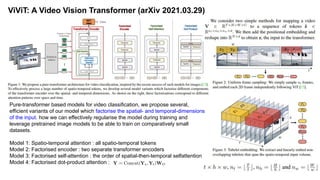
This document summarizes research on multiscale vision transformers (MViT). MViT builds on the transformer architecture by incorporating a multiscale pyramid of features, with early layers operating at high resolution to model low-level visual information and deeper layers focusing on coarse, complex features. MViT introduces multi-head pooling attention to operate at changing resolutions, and uses separate spatial and temporal embeddings. Experiments on Kinetics-400 and ImageNet show MViT achieves better accuracy than ViT baselines with fewer parameters and lower computational cost. Ablation studies validate design choices in MViT like input sampling and stage distribution.




















![Codes
# MViT options (/slowfast/config/defaults.py)
_C.MVIT = CfgNode()
_C.MVIT.PATCH_KERNEL = [3, 7, 7] _C.MVIT.PATCH_STRIDE = [2, 4, 4] _C.MVIT.PATCH_PADDING = [2, 4, 4]
_C.MVIT.EMBED_DIM = 96 _C.MVIT.MLP_RATIO = 4.0 _C.MVIT.DEPTH = 16 _C.MVIT.NORM = "layernorm"
# MViT options (/slowfast/models/video_model_builder.py)
@MODEL_REGISTRY.register()
class MViT(nn.Module):
if cfg.MVIT.NORM == "layernorm":
norm_layer = partial(nn.LayerNorm, eps=1e-6)
self.patch_dims = [
self.input_dims[i] // self.patch_stride[i]
for i in range(len(self.input_dims))
]
num_patches = math.prod(self.patch_dims)
dim_mul, head_mul = torch.ones(depth + 1), torch.ones(depth + 1)
for i in range(len(cfg.MVIT.DIM_MUL)):
dim_mul[cfg.MVIT.DIM_MUL[i][0]] = cfg.MVIT.DIM_MUL[i][1]
for i in range(len(cfg.MVIT.HEAD_MUL)):
head_mul[cfg.MVIT.HEAD_MUL[i][0]] = cfg.MVIT.HEAD_MUL[i][1]
https://github1s.com/facebookresearch/SlowFast/blob/master/slowfast/config/defaults.py](https://image.slidesharecdn.com/papermultiscalevisiontransformers-210808092058/85/Paper-Multiscale-Vision-Transformers-MVit-23-320.jpg)
![Codes
for i in range(len(cfg.MVIT.POOL_Q_STRIDE)):
for i in range(len(cfg.MVIT.POOL_KV_STRIDE)):
for i in range(depth):
num_heads = round_width(num_heads, head_mul[i])
embed_dim = round_width(embed_dim, dim_mul[i], divisor=num_heads)
dim_out = round_width( embed_dim, dim_mul[i + 1],
divisor=round_width(num_heads, head_mul[i + 1]),
)
self.blocks.append(
MultiScaleBlock(
dim=embed_dim, dim_out=dim_out, num_heads=num_heads, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, drop_rate=self.drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
kernel_q=pool_q[i] if len(pool_q) > i else [],
kernel_kv=pool_kv[i] if len(pool_kv) > i else [],
stride_q=stride_q[i] if len(stride_q) > i else [],
stride_kv=stride_kv[i] if len(stride_kv) > i else [],
mode=mode, has_cls_embed=self.cls_embed_on, pool_first=pool_first,
)
)
https://github1s.com/facebookresearch/SlowFast/blob/master/slowfast/models/video_model_builder.py](https://image.slidesharecdn.com/papermultiscalevisiontransformers-210808092058/85/Paper-Multiscale-Vision-Transformers-MVit-24-320.jpg)





![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)











































![[Paper] attention mechanism(luong)](https://cdn.slidesharecdn.com/ss_thumbnails/paperattentionmechanismluong-210508090926-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] GIRAFFE: Representing Scenes as Compositional Generative Neural Featu...](https://cdn.slidesharecdn.com/ss_thumbnails/papergirafferepresentingscenesascompositionalgenerativeneuralfeaturefields-210823043723-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Paper] eXplainable ai(xai) in computer vision](https://cdn.slidesharecdn.com/ss_thumbnails/paperexplainableaixaiincomputervision-210411093712-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Paper] DetectoRS for Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/paperdetectorsobjectdetection-210320013551-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] anti spoofing for face recognition](https://cdn.slidesharecdn.com/ss_thumbnails/paperanti-spoofingforfacerecognition-210508093958-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Paper] auto ml part 1](https://cdn.slidesharecdn.com/ss_thumbnails/paperautomlpart1-210413122952-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Paper] dynamic routing between capsules](https://cdn.slidesharecdn.com/ss_thumbnails/paperdynamicroutingbetweencapsules-210509101120-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Paper] learning video representations from correspondence proposals](https://cdn.slidesharecdn.com/ss_thumbnails/paperlearningvideorepresentationsfromcorrespondenceproposals-210410235049-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] shuffle net an extremely efficient convolutional neural network for ...](https://cdn.slidesharecdn.com/ss_thumbnails/papershufflenetanextremelyefficientconvolutionalneuralnetworkformobiledevices-210424000132-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] EDA : easy data augmentation techniques for boosting performance on t...](https://cdn.slidesharecdn.com/ss_thumbnails/paperedaeasydataaugmentationtechniquesforboostingperformanceontextclassificationtasks-210414133327-thumbnail.jpg?width=640&height=640&fit=bounds)



















