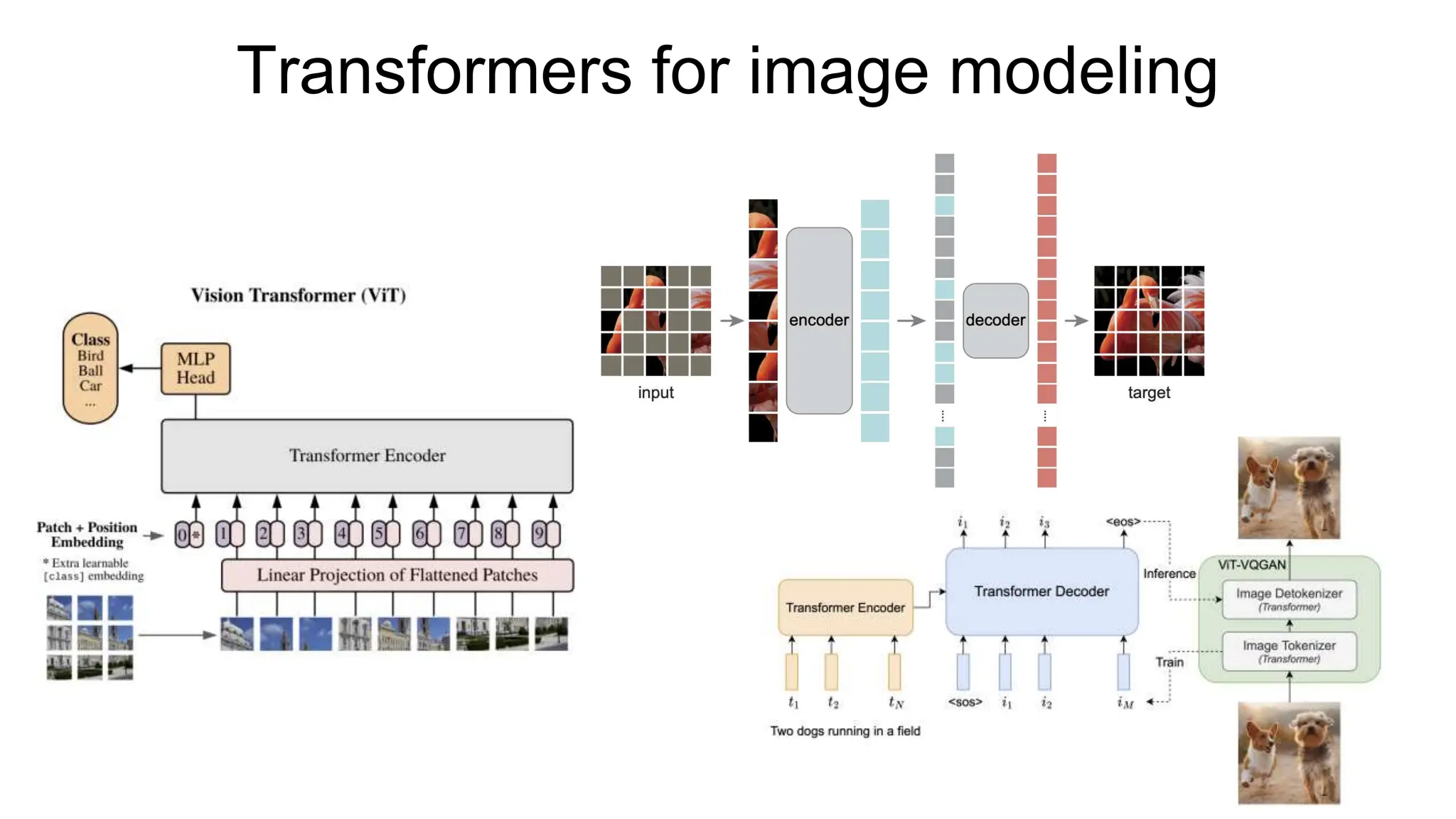
The document discusses the application of transformers in vision tasks, outlining various architectures and self-supervised learning methods. It critiques previous approaches to image modeling using self-attention, their complexities, and results that often do not justify their use over convolutional networks. Additionally, it introduces methods like Vision Transformer (ViT) and Swin Transformer, highlighting advancements in efficiency and new self-supervised techniques like DINO and masked autoencoders.




























![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[DSC Europe 23] Ivan Biliskov - Seeing Through the Lens of Transformers: A Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/ivanbiliskov-cvvisiontransformers-231129094209-d32f1292-thumbnail.jpg?width=640&height=640&fit=bounds)



















