Download as PDF, PPTX
![@DocXavi
Xavier Giró-i-Nieto
[http://pagines.uab.cat/mcv/]
Module 6
Deep Learning for Video:
Action Recognition
22nd March 2018](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-1-320.jpg)
![@DocXavi
Xavier Giró-i-Nieto
[http://pagines.uab.cat/mcv/]
Module 6
Deep Learning for Video:
Action Recognition
22nd March 2018](https://image.slidesharecdn.com/1-actionrecognition-180326163443/75/Deep-Learning-for-Video-Action-Recognition-UPC-2018-1-2048.jpg)







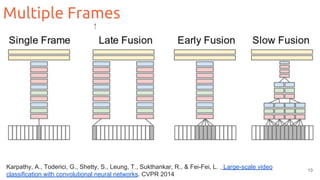

![17Slide credit: Santi Pascual
If we have a sequence of samples...
predict sample x[t+1] knowing previous values {x[t], x[t-1], x[t-2], …, x[t-τ]}
Limitation of Feed Forward NN (as CNNs)](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-17-320.jpg)
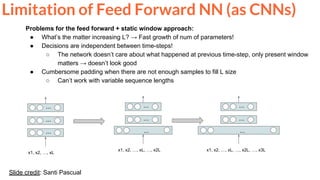
![18Slide credit: Santi Pascual
Feed Forward approach:
● static window of size L
● slide the window time-step wise
...
...
...
x[t+1]
x[t-L], …, x[t-1], x[t]
x[t+1]
L
Limitation of Feed Forward NN (as CNNs)](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-18-320.jpg)
![19Slide credit: Santi Pascual
Feed Forward approach:
● static window of size L
● slide the window time-step wise
...
...
...
x[t+2]
x[t-L+1], …, x[t], x[t+1]
...
...
...
x[t+1]
x[t-L], …, x[t-1], x[t]
x[t+2]
L
Limitation of Feed Forward NN (as CNNs)](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-19-320.jpg)
![20Slide credit: Santi Pascual 20
Feed Forward approach:
● static window of size L
● slide the window time-step wise
x[t+3]
L
...
...
...
x[t+3]
x[t-L+2], …, x[t+1], x[t+2]
...
...
...
x[t+2]
x[t-L+1], …, x[t], x[t+1]
...
...
...
x[t+1]
x[t-L], …, x[t-1], x[t]
Limitation of Feed Forward NN (as CNNs)](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-20-320.jpg)

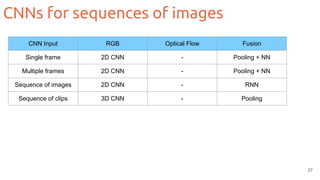

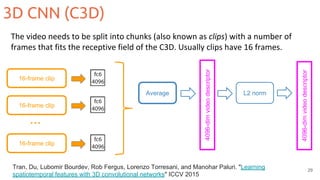

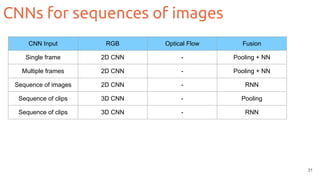

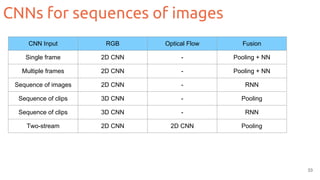
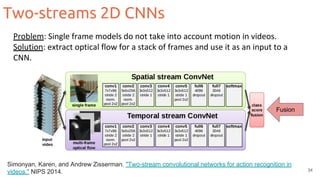
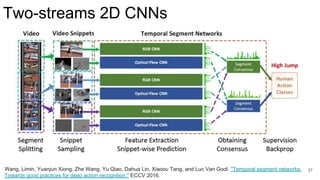
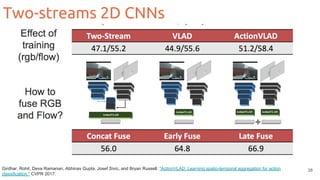
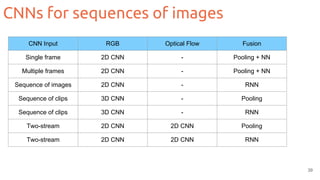
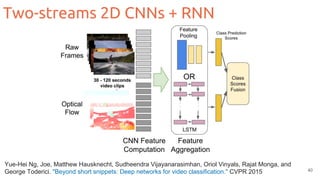
![Two-streams 2D CNNs
35
Feichtenhofer, Christoph, Axel Pinz, and Andrew Zisserman. "Convolutional two-stream network fusion for video action recognition." CVPR 2016. [code]
Fusion](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-35-320.jpg)
![Two-streams 2D CNNs
36
Feichtenhofer, Christoph, Axel Pinz, and Richard Wildes. "Spatiotemporal residual networks for video action recognition." NIPS 2016. [code]](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-36-320.jpg)
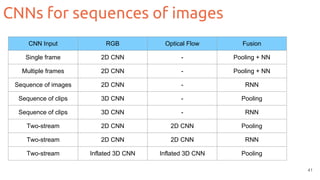
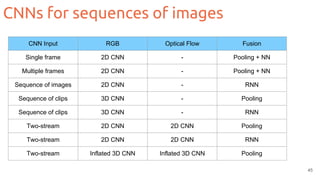
![Two-streams 3D CNNs
42
Carreira, J., & Zisserman, A. . Quo vadis, action recognition? A new model and the kinetics dataset. CVPR
2017. [code]](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-42-320.jpg)
![Two-streams Inflated 3D CNNs (I3D)
43
Carreira, J., & Zisserman, A. . Quo vadis, action recognition? A new model and the kinetics dataset. CVPR
2017. [code]
NxN NxNxN](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-43-320.jpg)
![Two-streams 3D CNNs
44
Carreira, J., & Zisserman, A. . Quo vadis, action recognition? A new model and the kinetics dataset. CVPR
2017. [code]](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-44-320.jpg)

