Downloaded 34 times







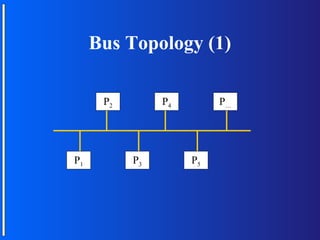

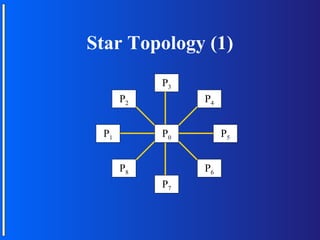

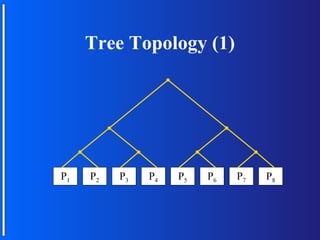

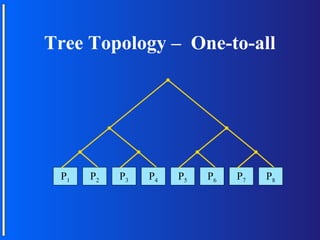
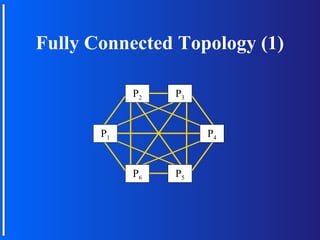

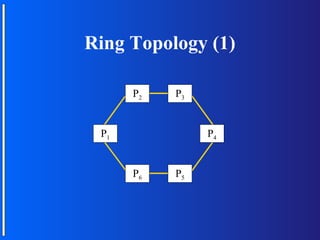

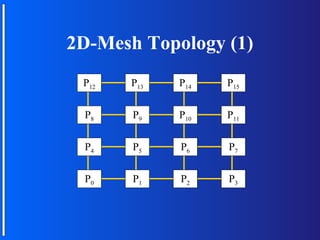

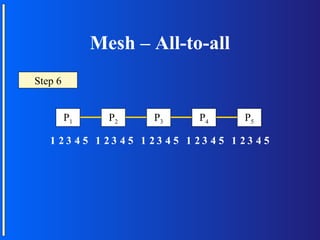
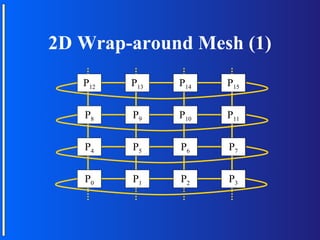

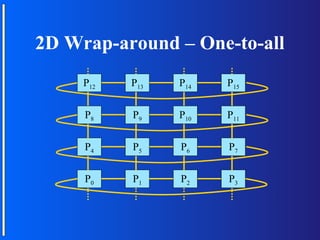
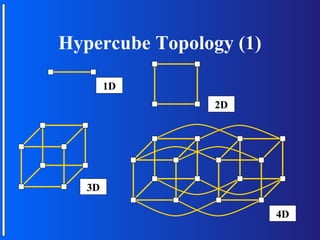
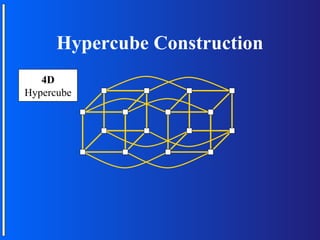














The document discusses various topologies for connecting processors in parallel computing systems, including bus, star, tree, fully connected, ring, mesh, wrap-around mesh, and hypercube topologies. It examines the hardware cost, communication performance, and scalability of each topology. Additionally, it covers synchronous and asynchronous communication methods between processors and issues that can arise like deadlocks.