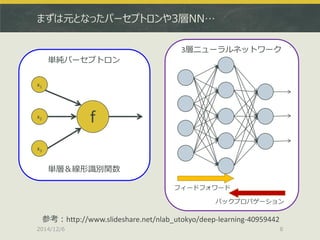





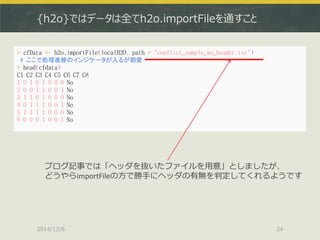
![h2o.deeplearning + Leave-one-outによる性能確認
2014/12/6
25
> res.err.dl<-rep(0,100)
# 判定結果を格納する空ベクトルを作る
> numlist<-sample(3000,100,replace=F)
# CVのためにどのインデックスから抜いてくるかをランダムに指定する
> for(i in 1:100){
+ cf.train <- cfData[-numlist[i],]
+ cf.test <- cfData[numlist[i],]
+ # 学習データとテストデータに分割
+ res.dl <- h2o.deeplearning(x = 1:7, y = 8, data = cf.train,
+ activation = "Tanh",hidden=rep(20,2))
+ pred.dl <- h2o.predict(object=res.dl,newdata=cf.test[,-8])
+ # Deep Learningによる学習と予測
+ pred.dl.df <- as.data.frame(pred.dl)
+ test.dl.df <- as.data.frame(cf.test)
+ # 予測結果の整形
+ res.err.dl[i] <- ifelse(as.character(pred.dl.df[1,1])
+ ==as.character(test.dl.df[1,8]),0,1)
+ # 結果の格納-正解なら0, 不正解なら1の値が入る
+ }
> sum(res.err.dl)
[1] 5 # この和が不正解の回数(100回中)
参考:http://www.albert2005.co.jp/analyst_blog/?p=1189](https://image.slidesharecdn.com/japanr2014tjo-141206010425-conversion-gate01/85/Deep-Learning-R-in-Japan-R-2014-26-320.jpg)
![h2o.deeplearning + Leave-one-outによる性能確認
2014/12/6
26
> res.err.dl<-rep(0,100)
# 判定結果を格納する空ベクトルを作る
> numlist<-sample(3000,100,replace=F)
# CVのためにどのインデックスから抜いてくるかをランダムに指定する
> for(i in 1:100){
+ cf.train <- cfData[-numlist[i],]
+ cf.test <- cfData[numlist[i],]
+ # 学習データとテストデータに分割
+ res.dl <- h2o.deeplearning(x = 1:7, y = 8, data = cf.train,
+ activation = "Tanh",hidden=rep(20,2))
+ pred.dl <- h2o.predict(object=res.dl,newdata=cf.test[,-8])
+ # Deep Learningによる学習と予測
+ pred.dl.df <- as.data.frame(pred.dl)
+ test.dl.df <- as.data.frame(cf.test)
+ # 予測結果の整形
+ res.err.dl[i] <- ifelse(as.character(pred.dl.df[1,1])
+ ==as.character(test.dl.df[1,8]),0,1)
+ # 結果の格納-正解なら0, 不正解なら1の値が入る
+ }
> sum(res.err.dl)
[1] 5 # この和が不正解の回数(100回中)](https://image.slidesharecdn.com/japanr2014tjo-141206010425-conversion-gate01/85/Deep-Learning-R-in-Japan-R-2014-27-320.jpg)