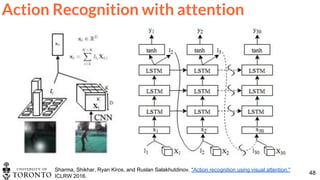
![BSc
thesis
47
Action Recognition with object detection
Gkioxari, Georgia, Ross Girshick, and Jitendra Malik. "Contextual action recognition with r* cnn." In ICCV
2015. [code]](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-47-320.jpg)









![58
Sigurdsson, G. A., Varol, G., Wang, X., Farhadi, A., Laptev, I., & Gupta, A. (2016, October). Hollywood in homes: Crowdsourcing data collection
for activity understanding. ECCV 2016. [Dataset] [Code]
Datasets: Charades (Allen AI)](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-58-320.jpg)
![60
(Slides by Dídac Surís) Abu-El-Haija, Sami, Nisarg Kothari, Joonseok Lee, Paul Natsev, George Toderici, Balakrishnan Varadarajan, and Sudheendra
Vijayanarasimhan. "Youtube-8m: A large-scale video classification benchmark." arXiv preprint arXiv:1609.08675 (2016). [project]
Datasets: YouTube-8M (Google)](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-60-320.jpg)
![61
(Slides by Dídac Surís) Abu-El-Haija, Sami, Nisarg Kothari, Joonseok Lee, Paul Natsev, George Toderici, Balakrishnan Varadarajan, and Sudheendra
Vijayanarasimhan. "Youtube-8m: A large-scale video classification benchmark." arXiv preprint arXiv:1609.08675 (2016). [project]
Activity Recognition: Datasets](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-61-320.jpg)
![62
Hang Zhao, Zhicheng Yan, Heng Wang, Lorenzo Torresani, Antonio Torralba, “SLAC: A Sparsely Labeled Dataset for Action Classification and
Localization” arXiv 2017 [project page]
Datasets: SLAC (MIT & Facebook)](https://image.slidesharecdn.com/1-actionrecognition-180326163443/85/Deep-Learning-for-Video-Action-Recognition-UPC-2018-62-320.jpg)









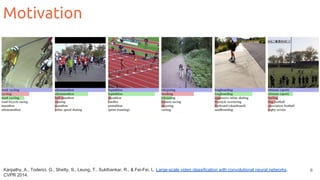
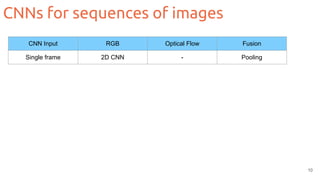
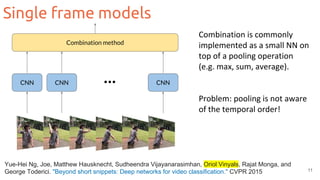
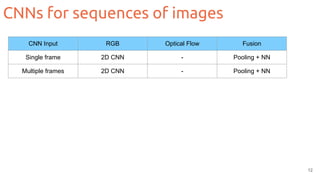
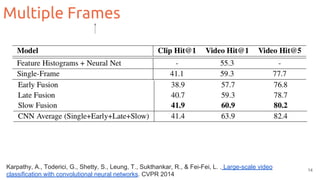
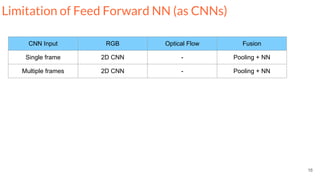
The document outlines techniques for action recognition in videos using deep learning, with a focus on convolutional neural networks (CNNs) and recurrent neural networks (RNNs). It discusses various approaches, limitations, and advances in video classification, highlighting key studies and datasets relevant to the field. Additionally, it provides insights into methods for improving model performance and addressing challenges faced when working with video data.

























![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)



























































