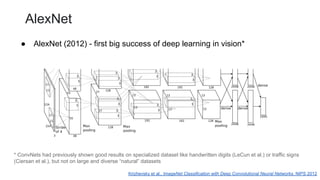
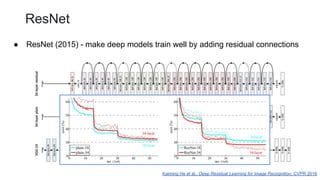
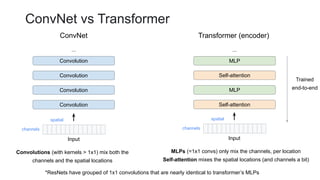
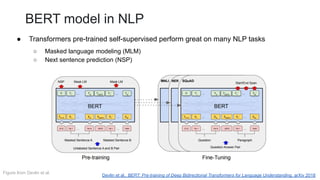
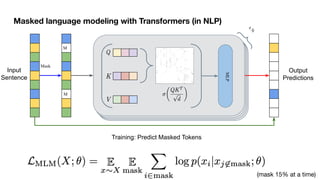
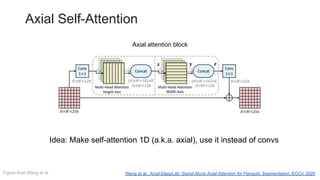
This document outlines a lecture on transformer models applied to vision tasks, discussing their background, architecture, and applications in image classification. It highlights the transition from traditional convolutional networks to transformers, the challenges of self-attention for visual data, and innovations such as local and axial self-attention. Additionally, it addresses scaling laws and the performance of vision transformers compared to traditional models like ResNet.


![Outline
● Background on Transformer models
● Transformers for image classification
● [Admin interlude]
● Perceiver models [guest talk from Drew Jaegle, DeepMind]](https://image.slidesharecdn.com/5transformers-250211090123-8b9aab37/85/BriefHistoryTransformerstransformers-pdf-2-320.jpg)



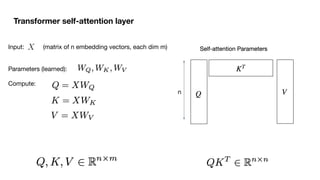
![Self-Attention with Queries, Keys, Values
Make three version of each input embedding x(i)
[Julia Hockenmaier, Lecture 9, UIUC]](https://image.slidesharecdn.com/5transformers-250211090123-8b9aab37/85/BriefHistoryTransformerstransformers-pdf-8-320.jpg)
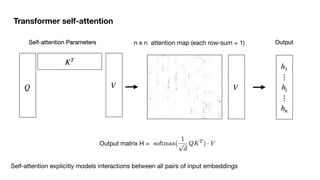
![[Julia Hockenmaier, Lecture 9, UIUC]
Multi-Head attention](https://image.slidesharecdn.com/5transformers-250211090123-8b9aab37/85/BriefHistoryTransformerstransformers-pdf-11-320.jpg)





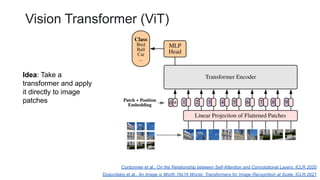
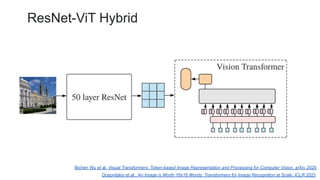
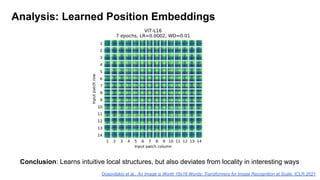
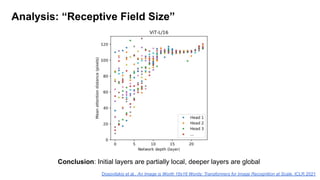




![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)






















