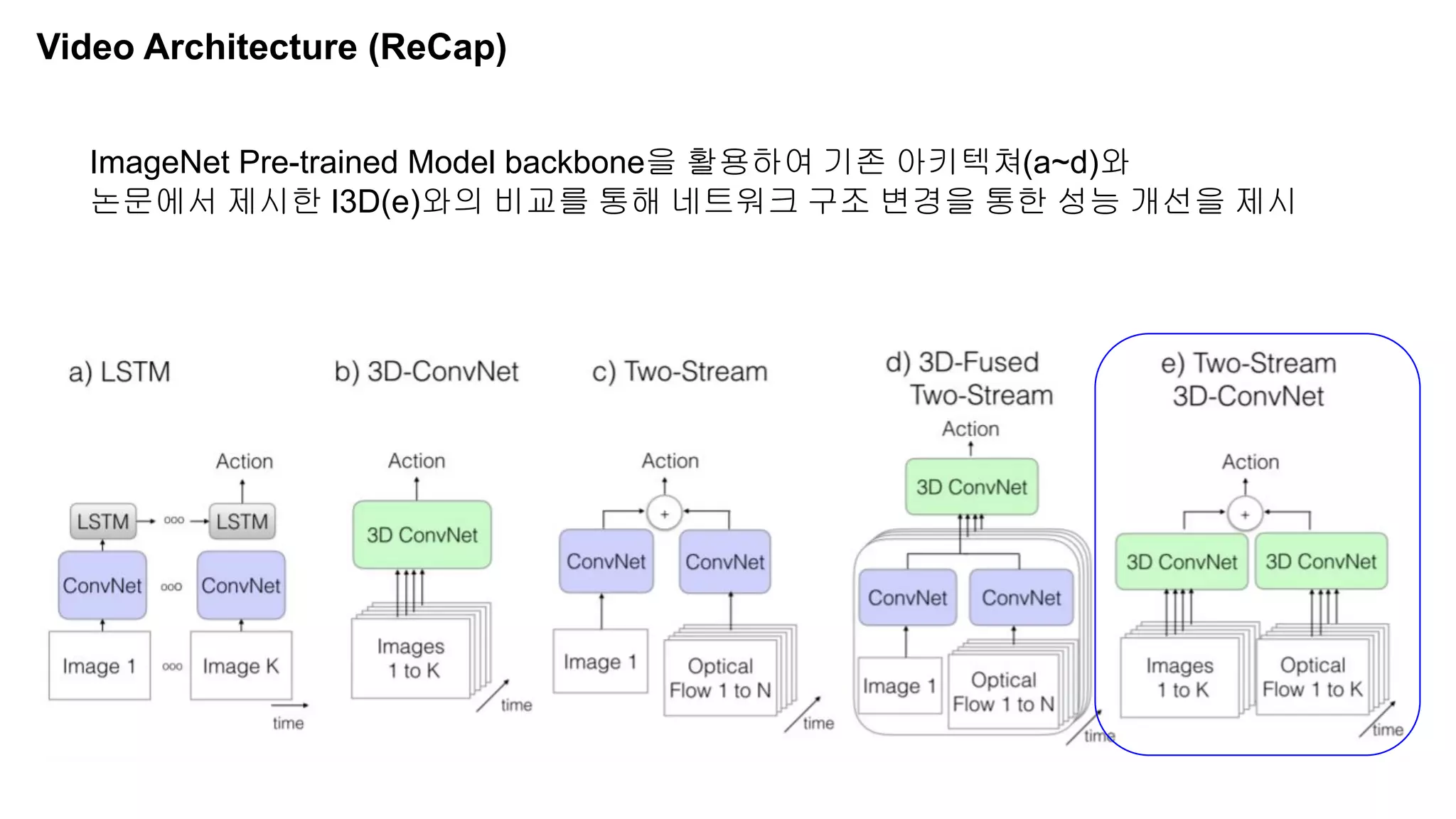
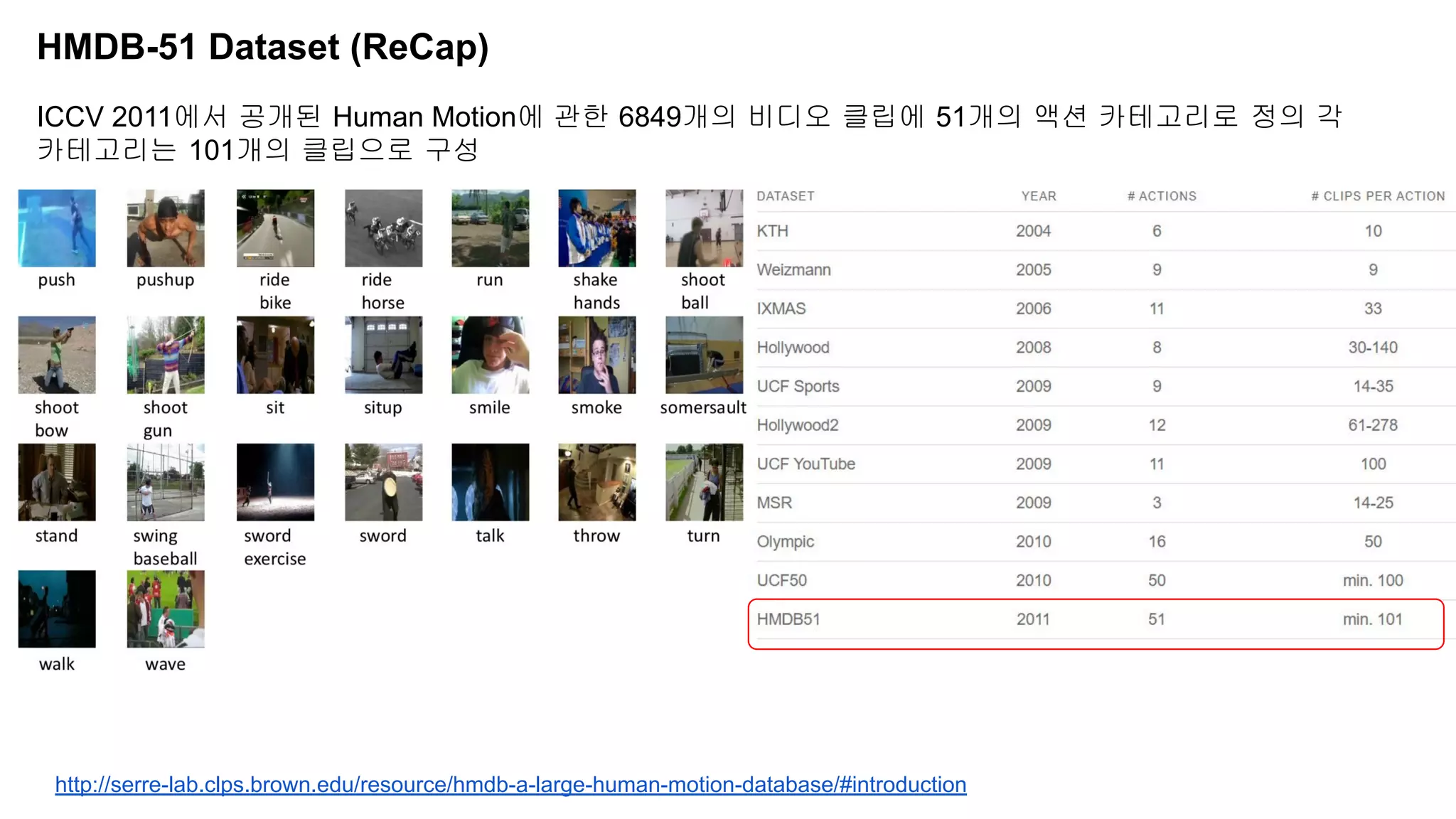
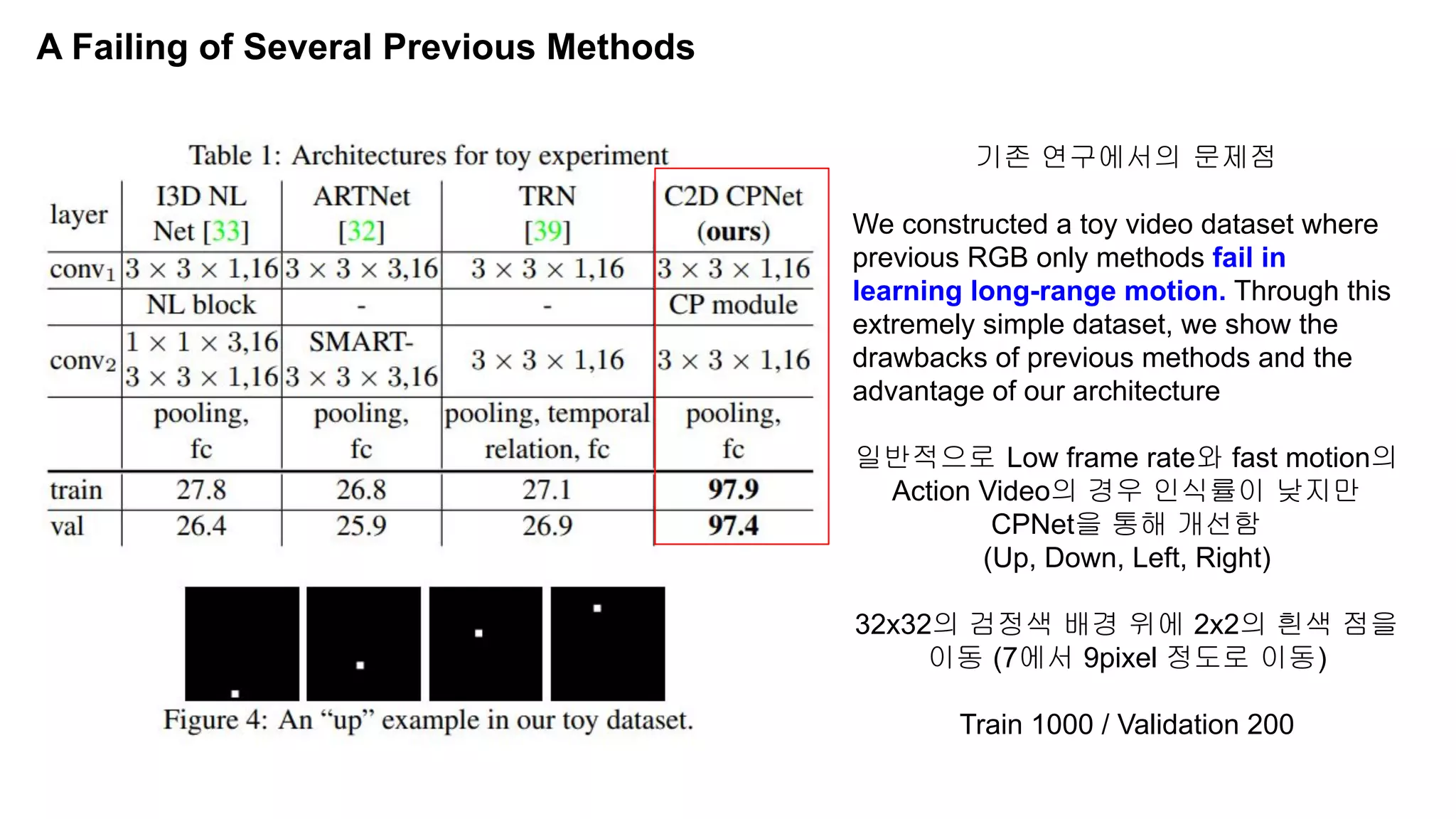
