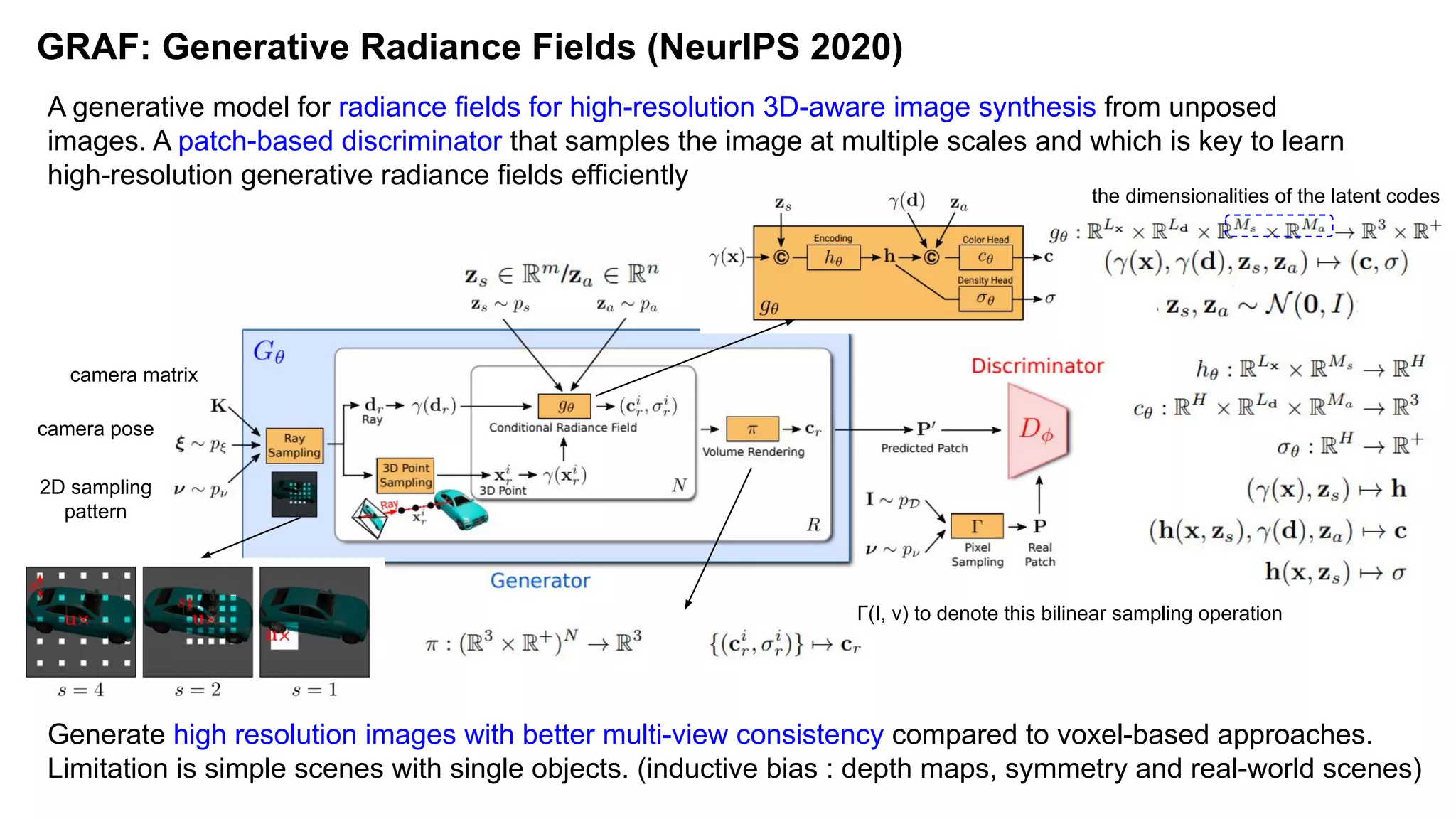
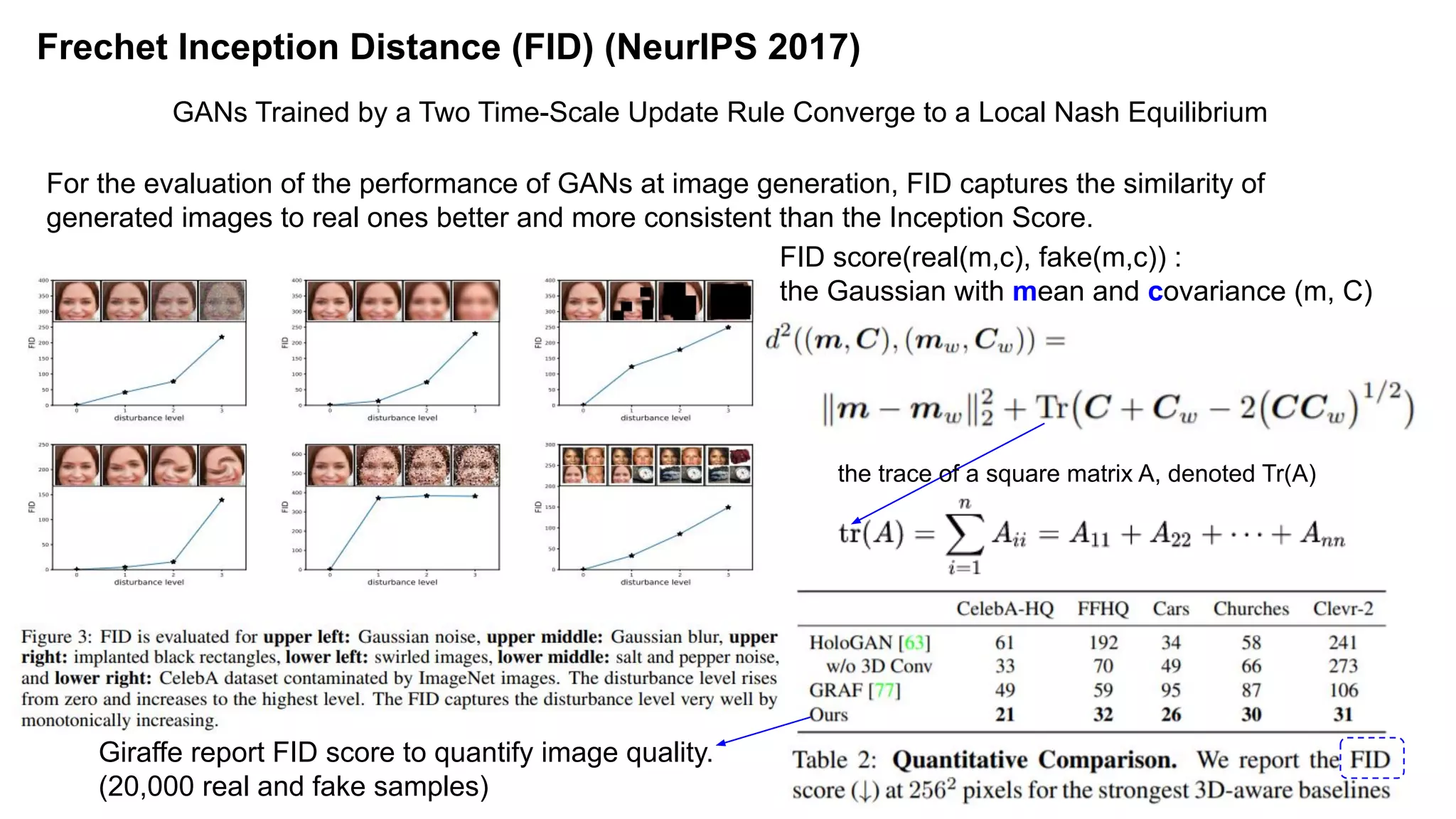
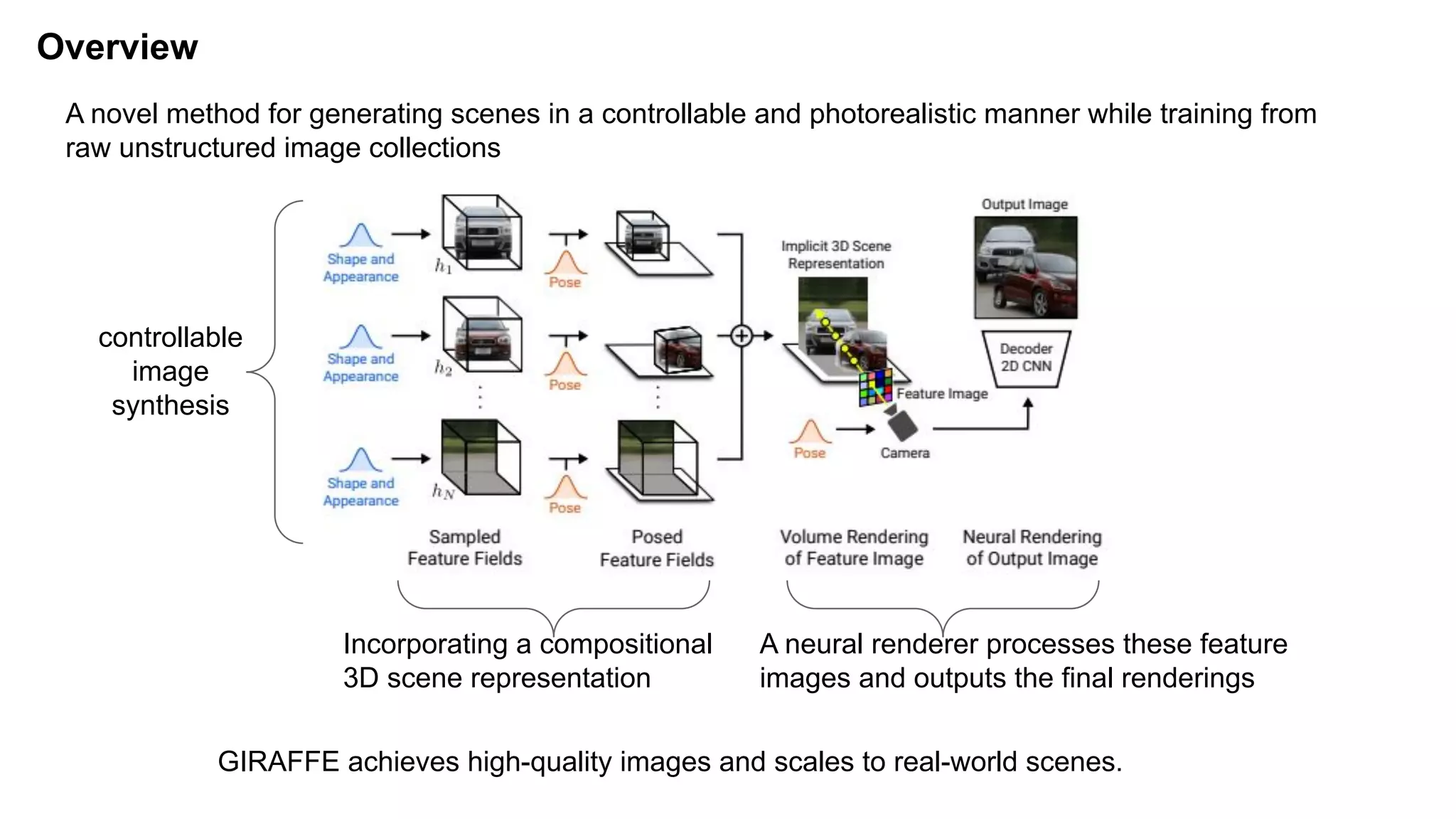
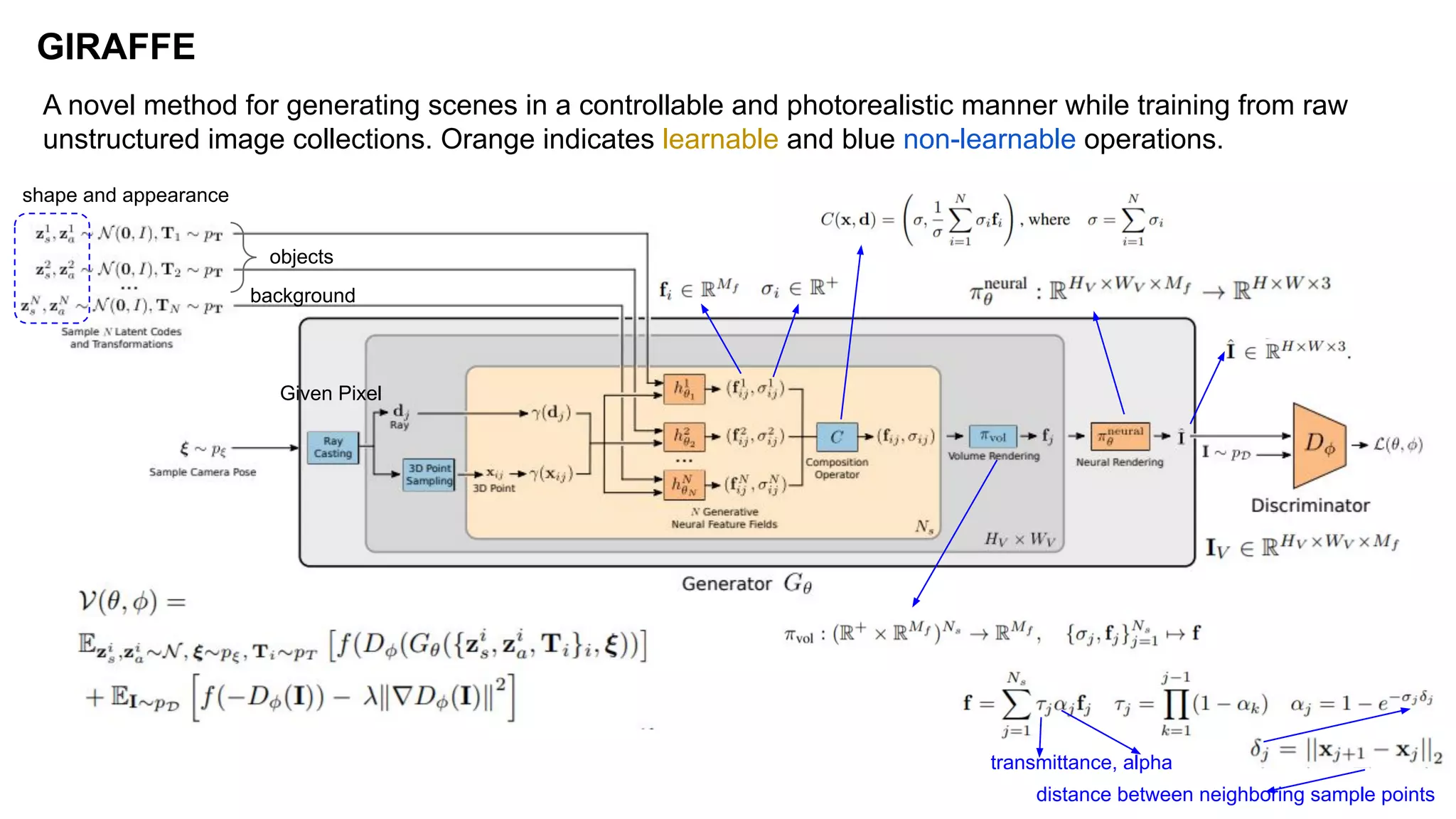
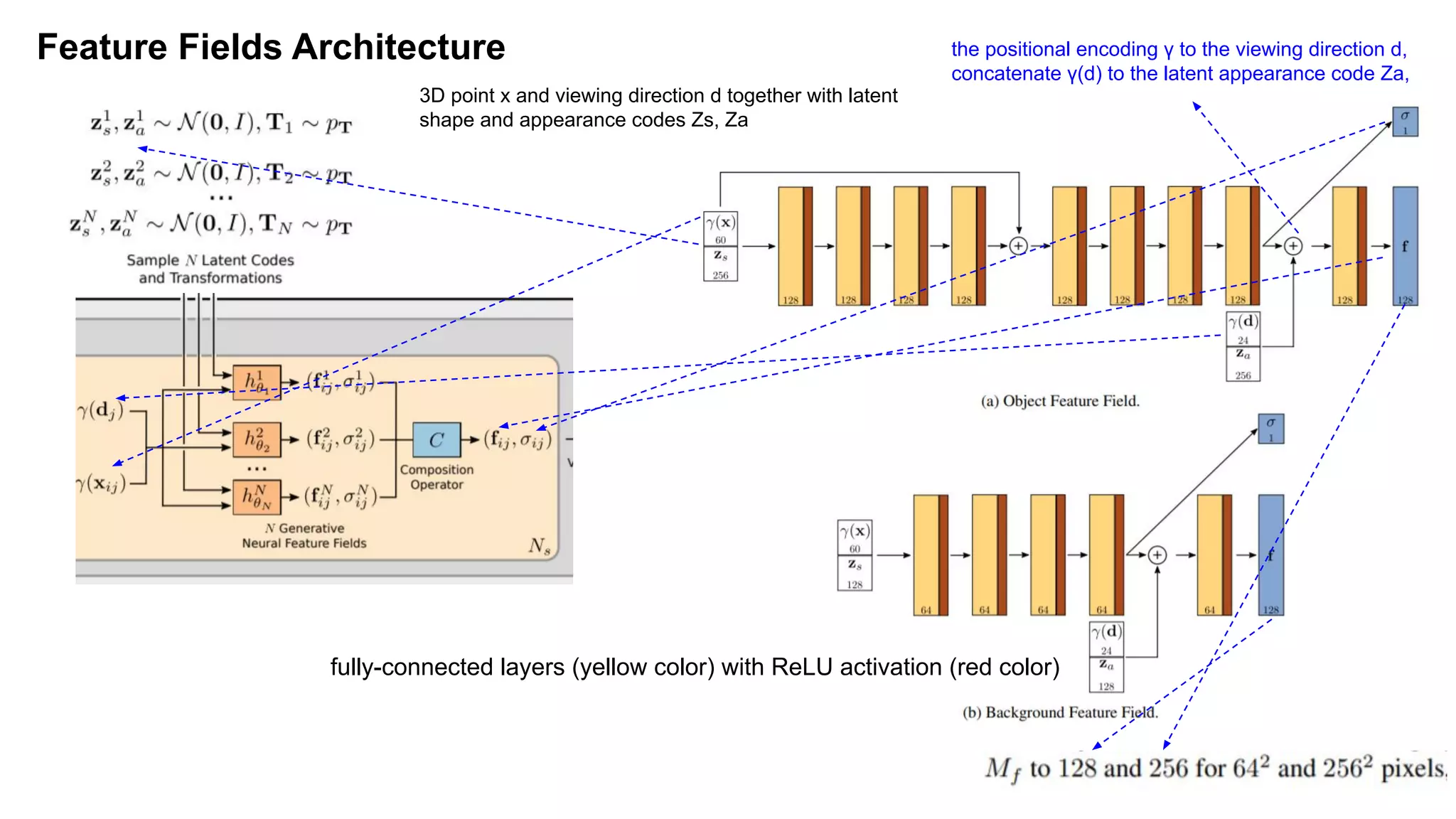
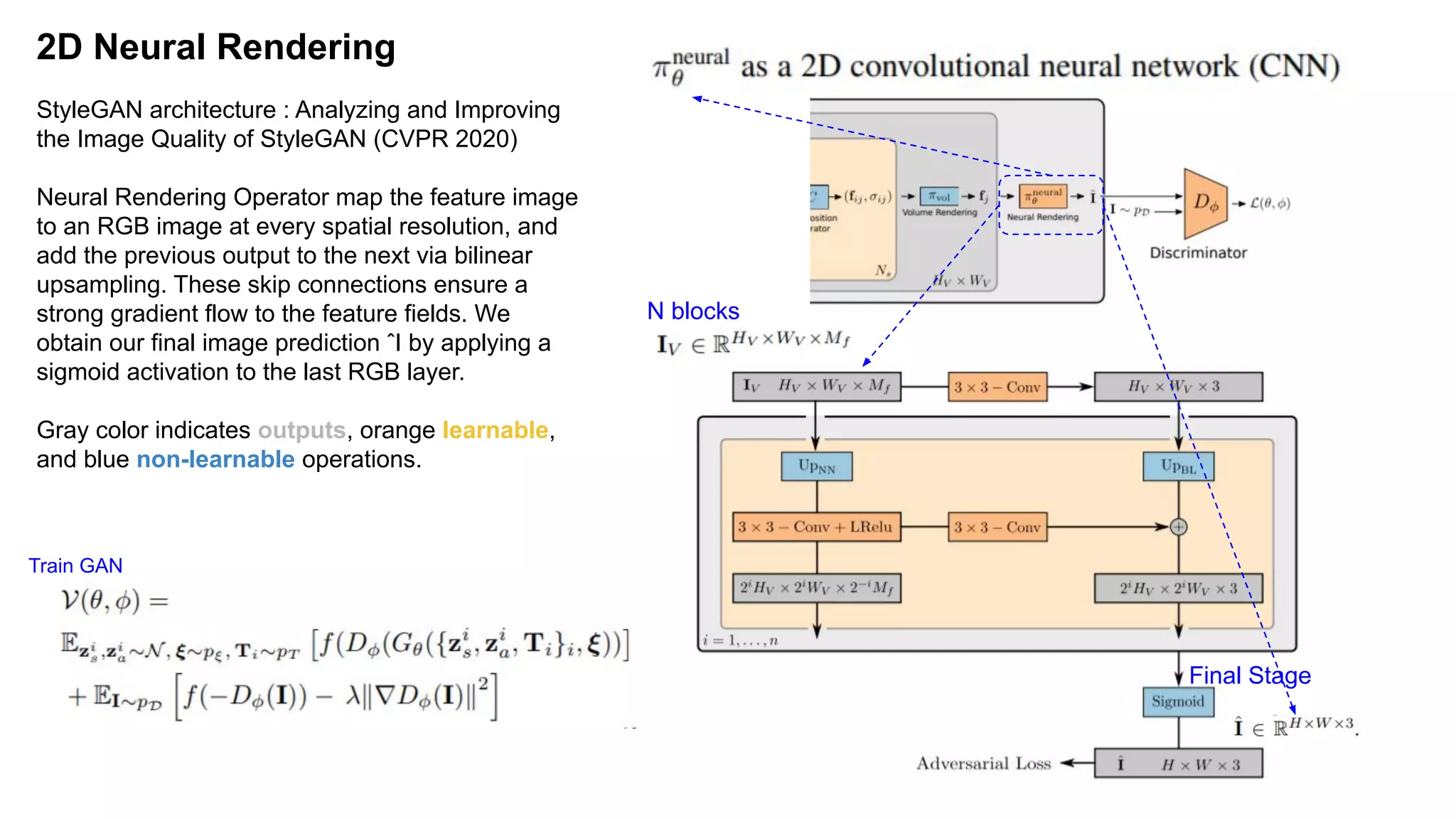
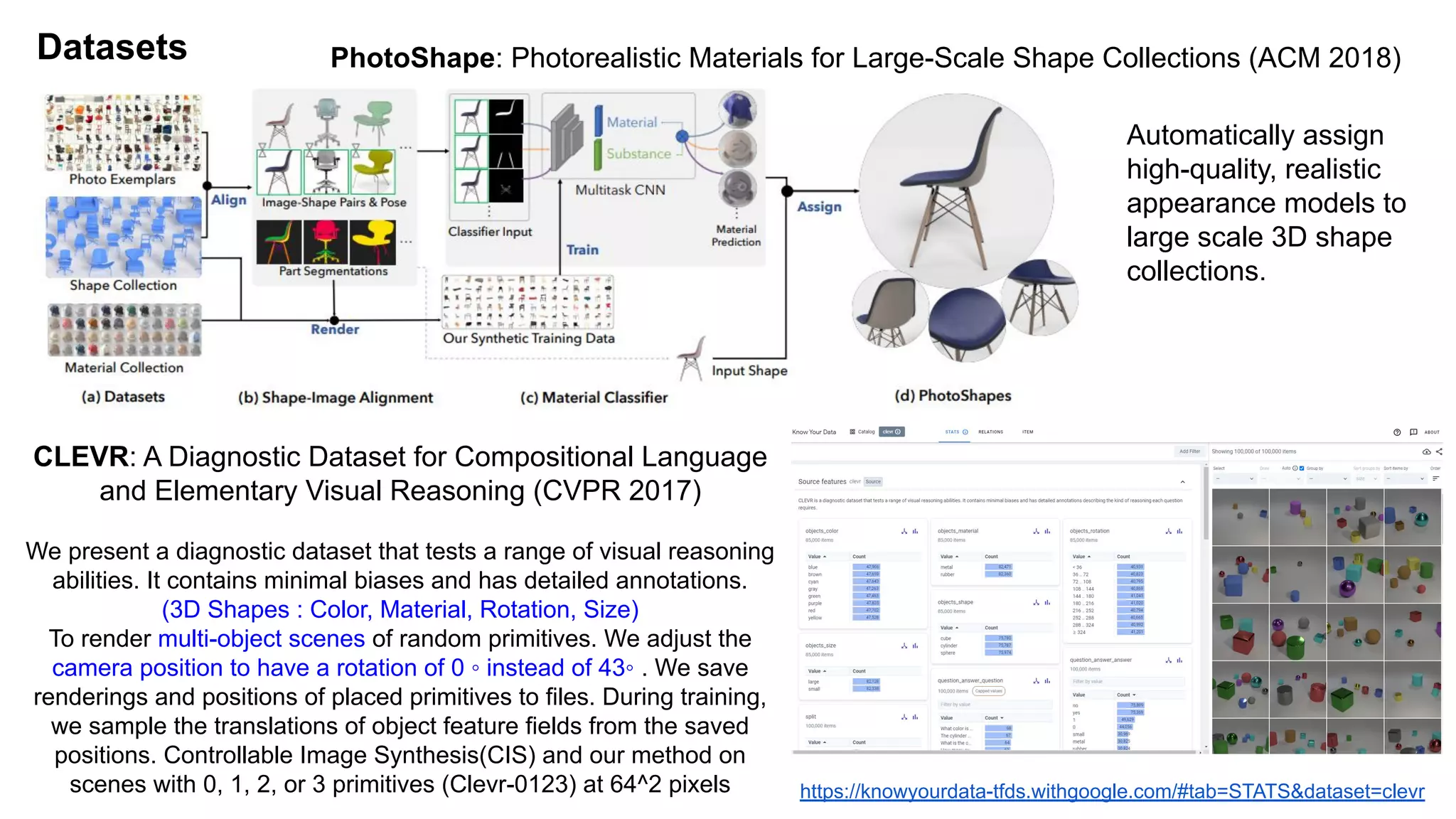
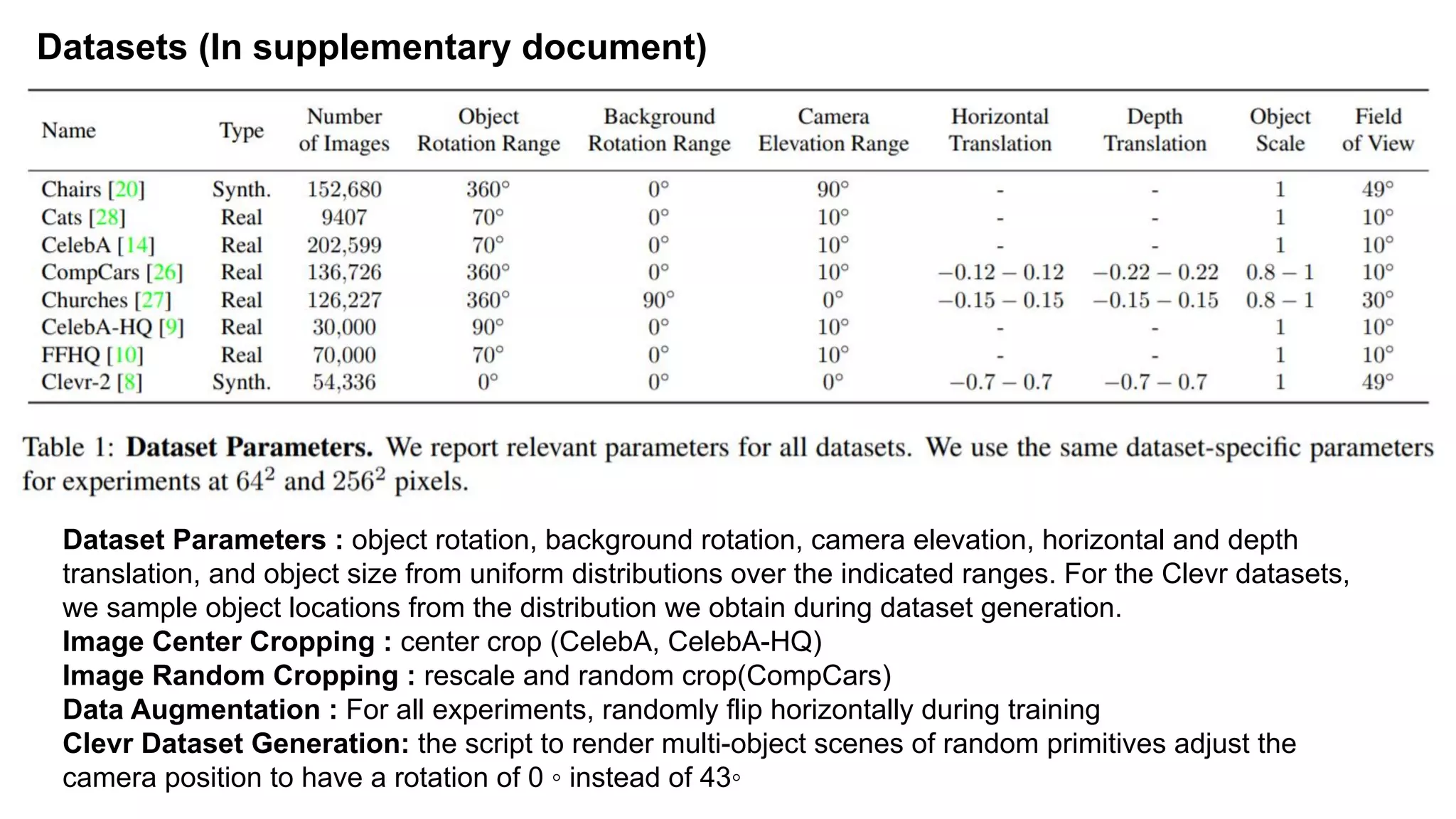
The document discusses 'Giraffe', a novel method for controllable image synthesis that represents 3D scenes using compositional generative neural feature fields, winning the CVPR 2021 Best Paper Award. It addresses