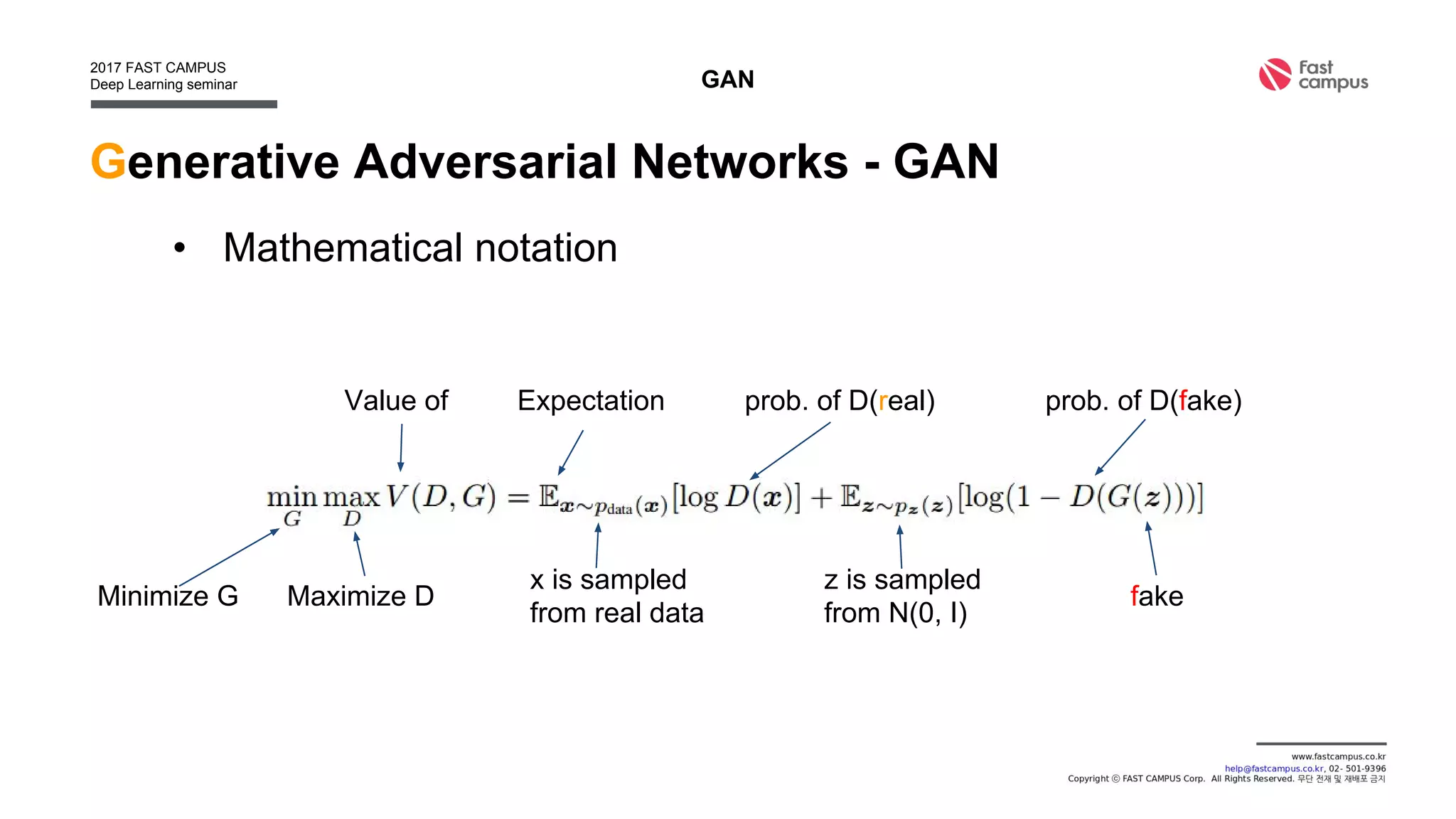
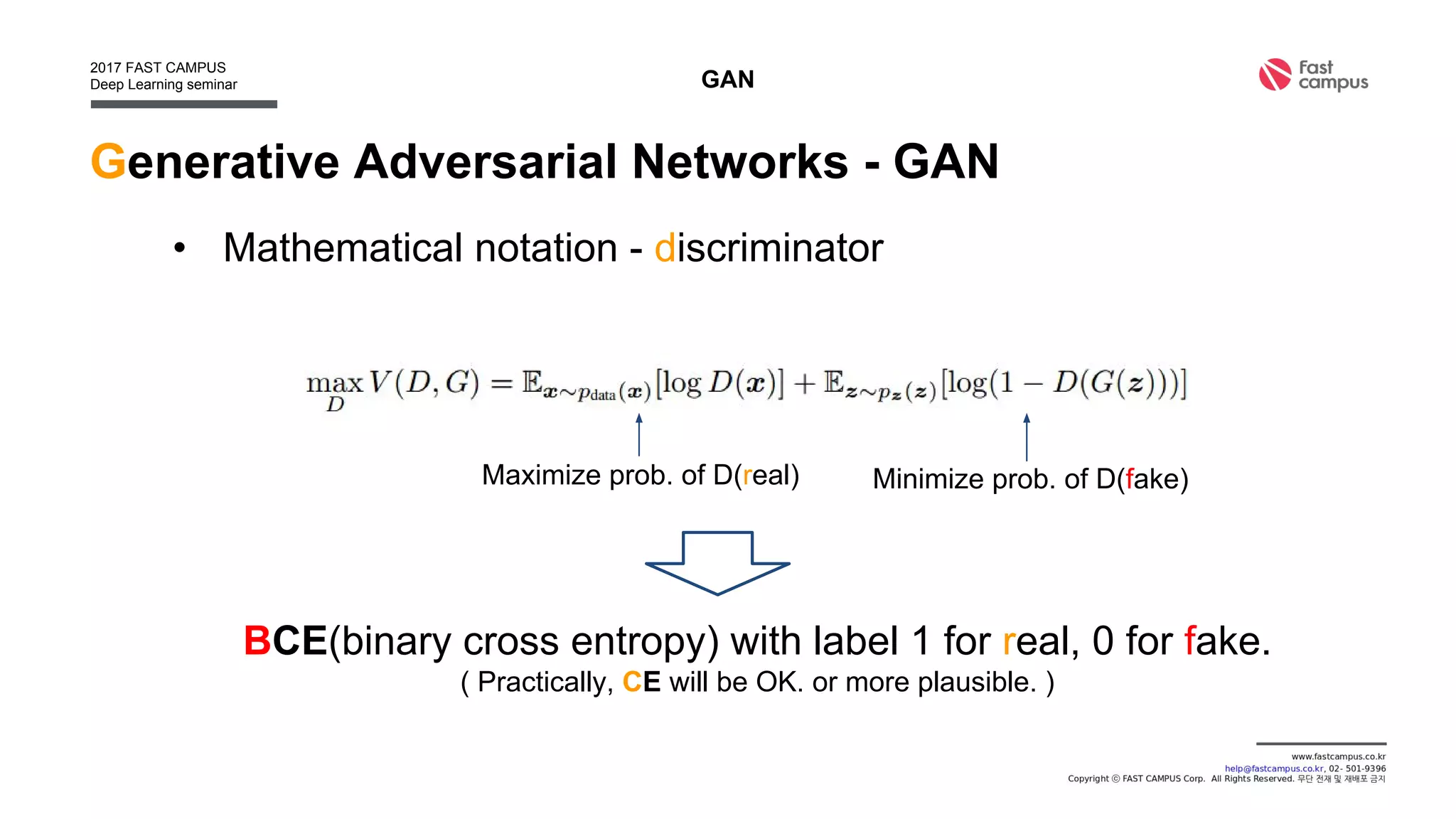
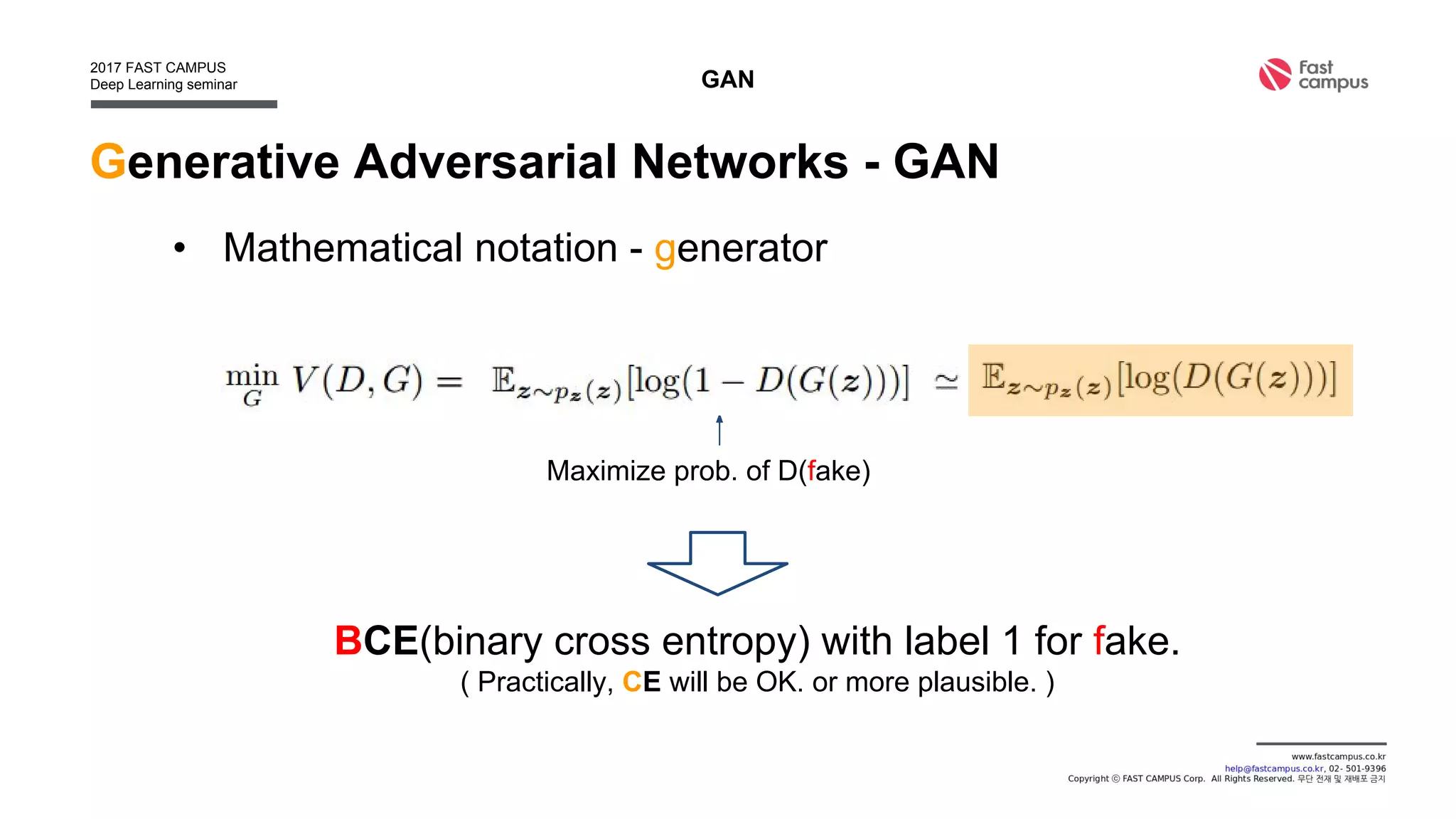
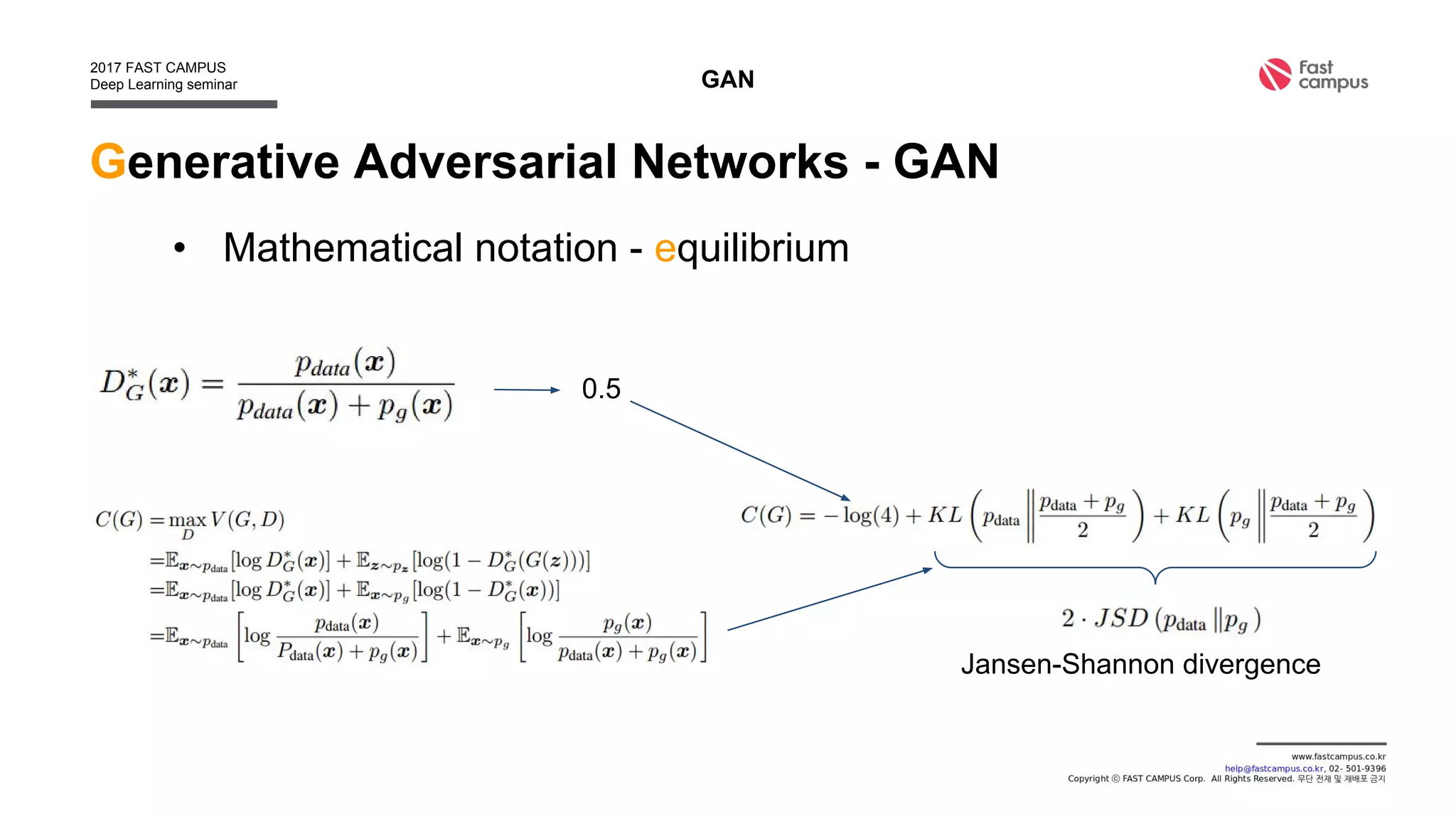
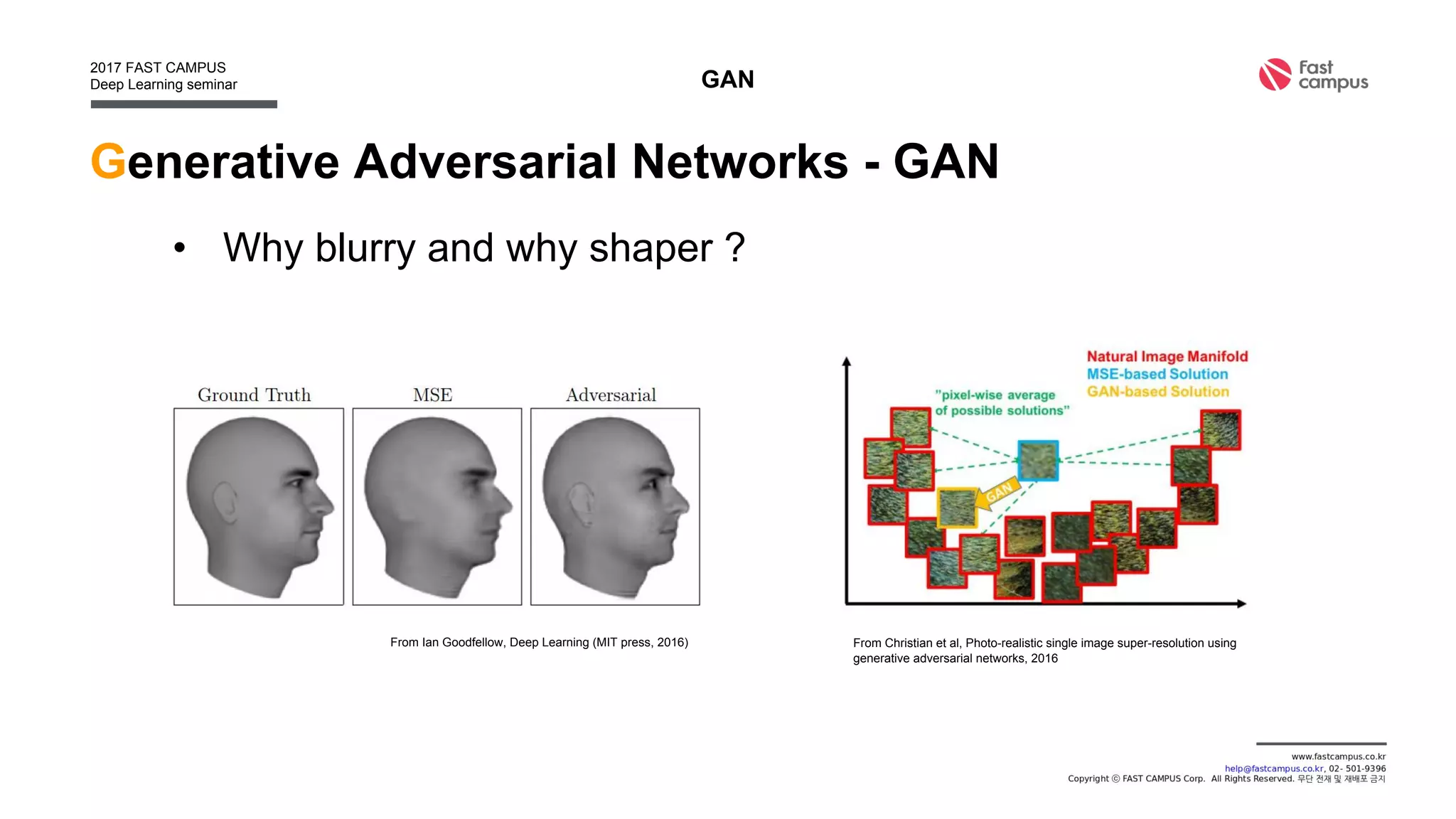
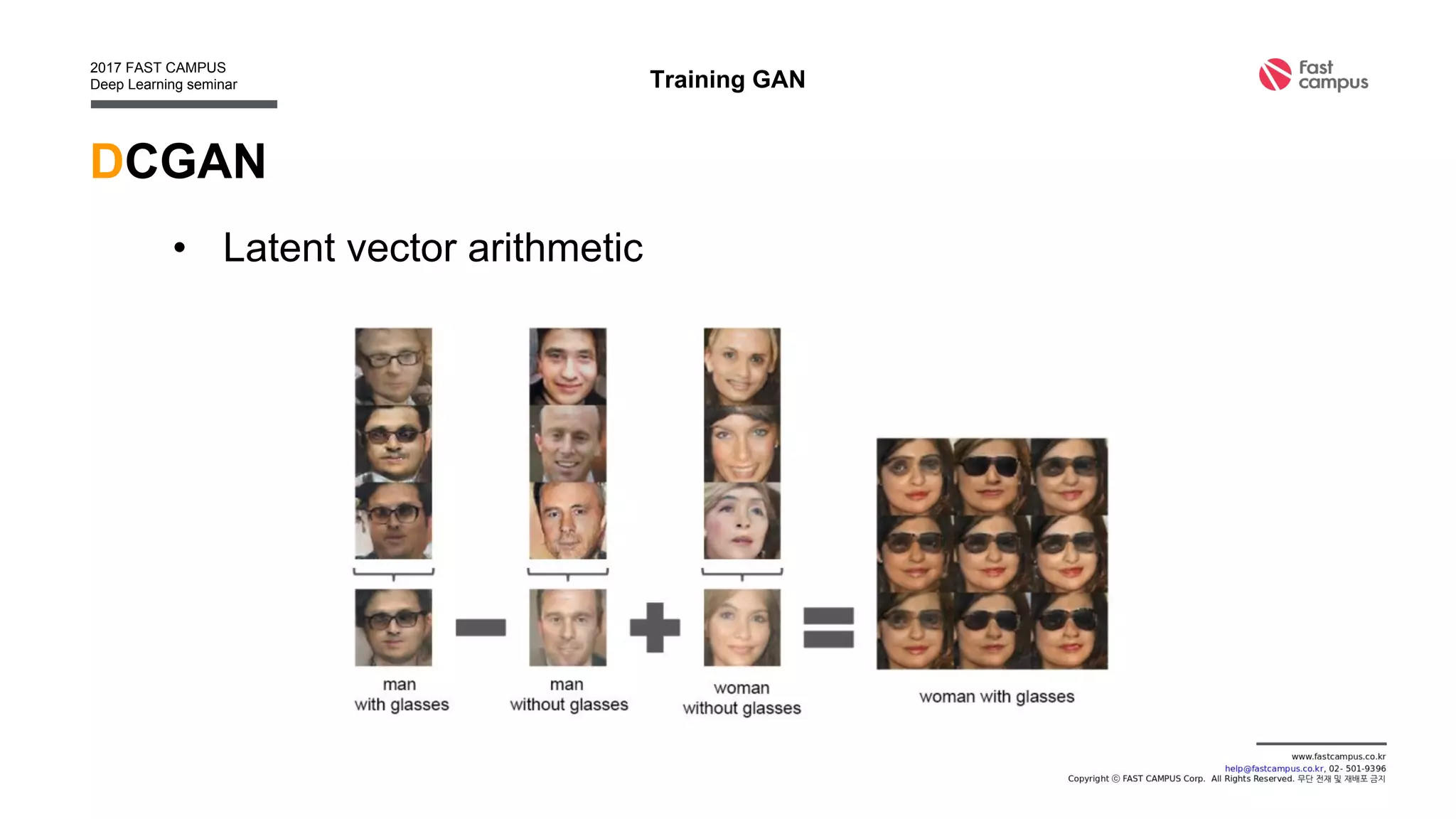