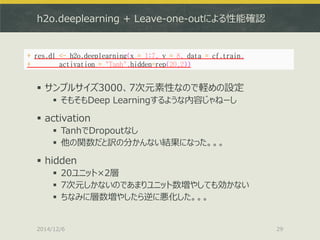
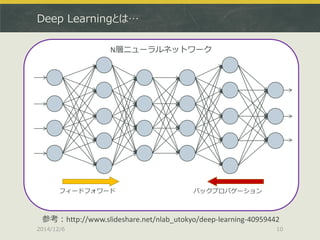
![h2o.deeplearning + Leave-one-outによる性能確認
2014/12/6
30
> res.err.dl<-rep(0,100)
# 判定結果を格納する空ベクトルを作る
> numlist<-sample(3000,100,replace=F)
# CVのためにどのインデックスから抜いてくるかをランダムに指定する
> for(i in 1:100){
+ cf.train <- cfData[-numlist[i],]
+ cf.test <- cfData[numlist[i],]
+ # 学習データとテストデータに分割
+ res.dl <- h2o.deeplearning(x = 1:7, y = 8, data = cf.train,
+ activation = "Tanh",hidden=rep(20,2))
+ pred.dl <- h2o.predict(object=res.dl,newdata=cf.test[,-8])
+ # Deep Learningによる学習と予測
+ pred.dl.df <- as.data.frame(pred.dl)
+ test.dl.df <- as.data.frame(cf.test)
+ # 予測結果の整形
+ res.err.dl[i] <- ifelse(as.character(pred.dl.df[1,1])
+ ==as.character(test.dl.df[1,8]),0,1)
+ # 結果の格納-正解なら0, 不正解なら1の値が入る
+ }
> sum(res.err.dl)
[1] 5 # この和が不正解の回数(100回中) 正答率95%
※100回CVに絞ったのはJava VMがOOMで落ちたため…](https://image.slidesharecdn.com/japanr2014tjo-141206010425-conversion-gate01/85/Deep-Learning-R-in-Japan-R-2014-31-320.jpg)
![ちなみにsvm{e1071}で同じことをやると…
2014/12/6
31
> library(e1071)
> d<-read.table("conflict_sample.txt", header=TRUE, quote="¥"")
> res.err.svm<-rep(0,100)
> numlist<-sample(3000,100,replace=F)
> for(i in 1:100){
+ cf.train <- d[-numlist[i],]
+ cf.test <- d[numlist[i],]
+ res.svm <- svm(cv~.,cf.train)
+ pred.svm <- predict(res.svm,newdata=cf.test[,-8])
+ res.err.svm[i] <- ifelse(pred.svm==cf.test[,8], 0, 1)
+ }
> sum(res.err.svm)
[1] 7 正答率93%
とりあえずSVMよりは優秀っぽい](https://image.slidesharecdn.com/japanr2014tjo-141206010425-conversion-gate01/85/Deep-Learning-R-in-Japan-R-2014-32-320.jpg)

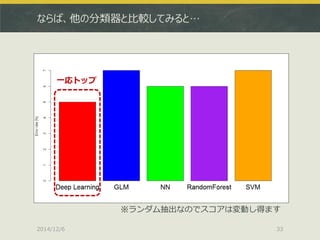

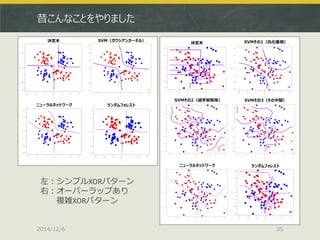
![同じことをh2o.deeplearningでやってみる
2014/12/6
36
> xorc <- read.table("xor_complex.txt", header=T)
> xors <- read.table("xor_simple.txt", header=T)
> library(h2o)
> localH2O <- h2o.init(ip = "localhost", port = 54321,
+ startH2O = TRUE, nthreads=-1)
> xorcData<-h2o.importFile(localH2O,path="xor_complex_wo_header.txt")
> xorsData<-h2o.importFile(localH2O,path="xor_simple_wo_header.txt")
> pgData<-h2o.importFile(localH2O,path="pgrid_wo_header.txt")
> res.dl<-h2o.deeplearning(x=1:2,y=3,data=xorsData,classification=T,
+ activation="Tanh",hidden=c(10,10),epochs=20)
> prd.dl<-h2o.predict(res.dl,newdata=pgData)
> prd.dl.df<-as.data.frame(prd.dl)
> plot(xors[,-3],pch=19,col=c(rep('blue',50),rep('red',50)),
+ cex=3,xlim=c(-4,4),ylim=c(-4,4), main="Tanh, (10,10)")
> par(new=T)
> contour(px,py,array(prd.dl.df[,1],dim=c(length(px),length(py))),
+ xlim=c(-4,4),ylim=c(-4,4),col="purple",lwd=3,drawlabels=F)
出典:http://tjo.hatenablog.com/entry/2014/11/07/190314](https://image.slidesharecdn.com/japanr2014tjo-141206010425-conversion-gate01/85/Deep-Learning-R-in-Japan-R-2014-37-320.jpg)


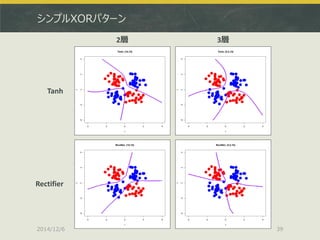
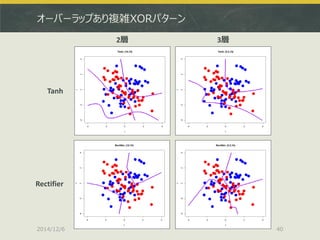
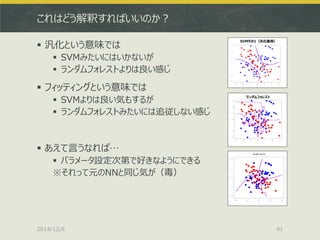