limitations of existing models such as NeRF and GRAF by allowing for the disentanglement of individual objects and their attributes in 3D space, thereby enhancing image generation from unstructured data. The approach successfully combines various techniques, allowing for better multi-view consistency and high-quality renderings in complex scenes.


![NeRF : Neural Radiance Fields (ECCV 2020 - Best Paper Honorable Mention)
Input is a single continuous 5D coordinate (spatial
location (x, y, z) and viewing direction (θ, φ)) and
whose output is the volume density and
view-dependent emitted radiance at that spatial
location
FΘ : (x, d) → (c, σ) and optimize its
weights Θ to map from each input 5D
coordinate to its corresponding
volume density and directional emitted
color
Positional encoding : γ(·) is applied separately to each of the three coordinate values in x (which are
normalized to lie in [−1, 1]) and to the three components of the Cartesian viewing direction unit vector d
(which by construction lie in [−1, 1]). In our experiments, we set L = 10 for γ(x) and L = 4 for γ(d).
higher dimensional space to enable our MLP to more easily approximate a higher frequency function](https://image.slidesharecdn.com/papergirafferepresentingscenesascompositionalgenerativeneuralfeaturefields-210823043723/75/Paper-GIRAFFE-Representing-Scenes-as-Compositional-Generative-Neural-Feature-Fields-3-2048.jpg)


























![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/20190125misono-190125024053-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ODT: Online Decision