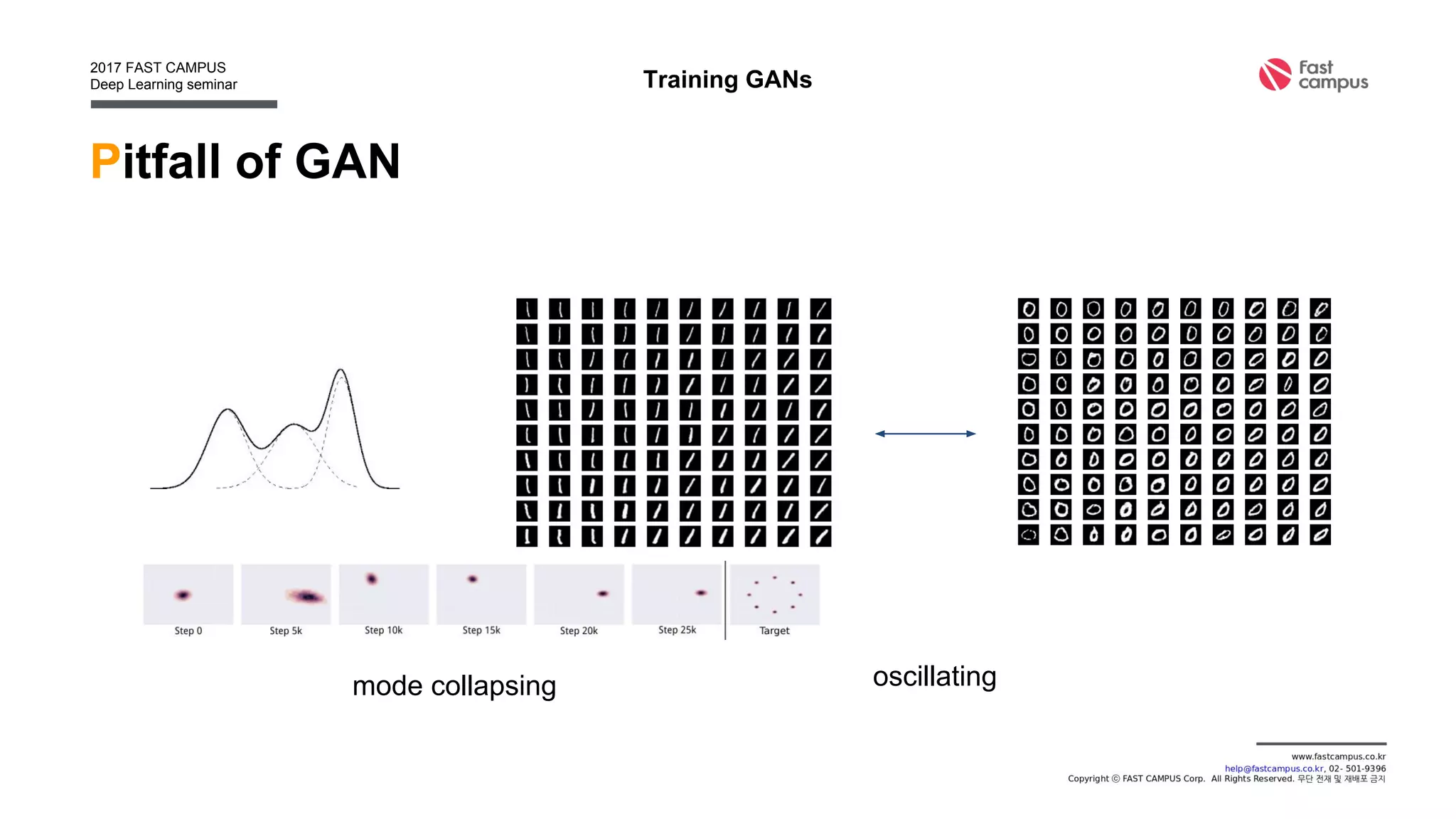
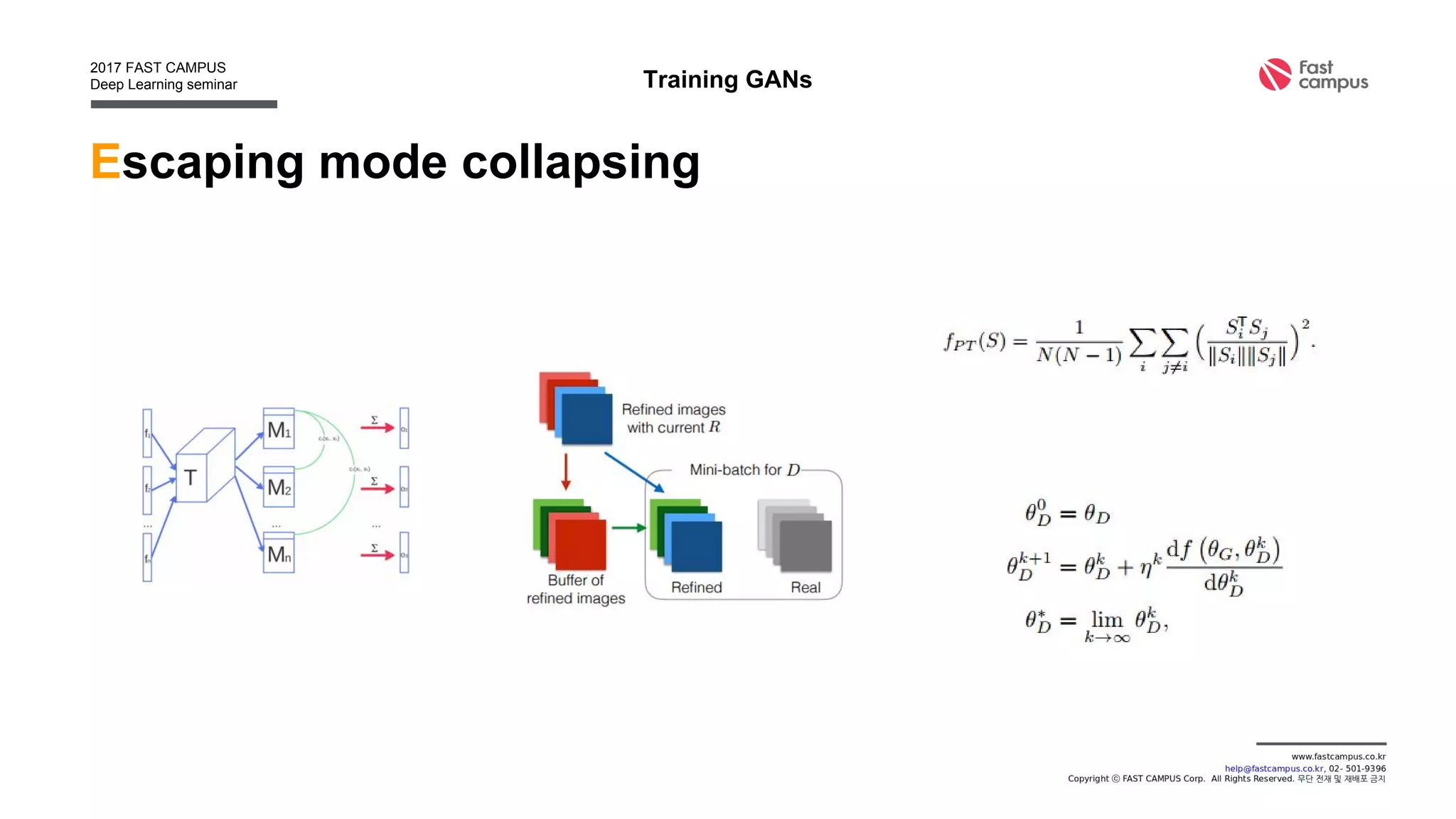
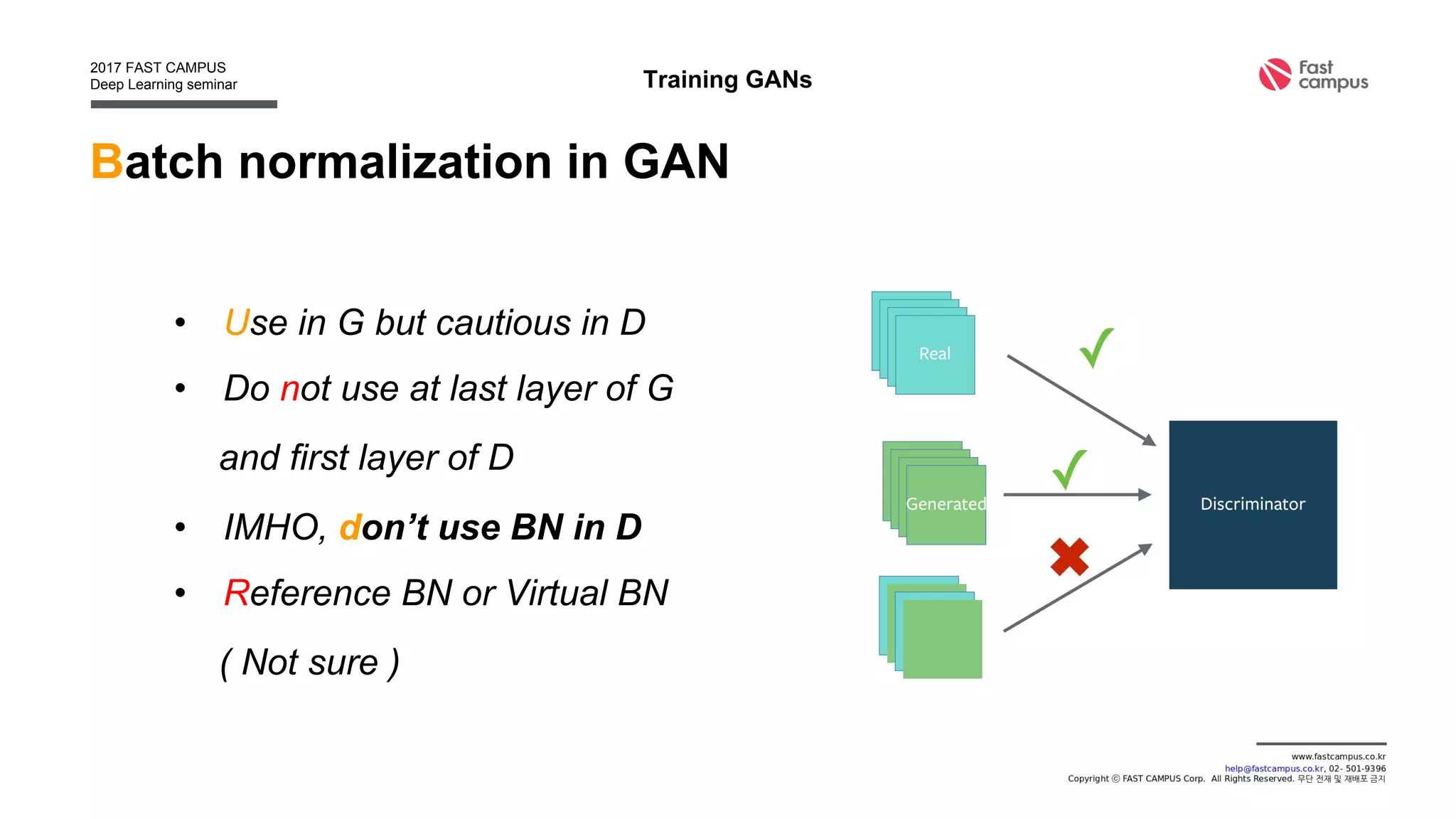
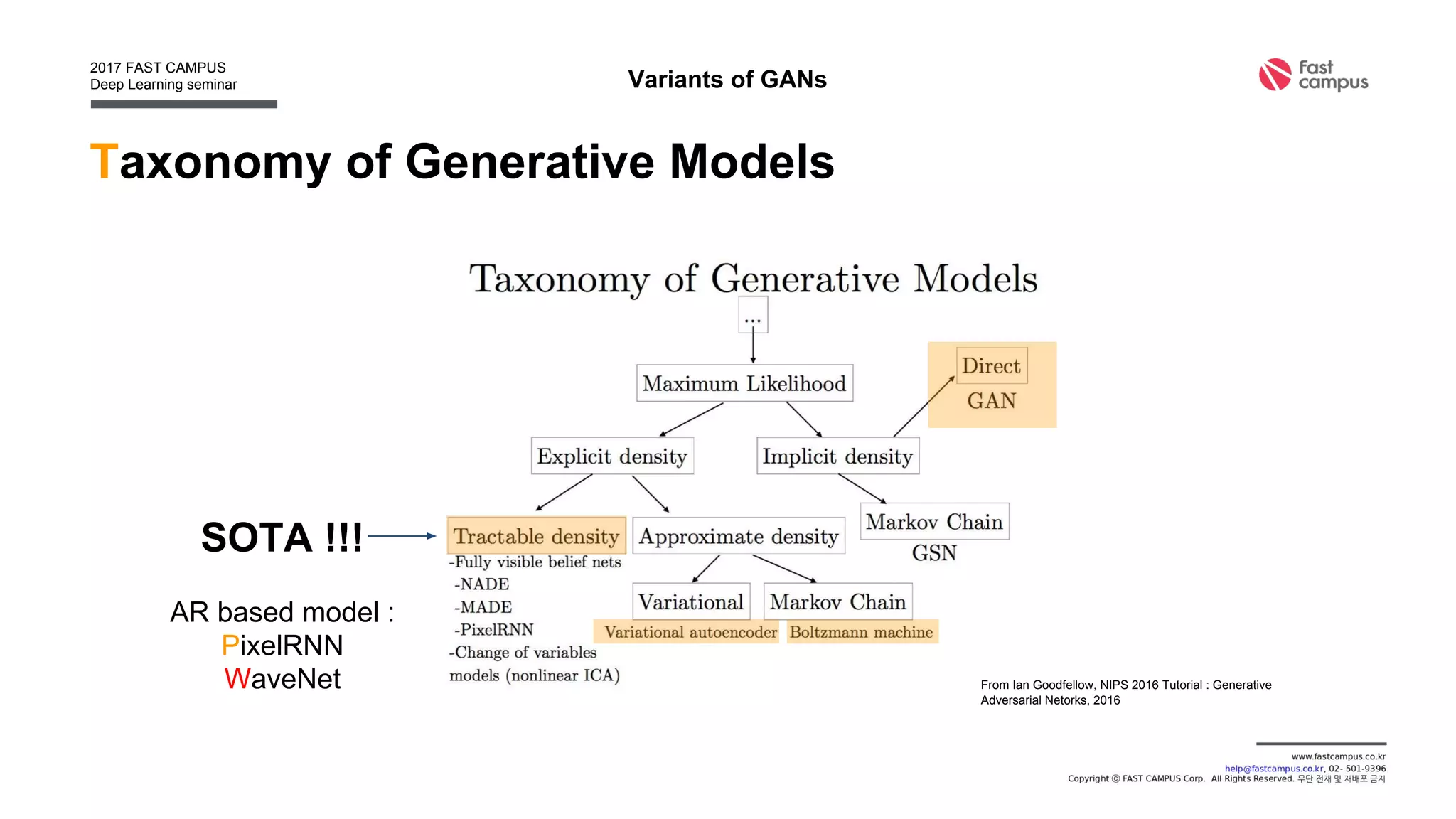
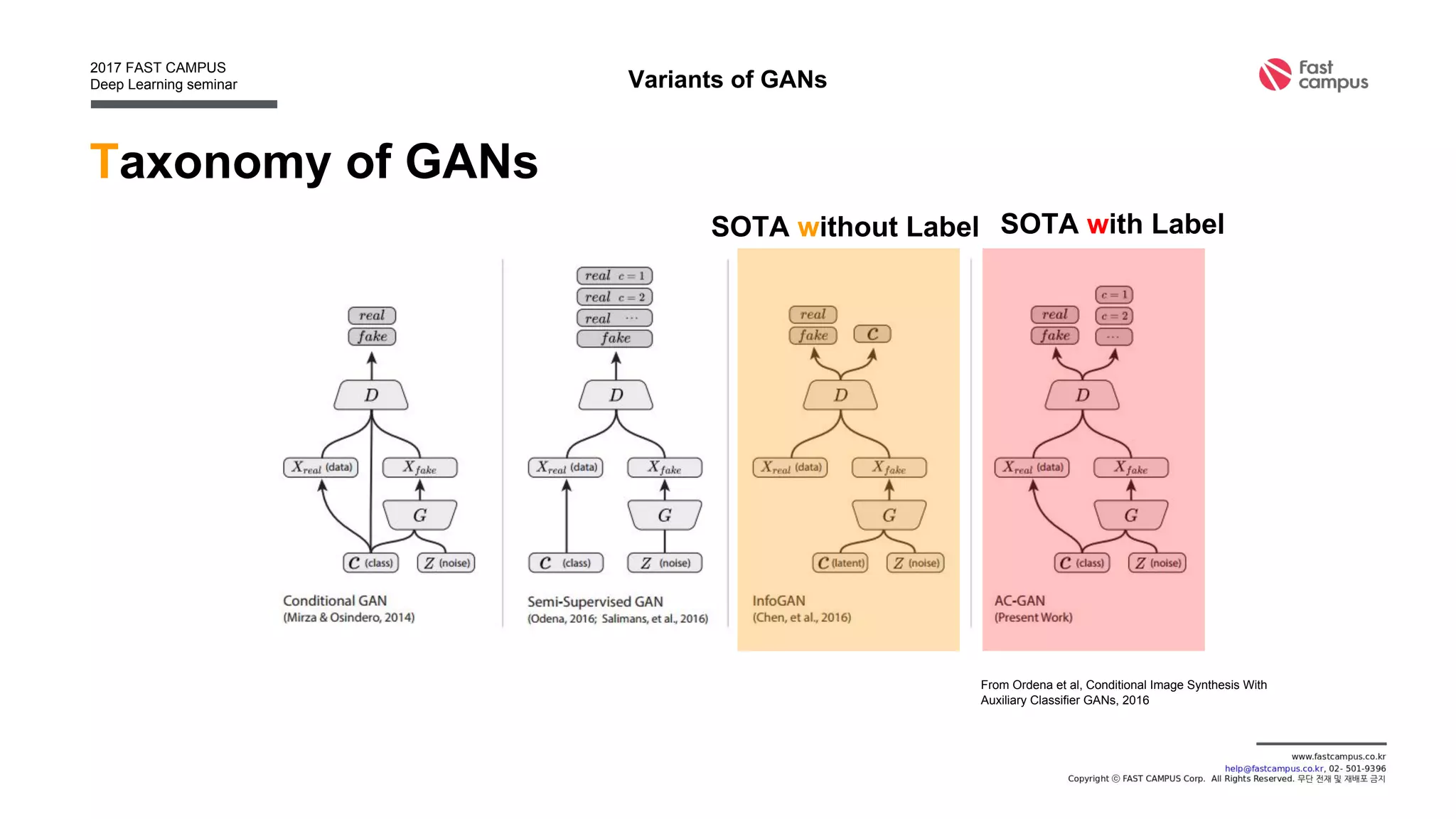
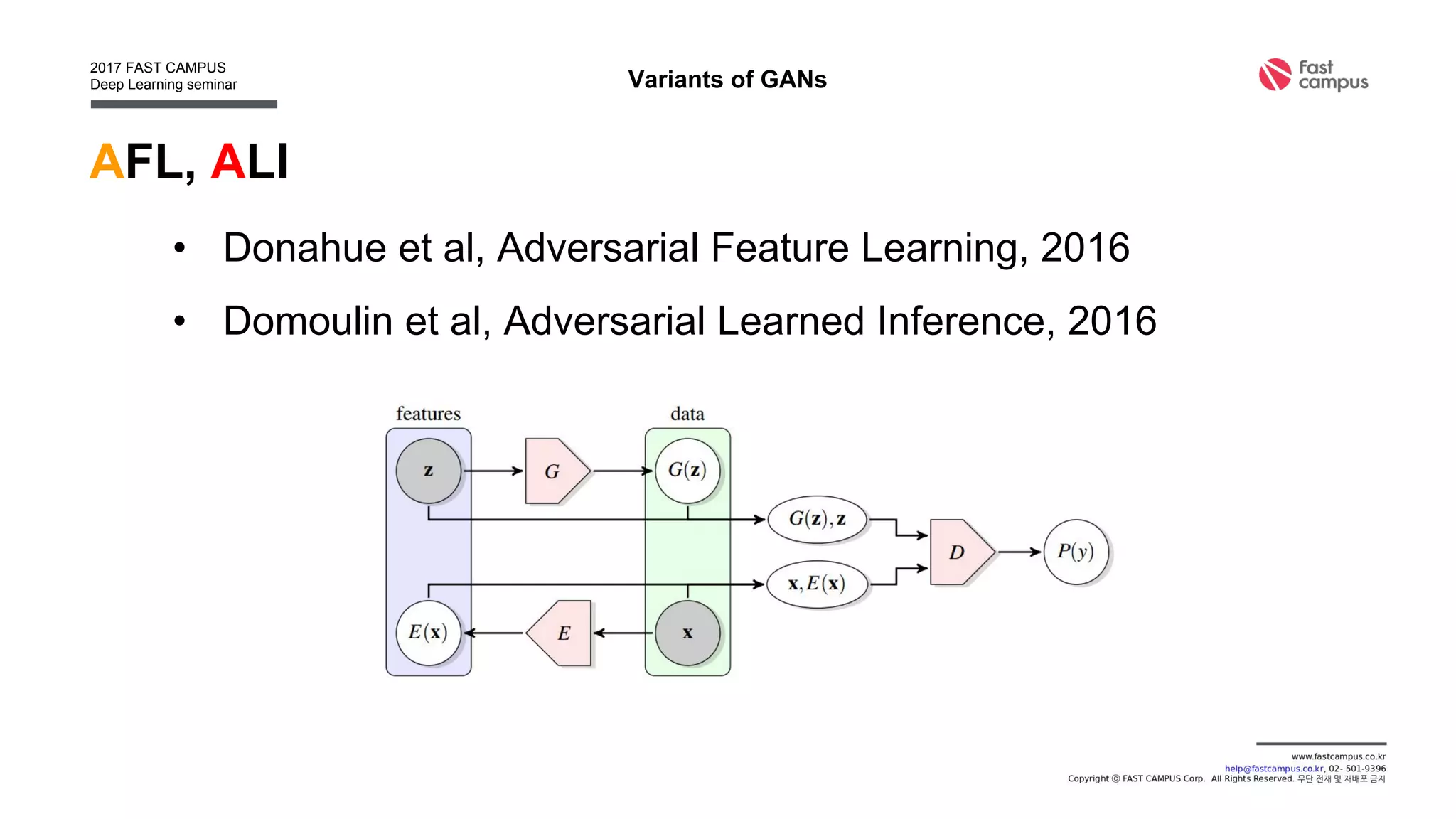
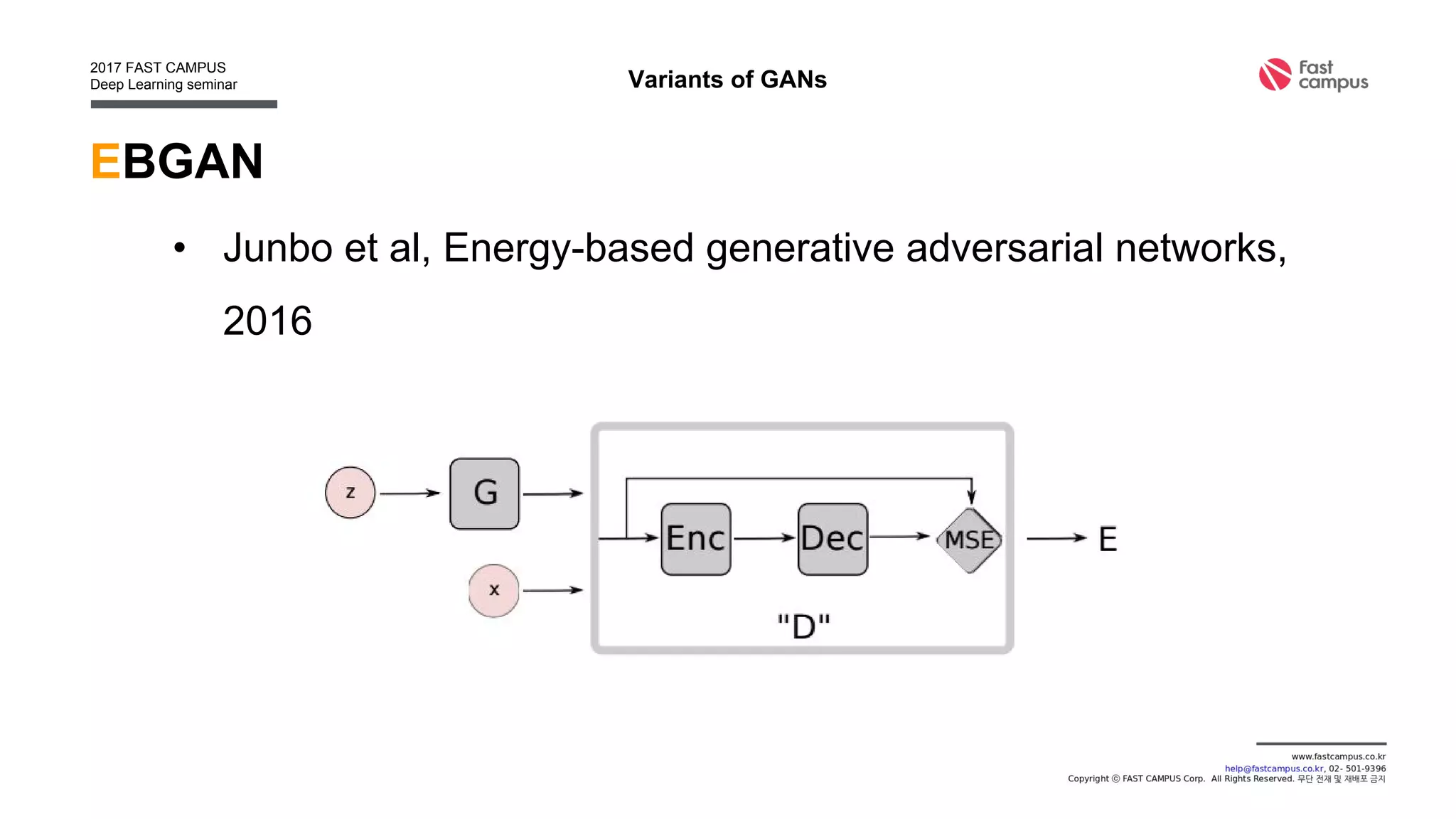
