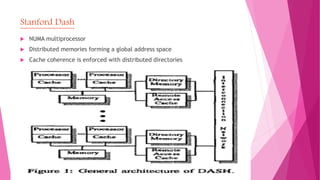
The document reviews the evolution of multiple-processor architectures, highlighting shared-memory and distributed-memory systems like the NYU Ultracomputer and Illinois Cedar, along with their unique interconnect networks. It discusses various multiprocessor systems including Fujitsu VPP500 and BBN Butterfly, emphasizing their designs and connectivity options for memory access. Additionally, it touches upon vector supercomputers and SIMD architectures such as Cray 1 and ILIAC IV, illustrating the advancements in parallel computing technologies.