Transformer](https://cdn.slidesharecdn.com/ss_thumbnails/20220318-220322065805-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[PR12] Generative Models as Distributions of Functions](https://cdn.slidesharecdn.com/ss_thumbnails/pr12generativemodelsasdistributionsoffunctions-jaejunyoo-210411152822-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Paper] eXplainable ai(xai) in computer vision](https://cdn.slidesharecdn.com/ss_thumbnails/paperexplainableaixaiincomputervision-210411093712-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] anti spoofing for face recognition](https://cdn.slidesharecdn.com/ss_thumbnails/paperanti-spoofingforfacerecognition-210508093958-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] DetectoRS for Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/paperdetectorsobjectdetection-210320013551-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Paper] dynamic routing between capsules](https://cdn.slidesharecdn.com/ss_thumbnails/paperdynamicroutingbetweencapsules-210509101120-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] attention mechanism(luong)](https://cdn.slidesharecdn.com/ss_thumbnails/paperattentionmechanismluong-210508090926-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Paper] EDA : easy data augmentation techniques for boosting performance on t...](https://cdn.slidesharecdn.com/ss_thumbnails/paperedaeasydataaugmentationtechniquesforboostingperformanceontextclassificationtasks-210414133327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] auto ml part 1](https://cdn.slidesharecdn.com/ss_thumbnails/paperautomlpart1-210413122952-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] learning video representations from correspondence proposals](https://cdn.slidesharecdn.com/ss_thumbnails/paperlearningvideorepresentationsfromcorrespondenceproposals-210410235049-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] shuffle net an extremely efficient convolutional neural network for ...](https://cdn.slidesharecdn.com/ss_thumbnails/papershufflenetanextremelyefficientconvolutionalneuralnetworkformobiledevices-210424000132-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)