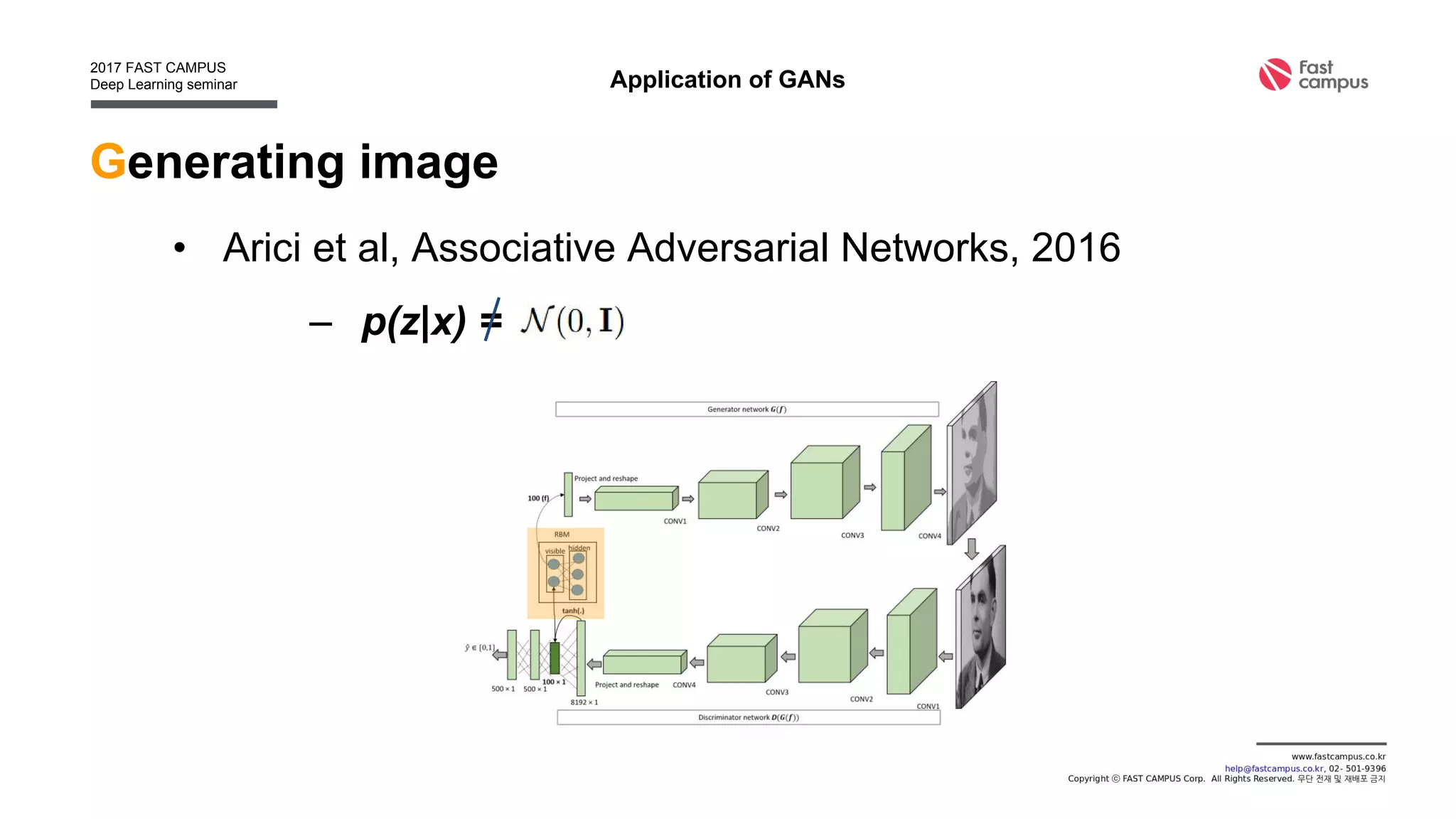
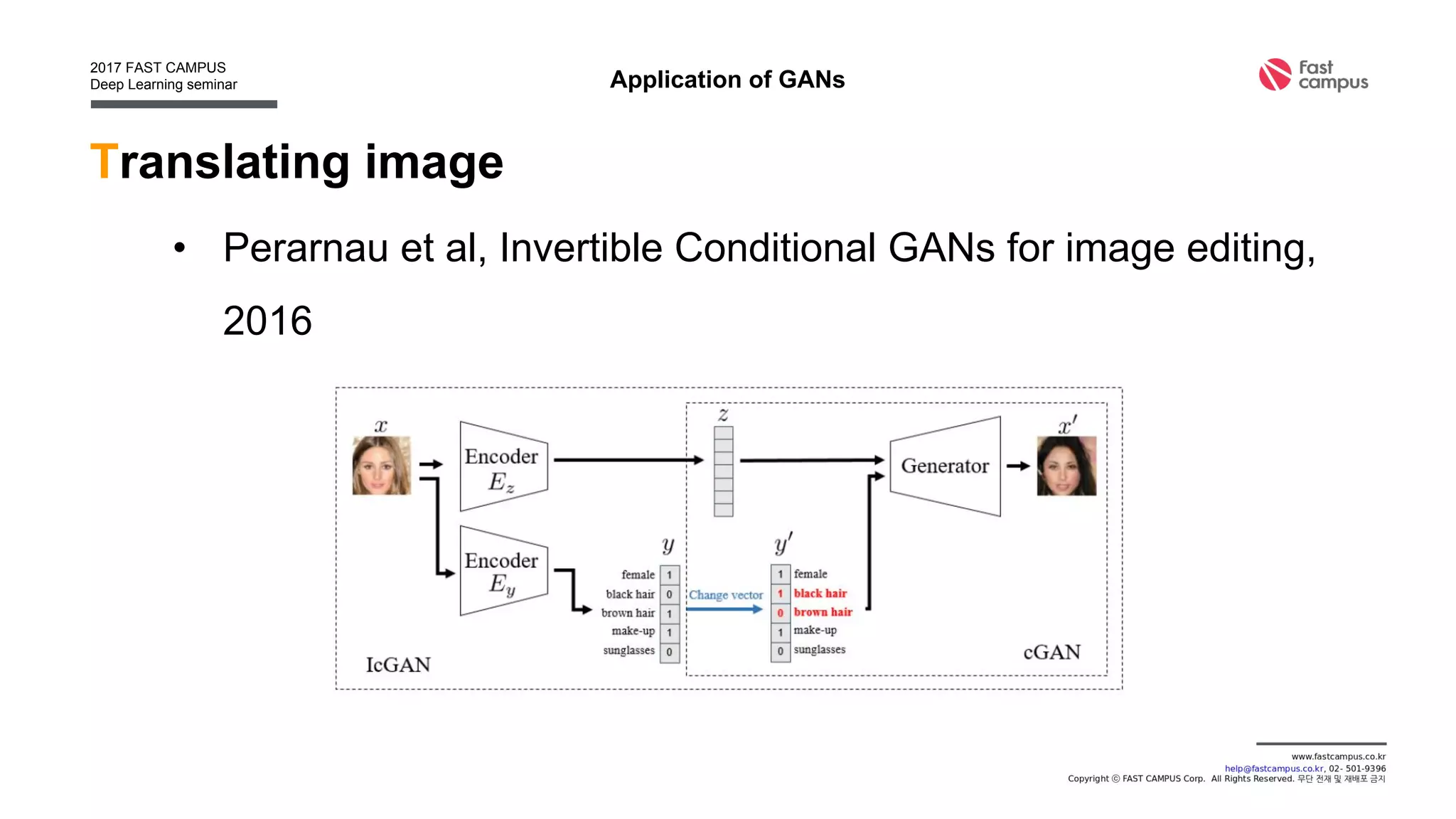
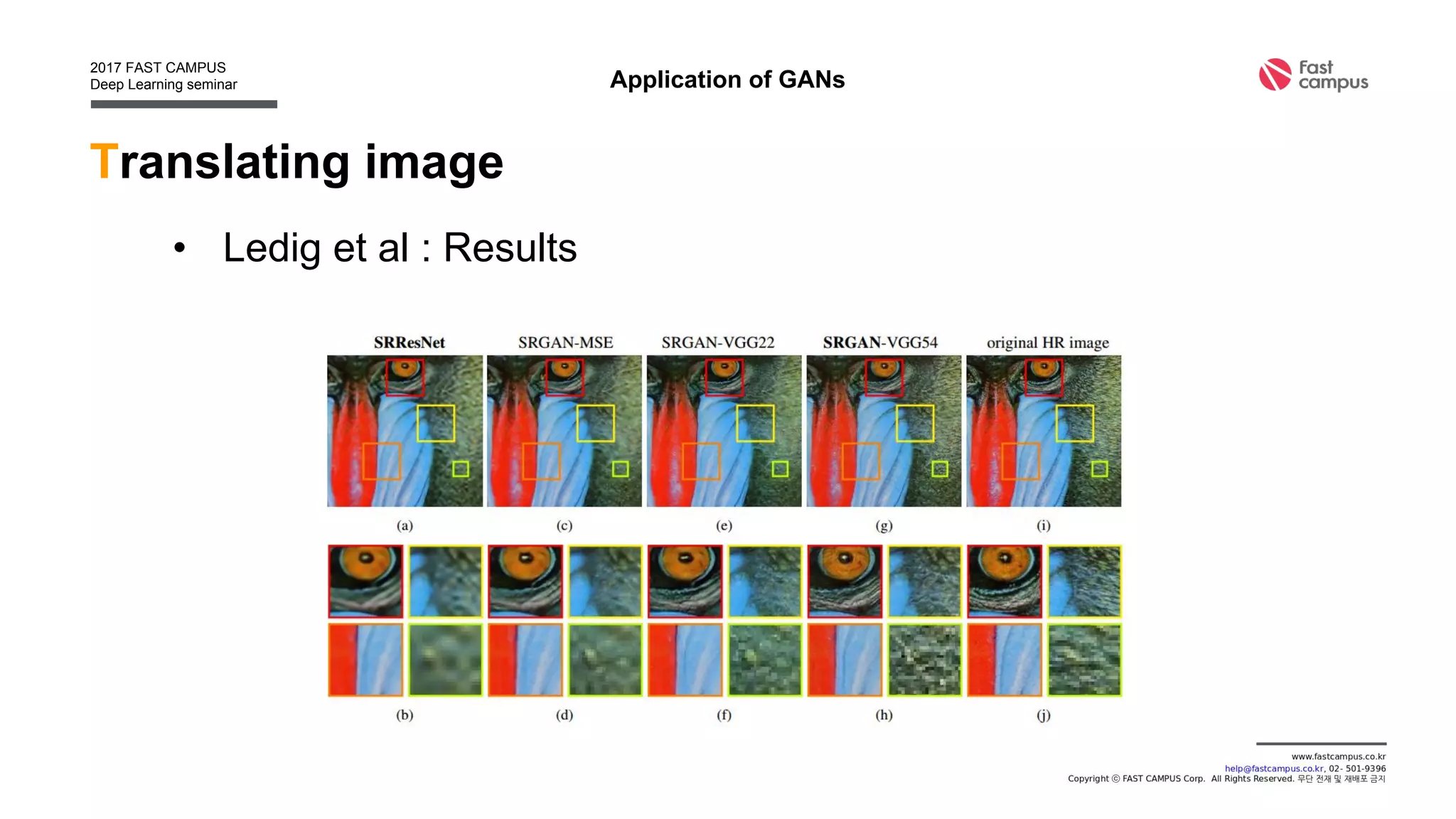
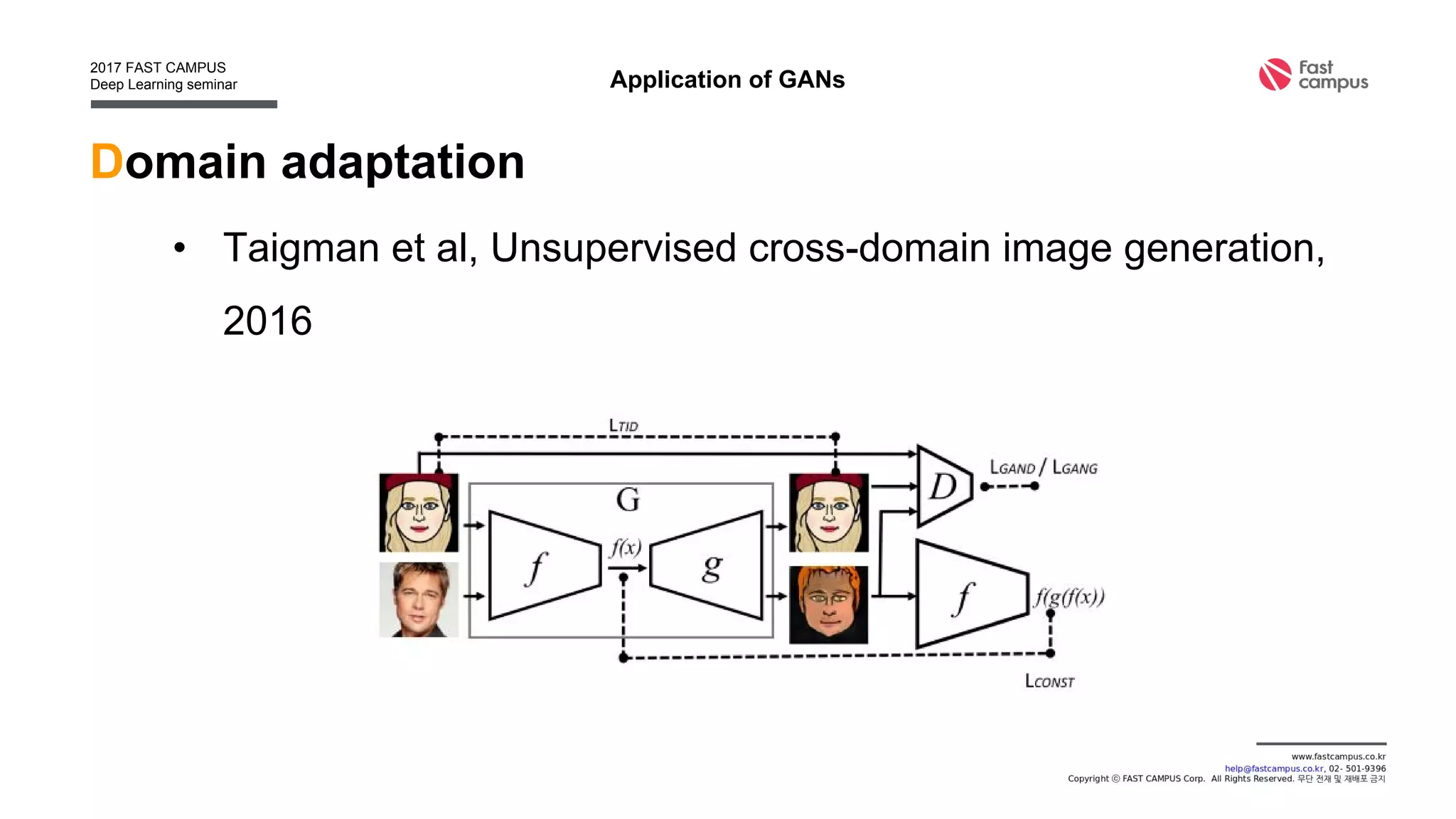
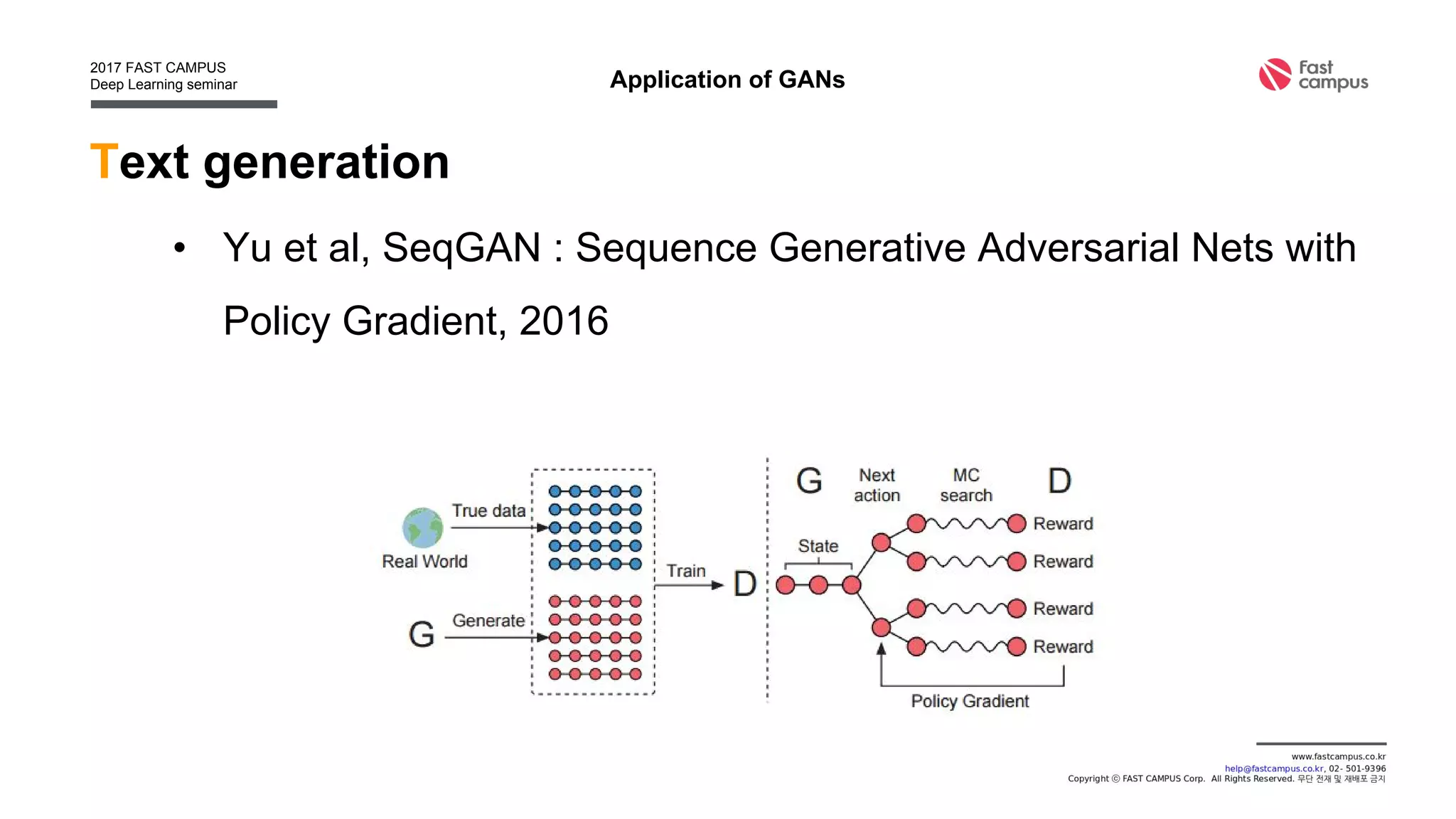
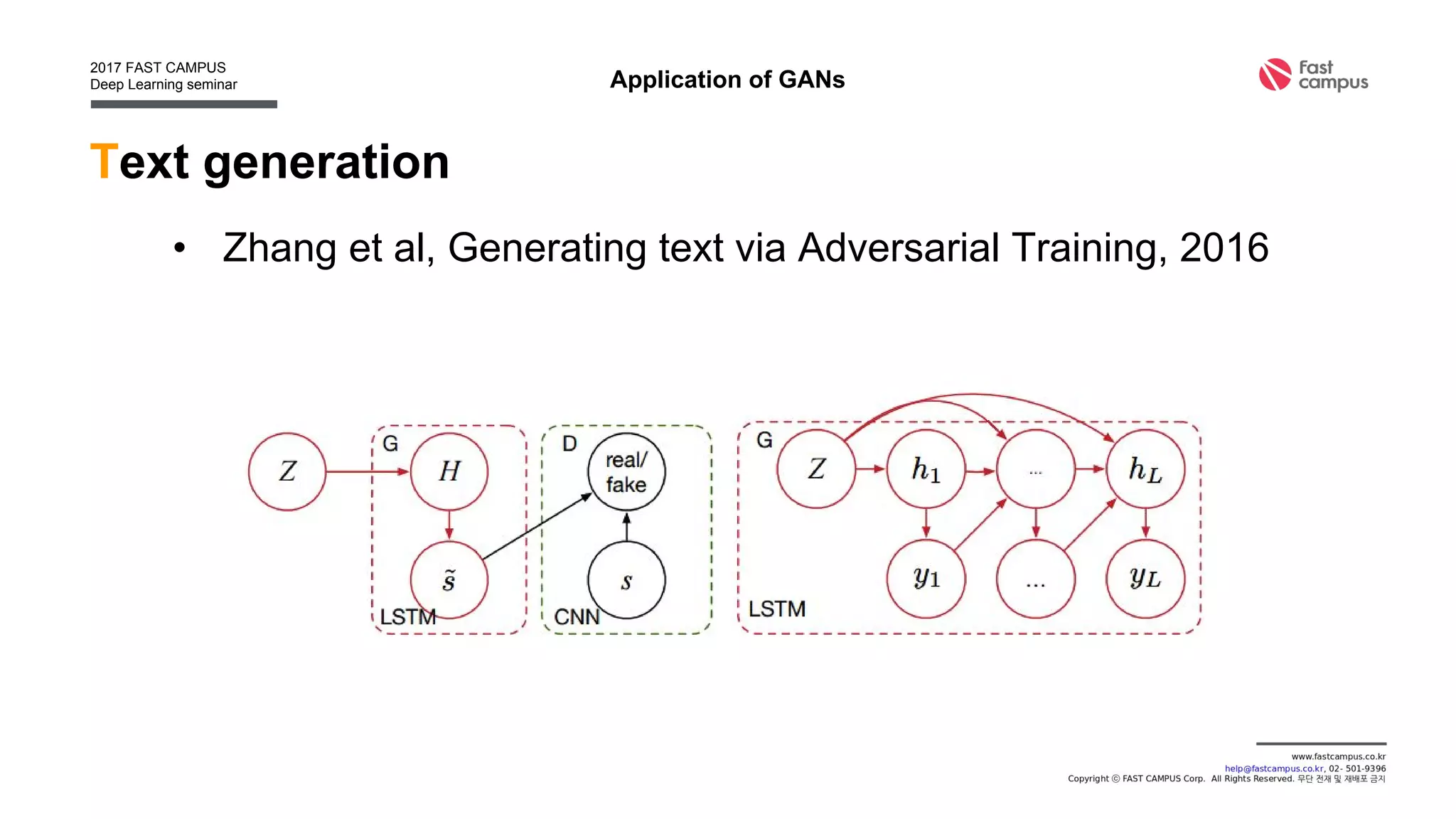