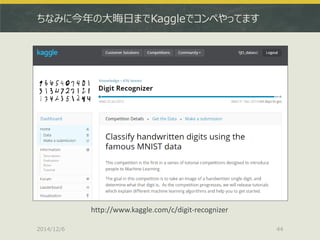
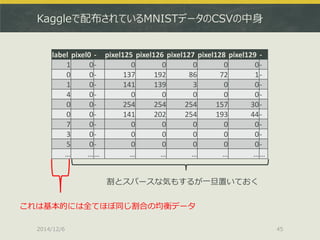
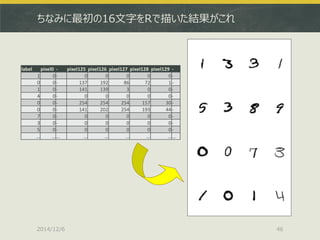

![2通りとりあえずやってみました
Kaggleコンペにそのまま参加する
http://www.kaggle.com/c/digit-recognizer/data
ちなみにベンチマークだと多分順位の半分もいきません
Kaggleの学習データを適当に自前で二分する
上記train.csvを持ってきて以下のような感じで分ける
2014/12/6
48
> dat<-read.csv("train.csv", header=TRUE)
> labels<-dat[,1]
> test_idx<-c()
> for (i in 1:10) {
+ tmp1<-which(labels==(i-1))
+ tmp2<-sample(tmp1,1000,replace=F)
+ test_idx<-c(test_idx,tmp2)
+ }
> test<-dat[test_idx,]
> train<-dat[-test_idx,]
> write.table(train,file="prac_train.csv",
+ quote=F,col.names=T,row.names=F,sep=",")
> write.table(test,file="prac_test.csv",
+ quote=F,col.names=T,row.names=F,sep=",")](https://image.slidesharecdn.com/japanr2014tjo-141206010425-conversion-gate01/85/Deep-Learning-R-in-Japan-R-2014-49-320.jpg)
![ベンチマークに指定されているのでランダムフォレストで試す
2014/12/6
49
> prac_train <- read.csv("prac_train.csv")
> prac_test <- read.csv("prac_test.csv")
> library(randomForest)
> prac_train$label<-as.factor(prac_train$label)
> prac.rf<-randomForest(label~.,prac_train)
> prd.rf<-predict(prac.rf,newdata=prac_test[,-1],type="response")
> sum(diag(table(test_labels,prd.rf)))
[1] 9658](https://image.slidesharecdn.com/japanr2014tjo-141206010425-conversion-gate01/85/Deep-Learning-R-in-Japan-R-2014-50-320.jpg)
![ベンチマークに指定されているのでランダムフォレストで試す
2014/12/6
50
> prac_train <- read.csv("prac_train.csv")
> prac_test <- read.csv("prac_test.csv")
> library(randomForest)
> prac_train$label<-as.factor(prac_train$label)
> prac.rf<-randomForest(label~.,prac_train)
> prd.rf<-predict(prac.rf,newdata=prac_test[,-1],type="response")
> sum(diag(table(test_labels,prd.rf)))
[1] 9658 正答率96.58%
ベンチマークの正答率
意外と高いんですが(白目](https://image.slidesharecdn.com/japanr2014tjo-141206010425-conversion-gate01/85/Deep-Learning-R-in-Japan-R-2014-51-320.jpg)
![h2o.deeplearningでのベストチューニング結果
2014/12/6
51
> library(h2o)
> localH2O <- h2o.init(ip = "localhost", port = 54321,
+ startH2O = TRUE, nthreads=-1)
> trData<-h2o.importFile(localH2O,path = "prac_train.csv")
> tsData<-h2o.importFile(localH2O,path = "prac_test.csv")
> res.dl <- h2o.deeplearning(x = 2:785, y = 1, data = trData,
+ activation = "RectifierWithDropout", hidden=c(1024,1024,2048),
+ epochs = 200, adaptive_rate = FALSE, rate=0.01,
+ rate_annealing = 1.0e-6, + rate_decay = 1.0, momentum_start = 0.5,
+ momentum_ramp = 42000*12, momentum_stable = 0.99, input_dropout_ratio = 0.2,
+ l1 = 1.0e-5,l2 = 0.0,max_w2 = 15.0, initial_weight_distribution = "Normal",
+ initial_weight_scale = 0.01, + nesterov_accelerated_gradient = T,
+ loss = "CrossEntropy", fast_mode = T, diagnostics = T,
+ ignore_const_cols = T, + force_load_balance = T)
> pred.dl<-h2o.predict(object=res.dl,newdata=tsData[,-1])
> pred.dl.df<-as.data.frame(pred.dl)
> sum(diag(table(test_labels,pred.dl.df[,1])))
[1] 9816 正答率98.16%
Kaggle本番でも98.3%](https://image.slidesharecdn.com/japanr2014tjo-141206010425-conversion-gate01/85/Deep-Learning-R-in-Japan-R-2014-52-320.jpg)

















![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)




























































