Downloaded 46 times
![[http://pagines.uab.cat/mcv/]
Module 6 - Day 8 - Lecture 2
The Transformer
in Vision
31th March 2022
Xavier Giro-i-Nieto
@DocXavi
xavier.giro@upc.edu
Associate Professor
Universitat Politècnica de Catalunya](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-1-320.jpg)
![[http://pagines.uab.cat/mcv/]
Module 6 - Day 8 - Lecture 2
The Transformer
in Vision
31th March 2022
Xavier Giro-i-Nieto
@DocXavi
xavier.giro@upc.edu
Associate Professor
Universitat Politècnica de Catalunya](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/75/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-1-2048.jpg)

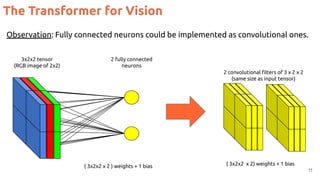
![The Transformer for Vision: ViT
3
#ViT Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. "An
image is worth 16x16 words: Transformers for image recognition at scale." ICLR 2021. [blog] [code] [video by Yannic Kilcher]](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-3-320.jpg)

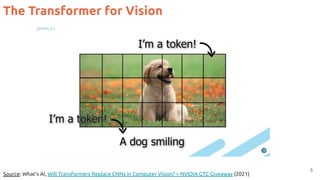
![The Transformer for Vision: ViT
6
#ViT Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. "An
image is worth 16x16 words: Transformers for image recognition at scale." ICLR 2021. [blog] [code] [video by Yannic Kilcher]](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-6-320.jpg)
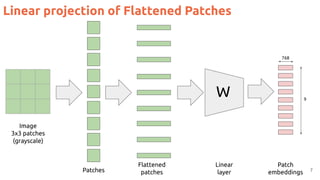
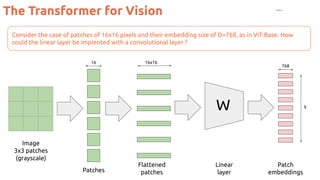
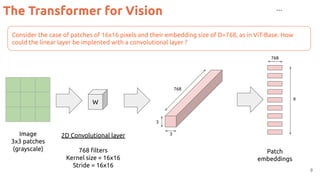


![Position Embeddings
13
#ViT Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. "An
image is worth 16x16 words: Transformers for image recognition at scale." ICLR 2021. [blog] [code] [video by Yannic Kilcher]](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-13-320.jpg)
![Position embeddings
14
#ViT Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. "An
image is worth 16x16 words: Transformers for image recognition at scale." ICLR 2021. [blog] [code] [video by Yannic Kilcher]
The model learns to encode the relative position between patches.
Each position embedding is most similar to
others in the same row and column, indicating
that the model has recovered the grid structure
of the original images.](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-14-320.jpg)

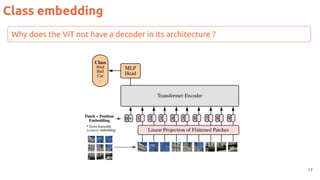
![Class embedding
16
#BERT Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. "Bert: Pre-training of deep bidirectional transformers for language
understanding." NAACL 2019.
[class] is a special learnable
embedding added in front of
every input example.
It triggers the class prediction.](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-16-320.jpg)


![Performance: Accuracy
21
#BiT Kolesnikov, Alexander, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. "Big transfer (bit): General
visual representation learning." ECCV 2020.
#ViT Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. "An
image is worth 16x16 words: Transformers for image recognition at scale." ICLR 2021. [blog] [code] [video by Yannic Kilcher]
Slight improvement over
CNN (BiT) when very
large amounts of training
data available.
Worse
performance
than CNN (BiT)
with ImageNet
data only.](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-21-320.jpg)
![Performance: Computation
22
#BiT Kolesnikov, Alexander, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. "Big transfer (bit): General
visual representation learning." ECCV 2020.
#ViT Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani et al. "An
image is worth 16x16 words: Transformers for image recognition at scale." ICLR 2021. [blog] [code] [video by Yannic Kilcher]
Requires less training
computation than
comparable CNN (BiT).](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-22-320.jpg)