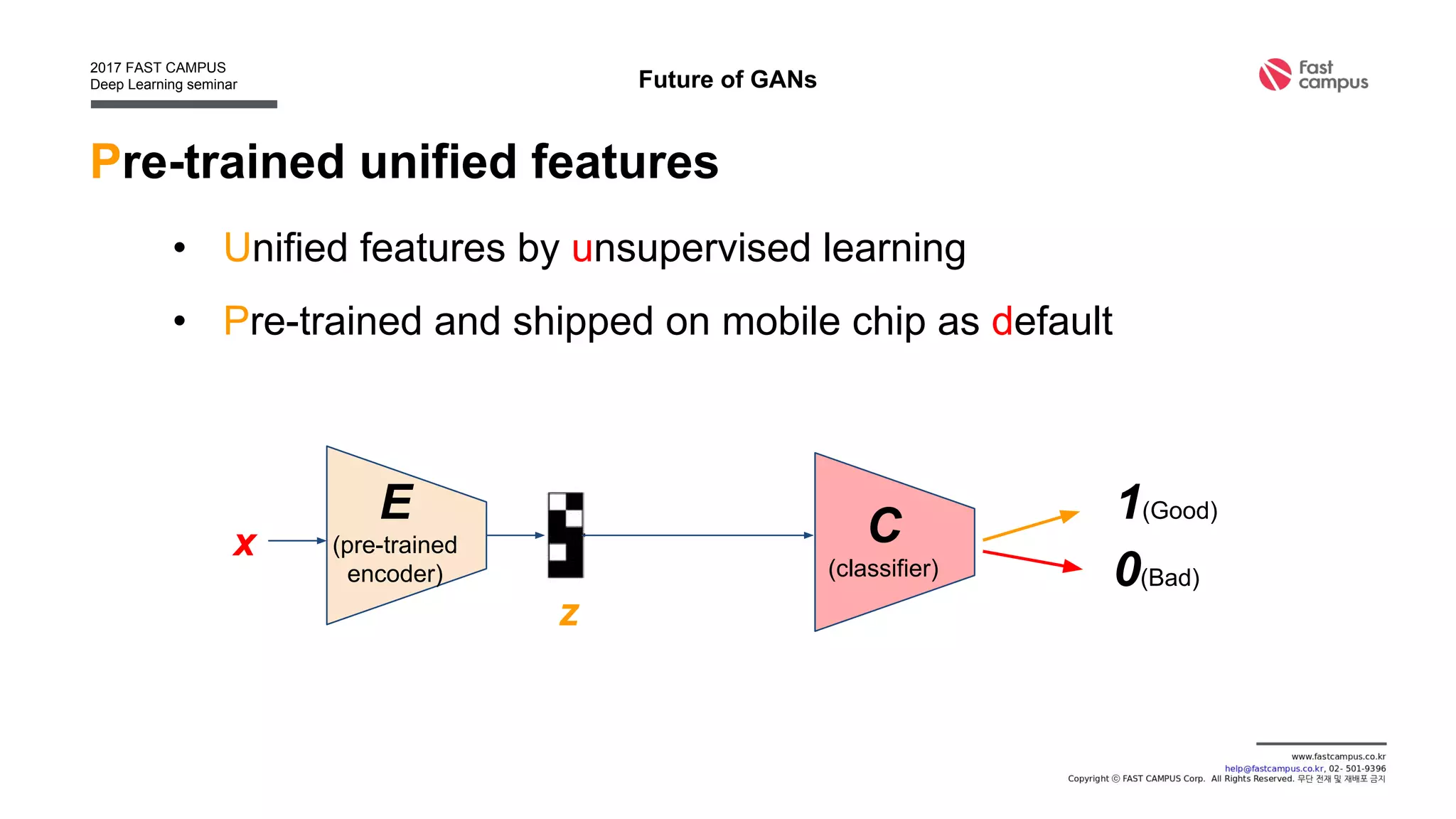
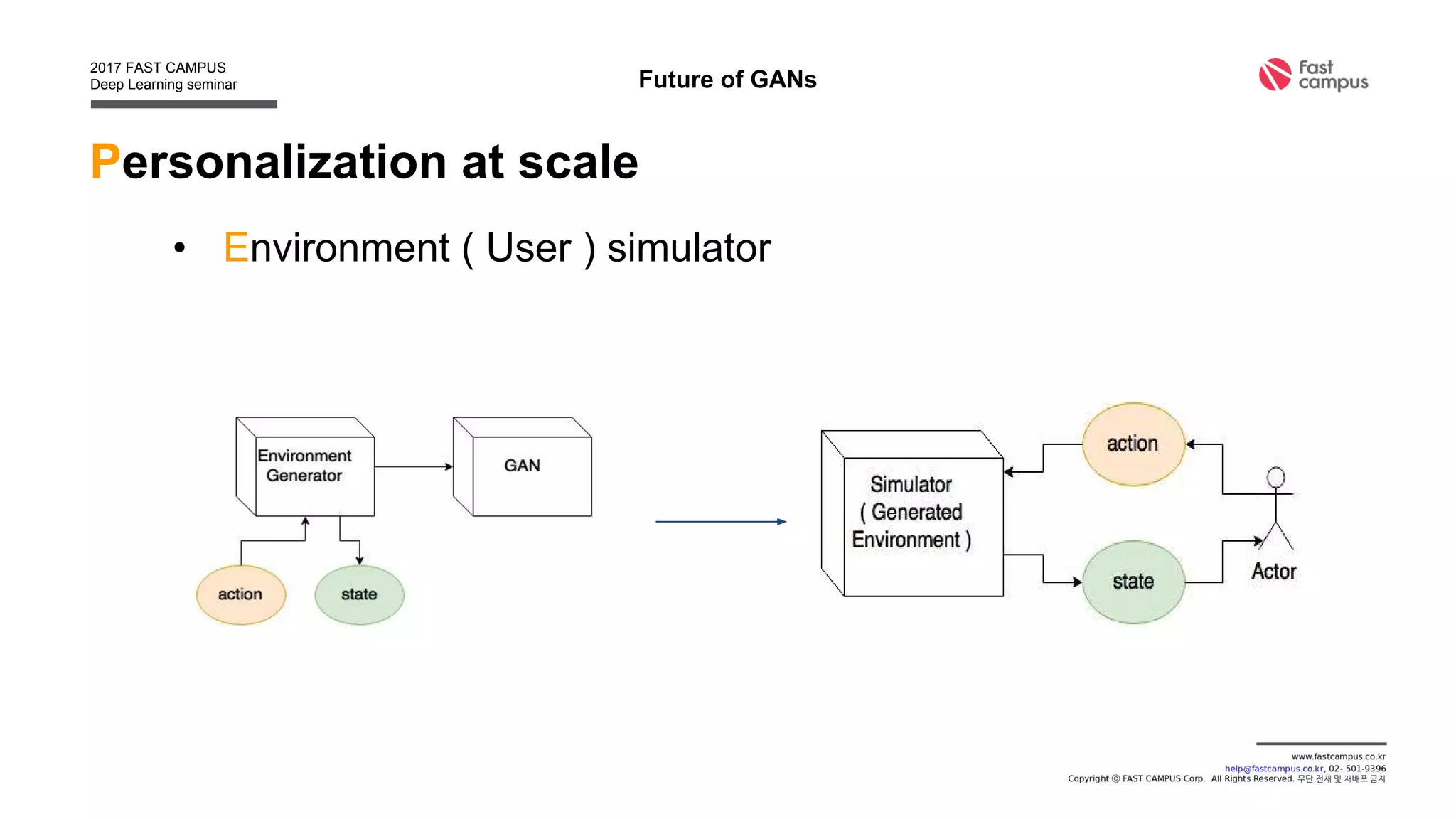
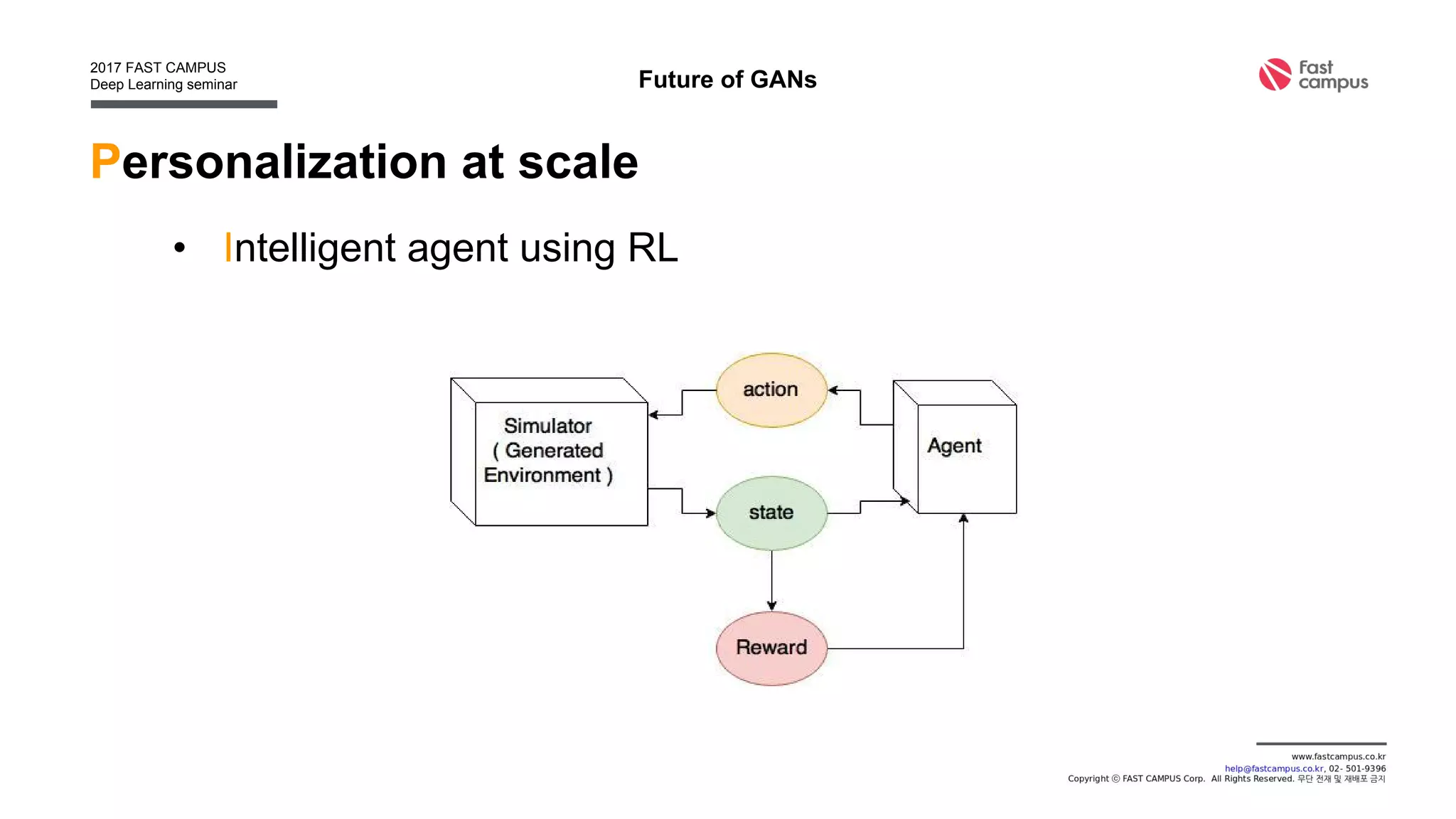
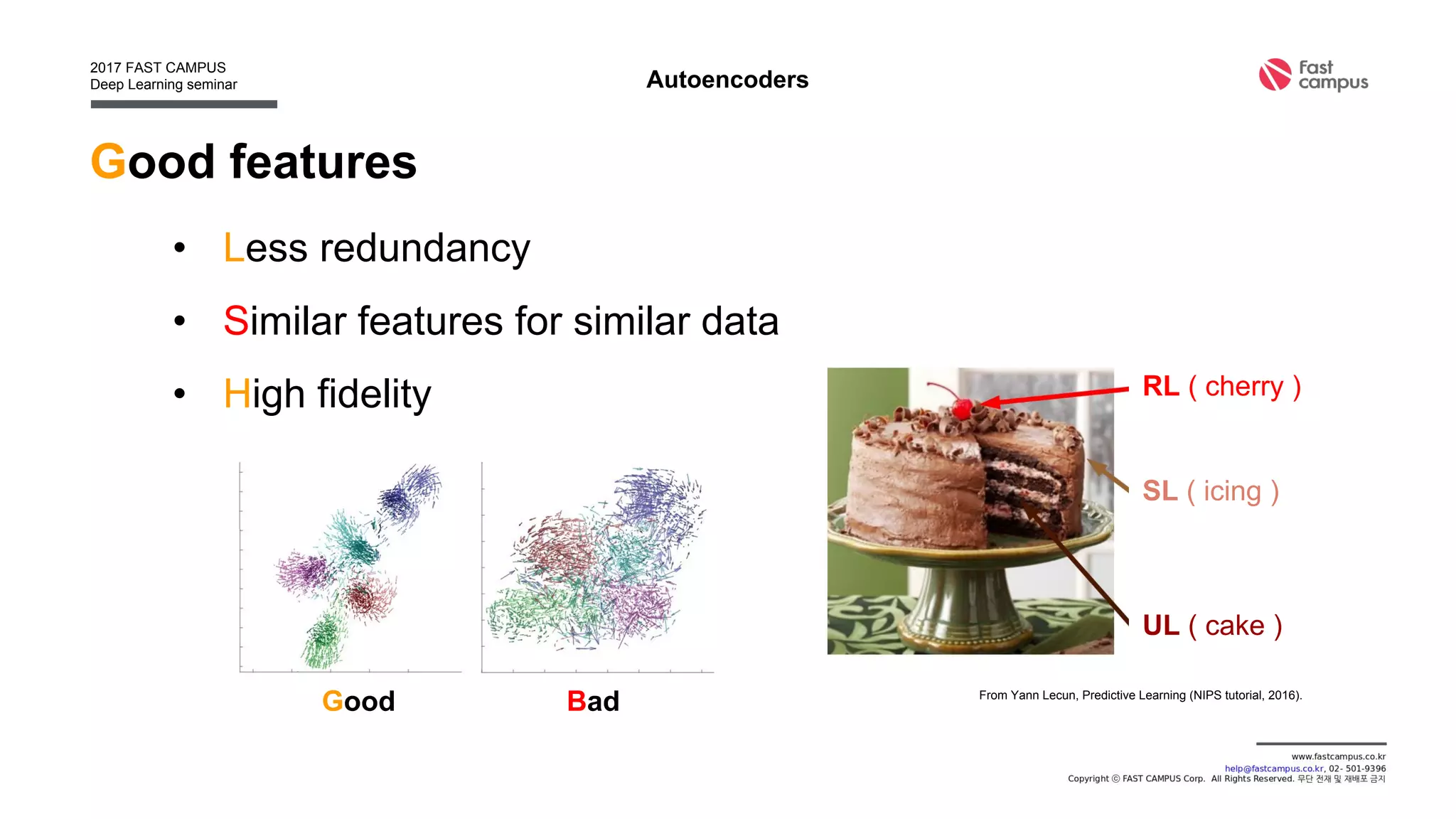
Generative Adversarial Networks (GANs) are a class of machine learning frameworks where two neural networks contest with each other in a game. A generator network generates new data instances, while a discriminator network evaluates them for authenticity, classifying them as real or generated. This adversarial process allows the generator to improve over time and generate highly realistic samples that can pass for real data. The document provides an overview of GANs and their variants, including DCGAN, InfoGAN, EBGAN, and ACGAN models. It also discusses techniques for training more stable GANs and escaping issues like mode collapse.