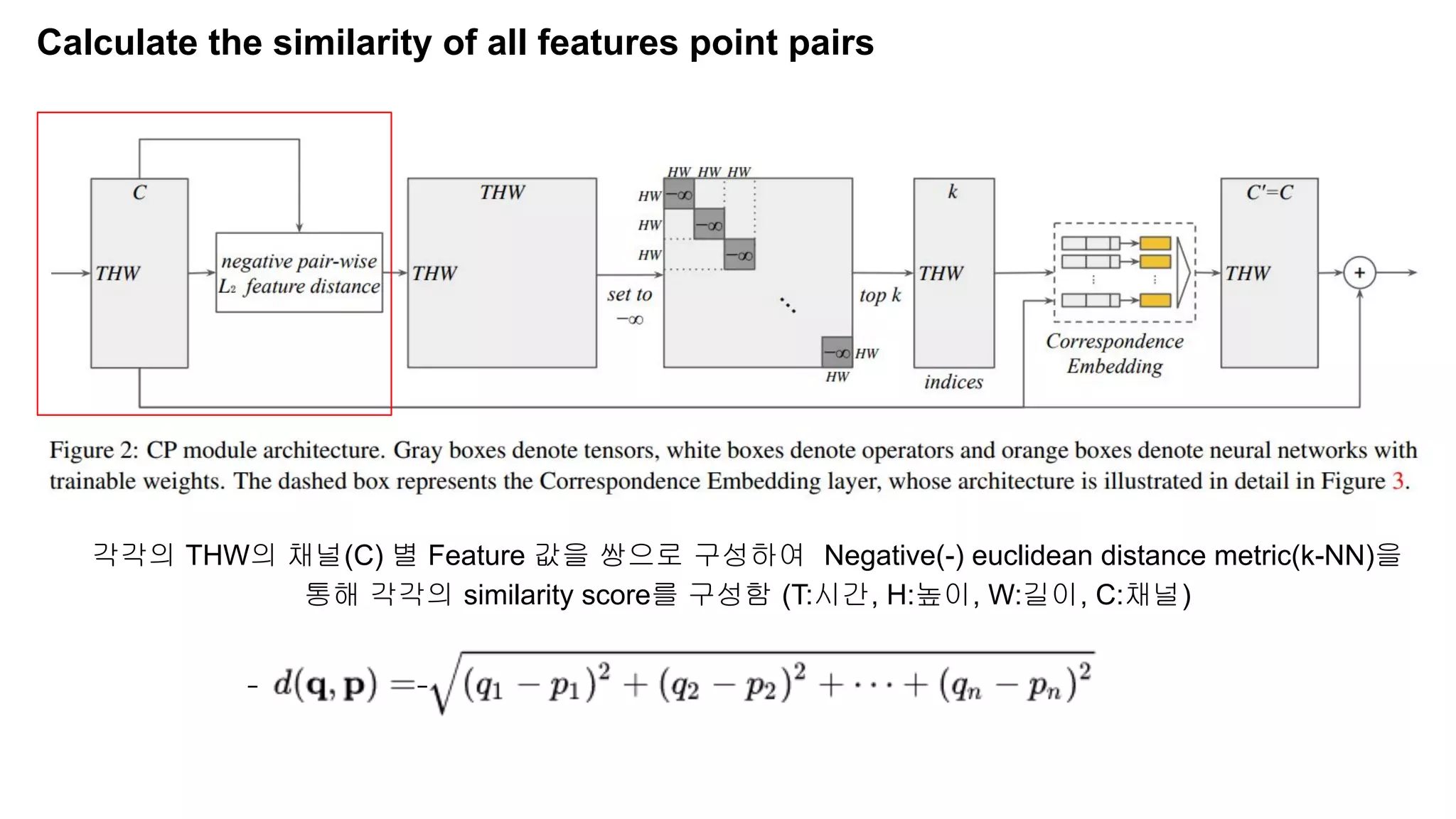
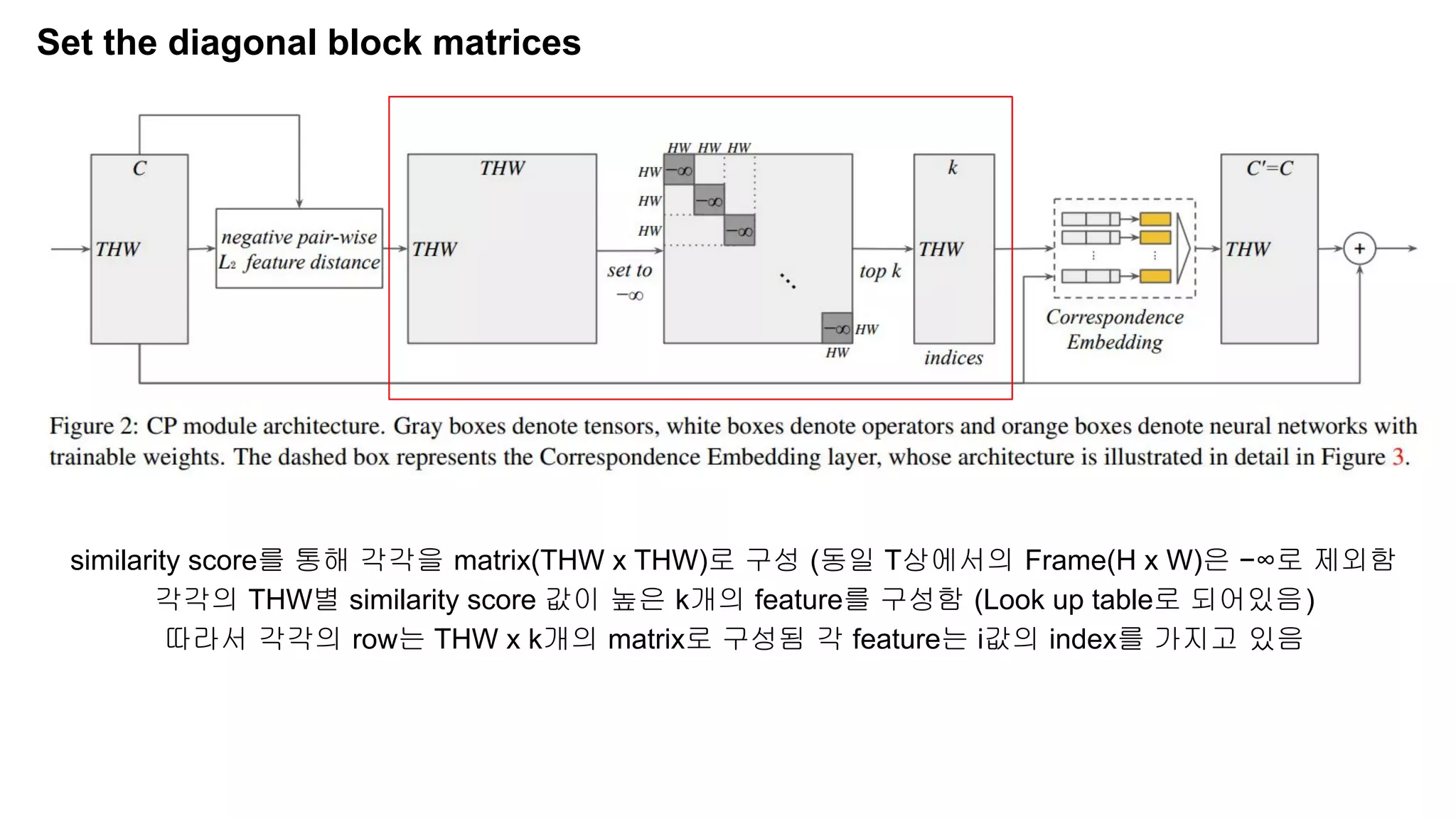
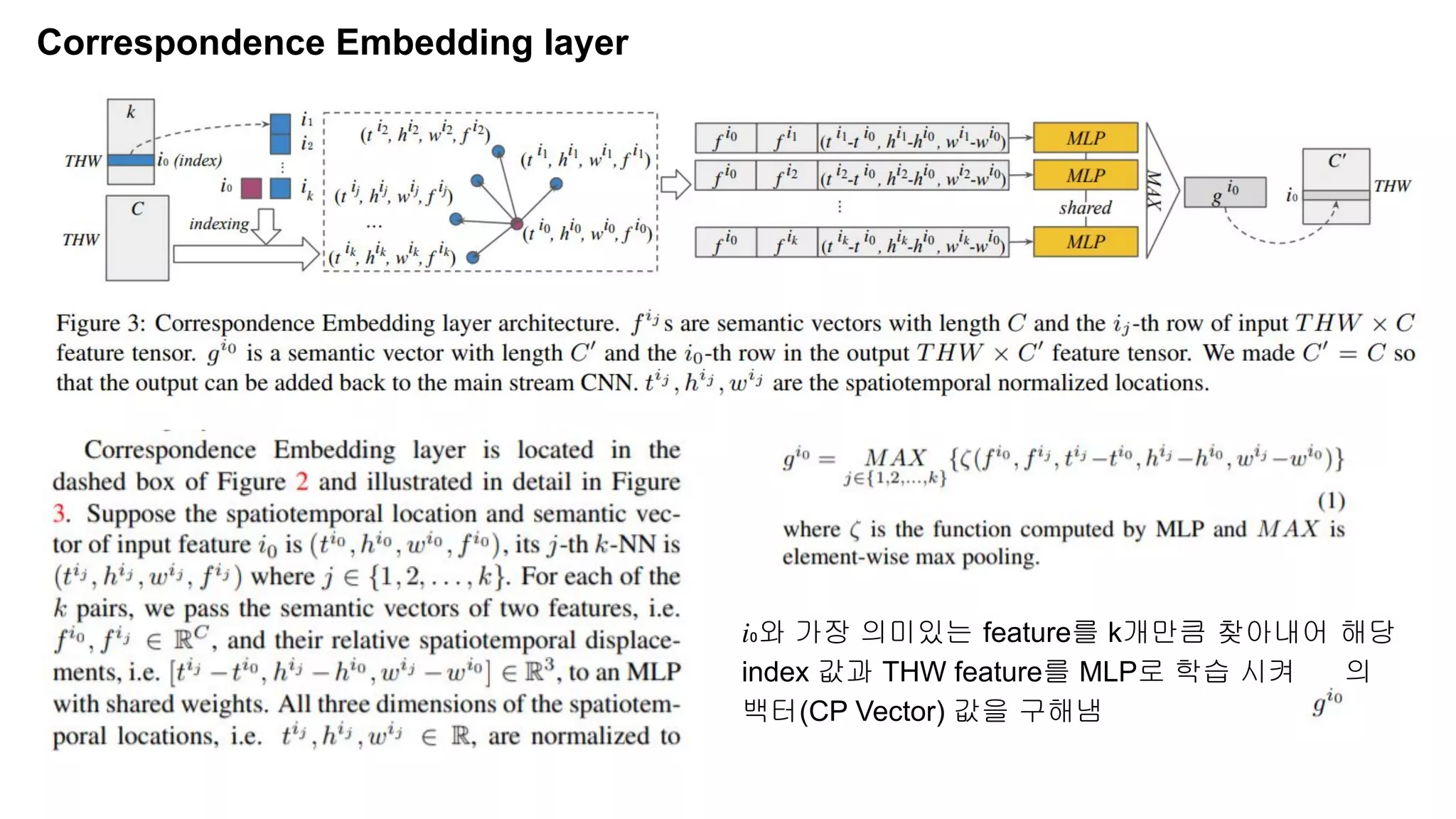
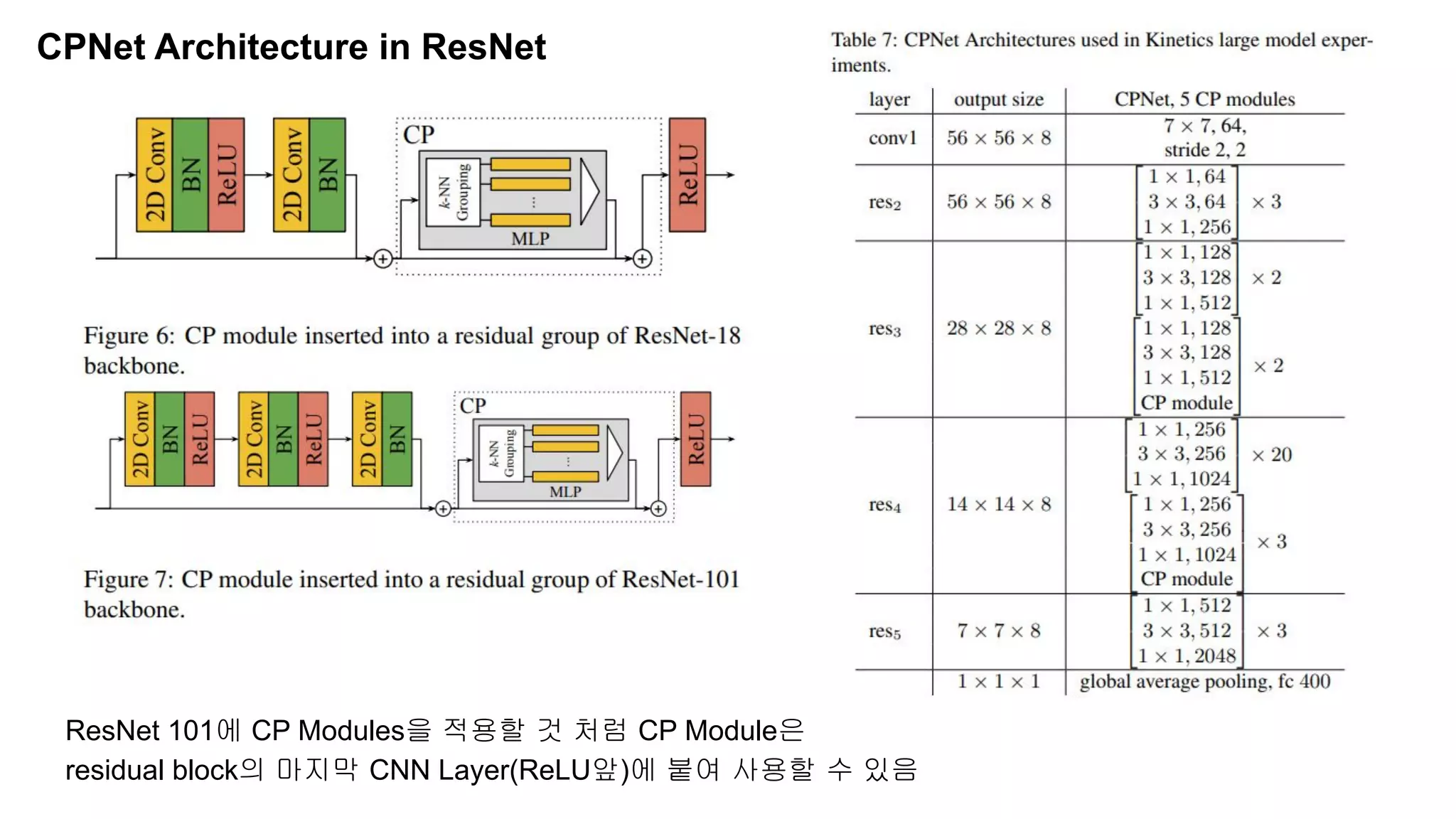