![Shifted WINdow (SWIN) Self-Attention (SA)
25
#SWIN Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., ... & Guo, B. Swin Transformer: Hierarchical Vision Transformer using
Shifted Windows. ICCV 2021 [Best paper award].
Less computation by self-attenting only in local windows (in grey).
ViT Swin Transformers
Localized
SA
Global SA
Global SA](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-25-320.jpg)
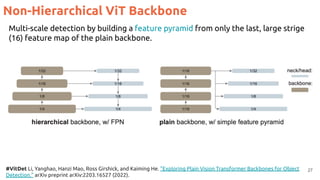
![26
#SWIN Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., ... & Guo, B. Swin Transformer: Hierarchical Vision Transformer using
Shifted Windows. ICCV 2021 [Best paper award].
Hierarchical features maps by merging image patches (in red) across layers.
ViT Swin Transformers
Low
resolution
High
resolution
Low
resolution
Hierarchical ViT Backbone](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-26-320.jpg)

![Object Detection
29
#DETR Carion, Nicolas, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko.
"End-to-End Object Detection with Transformers." ECCV 2020. [code] [colab]
● Object detection formulated as a set prediction problem.
● DETR infers a fixed-size amount of predictions.
● Comparable performance to Faster R-CNN.](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-29-320.jpg)
![30
#DETR Carion, Nicolas, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko.
"End-to-End Object Detection with Transformers." ECCV 2020. [code] [colab]
● During training, bipartite matching uniquely assigns predictions with ground
truth boxes.
● Prediction with no match should yield a “no object” (∅) class prediction.
Predictions
Ground
Truth
Object Detection](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-30-320.jpg)
![31
Is attention (or convolutions) all we need ?
#MLP-Mixer Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica
Yung, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy, “MLP-Mixer: An all-MLP Architecture for Vision”.
NeurIPS 2021. [tweet] [video by Yannic Kilcher]
“In this paper we show that while convolutions and attention are both sufficient
for good performance, neither of them are necessary.”](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-31-320.jpg)
![32
Is attention (or convolutions) all we need ?
#MLP-Mixer Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica
Yung, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy, “MLP-Mixer: An all-MLP Architecture for Vision”.
NeurIPS 2021. [tweet] [video by Yannic Kilcher] [code]
Two types of MLP Layers:
● MLP 1: Applied independently to image patches (i.e. “mixing” the
per-location features”)
● MLP 2: applied across patches (i.e. “mixing spatial information”).](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-32-320.jpg)
![33
#MLP-Mixer Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica
Yung, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy, “MLP-Mixer: An all-MLP Architecture for Vision”.
NeurIPS 2021. [tweet] [video by Yannic Kilcher]
Computation efficiency (train) Training data efficiency
Is attention (or convolutions) all we need ?](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-33-320.jpg)
![34
#MLP-Mixer Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica
Yung, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy, “MLP-Mixer: An all-MLP Architecture for Vision”.
NeurIPS 2021. [tweet] [video by Yannic Kilcher]
Is attention (or convolutions) all we need ?](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-34-320.jpg)
![35
#RepMLP Xiaohan Ding, Xiangyu Zhang, Jungong Han, Guiguang Ding, “RepMLP: Re-parameterizing Convolutions into
Fully-connected Layers for Image Recognition” CVPR 2022. [code] [tweet]
Is attention all we need ?](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-35-320.jpg)
![36
#ConvNeXt Liu, Zhuang, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. "A ConvNet
for the 2020s." CVPR 2022. [code]
Is attention all we need ?
Gradually “modernize” a standard ResNet towards the design of ViT.](https://image.slidesharecdn.com/82vitmcvm62022public-220525091343-4304afcf/85/The-Transformer-in-Vision-Xavier-Giro-Master-in-Computer-Vision-Barcelona-2022-36-320.jpg)


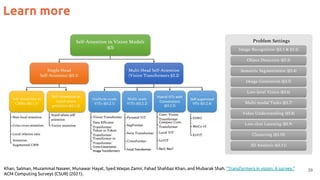



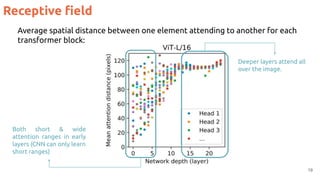
The document discusses the Vision Transformer (ViT) model for computer vision tasks. It covers: 1. How ViT tokenizes images into patches and uses position embeddings to encode spatial relationships. 2. ViT uses a class embedding to trigger class predictions, unlike CNNs which have decoders. 3. The receptive field of ViT grows as the attention mechanism allows elements to attend to other distant elements in later layers. 4. Initial results showed ViT performance was comparable to CNNs when trained on large datasets but lagged CNNs trained on smaller datasets like ImageNet.




![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)













![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 23] Ivan Biliskov - Seeing Through the Lens of Transformers: A Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/ivanbiliskov-cvvisiontransformers-231129094209-d32f1292-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)










