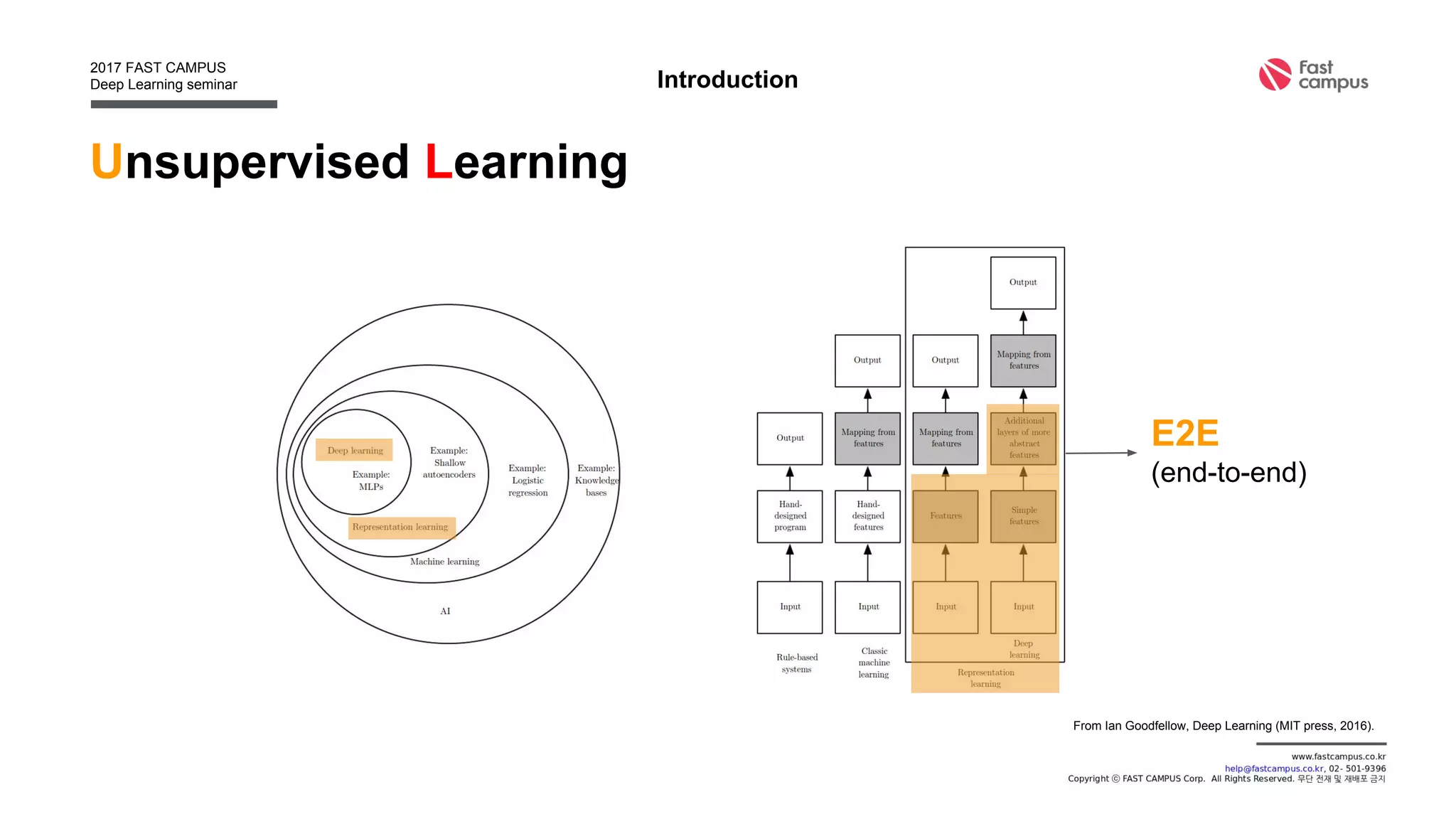
![Unsupervised Learning
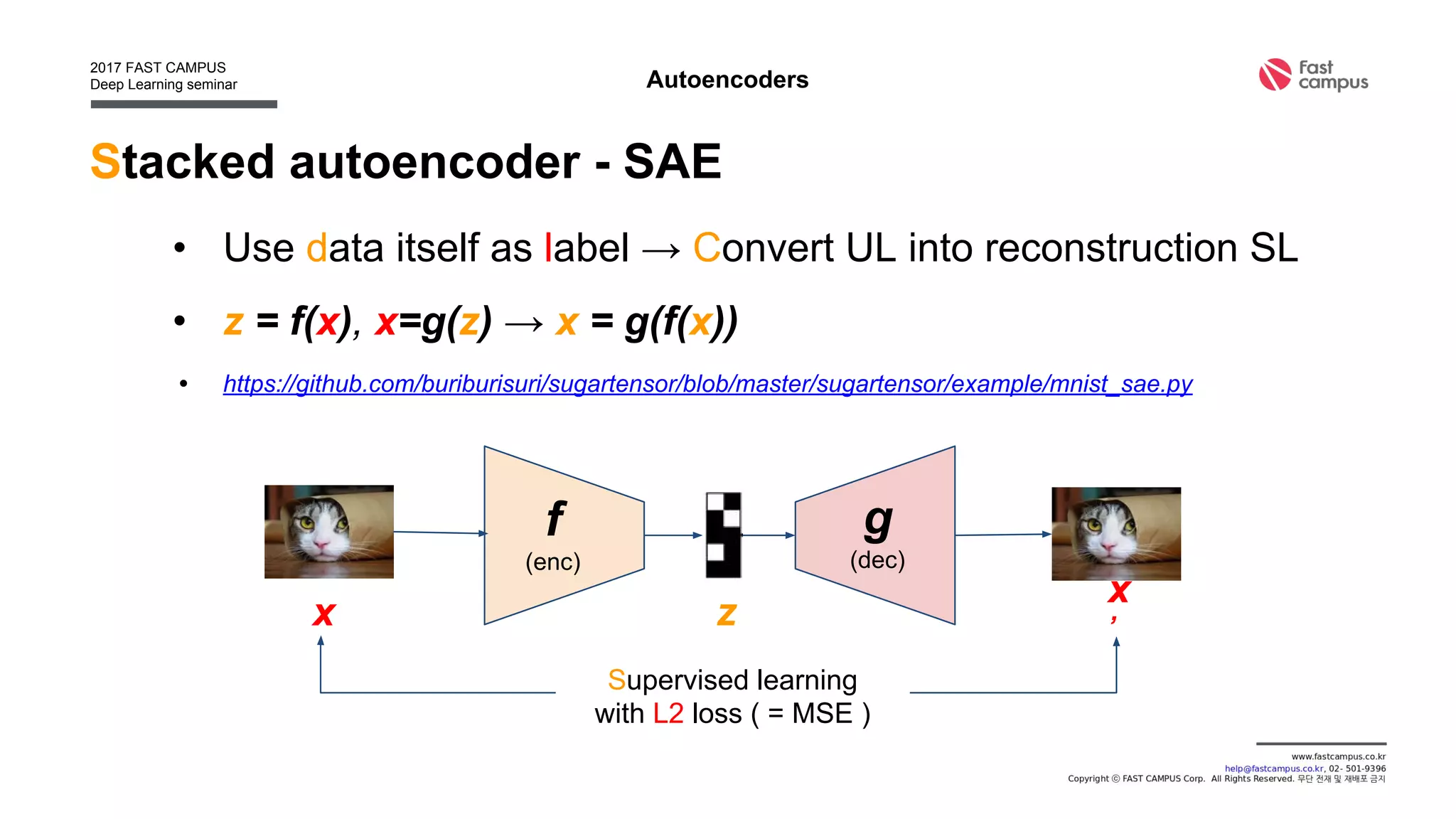
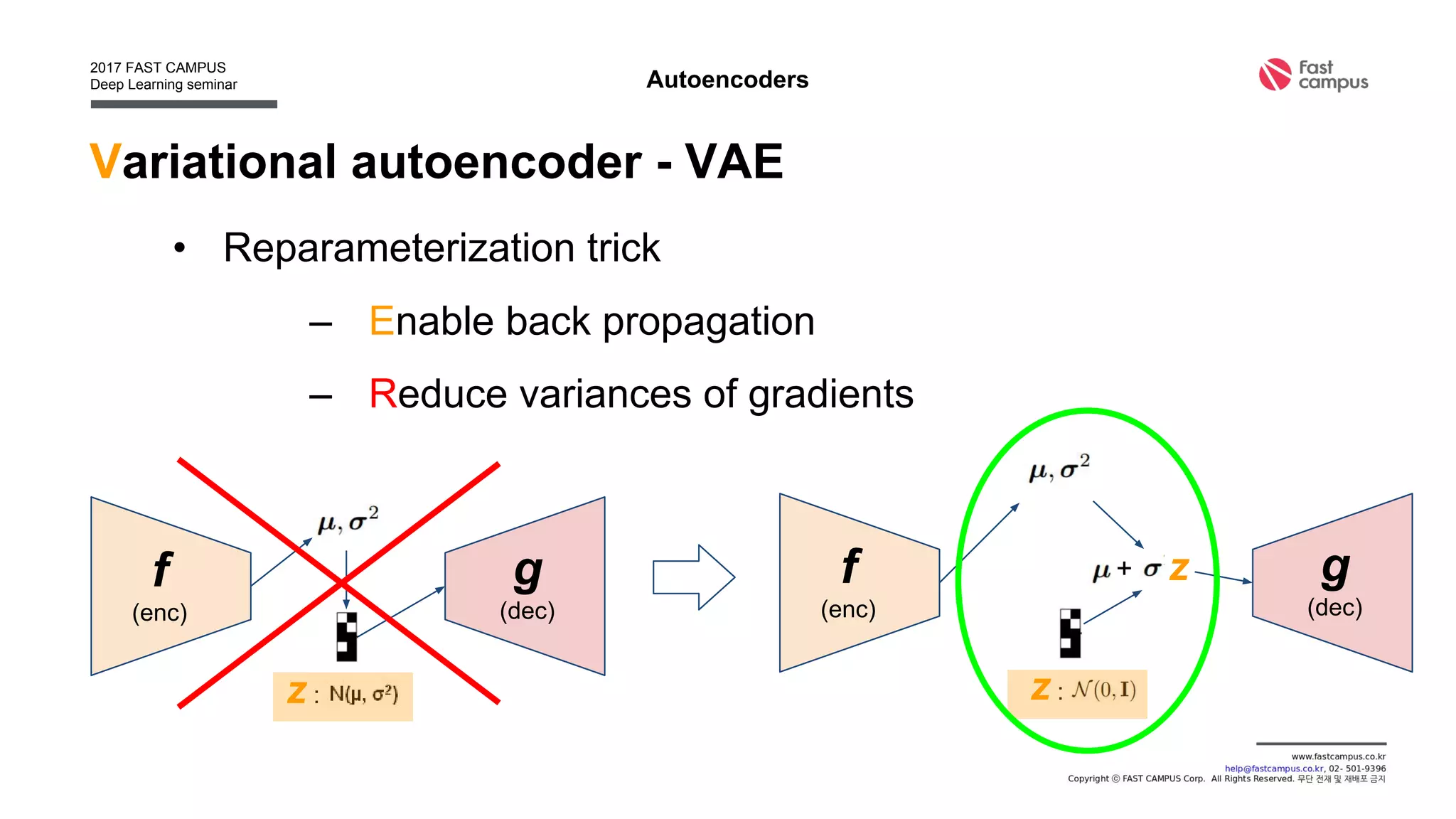
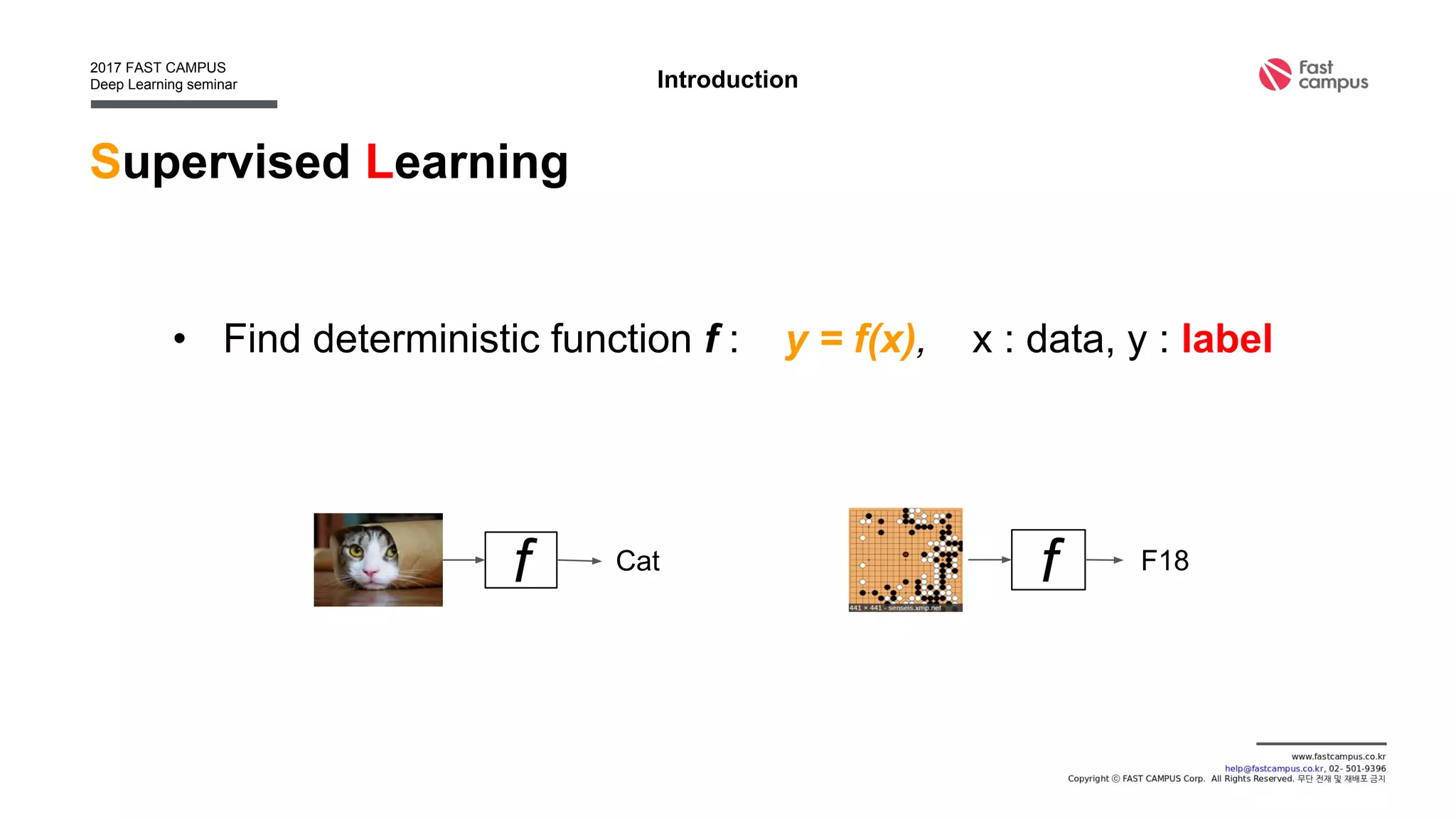
• Find deterministic function f : z = f(x), x : data, z : latent
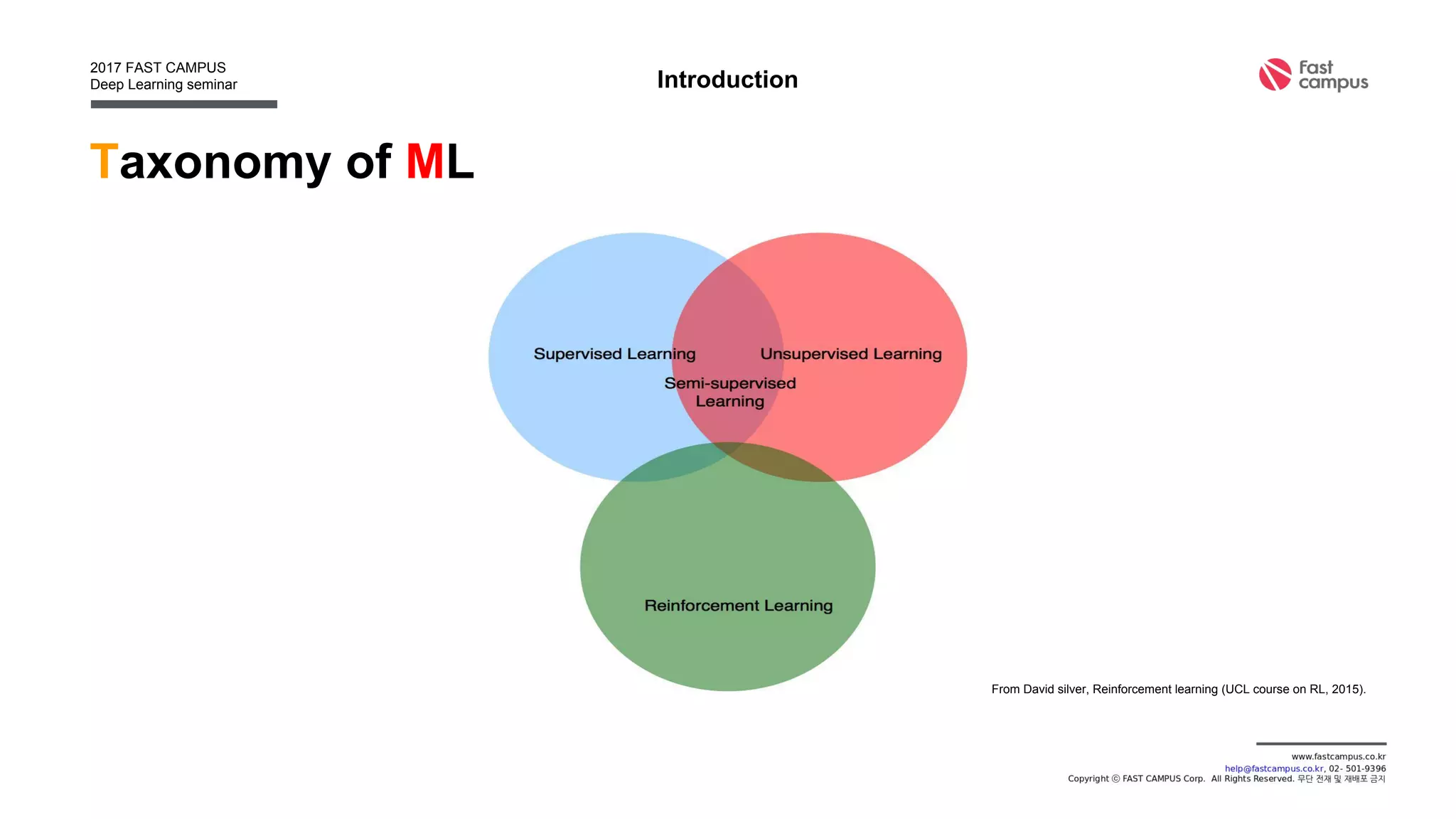
Introduction
[0.1, 0.3, -0.8, 0.4, … ]f](https://image.slidesharecdn.com/generativeadversarialnetworks-170111082649/75/Generative-adversarial-networks-13-2048.jpg)