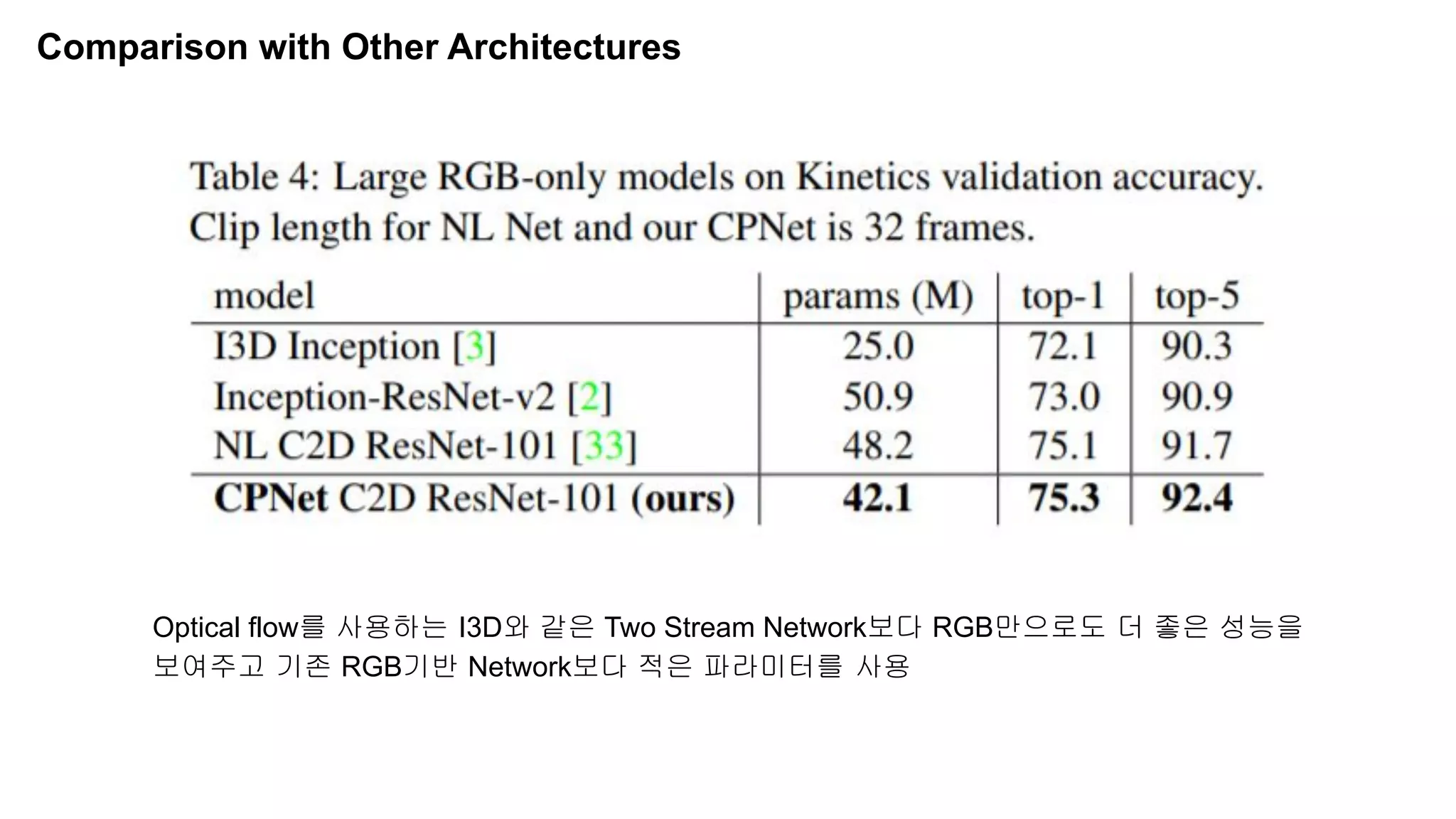
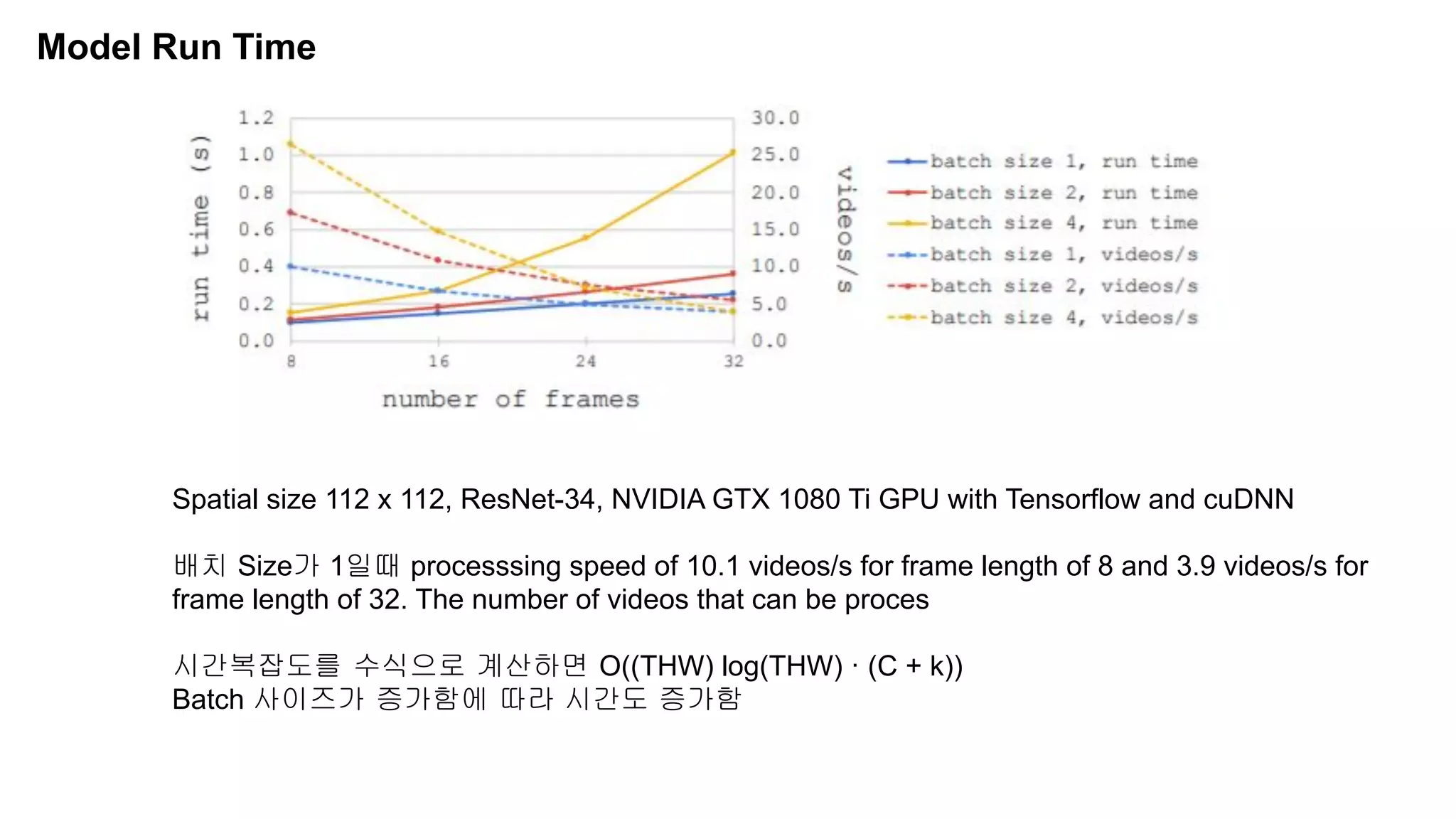
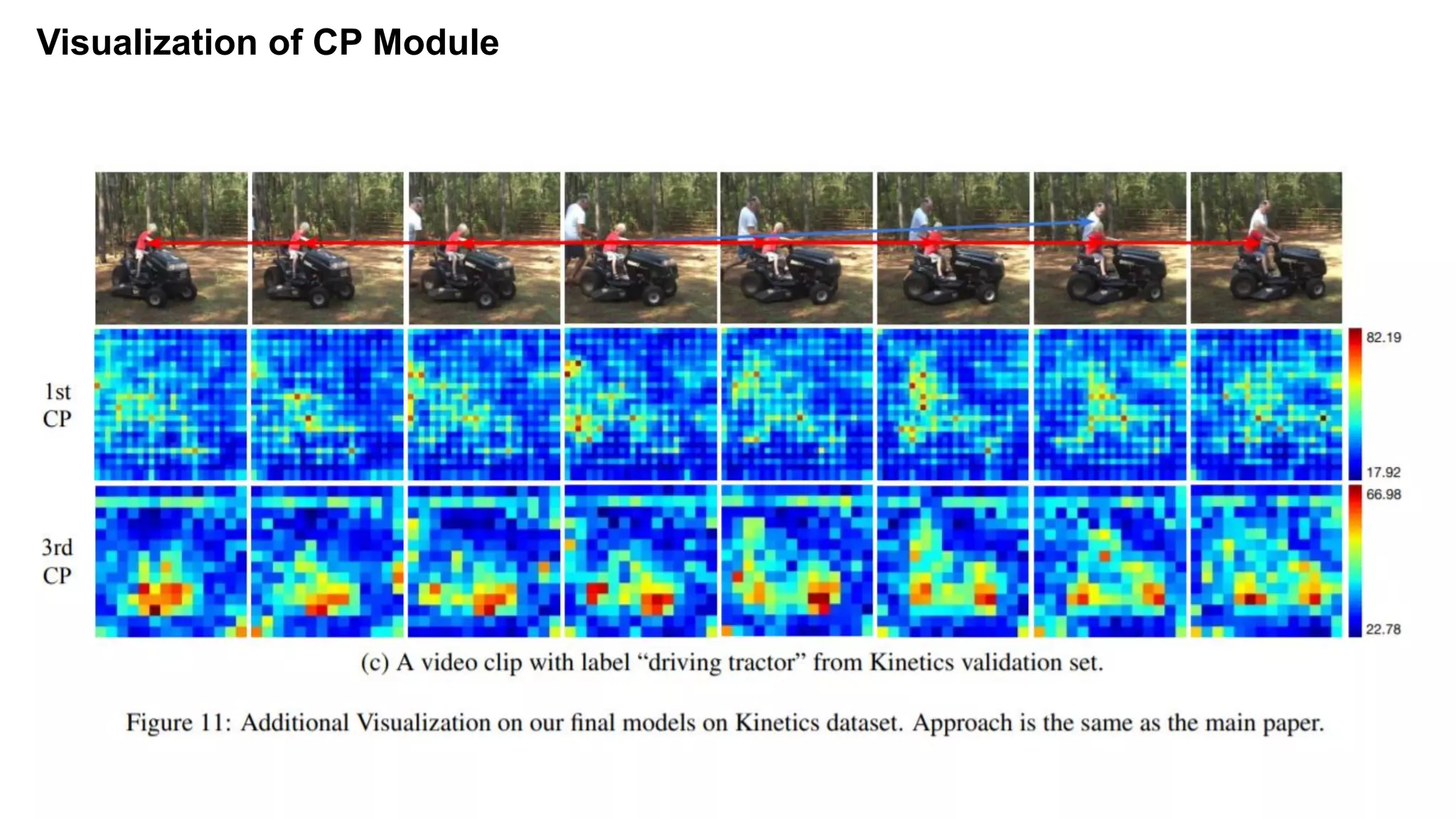
The document discusses advancements in video understanding through action recognition using deep learning techniques, particularly highlighting the use of the Kinetics dataset and a correspondence proposals module (CPNet). It compares traditional RGB-based methods with the proposed architecture that improves long-range motion recognition and achieves state-of-the-art results. Furthermore, it details the architecture and implementation aspects, including performance metrics and processing speeds on various computing setups.