![Generative Model
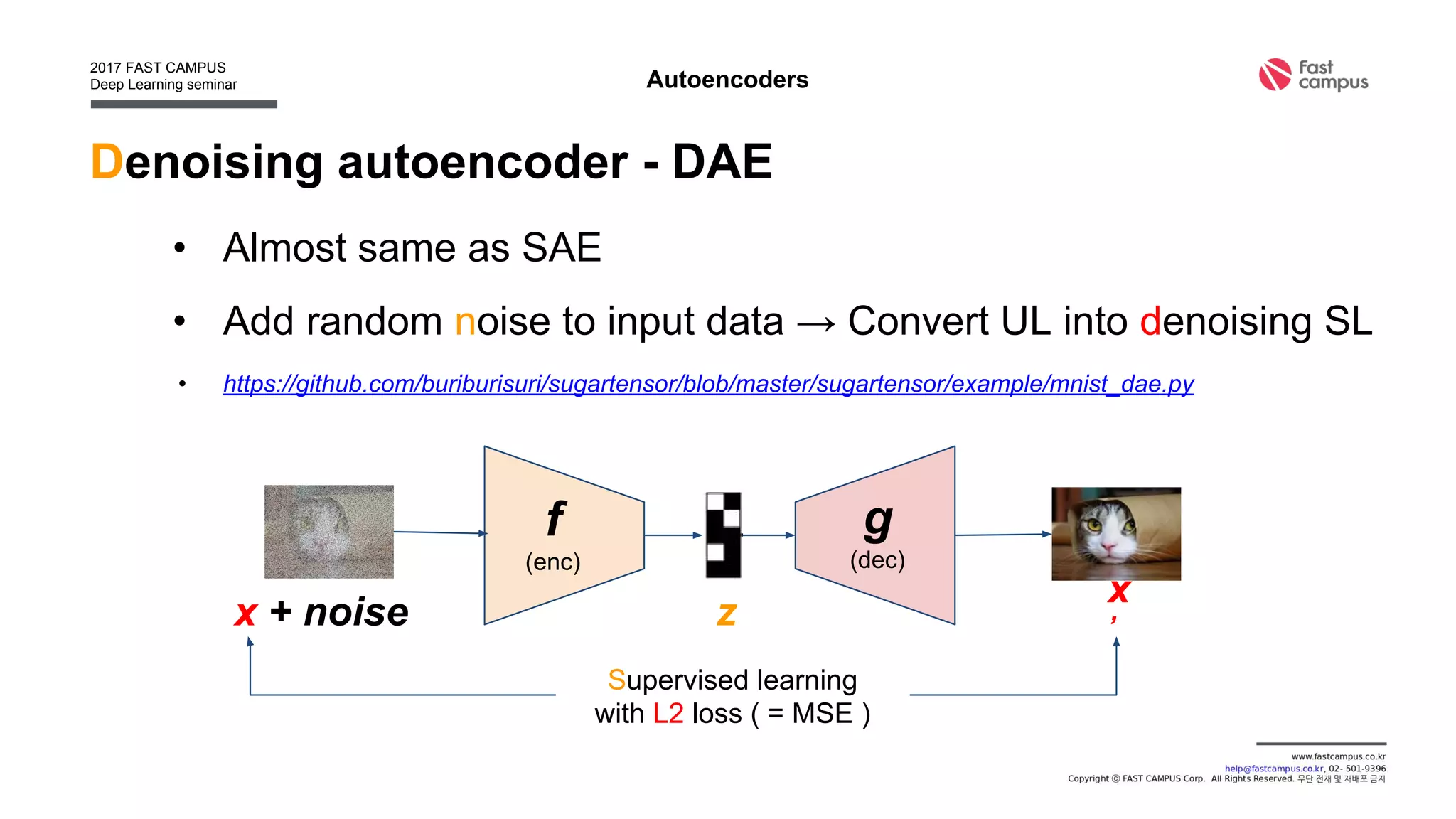
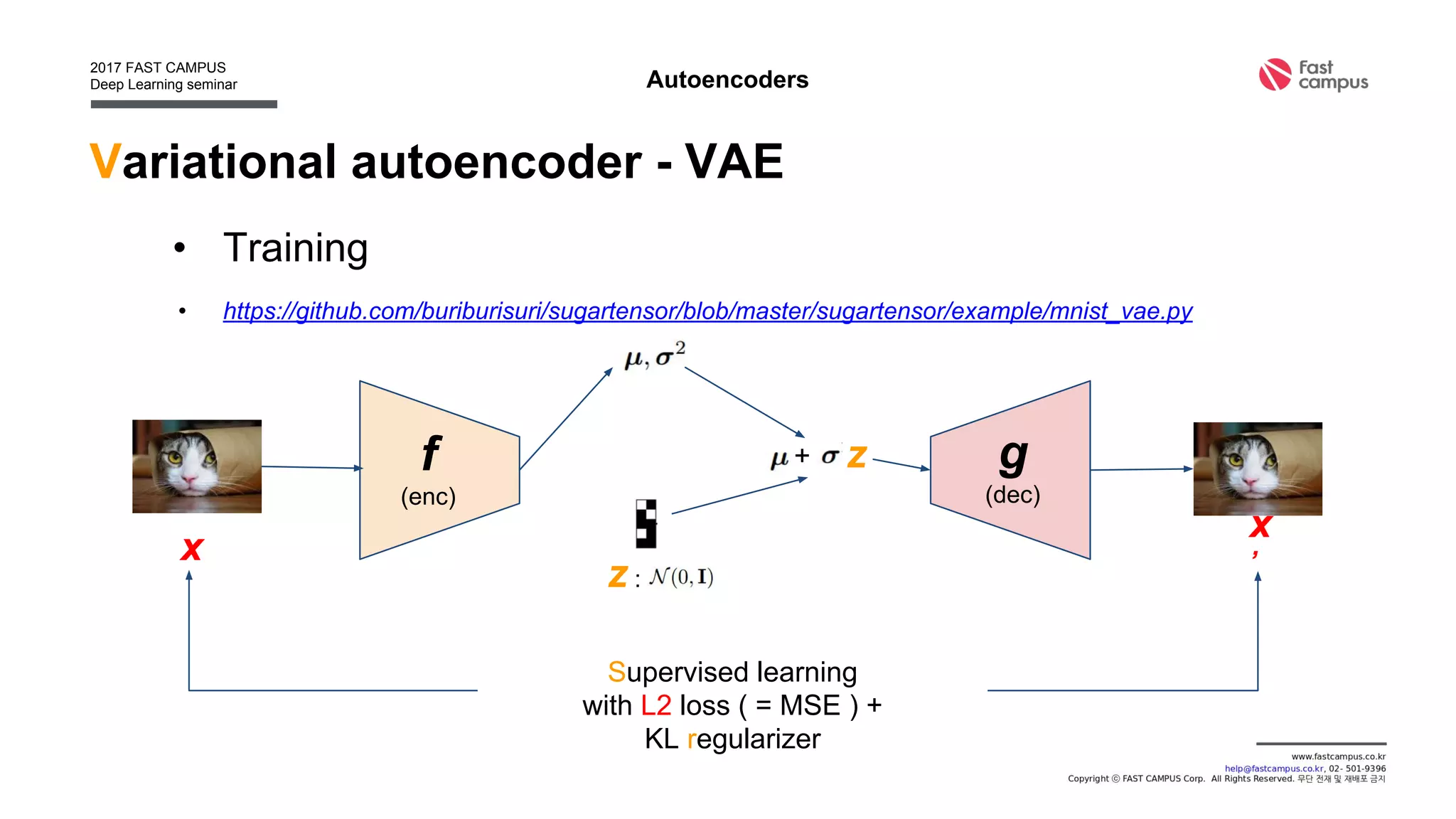
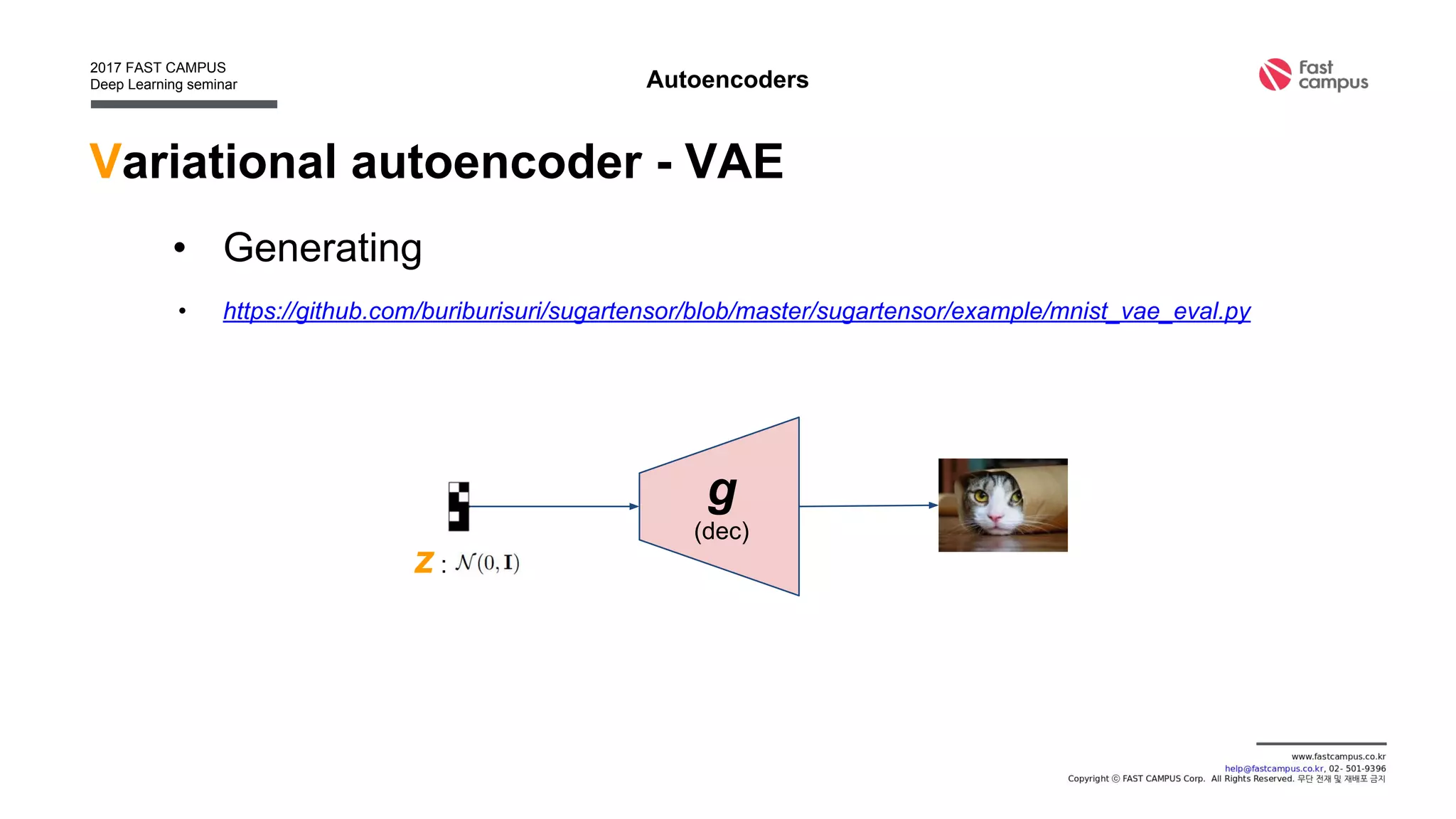
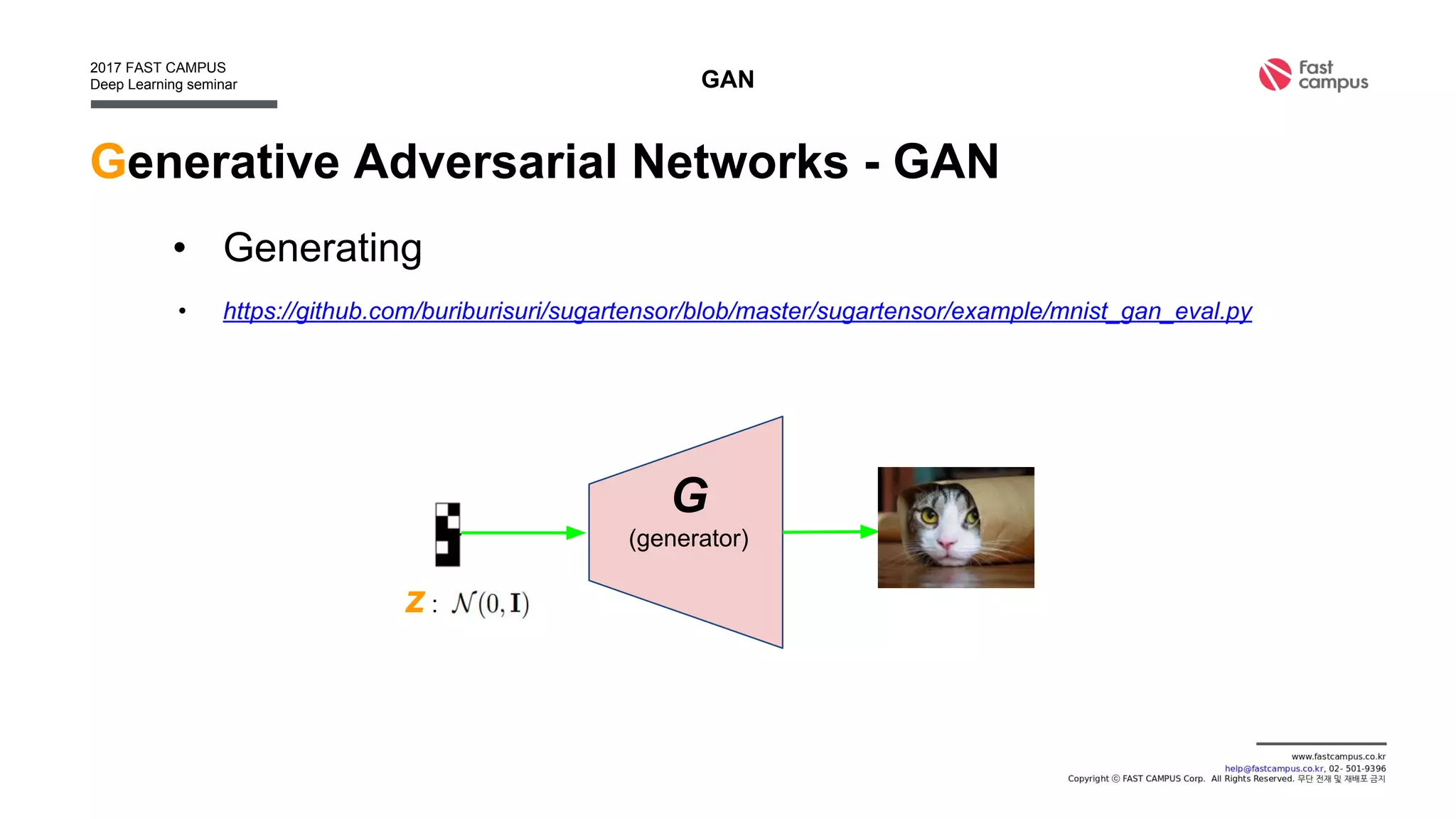
• Find generation function g : x = g(z), x : data, z : latent
Introduction
[0.1, 0.3, -0.8, 0.4, … ]
g](https://image.slidesharecdn.com/generativeadversarialnetworks-170111082649/75/Generative-adversarial-networks-17-2048.jpg)