![CP Modules Codes
nn_idx = knn.knn(net, k, new_height * new_width)
net_expand = tf.tile(tf.expand_dims(net, axis=2), [1,1,k,1])
net_grouped = tf_grouping.group_point(net, nn_idx)
coord = get_coord(tf.reshape(video, [batch_size, -1, new_height, new_width,
num_channels_bottleneck]))
coord_expand = tf.tile(tf.expand_dims(coord, axis=2), [1,1,k,1])
coord_grouped = tf_grouping.group_point(coord, nn_idx)
coord_diff = coord_grouped - coord_expand
end_points['coord'] = {'coord': coord, 'coord_grouped': coord_grouped, 'coord_diff':
coord_diff}
net = tf.concat([coord_diff, net_expand, net_grouped], axis=-1)
with tf.variable_scope(scope) as sc:
for i, num_out_channel in enumerate(mlp):
net = tf_util.conv2d(net, num_out_channel, [1,1], padding='VALID',
stride=[1,1], bn=True, is_training=is_training,
scope='conv%d'%(i), bn_decay=bn_decay, weight_decay=weight_decay,
data_format=data_format, freeze_bn=freeze_bn)
end_points['before_max'] = net
net = tf.reduce_max(net, axis=[2], keepdims=True, name='maxpool')
end_points['after_max'] = net
net = tf.reshape(net, [batch_size, num_frames, new_height, new_width, lp[-1]])
with tf.variable_scope(scope) as sc:
net = tf_util.conv3d(net, num_channels, [1, 1, 1], stride=[1, 1, 1],
bn=False, activation_fn=None, weight_decay=weight_decay, scope='conv_final')
net = tf.contrib.layers.batch_norm(net, center=True, scale=True,
is_training=is_training if not freeze_bn else tf.constant(False,
shape=(), dtype=tf.bool), decay=bn_decay, updates_collections=None,
scope='bn_final', data_format=data_format, param_initializers={'gamma':
tf.constant_initializer(0., dtype=tf.float32)}, trainable=not freeze_bn)
return net, end_points
def cp_module(video, k, mlp, scope, mlp0=None, is_training=None, bn_decay=None, weight_decay=None, data_format='NHWC',
distance='l2', activation_fn=None, shrink_ratio=None, freeze_bn=False):](https://image.slidesharecdn.com/paperlearningvideorepresentationsfromcorrespondenceproposals-210410235049/75/Paper-learning-video-representations-from-correspondence-proposals-13-2048.jpg)




![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Review] BoxInst: High-Performance Instance Segmentation with Box Annotations...](https://cdn.slidesharecdn.com/ss_thumbnails/boxinstreviewcdm-210627063153-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[신경망기초] 합성곱신경망](https://cdn.slidesharecdn.com/ss_thumbnails/2-180604135842-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[Paper] GIRAFFE: Representing Scenes as Compositional Generative Neural Featu...](https://cdn.slidesharecdn.com/ss_thumbnails/papergirafferepresentingscenesascompositionalgenerativeneuralfeaturefields-210823043723-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] dynamic routing between capsules](https://cdn.slidesharecdn.com/ss_thumbnails/paperdynamicroutingbetweencapsules-210509101120-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] anti spoofing for face recognition](https://cdn.slidesharecdn.com/ss_thumbnails/paperanti-spoofingforfacerecognition-210508093958-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] attention mechanism(luong)](https://cdn.slidesharecdn.com/ss_thumbnails/paperattentionmechanismluong-210508090926-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] shuffle net an extremely efficient convolutional neural network for ...](https://cdn.slidesharecdn.com/ss_thumbnails/papershufflenetanextremelyefficientconvolutionalneuralnetworkformobiledevices-210424000132-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] EDA : easy data augmentation techniques for boosting performance on t...](https://cdn.slidesharecdn.com/ss_thumbnails/paperedaeasydataaugmentationtechniquesforboostingperformanceontextclassificationtasks-210414133327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] auto ml part 1](https://cdn.slidesharecdn.com/ss_thumbnails/paperautomlpart1-210413122952-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] eXplainable ai(xai) in computer vision](https://cdn.slidesharecdn.com/ss_thumbnails/paperexplainableaixaiincomputervision-210411093712-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] DetectoRS for Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/paperdetectorsobjectdetection-210320013551-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)







